快速排序
快排
快排是对冒泡的改进,采用分治策略
时间复杂度O(n log n),最好情况O(n log n),最坏情况退化为O(n2),空间复杂度O(log n)
基本步骤是:
- 从待排序列中选定一个“基准”
- 对序列进行“划分”,比“基准”大的元素放到其右边,比“基准”小的元素放到其左边
- 对“基准”左右两个子序列递归地进行划分
伪代码实现思路:
// 主函数,参数分别为:待排整型数组、数组长度、需要排序的序列起始和结束索引
void QuickSort(int data[],int length,int start,int end){
// 非法参数检查
// 进行第一次划分初始化“基准”的索引值
// 对左右两个子序列递归地进行划分,同样要检查非法参数(作为结束条件)
}
// 划分子函数,返回值为进行一次划分后“基准”的索引值(整型)
int Paritition(int data[],int length,int start,int end){
// 非法参数检查
// 初始化指定一个“基准”
// 对序列进行划分,比“基准”大的放其右边,小的放其左边
return pivot;
}
来自《剑指Offer》的实现代码(略改以保证能运行)
#include<algorithm>
#include<time.h>
#include<stdlib.h>
using namespace std;
int RandomInRange(int start, int end) {
// 加了能保证rand()每次运行都是一个不同的数
srand(time(NULL));
// 模运算与乘除同级
return rand() % (end - start + 1) + start;
}
int Paritition(int data[], int length, int start, int end) {
if (data == nullptr || length <= 0 || start < 0 || end >= length) {
throw new exception("Invalid Parameters");
}
int index = RandomInRange(start, end);
swap(data[index], data[end]);// 交换后end指向的就相当于是基准的值
int small = start - 1;
for (index = start; index < end; ++index) {
if (data[index] < data[end]) {
++small;
if (small != index) {
// 条件判断可写可不写,直接换就行
// 只是当两个指针相等时,下面的交换换了跟没换没区别
swap(data[small], data[index]);
}
}
}
++small;
swap(data[small], data[end]);
return small;
}
void QuickSort(int data[], int length, int start, int end) {
if (start == end) return;
int index = Paritition(data, length, start, end);
if (index > start) {
QuickSort(data, length, start, index - 1);
}
if (index < end) {
QuickSort(data, length, index + 1, end);
}
}
测试:
int main() {
int test[9] = { 5,2,8,3,6,4,9,7,1 };
QuickSort(test, 9, 0, 8);
for (int a : test) {
cout << a << " ";
}
}
输出:

代码过程解析
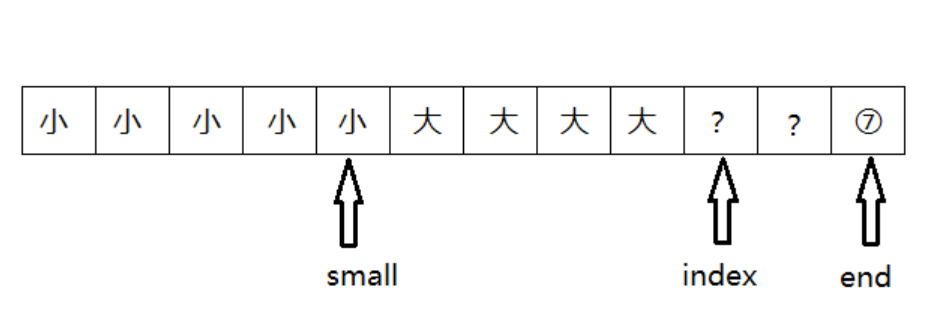
使用了双指针(同向)
- small:指向最后一个比基准小的元素
- index:用于遍历整个数组
small左边都是比基准小的元素,xmall和index中间都是比基准大的元素
关键的代码段解析
for(index = start;index<end;++index){
if(data[index]<data[end]){
++small;
if(small!=index){
swap(data[small],data[index]);
}}}// 这诡异的括号是为了省篇幅
index指针遍历整个数组,如果遇到比最后一个元素(基准)小的元素,small+1指向第一个比“基准”大的元素(两个指针指向同一元素例外,相当于初始化指向第一个(也是最后一个)比基准小的值),然后两个指针指向的元素值互换。
这样small指针就更新为指向了了最新(也是最后)一个比“基准”小的元素,原本第一个比“基准”大的元素位置则被换到了(比“基准”大的子数列的末尾)
如果遇到比最后一个元素(基准)大的元素,跳过循环,small不变,index指向下一个,这样比“基准”大的元素就夹在两个指针之间了
++small;
swap(data[small],data[end]);
当遍历结束后,small仍然指向前端比“基准”小的子序列的最后一个,++small则指向了第一个比“基准”大的元素
交换则small的位置不变,指向的值变为“基准”的值。
因为被换到末尾的值仍然比“基准”大,那么现在的数组就是划分完成的样子:small指向的基准左边都比基准小,右边都比基准大

 浙公网安备 33010602011771号
浙公网安备 33010602011771号