R数据分析实战学习笔记(1)
2.6
和R“工作空间”概念相对应,Rstudio中有“项目”概念。
项目是软件工程中的概念,用于管理软件开发,可理解为源代码和相关文档的集合。
在Rstudio中的项目,可理解为一个文件夹,里面放着R的源代码、相关数据文件和R的工作空间。
如何创建项目,创建项目不是必须,但是一个好的习惯;
保存R文件,文件名以“.R”结尾,将文件保存到项目目录下;
执行命令,快捷键ctrl+enter;
3.7
变量:数据赋值的对象,通过变量来操作数据;
3.8
三种常用的数据类型:数值型、字符型、逻辑型;
logical逻辑型运算规则:与、或、非,& | !
在与运算中,两个逻辑值都为假,则结果为假;
3.9
numeric数值型:数学中的实数,包括负数、0、正数;
运算规则:加减乘除;
数值型和逻辑型间的转换:TRUE对应1,FALSE对应0

3.10
字符型与逻辑型、数值型间的转换:

3.11字符型高级技巧
使用到的函数:
nchar(),length(),chartr(),tolower(),toupper(),paste(),strsplit(),grep(),grepl(),sub(),gsub(),substr(),substring()
字符串的长度:
nchar():计算字符个数;
length():变量长度;
字符串的替换:
chartr(old,new,x):用新字符替换字符型变量x中的old字符;
字符串的大小写转换:
tolower(x);将字符型变量x全部转为小写;
toupper(x):将字符型变量x全部转为大写;
字符串的拼接:
paste(...,sep=""):字符串的拼接(可为任何数据类型,较短的向量被循环使用);


字符串的切割:
strsplit(x,split):字符串的切割,x必须为字符型(数值型和逻辑型不行),得到的结果是个list。当split参数的长度为0时,得到的结果是将x分割呈一个一个字符。
class():查看数据结构;

字符串的查找:
grep(,pattern,x)、grepl(pattern,x):返回pattern的匹配值。前者返回匹配项的下标,后者返回逻辑值,x长度是多少,就返回多少个逻辑值。如果在grep()中添加一个value参数,且赋值为T,则返回匹配项的值。

字符串的替换:
sub(pattern,replacement,x),gsub(pattern,replacement,x):返回用replacement替换匹配项后的x(字符型向量)。前者只替换向量中每个元素的第一个匹配值,后者替换全部匹配值。

字符串的截取:
substr(x,start,stop),substring(x,start,stop):表示从start开始到stop结尾的获取中间的字符串。由于start和stop有时是一个数字,有时是一个数值型向量。所以,substr只从start的第一个数开始,到stop的第一个数结束。substring是从start的各元素开始,到stop对应的各元素结束。

3.12
学习一类数据结构要学习数据结构的概念、定义、限制、查找、修改。
3.13 array 数组
array数组分为一维数组和多维数组。一维数组即为向量。
array函数的参数dim默认为1,定义的是向量。

增加的两种方法:
 动态增加:
动态增加:

修改:凡是能访问到的地方都可以修改
删除:凡是能访问到的地方都可以删除。

注:增加append()和删除 会赋值到一个新的变量,需要重新赋值给原变量来变更原变量。
查找/过滤:
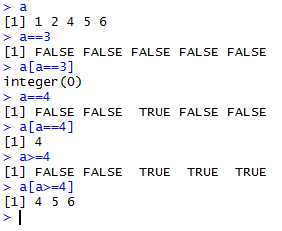
3.14 factor 因子
用来存储类别变量和有序变量,这类变量不是用来计算,而是用来分类或计数。
factor和ordered factor
用到的函数:factor() ordered() order() table() cut() getwd() setwd() read.table() read.csv()
读入csv文件:


factor作用一:统一映射为另一标签数据。
把第一列class变量转化为带有标签的因子:

factor作用二:排除异常值

注:通过levels参数指定因子的顺序
as.vector() as.numeric() 转化为字符向量和数值向量:
as.numeric函数得到的是因子的位置数字。

连续变量的离散化:

注:cut得到的是因子,table是对因子的各类别的频数统计
切成自己设计的组,则对breaks参数赋值为一个向量。
一个有序因子:

可排序的离散分类变量:
使用ordered函数得到一个有序因子,再使用order根据有序因子进行排序。


3.15 list 列表
带tag的列表相当于键值对, tag_name为元素名称即标签,index为元素索引。
list的访问:
list中元素(也就是值)的访问有三种方式:
list_name$tag_name
list_name[[tag_name]]
list_name[[index]]
list中包括元素名称和数值(也就是键值对)的访问:
list_name[tag_name] 或 list_name[index] 的结果是一个列表
获取标签的函数:labels()
list的修改:
赋值为NULL进行删除,删除后,它后面的索引位置自动减一。
3.16 data frame 数据框
数据框:data.frame(向量1,向量2,...)
如果列没有内容,列定义是不成功的,可以先给列赋值为NA。


查找:f[,1]
更改列名:使用names()函数
更改某一列的名:使用查找索引。

更改行名:row.names()函数
删除行、列,增加行、列:
f[-1,]
f[,-1]
f[nrow(f)+1,]<-c(...)
f[,"sex"]<-c(...)
在数据框中新增一列sex,有2中方法。一是f[,"sex"]<-c()或 f$sex<-c();一是f<-data.frame(f,sex)。
总结:
第一类:向量、矩阵、数组。向量是一维数组,矩阵是二维数组。各列必须是相同的数据类型。
第二类:数据框、列表。各列可以是不同的数据类型。查找元素用$ [,1]或[[名或索引]]
对于列表而言,当list的属性是变量时,只能用[],不能用$。list$key=list["key"] ,当key是变量时,只能写list[key]
第三类:因子


 浙公网安备 33010602011771号
浙公网安备 33010602011771号