
分布式本地缓存
技术选型理由
Etcd
- Zookeeper 和Etcd 都是业界优秀的分布式协调系统,解决了分布式系统协调和元数据存储。etcd 参考了 ZooKeeper 的设计和实现经验,并从 Zookeeper 中汲取的经验教训用于优化自身架构,从而帮助其支持 Kubernetes 等大型系统。
- 解决服务发现,保证元数据变更后对集群中的每个实例的本地缓存进行更新
- 技术创新,使用业界认可的中间件,保持技术先进性。使用成熟后可覆盖其他业务场景。
Guava cache
业界和本部门很多应用都比较常用,基于jvm的内存缓存,适用于以下场景:
- 愿意消耗一些内存空间来提升读性能
- 键值会多次被查询
- 内存适用总量不会超过jvm内容容量
对于分布式协调的应用场景没有用redis、ducc、jmq因为这些中间件的应用场景的优势不在于此。
改造一:业务数据本地缓存化,并通过分布式数据库解决元数据一致性
目的
- 当前数据查询先走redis缓存,为提高服务器利用率,遇突发流量时可以减少redis单分片的压力
- 两级缓存提高服务稳定性
- 解决数据在集群环境下的一致性,保证每个jvm内存中的数据一致
影响范围
大促核心接口:
- xxx.checkSkuId,预估数据量10w条 (MaximumSize)10MB,最终按照压测情况调优。
PopWareDetailService.PC/M 样式接口,但由于数据内容较大,如果要做缓存,数据量要线上实际去观测一下,建议只做热点。
业务流程

第一步:业务场景下,数据的新增与更新会触发入库(mysql/mongodb)和redis,本方案会新增写入etcd集群。写入规则是根节点(系统名)/子节点(业务名)/叶子节点(业务key)
第二步:每个应用客户端docker节点订阅etcd集群业务目录,业务目录下的key值变更都会监听到
第三步:监听到有变化的key会将数据同步到基于guava cache实现的本地缓存中
第四步:当业务代码被访问时先从本地缓存中获取数据,本地缓存是有数据的
第五步:如果本地缓存没有数据(或者应用被重启)通过第6步回源到redis获取数据,并回写到本地缓存中。数据有变更时会通过1,2,3步骤完成本地缓存的更新
第七步:监控服务负责Etcd集群监控,另外再用mdc系统监控
第八步:开源应用,查看Etcd节点和叶子节点数据
使用 对内存的管理:
- 缓存淘汰策略:LRU,最近最少使用策略,无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。策略算法主要比较元素最近一次被get使用时间。在热点数据场景下较适用,优先保证热点数据的有效性
- 提供统计接口:缓存命中率、缓存条数
- 清理缓存接口:key、keys、all
业务规则
- etcd集群,一主两从,预发环境2c4g,生产环境4c8g
- etcd集群监控,
- 现阶段通过mdc进行服务器性能监控(cpu、内存、磁盘、连通性等)
- 搭建新应用来对集群健康进行监控,通过etcd提供http接口来获取,结合ump进行监控,暂不进行监控数据的持久化
- 为XX.checkSkuId设置本地缓存优先读取,如果没查到回源到jimdb
- ducc参数与开关配置:
- 是否优先读取本地缓存开关
- guava cache初始化配置,包括:缓存条数
- 本地缓存运维查询接口:查询key,删除key/ALL,缓存命中率
- etcd SDK开发,包括功能put、get、del、watch
改造二:对缓存穿透、热key、异常量、限流 4种数据上报,通过服务端计算进行结果的同步
目的
- 对null key进行计算,达到阈值则同步到集群的各客户端jvm内存,解决缓存穿透
- 对热key进行秒级的计算,达到阈值则同步到集群的各客户端jvm内存,防止redis单片过热
- 对调用的上游业务接口异常量进行计算,达到阈值则同步到集群的各客户端jvm内存,进行业务熔断
影响范围
- PopWareDetailService.PC/M 样式接口(nullkey、热key)
- 工作台保存业务中的多个上游接口(熔断)
业务流程
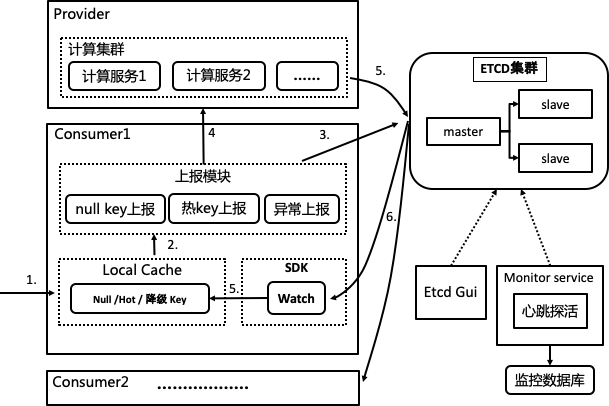
第一步,请求进入客户端,从本地缓存读取业务key数据进行业务流程判断,是否空值,是否被限流、是否被降级
第二步,客户端根据业务需求调用上报SDK模块,进行null key的上报、调用上报、接口调用异常上报
第三步,计算集群上报心跳到etcd集群,SDK模块从etcd获取计算服务IP集合,实现服务发现
第四步,将业务key进行hash取模,再将上报请求固定在一台计算服务机器上进行计算。基于netty建立长链接,提高TPS
第五步,将符合阈值(ducc)的计算结果put到etcd集群的业务目录/业务key。Sentinel、Resilience4j
第六步,客户端对业务目录/业务key进行订阅,监听程序进行数据同步,并更新到每个客户端jvm内存
业务规则
- 先完成方案一的技术搭建
- 上报模块SDK开发(空key、异常量、热key),数据上报通信模块客户端开发
- 计算服务端开发(计算模块),数据上报通信模块服务端开发
- ducc参数与开关配置:
- 上报数据计算阈值配置
- 上报开关配置
- 是否优先读取本地缓存配置
改造三:商品介绍数据Etcd兜底(探讨,结论:不适合)
目的
- 为商品介绍数据寻找一个兜底数据库,并且能100%负载大促流量和性能指标的数据库
影响范围
大促核心接口:SkuDecCheckService.checkWareIdDecInfo、PopWareDetailService.获取样式接口
业务流程
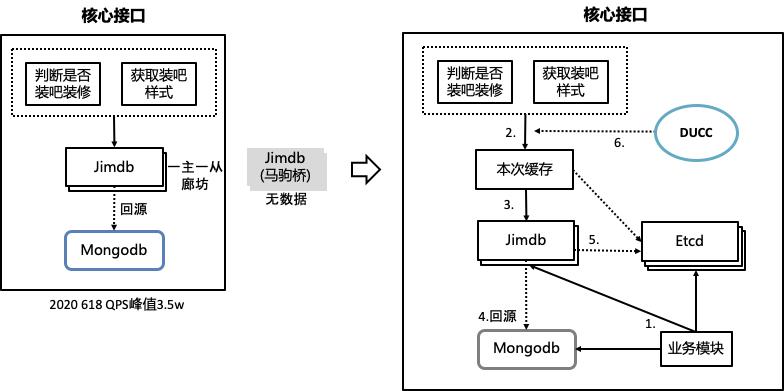
原有架构,核心接口中读数据由jimdb硬抗。改造后
第一步,业务模块会进行三写,jimdb+etcd+mongodb。
第二步,数据请求先访问本地缓存
第三步,本地缓存没有查询jimdb
第四步,jimdb没有数据回源查询mongodb
第五步,jimdb异常从etcd查询
第六步,ducc作为查询jimdb还是etcd的手动开关
目前jimdb资源占用内存130G,8分片,峰值操作6.7w次。建议Etcd集群指标 QPS 8w、硬盘300G。
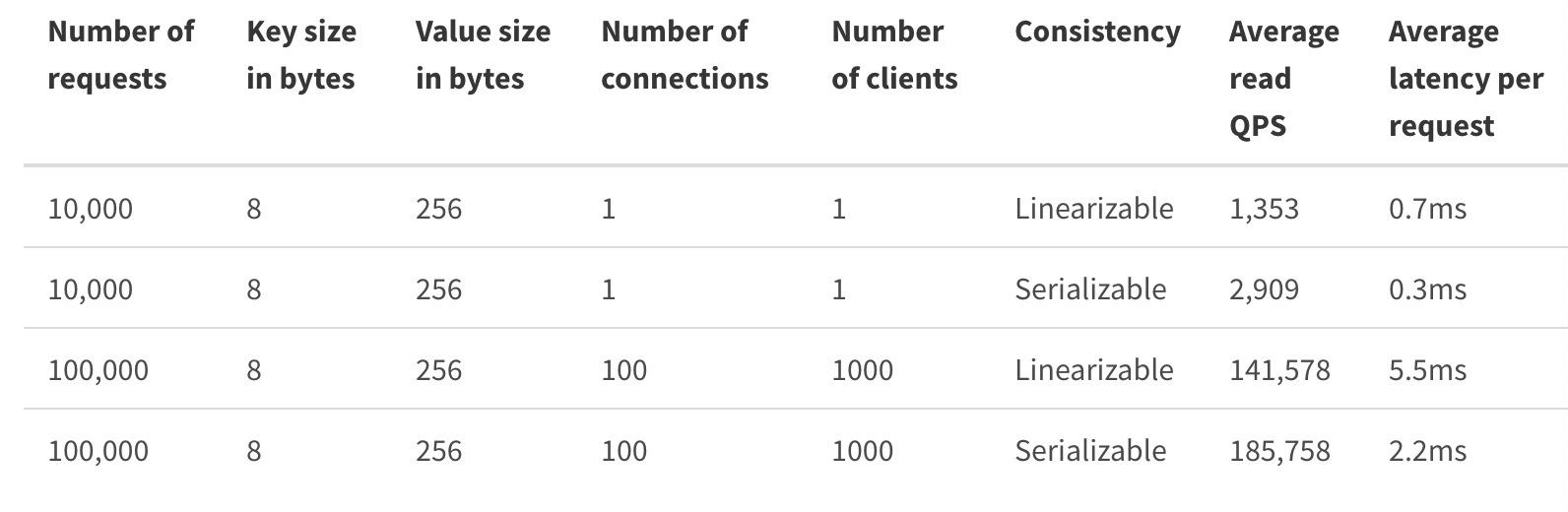
以下是官方的性能参考:

集群部署策略:
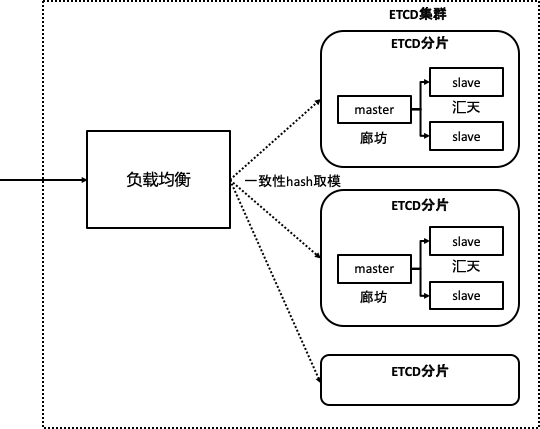
- 集群磁盘容量不足,分片存储
- 提高QPS
- 数据分摊,单点故障也能提供有损服务
兜底数据可以考虑使用es。oss
Etcd运维
- etcd搭建(集群) etcd + (nginx/HAProxy) 高可用部署方案
- etcd服务监控(集群健康情况监控告警、新增节点、移除节点、单点故障与恢复)
- etcd方案权限控制(保证开发环境与生产环境的隔离)
- etcd重启与数据恢复
- etcd磁盘打满解决方案
其他
发布过的sku数量:27874618(未去重)
不进行全量数据的本地缓存(虽然全量数据不多),因为历史数据可能就没有访问量,存入本地缓存浪费资源。
对非热点数据不进行本地缓存数据一致性处理,比如场景:容器A接收到请求写入本地缓存key1后,不将key1同步到容器B、C。
压缩样式内容字符串,提高缓存数量
其他:当前业务没有限流的需求,但基于这样的架构限流也能做
待确认
1、etcd的集群申请
2、实时计算服务的选型可以考虑kafka,kafka性能:单个Consumer每秒可消费三百万条消息,单个Producer每秒可成功发送一百多万条消息
3、灾备建议使用jimdb成本较低
4、watch的延时问题,需要通过测试来验证
1、愿意消耗一些内存空间来提升读性能
2、键值会多次被查询
3、内存适用总量不会超过jvm内容容量
