在hadoop上创建目录/spark-study/users/gender=male/country=US/users.parquet(并且把文件put上去)
code:
package cn.spark.study.core.mycode_dataFrame;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.SQLContext;
public class ParquetPartitionDiscovery {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
//.setMaster("local")
.setAppName("ParquetPartitionDiscovery");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
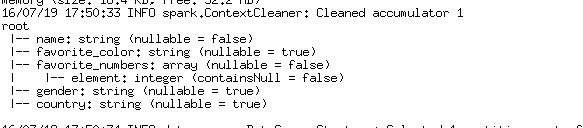
DataFrame df = sqlContext.read().parquet("hdfs://spark1:9000/spark-study/users/gender=male/country=US/users.parquet");
df.printSchema();
df.show();
}
}