


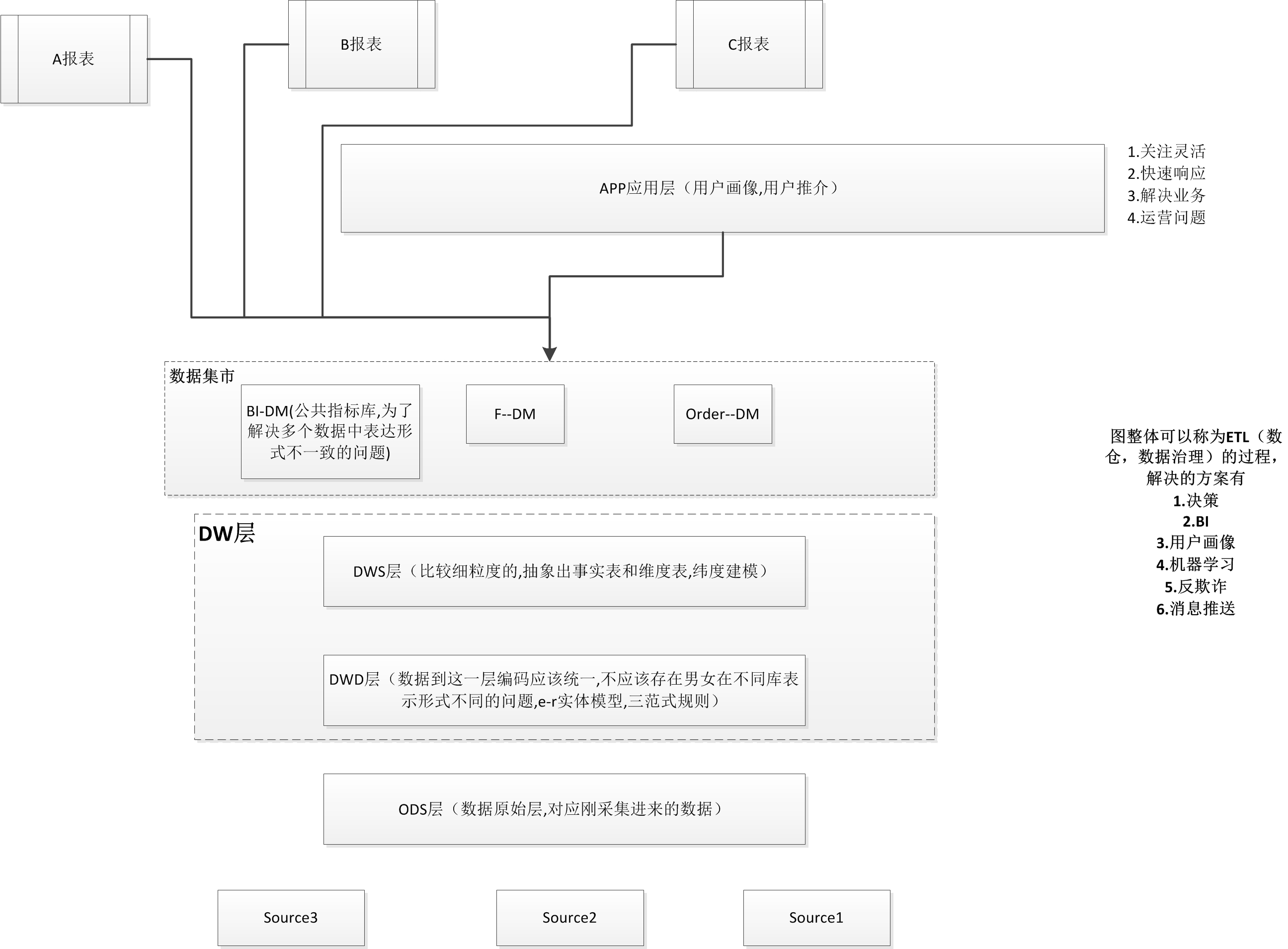
市面公司大多基础模型如图
数仓建模目标
1.访问性能-快速查询所需数据,减少IO,缩短统计路径
2.数据成本-减少不必要的数据冗余,实际计算结果数据复用,降低达数据系统中的存储成本和计算成本
3.使用效率-改善用户体验,提高使用数据率
4.数据质量-改善数据口径不一致性,减少计算错误的可能性,提供高质量的,一致的数据访问平台。
(这里我感觉数据仓库也属于为大数据计算提供便捷的一个设计或者产品吧)
大数据的数仓建摸需要通过建模的方法更好的组织,存储数据,一边在性能,成本,效率和数据质量之间找到最佳的平衡点
关系模式范式
目的:降低数据的冗余性达到数据一致性,涉及规范有
1.第一范式--表字段都应为原子性的,不可分割的
2.第二范式--实体的属性完全依赖于主键字段,不能存在依赖外键之类的字段(非主键)。(缺点:容易造成冗余,调整表字段时候造成大量列的修改,第二范式和第三范式容易混淆,比如联合ID的情况订单ID和产品ID,如果这时候加入产品name只依赖产品ID而不依赖订单id,设计上就会出错)
3.第三范式--消除传递依赖(传统数据库和数据仓库一般只做到第三范式)
4.巴斯-柯德范式(对第三范式的一个补充)
5.第四范式
6.第六范式
数据仓库建模基本理论模型(实体 eg:[商品,仓库,货位,汽车],属性 eg:[颜色,尺寸,重量,产地],关系表示数据之间的关系)
1.ER实体模型
2.维度建模
3.dataValue模型
4.Anchor(key-value)模型
关系:实体之间建立关系时,存在对照关系一般有:
1:1
1:n
n:m
梳理步骤一般为
1.找出实体,抽象出主体
2.梳理关系
3.梳理属性
4.画ER关系图
雪花,星型模型对比(只要纬度表下还有伸衍生出的纬度表,设计方式就是雪花模型,降纬会变成星型模型)
冗余:雪花模型符合业务逻辑设计,采用三范式设计,有效降低数据冗余;星型模型的纬度表设计不符合三范式,反而更规范化,纬度表之间不会直接相关,牺牲部分存储空间
性能:雪花模型由于存在纬度间的关联,采用三范式降低冗余,通常在使用过程中,需要连接更多的维度表,导致性能偏低;星型模型反三范式,采用降纬的操作将纬度整合,以存储空间为代价有效降低纬度表连接数,性能较雪花模型高
ETL难度:雪花模型符合业务ER模型设计原则,在ETL过程中相对简单,但是由于附属模型的限制,ETL任务并行化较低;
星型模型设计纬度时反范式设计,所以在ETL过程中整合业务数据到纬度表有一定难度,但是由于避免附属纬度,可并行化处理
总结:星型模型和雪花模型之间的转换其实是一个以空间换取时间的一个过程,降低了纬度增加了数据统计的数据的速度,但是增加了数据的人冗余,增加了存储的开销
hive优化层面:星型模型少的表可以减少job数,减少资源的开销.而且星型模型虽然数据冗余,但是只有一个文件,但是雪花模型虽然符合三范式,但是却是会产生多个文件,总体文件数的大小不一定比星星模型小
(一般优选星型模型)
事实表设计选择
单事件(单事务)事实表
对于每一个业务动作事件,设计一个事实表,仅记录该时间的实时以及状态
说明:更方便跟踪业务流程细节数据,针对特殊业务分析场景比较方便灵活,数据处理上也更加灵活;不方便的地方就是数仓中需要管理太多的事实表,同时跟踪业务流转不够直观
流程事实表
对于一个业务流程主体,设计一个事实表,跟踪整个流程的事实以及状态流转
说明:能够更直观的跟踪业务流转和当前状态,流程事实集中,方便大部分通用分析应用场景,由于和业务侧的数据模型设计思路一致,也是目前最常用的事实表设计;但是细节数据跟踪不到位,特殊场景的分析不够灵活
一般实际应用需要两种表结合使用
事实表设计方案
增量存储 (每天处理增量部分数据,针对状态无变化的数据比较适合)
全量快照(适合每天数据量不大场景)
保存策略:
1.如果存储空间成本可接受,完整存储,缺包能够追溯到历史每天数据状态
2.存储空间有限,考虑移动历史快照数据到冷盘,需要使用的时候可恢复
3.数据历史状态数据无太大价值,可以考虑部分删除,比如近保留每月最后一天的快照数据
拉链表 (数据量大,但缓慢变化,需要跟着历史状态,和缓慢渐变纬类似)
案例
credit_amount:card_id,user_id,amount,used_amount,create_time,updated_time
1.采集数据表-----> s_credit_amount
---query "select col_name from .... where updated_time >= '2018-06-01 00:00:00' " (sqoop采集过程记得要全部字段名写上,如果使用select * 后期容易造成别人更改表结构时候,万一从中间加字段出错)
2.dwd拉链表:d_credit_amount_1
drop table if exists tmp_credit_amount;
create table tmp_credit_amount as
select * from
(select
ta.card_id,
ta.user_id,
ta.amount,
ta.used_amount,
ta.created_time,
ta.updated_time
(case when tb.card_id is not null and ta.end_date > '2018-06-01' then '2018-05-31' else ta.end_date end)
--把发生变化的数据置为失效,比如数据
--id startdate enddate
--1 2018-11-12 2018-11-13
--1 2018-12-13 9999-12-31(需要把这条enddate给更改掉,修改为最新的结束时间‘今天的时间的前一天作为数据的失效时间’,后面合并会跟上最新的数据条目)
load time
d_credit_amount_1 as ta
left join
s_credit_amount as tb
on ta.card_id=tb.card_id
union all
select
ta.card_id,
ta.user_id,
ta.amount,
ta.used_amount,
ta.created_time,
ta.updated_time
'2018-06-01' as start_date,
'9999-12-31' as end_date
unix_timestamp() as load_time --用于方便排查问题
from
s_credit_amount)tmp
insert overwrite into d_credit_amount_1
select * from tmp_credit_amount; --第二天跑表任务会自动进行drop,所以数据保留一天方便排查问题
--------------------------基于全量快照数据做拉链表
dwd:d_credit_amount_d --->d_credit_amount_1
card_id,user_id,amount,used_amount,create_time,updated_time
1获取商日发生变化的数据(利用MD5不等或者为null都是新增数据)
select
ta.*
(select
ta.card_id,
ta.user_id,
ta.amount,
ta.used_amount,
ta.created_time,
ta.updated_time,
md5(concat(card_id,user_id,amount,used_amount,create_time)) as md5_flag
from d_credit_amount_d as ta where dt = '2018-06-01')ta
left join
(select
ta.card_id,
ta.user_id,
ta.amount,
ta.used_amount,
ta.created_time,
ta.updated_time,
md5(concat(card_id,user_id,amount,used_amount,create_time)) as md5_flag
from d_credit_amount_d as ta where dt = '2018-05-31')tb
on ta.card_id=tb.card_id
where ta.md5 != tb.md5 or tb.card_id is null
后面同上思路以后补上
