R数据分析实战学习笔记(3)
4.24 数据的导入

导入csv、txt及任意格式文件,都可以用read.csv()函数。
如果文件没有列名,当参数header=TRUE,则认为文件的第一行为列名;如果=FALSE,则会赋予表v1,v2,...列名;
如果文件有列名,当参数header=TRUE,则认为文件的第一行为列名;如果=FALSE,则会赋予表v1,v2,...列名。
通过sep指定分隔符。
通过参数stringAsFactor=FALSE 去除factor的属性,文件的各列属性默认为factor。
4.25

4.26 数据的导出

注:参数file表示保存的文件路径,包括路径和文件名。如G:\Rstudy\4.2\f.csv
data.frame() read.table() write.table() 要有fileEncoding和stringAsFactor参数。
4.27重复值处理

4.28 缺失值处理(NA)


na.omit():删除存在空值即NA 的行。
4.29空格值的处理(包括下载安装包的信息)

下载安装包时,如出现以下信息:

则使用
这是下载路径不同,网速会更快。
4.30字段抽取

4.31随机抽样

replace=TRUE 为放回抽样,=FALSE为不放回抽样。
4.32 记录合并
即:将两个结构相同的数据框,合并成一个数据框。

fix()函数:调用数据编辑器
4.33 字段合并
即:将同一个数据框中的不同列,进行合并,形成一个新的列。

4.34 字段匹配
即:不同结构的数据框,按照一定条件进行合并。按照共同字段进行一一匹配。


注:by.x by.y指的是进行匹配的列名,而不是该列的具体数据。
merge()相当于excel中的vlookup函数。
cbind()是单纯的将两个数据框按列合并,进行列扩展,不能保证一定匹配。
4.35 简单计算
即通过对字段进行简单的加减乘除四则运算,计算出想要的字段。
4.36 数据标准化

0-1标准化的好处是很容易进行10分制、百分制的标准化。
4.37 数据分组


4.38 日期转换

as.Date()函数也能将字符串格式的日期转化为数值型的日期。
4.39 日期格式化

注:字符串型日期转化为数值型,用as.POSIXlt() 或 as.Date()
数值型日期转化为指定格式的字符串型日期,用format()
4.40 日期抽取
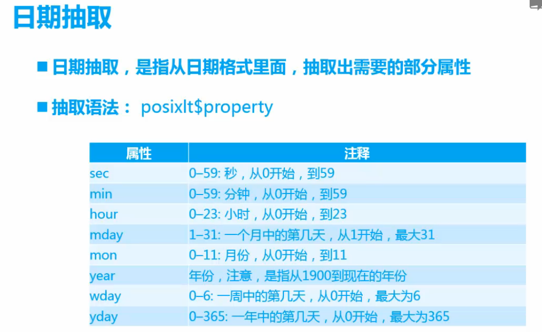
先用as.POSIXlt函数转化为日期型格式,然后再利用$符号提取。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号