

搭建模式规划
一共四台。分别为hostname rhel071,rhel072,rhel075,rhel076 模式为
rhel072 分片1 副本1
rhel075 分片1 副本2
rhel076 分片2 副本1
rhel079 分片2 副本2
1.首先四台机器分别要安装好单机版的clickhouse
2.四个分别修改配置文件/etc/metrika.xml
1).默认改文件再/etc/下也可以自行修改,密码这里由于是测试环境没进行加密,CH也有提供加密的方式
<?xml version="1.0" encoding="utf-8"?>
<yandex>
<clickhouse_remote_servers>
<mycluster>
<shard>
<!-- 其他副本从这个副本进行复制同步,而不是同时插入,false无法保证数据一致性 -->
<internal_replication>true</internal_replication>
<replica>
<host>rhel072</host>
<port>9954</port>
<user>user_richdm</user>
<password>richdm</password>
</replica>
<replica>
<host>rhel075</host>
<port>9954</port>
<user>user_richdm</user>
<password>richdm</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>rhel076</host>
<port>9954</port>
<user>user_richdm</user>
<password>richdm</password>
</replica>
<replica>
<host>rhel079</host>
<port>9954</port>
<user>user_richdm</user>
<password>richdm</password>
</replica>
</shard>
</mycluster>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>rhel072</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- 这里每个对应节点只放开一个 -->
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>rhel072</replica>
</macros>
<!--
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>rhel075</replica>
</macros>
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>rhel076</replica>
</macros>
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>rhel079</replica>
</macros>
-->
</yandex>
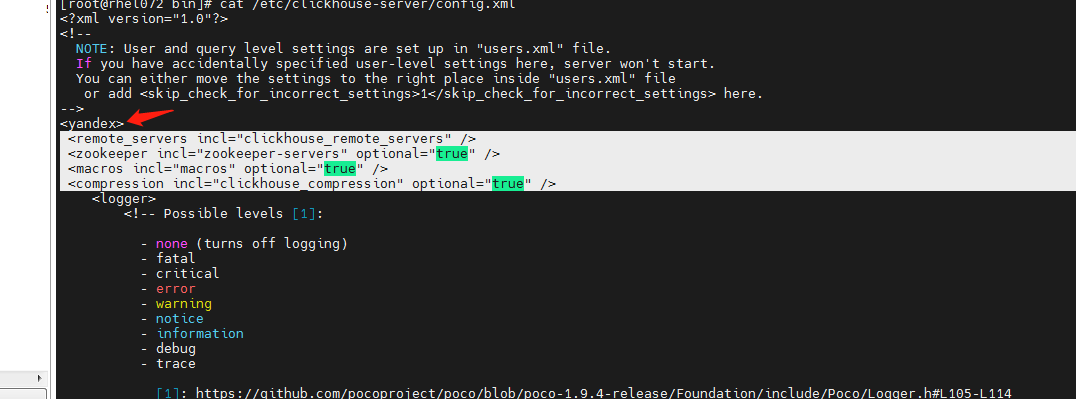
2)添加以下几行(旧版本好像不用,我用新版本如果不添加四个机器都是独立模式不能组成集群)
<remote_servers incl="clickhouse_remote_servers" /> <zookeeper incl="zookeeper-servers" optional="true" /> <macros incl="macros" optional="true" /> <compression incl="clickhouse_compression" optional="true" />
3)重启CH服务
重启服务
systemctl restart clickhouse-server.service
查看服务状态
systemctl status clickhouse-server.service
4)利用客户端连接进入命令行(端口,密码,用户名都可以自己进行配置,默认9000太容易冲突了python我们环境就用了9000)
clickhouse-client -h rhel075
5)制作测试表
1. 在所有节点执行如下语句:
创建本地复制表:
CREATE TABLE table_local on cluster mycluster
(EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/table_local', '{replica}')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID);
##('/clickhouse/tables/{layer}-{shard}/table_local', '{replica}') CH本地复制表插入时候会写入ZK数据,该路径为创建表时候ZK的存储数据路径。百万数据大概会往ZK写入十几条。
创建分布式表:
CREATE TABLE table_distributed as table_local ENGINE = Distributed(mycluster, default, table_local, rand());
1.本地复制表为把数据分别存在两个分片上。
2.存在副本的分片,副本节点宕机不会影响到数据的完整性
3.需要到哪个节点查询全部数据就在该节点创建分布式表,进行可以对全部本地复制表数据进行查询
