SQL套题
我一直觉得这种SQL套题是自己明显的短板,之前海康的笔试也遇到了,这也可能是没能通过的一大原因
因为好像到目前为止,除了上《数据库原理》课的时候,其他时候基本都是写的非常简单的增删查改SQL
正文
题目如下:
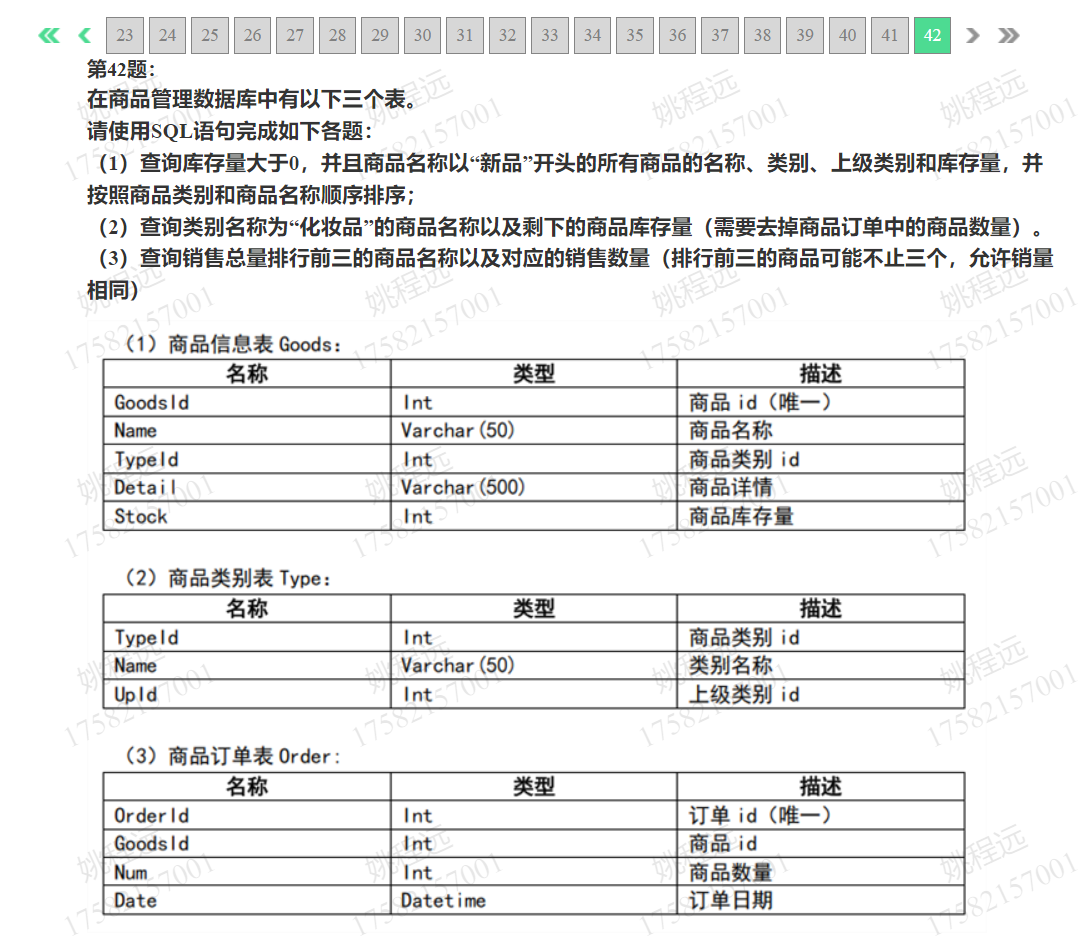
建表,准备素材
这里省去了goods表的detail字段,同时也省去了外键
先填type表字段
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for goods
-- ----------------------------
DROP TABLE IF EXISTS `goods`;
CREATE TABLE `goods` (
`GoodsLd` int NOT NULL,
`Name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`TypeId` int NULL DEFAULT NULL,
`Stock` int NULL DEFAULT NULL,
PRIMARY KEY (`GoodsLd`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of goods
-- ----------------------------
INSERT INTO `goods` VALUES (1, '大众S1', 3, 67);
INSERT INTO `goods` VALUES (2, '大众A7', 3, 32);
INSERT INTO `goods` VALUES (3, '丰田U2', 4, 12);
INSERT INTO `goods` VALUES (4, '铃木4', 5, 46);
INSERT INTO `goods` VALUES (5, '宝马Q4', 6, 43);
SET FOREIGN_KEY_CHECKS = 1;
-- ----------------------------
-- Table structure for order
-- ----------------------------
DROP TABLE IF EXISTS `order`;
CREATE TABLE `order` (
`OrderId` int NOT NULL,
`GoodsId` int NULL DEFAULT NULL,
`Num` int NULL DEFAULT NULL,
`Date` datetime NULL DEFAULT NULL,
PRIMARY KEY (`OrderId`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of order
-- ----------------------------
INSERT INTO `order` VALUES (1, 1, 13, NULL);
INSERT INTO `order` VALUES (2, 3, 4, NULL);
INSERT INTO `order` VALUES (3, 4, 10, NULL);
INSERT INTO `order` VALUES (4, 5, 36, NULL);
SET FOREIGN_KEY_CHECKS = 1;
-- ----------------------------
-- Table structure for type
-- ----------------------------
DROP TABLE IF EXISTS `type`;
CREATE TABLE `type` (
`TypeId` int NOT NULL,
`Name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`UpId` int NULL DEFAULT NULL,
PRIMARY KEY (`TypeId`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of type
-- ----------------------------
INSERT INTO `type` VALUES (1, '汽车', NULL);
INSERT INTO `type` VALUES (2, '摩托车', NULL);
INSERT INTO `type` VALUES (3, '大众', 1);
INSERT INTO `type` VALUES (4, '丰田', 1);
INSERT INTO `type` VALUES (5, '铃木', 2);
INSERT INTO `type` VALUES (6, '宝马', 2);
SET FOREIGN_KEY_CHECKS = 1;
开始干正事儿
- 第一问的难点在于上级类别
SELECT
a.`Name`,
Stock,
`类别`,
c.`name` AS '上级类别'
FROM
(
SELECT
goods.NAME,
Stock,
type.`Name` AS '类别',
UpId
FROM
goods,
type
WHERE
Stock > 0
AND goods.`Name` LIKE '新品%'
AND goods.TypeId = type.TypeId
) a
LEFT JOIN ( SELECT TypeId, NAME FROM type ) c ON c.TypeId = a.UpId
我们先做了一次查询,得到了需要的大部分数据,但是UpId并不是最终的数据,还得再去type表中查一次,而且是需要同时匹配多个数据,同时需要左表中所有的数据,所以这里用LEFT JOIN
另外UpId和TypeId这两个额外的关联字段是必须的
# 还可以先处理type表
SELECT
goods.`Name`,
Stock,
`类别`,
`上级类别`
FROM
goods,(
SELECT
a.`TypeId`,
a.`Name` AS '类别',
b.`Name` AS '上级类别'
FROM
type a
LEFT JOIN type b ON a.UpId = b.TypeId
) c
WHERE
Stock > 0
AND goods.`Name` LIKE '新品%'
AND goods.TypeId = c.TypeId
- 这里注意出现的问题是
这里
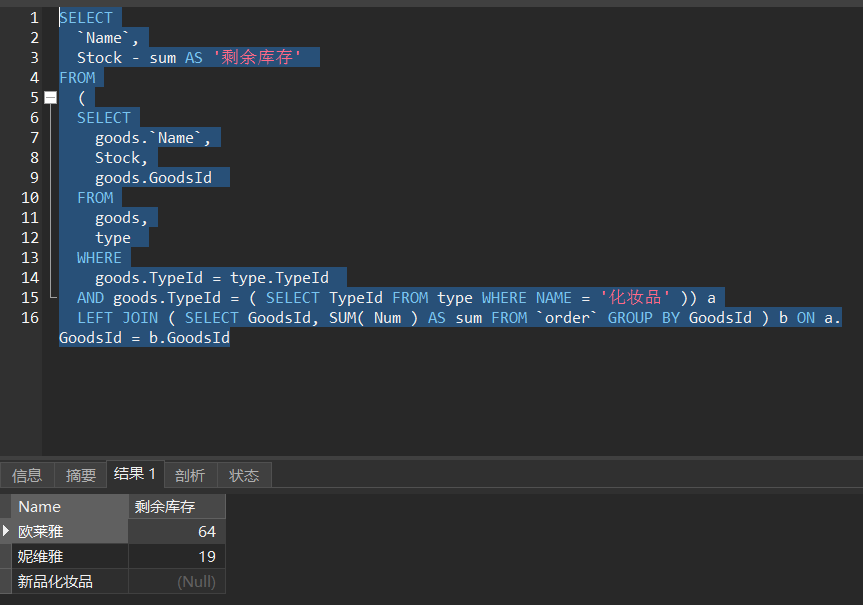
表1Stock有值,但是表2不存在对应项,导致

这里相减成了一个数减null,结果是null
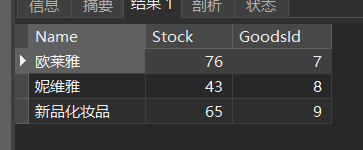
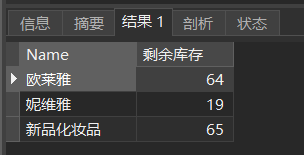
表1新品化妆品是有值的,但是表2没有这个记录
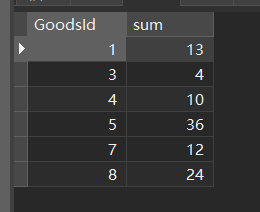
这里要用CASE WHEN配合ISNULL()解决
SELECT
`Name`,
( CASE WHEN ISNULL( sum ) THEN Stock ELSE Stock - sum END ) AS '剩余库存'
FROM
(
SELECT
goods.`Name`,
Stock,
goods.GoodsId
FROM
goods,
type
WHERE
goods.TypeId = type.TypeId
AND goods.TypeId = ( SELECT TypeId FROM type WHERE NAME = '化妆品' )) a
LEFT JOIN ( SELECT GoodsId, SUM( Num ) AS sum FROM `order` GROUP BY GoodsId ) b ON a.GoodsId = b.GoodsId
- 第三题的问题在于,查询前三,但是要求前三的数量可能不止3个
这里是涉及了排名函数
# 这么写的问题是查不出并列的情况
SELECT
`销售数量`,
b.`Name`
FROM
( SELECT GoodsId, SUM( Num ) AS '销售数量' FROM `order` GROUP BY GoodsId ORDER BY `销售数量` DESC LIMIT 3 ) a
LEFT JOIN goods b ON a.GoodsId = b.GoodsId
窗口函数
涉及到了不会的窗口函数,学习一下
这是我的原始数据
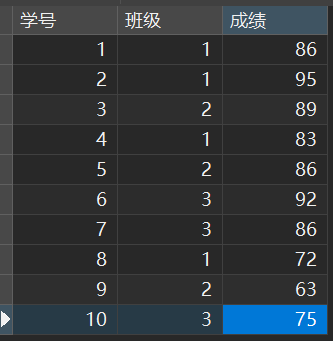
SELECT *,
RANK() over (ORDER BY 成绩 desc) as 'rank',
DENSE_RANK() over (ORDER BY 成绩 desc) as 'dense_rank',
ROW_NUMBER() over (ORDER BY 成绩 desc) as 'row_num'
from class;
结果
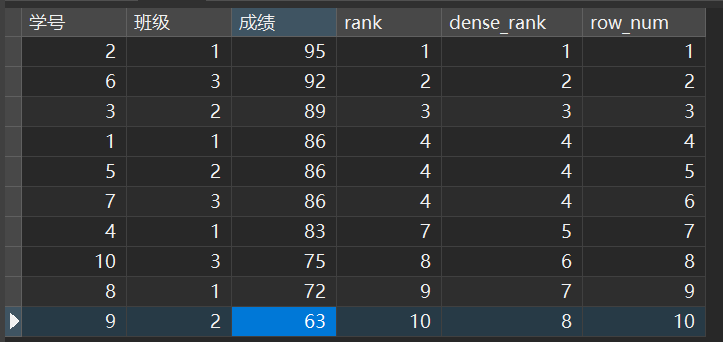
注意这里
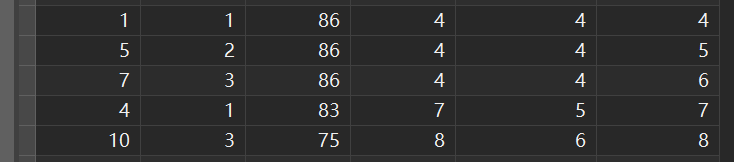
可以看到,能够相同成绩同一排名的是RANK()和DENSE_RANK()函数,区别是:
RANK()尽管排名相同,但是会占用后面的排名DENSE_RANK()排名相同,不占用后面的排名,接着排
那么如果考虑要分组呢?
添加partition by
select *,
rank() over (partition by 班级
order by 成绩 desc) as ranking
from 班级表
然后再回看这道题
先查出id和id对应的所有订单的总销量
原本是这么写的
SELECT GoodsId, SUM( Num ) AS '销售数量' FROM `order` GROUP BY GoodsId ORDER BY `销售数量` DESC
ORDER BY都可以改写,但是GROUP BY要保留
这里应该是RANK()和DENSE_RANK()都可以
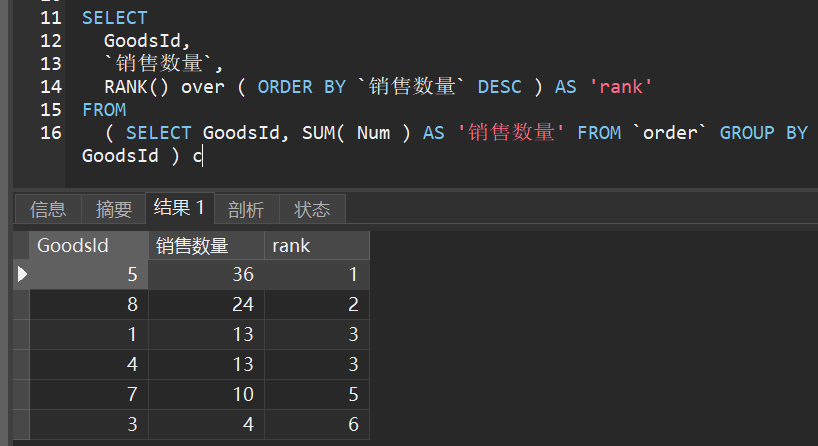
这样就排出来了
SELECT
GoodsId,
`销售数量`
FROM
(
SELECT
GoodsId,
`销售数量`,
RANK() over ( ORDER BY `销售数量` DESC ) AS '排名'
FROM
( SELECT GoodsId, SUM( Num ) AS '销售数量' FROM `order` GROUP BY GoodsId ) c
) a
WHERE
`排名` <4
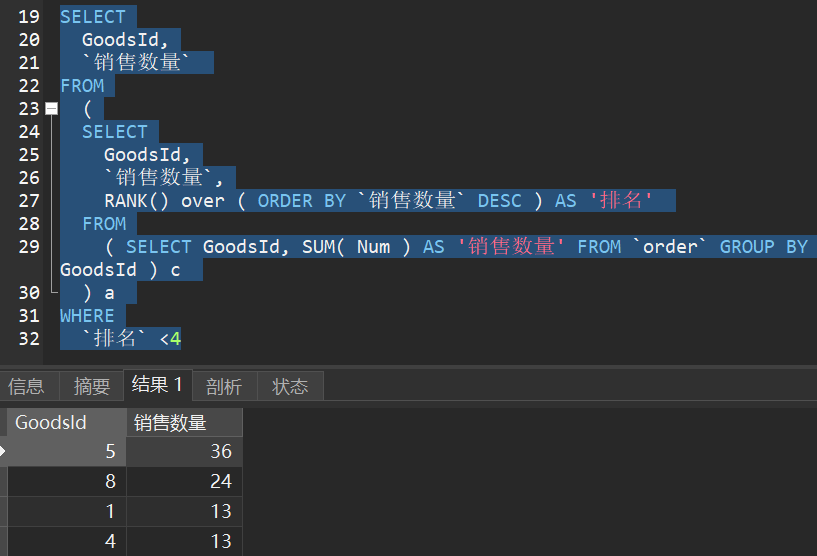
看起来可以说很不优雅了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号