2024-2025-1 20241305 《计算机基础和程序设计》第十三周学习总结
作业信息
| 这个作业属于哪个课程 | 2024-2025-1-计算机基础与程序设计](https://edu.cnblogs.com/campus/besti/2024-2025-1-CFAP) |
|---|---|
| 这个作业要求在哪里 | 2024-2025-1计算机基础与程序设计第十三周作业 |
| 这个作业的目标 | 《C语言程序设计》第12章并完成云班课测试 |
| 作业正文 | 本博客链接 |
教材学习内容总结
以下是对《C语言程序设计》第十二章“结构体和数据结构基础”各部分内容的总结:
12.1 从基本数据类型到抽象数据类型
- 主要内容:介绍了基本数据类型在处理简单数据时的便利性,但面对复杂且相互关联的数据组合时存在局限。抽象数据类型则是将数据及相关操作封装在一起的一种概念,结构体等就是C语言迈向抽象数据类型的一种体现,它能让程序员自定义可以表示更复杂逻辑结构的数据类型,更有效地组织和管理数据。
12.2 结构体的定义
- 定义方式:使用
struct关键字来定义结构体,语法格式一般为struct 结构体名 { 成员列表 };,成员列表中包含各种不同类型(如int、char、float等)的变量声明,这些变量就是结构体的成员。例如定义一个表示学生信息的结构体:
struct Student {
char name[20];
int age;
float score;
};
- 用途:通过结构体可以将多个相关的数据整合在一起,便于整体操作和管理,使程序的数据结构更贴合实际问题中的逻辑结构。
12.3 结构体数组的定义和初始化
- 定义:和普通数组定义类似,只是数组元素类型为结构体类型。例如:
struct Student students[10];就定义了一个包含 10 个Student结构体类型元素的数组,可用于存储多个学生的信息。 - 初始化:可以在定义时进行初始化,有多种初始化方式,如按顺序给每个成员赋初值,形式如下:
struct Student students[2] = {
{"Tom", 18, 85.5},
{"Jerry", 19, 90.0}
};
也可以只对部分元素初始化,未初始化的元素按相应类型默认值处理。
12.4 结构体指针的定义和初始化
- 定义:定义结构体指针变量的语法是
struct 结构体名 *指针变量名;,例如struct Student *p;就定义了一个指向Student结构体类型的指针变量。 - 初始化:可以将已定义的结构体变量的地址赋给指针使其初始化,如
struct Student s; p = &s;,也可以在动态内存分配时初始化,比如通过p = (struct Student *)malloc(sizeof(struct Student));为指针分配一块能存储Student结构体的内存空间并让指针指向它,之后可通过指针来访问结构体成员,使用->运算符,例如p->age = 20;。
12.5 从函数传递结构体
- 传递方式:可以按值传递结构体,即将整个结构体复制一份传递给函数,但这样在结构体较大时会有较大开销。也可以传递结构体指针,函数中通过指针操作原结构体,效率更高且能修改原结构体内容。例如:
// 按值传递结构体的函数声明
void printStudent(struct Student s);
// 按指针传递结构体的函数声明
void modifyStudent(struct Student *p);
- 应用场景:根据实际需求选择合适的传递方式,若只是查看结构体内容不修改可按值传递,若要在函数内修改原结构体数据则通常采用指针传递的方式。
12.6 共用体
- 定义与特点:使用
union关键字定义,语法类似结构体union 共用体名 { 成员列表 };。共用体的特点是所有成员共用同一块内存空间,在某一时刻只能存储其中一个成员的值,内存大小取决于其最大成员所占空间大小。例如:
union Data {
int num;
char ch;
};
- 应用场景:适用于对同一块内存空间有不同解释的情况,比如在某些底层硬件数据交互场景中,根据不同的操作需求把相同内存区域当作不同类型的数据来使用。
12.7 枚举数据类型
- 定义与作用:通过
enum关键字定义,语法为enum 枚举名 { 枚举常量列表 };,它用于定义一组具有离散值的相关常量,使代码可读性更强。例如:
enum Weekday {
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY,
SUNDAY
};
这里默认 MONDAY 为 0,后续常量依次递增 1,也可以手动指定常量的值。
- 使用场景:常用于表示有限的、固定的几种状态或选项的情况,如表示星期、颜色种类等,便于代码中根据不同枚举值进行不同逻辑处理。
12.8 动态数据结构 - 单向链表
- 基本概念:单向链表是一种常见的动态数据结构,由一个个节点组成,每个节点包含数据域(可以是结构体等类型存放具体数据)和指针域(指向下一个节点的指针)。节点结构体一般定义如下:
struct Node {
int data; // 数据域,这里以存储整数为例,实际可替换为其他结构体等类型
struct Node *next; // 指针域,指向下一个节点
};
- 基本操作及代码示例:
- 创建节点:
struct Node *createNode(int value) {
struct Node *newNode = (struct Node *)malloc(sizeof(struct Node));
if (newNode!= NULL) {
newNode->data = value;
newNode->next = NULL;
}
return newNode;
}
- **插入节点(以头插法为例)**:
void insertAtHead(struct Node **head, int value) {
struct Node *newNode = createNode(value);
if (newNode!= NULL) {
newNode->next = *head;
*head = newNode;
}
}
- **遍历链表**:
void traverseList(struct Node *head) {
struct Node *current = head;
while (current!= NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
}
- **释放链表内存(避免内存泄漏)**:
void freeList(struct Node *head) {
struct Node *current = head;
struct Node *next;
while (current!= NULL) {
next = current->next;
free(current);
current = next;
}
}
单向链表可以根据实际需求灵活地进行节点的插入、删除、查找等操作,适用于数据个数不确定、需要动态调整的数据存储和管理场景。
教材学习中的问题和解决过程(先问 AI)
问题一:动态数据结构-单向链表的优缺点有哪些?
解答:1. 单向链表的优点
- 动态性
- 单向链表可以根据程序运行过程中的实际需求动态地分配和释放内存空间。例如,在一个数据管理程序中,当需要插入新的数据元素时,通过调用malloc函数就可以创建一个新的节点并将其插入到链表中合适的位置。而不像数组那样,需要预先定义固定大小的内存空间,当数据量超过数组容量时可能会出现溢出等问题。
- 这种动态特性使得单向链表能够灵活地应对数据量不断变化的情况,非常适合处理不确定大小的数据集合,如在一个网络服务器程序中,用于存储客户端连接信息,连接数量在程序运行过程中是动态变化的,单向链表就可以很好地满足这种需求。
- 插入和删除操作相对高效(在特定位置)
- 对于单向链表来说,在链表头部或者中间已知位置插入和删除节点的操作相对比较简单和高效。以插入节点为例,在头部插入节点只需要进行少量的指针操作。假设head是指向链表头部的指针,插入新节点newNode的代码如下:
void insertAtHead(struct Node **head, int value) {
struct Node *newNode = createNode(value);
if (newNode!= NULL) {
newNode->next = *head;
*head = newNode;
}
}
- 在这个操作中,主要步骤是将新节点的`next`指针指向当前的头部节点,然后将新节点赋值给`head`,使得新节点成为新的头部,这样的操作时间复杂度为$O(1)$。在已知节点位置插入节点(如在节点`p`之后插入新节点`newNode`),操作也相对简单,代码如下:
void insertAfter(struct Node *p, int value) {
struct Node *newNode = createNode(value);
if (newNode!= NULL) {
newNode->next = p->next;
p->next = newNode;
}
}
- 这种操作的时间复杂度取决于找到插入位置的时间,在已经定位到插入位置的节点`p`后,插入操作本身时间复杂度为$O(1)$。
- **内存利用率较高(在某些情况下)**
- 由于单向链表不需要像数组那样预留连续的内存空间,所以在内存分配上更加灵活。如果数据存储的规模不确定,并且数据元素之间不需要连续存储,单向链表可以更好地利用内存碎片。例如,在一个嵌入式系统中,内存资源比较宝贵,单向链表可以根据实际的小数据块需求分配内存,避免浪费大量连续内存空间。
- 单向链表的缺点
- 访问效率较低
- 单向链表不能像数组那样通过索引直接访问元素。在单向链表中,要访问某个节点,必须从链表头部开始,通过逐个遍历节点的指针来找到目标节点。例如,要访问第
n个节点,平均需要遍历n/2个节点,时间复杂度为$O(n)$。对比数组,数组访问元素的时间复杂度为$O(1)$。 - 这种低效率在需要频繁随机访问数据元素的应用场景中会成为明显的劣势。例如,在一个需要快速查找特定元素的数据库系统中,如果使用单向链表来存储数据,查询操作会非常耗时。
- 单向链表不能像数组那样通过索引直接访问元素。在单向链表中,要访问某个节点,必须从链表头部开始,通过逐个遍历节点的指针来找到目标节点。例如,要访问第
- 反向遍历困难
- 单向链表只有一个方向的指针(指向下一个节点),没有指向前一个节点的指针。如果需要从链表的末尾开始向头部遍历,或者需要获取当前节点的前一个节点的信息,单向链表就很难实现。
- 虽然可以通过额外的手段(如使用栈来存储已经遍历过的节点指针)来实现反向遍历,但这样会增加程序的复杂性和额外的空间开销。
- 占用额外的内存空间用于存储指针
- 单向链表的每个节点除了存储数据本身,还需要存储一个指向下一个节点的指针。对于数据量较大的情况,这些指针所占用的额外内存空间可能会比较可观。例如,如果存储的数据元素是简单的整数类型,在32位系统中,一个整数通常占用4字节,而一个指针也占用4字节,这样指针所占用的空间就占了节点总存储空间的一半。
- 这在对内存空间要求比较苛刻的环境(如一些资源受限的微控制器应用)中是一个需要考虑的重要因素。
- 访问效率较低
问题二:链表和数组在实际应用中的选择依据?
解答:1. 数据访问模式
- 数组
- 当需要频繁地随机访问元素时,数组是更好的选择。因为数组中的元素在内存中是连续存储的,通过索引可以直接定位到任何一个元素,时间复杂度为$O(1)$。例如,在一个图像处理程序中,需要频繁地访问图像的像素点。图像通常以二维数组(实际上在内存中是一维连续存储)的形式存储,通过行和列索引就能快速获取特定位置的像素信息,如pixel_value = image_array[row][col]。
- 这种直接访问的方式使得数组在实现查找特定位置元素的算法时效率很高,比如二分查找算法要求数据是有序的并且存储在数组中,通过不断比较中间元素和目标元素,可以在对数时间内找到目标元素,时间复杂度为$O(log n)$。
- 链表
- 如果数据访问主要是顺序访问,尤其是在插入和删除操作频繁的情况下,链表更具优势。例如,在一个文本编辑器的实现中,用于存储文本行的结构可以是链表。当用户在文本中插入或删除一行时,只需要对链表节点进行指针操作,而不需要像数组那样移动大量元素。
- 链表在遍历操作时,虽然时间复杂度为$O(n)$,但在某些顺序处理数据的场景下是可以接受的。比如在一个任务调度系统中,任务以链表形式存储,按照添加的顺序依次执行,从链表头部开始逐个处理节点(任务)即可。
2. 数据大小的可变性
- 数组
- 数组需要预先分配固定大小的内存空间。如果在程序运行过程中,数据量可能会超过数组的初始容量,就需要进行复杂的扩容操作。例如,在一个数据采集系统中,如果最初定义的数组用于存储采集的数据样本,当采集的数据量超过数组大小时,要么重新分配更大的数组并将原有数据复制过去(这会消耗大量时间和额外内存),要么放弃新的数据,这两种情况都不太理想。
- 但是,如果能够准确预估数据的最大规模,并且这个规模相对稳定,数组是一种简单高效的存储方式,因为它的内存布局简单,访问速度快。
- 链表
- 链表的大小可以动态变化,能够根据需要随时添加或删除节点。例如,在一个网络服务器的连接管理模块中,服务器需要处理不定数量的客户端连接。使用链表来存储连接信息,每当有新的客户端连接时,就创建一个新的节点并插入到链表中;当客户端断开连接时,就从链表中删除相应的节点,这样可以很好地适应连接数量的动态变化。
3. 内存使用和分配方式
- 数组
- 数组占用连续的内存空间。这使得它在缓存友好性方面具有优势,因为现代处理器的缓存机制更倾向于连续的数据访问。例如,在一个对性能要求极高的数值计算程序中,数组元素的连续存储有助于提高缓存命中率,从而加快计算速度。
- 然而,这种连续内存要求也可能导致内存浪费。如果数组部分元素没有被使用,这部分内存空间仍然会被占用。而且,如果数组需要扩容,可能找不到足够大的连续内存块,导致分配失败。
- 链表
- 链表的节点在内存中的位置可以是分散的,每个节点通过指针相互连接。这种方式更灵活地利用了内存空间,特别是在处理大量小数据块且数据量不确定的情况下。例如,在一个内存管理系统的实现中,用于记录内存块分配情况的结构可以是链表。不同大小的内存块以节点形式存储在链表中,根据内存的分配和回收动态地添加和删除节点,有效地利用内存碎片。
- 但是,由于每个节点需要额外的空间来存储指针,这会导致一定的内存开销。并且,链表节点的分散存储可能导致缓存命中率较低,因为在遍历链表时,处理器可能需要频繁地从不同的内存位置读取数据。
4. 操作的复杂度和效率
- 插入和删除操作
- 数组:在数组中间插入或删除元素时,需要移动大量的元素来保持数组的连续性。例如,在一个有序数组中插入一个元素,平均需要移动$n/2$个元素,时间复杂度为$O(n)$。删除操作同样如此,这在数据量较大时会消耗大量时间。但是,如果是在数组的末尾进行插入和删除操作,时间复杂度为$O(1)$,因为不需要移动其他元素。
- 链表:在链表中插入和删除节点相对简单。在已知位置插入或删除节点,只需要修改相关节点的指针,时间复杂度为$O(1)$(不考虑查找插入或删除位置的时间)。例如,在一个链表中删除指定节点p(假设不是链表的尾节点),代码如下:
void deleteNode(struct Node *p) {
struct Node *nextNode = p->next;
p->data = nextNode->data;
p->next = nextNode->next;
free(nextNode);
}
- **排序操作**
- **数组**:对于数组,有多种高效的排序算法可以利用其连续存储和随机访问的特点。例如,快速排序算法在平均情况下时间复杂度为$O(n log n)$,它通过选择一个基准元素,将数组分为两部分,然后递归地对两部分进行排序。数组的连续内存布局使得元素交换操作相对简单,能够高效地实现排序算法。
- **链表**:对链表进行排序相对复杂。由于不能像数组那样直接通过索引访问元素,一些基于交换元素的排序算法(如冒泡排序)在链表上实现效率较低。通常需要采用更复杂的排序算法,如归并排序的链表版本,其时间复杂度也是$O(n log n)$,但实现过程中需要更多的指针操作来合并和分割链表。
基于AI的学习

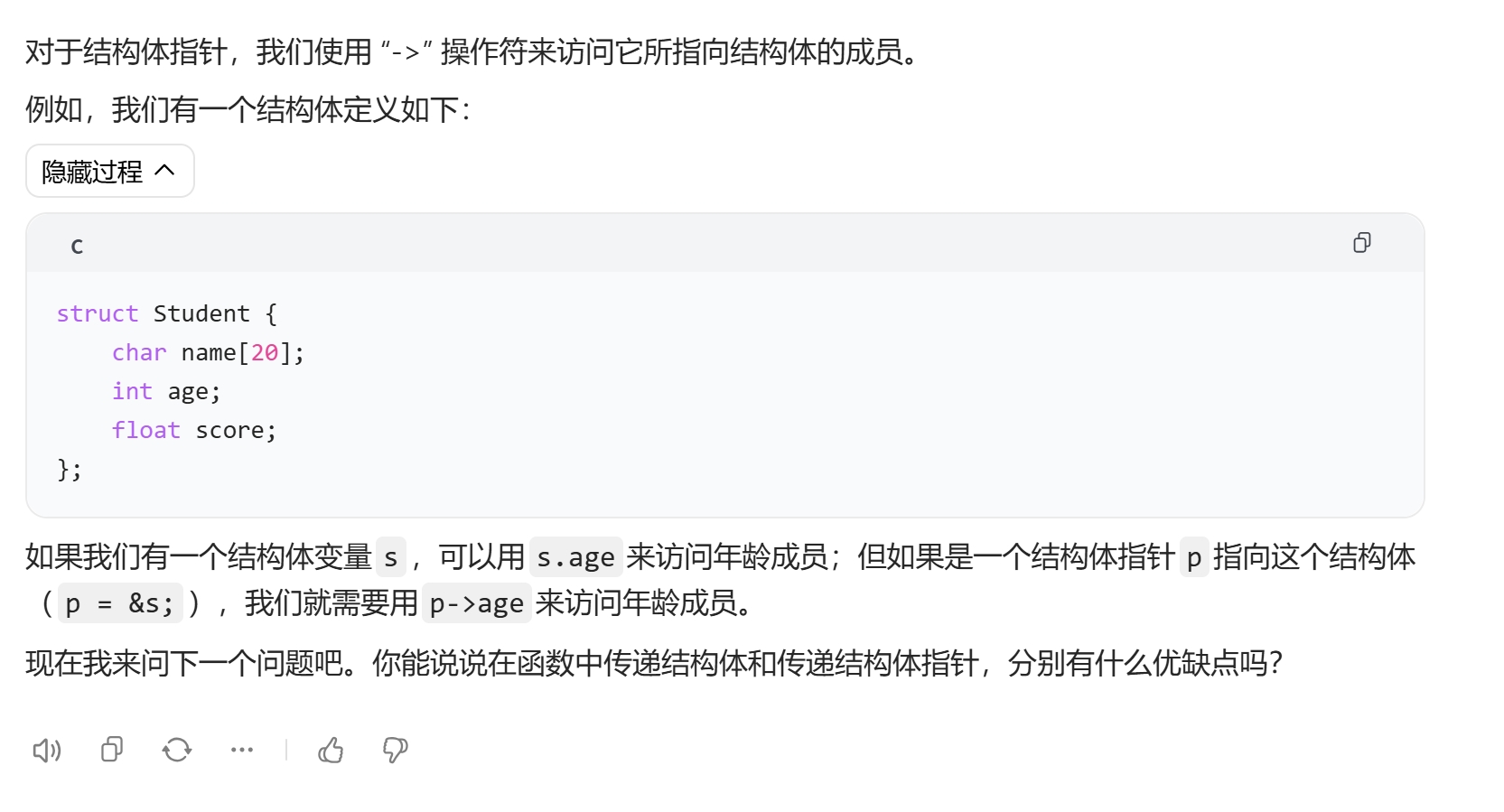
代码调试中的问题和解决过程
问题一:本周进行了实验六结构体和文件编程练习,发现开始时的程序运行会出现乱码和刷频的画面
解决:发现自己scanf时把浮点数保留了一位。产生错误(%f写成%。1f)
问题二:从文件读内容是程序错误
解决:自己把读文件的函数对应的人数n运用指针,用多余了
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第十三周 | 800/4400 | 2/19 | 20/230 |
计划学习时间:20时
实际学习时间:20时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号