第二次结对编程作业
链接
结对同学的博客链接
本作业博客的链接
Github项目地址
前端展示:登录界面、输入框
前端展示:主菜单、排行榜、历史记录、开始&重新开始牌局、战局状态情况、注销登录
具体分工
邓泽源主要负责代码的编码部分
姚彬锟主要负责博客的撰写、代码的分析测试。
PSP表格
| PSP2.1 | Personal Software Process Stages |
预估耗时(min) | 实际耗时(min) |
|---|---|---|---|
| Planning | 计划 | 50 | 40 |
| Estimate | 估计这个任务需要多少时间 | 50 | 40 |
| Development | 开发 | 1610 | 1920 |
| Analysis | 需求分析 (包括学习新技术) |
600 | 750 |
| Design Spec | 生成设计文档 | 60 | 50 |
| Design Review | 设计复审 | 60 | 50 |
| Coding Standard | 代码规范 (为开发制定合适的规范) |
30 | 30 |
| Design | 具体设计 | 200 | 200 |
| Coding | 具体编码 | 500 | 570 |
| Code Review | 代码复审 | 80 | 70 |
| Test | 测试 (自我测试,修改,提交修改) |
180 | 200 |
| Reporting | 报告 | 135 | 150 |
| Test Report | 测试报告 | 45 | 60 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan |
事后总结 并提出过程改进计划 |
60 | 60 |
| 合计 | 1795 | 2110 |
解题思路描述与设计实现说明
总体思路(后端)
一拿到这道题,我的内心第一反应是头大(绝望)因为没打过十三水,规则不懂,又复杂,但后来静下心来思考了一下(脑内口嗨了一下),有3种做法:
1.0 纯贪心算法:
先从13张内,挑出最大的5张牌作为后墩,然后剩下的8张牌,挑出5张最大的作为中墩,剩下3张作为前墩.
2.0 搜索+判断比对权值算法:
这个算法是我一开始就想到的,13张牌一共有13!(13 x 12 x 11 x……1)种排列方式,那我们把所有的排列方式储存起来,然后前3张就是前墩,中5张就是中墩,最后就是后墩,接着,对每种排列的前中后墩判断一下,看一下他是哪一种牌型,给每种牌设定一个权值,计算一下他的权值总和,那么,13!种排列中权值最大的就是赢面最大的。后面又经过 兴源和海东大佬的启发提醒,发现不需要找出全排列,只需要挑出C13 5 x C8 5 x C3 3 的组合就行,于是只有7万多种组合,大大减小了算法时间复杂度.
3.0 搜索+权值细化+引入胜率概念
权值细化就是在2.0的版本上,引入同级别牌型的比较,例如:前墩 A A 9> 7 5 3,中墩 3 3 3 5 5<4 4 4 6 6,每种牌型细化级别内的权值,而不是简单地判断一下牌.胜率概念:这个东西我考虑了很久……因为一直觉得这个搜索算法不够智能,终于在某天早起惊醒(闹钟震醒)的时候,想到如果13张牌能排出多种组合,且组合的权值和都差不多,比如排法1是级别1,级别3,级别7,排法2是级别1,级别2,级别8,双方权值和都是1+3+7=1+2+8,就算引入权值细化,可能也不知道应该选啥(当然这个时候我觉得也是 人 也应该纠结的点)因此引入胜率:也就是根据每个牌型在每一墩的具体能打败x%的牌型作为他的胜率,例如:AA在前墩能击败98%的牌型,AA在中墩,只能击败10%的牌型,于是就能根据概率论分布计算出他的胜率。
这时候再来看上面的牌型,级别1,3,7虽然看起来和1,2,8差不多,但是我3->2,胜率下降了10%,但是7->8因为7的牌型占比后墩比例很高,提升到级别8,一下胜率提高了30%,那么很明显我选后者。经过概率论计算,如下

算法的步骤如下图所示:
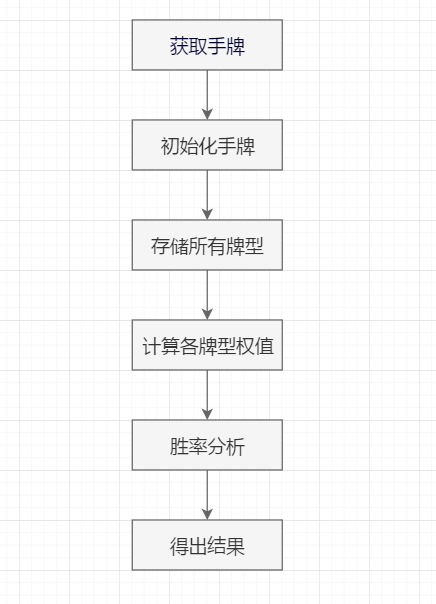
权值与各牌型分析
为了方便,做了一张权值与比对表图如下(放大查看清晰大图)
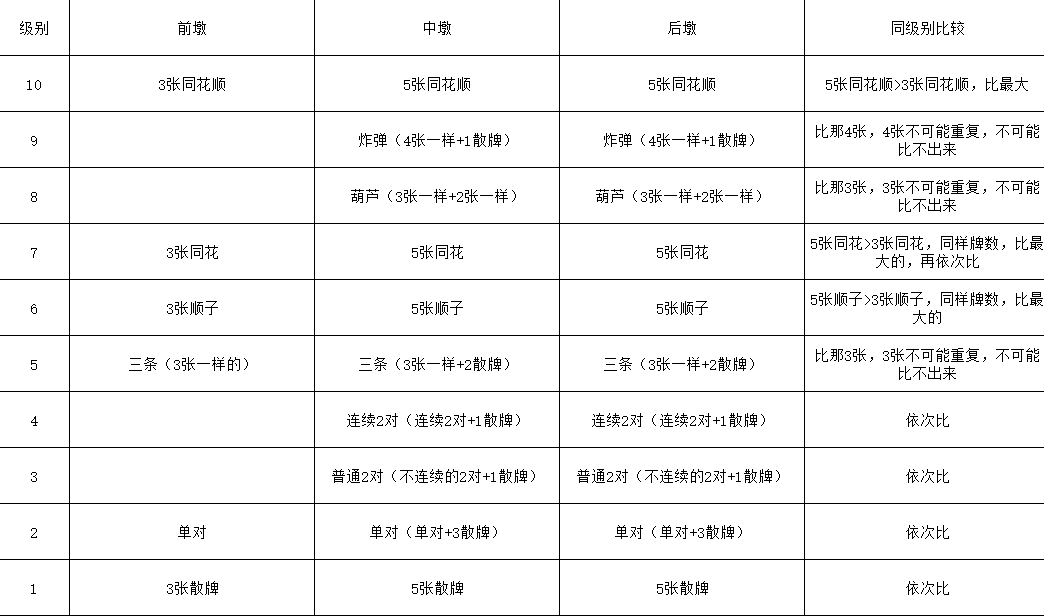
算法关键与版本对比
这个算法的关键就是上面提到的暴力搜索+权值细化

相对比2.0和3.0,1.0一个最大的优点就是在PY下跑的快(python的运行效率真是让人发指),至于对战应该是没有2.0和3.0来的智能的;
而2.0胜率版本因为前墩的重要性,很有可能某些时候会出现极端保前墩的情况,根据和兴源大佬的比对 我让胜率》50%的时候使用这个,
其余时候按3.0版本的权值细化版本来。
网络接口的使用
api请求使用的是python里的requests库
以开起牌局post和验证get token为例
def opengame():
global token,id
url = "https://api.shisanshui.rtxux.xyz/game/open"
headers = {"X-Auth-Token": token}
response = requests.post(url, headers=headers)
message=response.json()
id=message["data"]["id"]
card=message["data"]["card"]
print(response.text)
return card
def login_check():
global token
url = "https://api.shisanshui.rtxux.xyz/auth/validate"
headers = {"X-Auth-Token": token}
response = requests.get(url,headers=headers)
print(response.text)
代码组织与内部实现设计(类图)
| 变量模块 | 功能 |
|---|---|
| poker_1,poker_2,poker_3 | 扑克牌分堆 |
| ans_1,ans_2,ans_3 | 暂时寄存排列答案 |
| temp_1,temp_2,temp_3 | 存放完整排列答案 |
| end_1,end_2,end_3 | 最终答案 |
| s1,s2,s3 | 标记 |
| flower | 花色 |
| num | 牌号 |
| token,id,use | token,牌局ID,用户ID |
我们只有一个类,各方法的内部实现关系如下图所示:
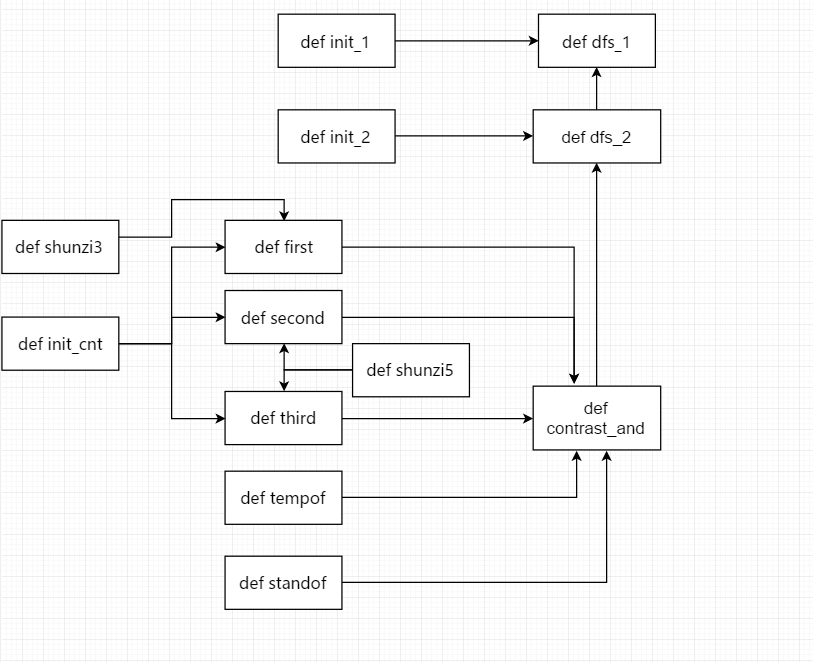
总体思路(前端)
没错=-= 我这个憨批 又来了
其实我把上面3个版本的后端都写了一下,1.0用的而是C++,2.0用的是Java,因为一开始是想开发web端,
但是因为前端原因又转了python,于是3.0就用python实现了,
网上搜寻了一下python的图形化界面,

最终,根据3.0版本的后端,用python的游戏模块图形化工具pygame写了前端界面进行联动
PS:前端其实还好,主要是麻烦,还有联动问题,但是用pygame和python后端联动可以直接封装调用,会舒服一点
使用的pygame主要涉及模块与函数
| 变量模块 | 功能 |
|---|---|
| pygame.cdrom | 访问光驱 |
| pygame.cursors | 加载光标 |
| pygame.display | 访问显示设备 |
| pygame.draw | 绘制形状、线和点 |
| pygame.event | 管理事件 |
| pygame.font | 使用字体 |
| pygame.image | 加载和存储图片 |
| pygame.joystick | 使用游戏手柄或者类似的东西 |
| pygame.key | 读取键盘按键 |
| pygame.mixer | 声音 |
| pygame.mouse | 鼠标 |
| pygame.movie | 播放视频 |
| pygame.music | 播放音频 |
| pygame.overlay | 访问高级视频叠加 |
| pygame.rect | 管理矩形区域 |
| pygame.scrap | 本地剪贴板访问 |
| pygame.sndarray | 操作声音数据 |
| pygame.sprite | 操作移动图像 |
| pygame.surface | 管理图像和屏幕 |
| pygame.surfarray | 管理点阵图像数据 |
| pygame.time | 管理时间和帧信息 |
| pygame.transform | 缩放和移动图像 |
前端展示
登录界面、输入框

主菜单、排行榜、历史记录、开始&重新开始牌局、战局状态情况、注销登录

关键代码解释
暴力搜索:
13张牌,挑出5张,然后把剩下的8张牌再放入组合搜索函数嵌套搜索,最后3张就不用搜了
def dfs_1(d, index_1): #/ * 枚举组合 * /
for i in range(d,13+1):
s1[i] = 1#标记,防止重复拿取
temp_1[index_1] = poker_1[i]#挑选
if index_1 == r1 :#r1=5,挑选够5张进入下一个dfs_2()函数,架构与dfs_1一样
init_1()#初始化dfs_2()函数,清空等操作
dfs_2(1, 1)
else:
dfs_1(i + 1, index_1 + 1)
s1[i] = 0
统计花色与牌号:
统计牌型用桶排序,dict用于统计花色和牌号,list用于储存牌组结构体
for i in range(1,3+1):
hua[ans_3[i].flower] +=1
number[ans_3[i].num]+=1
权值判断与细化:
以前墩部分牌型为例,总细化权值=细化权值 x 细化级别
for i in range(1,4+1):
if hua[i] == 3:
if shunzi3(ans_3[1].num) == 1:
k=(9.0+0.9 / 11.0 * (ans_3[1].num - 1))
score += k
return k # 3张同花顺
for i in range(3,0,-1):
if number[ans_3[i].num] == 1:
x = ans_3[i].num
if number[ans_3[i].num] == 2:
k=(1.0 + 0.9/(130+13)*((ans_3[i].num - 1)*10+x-1)*1.0)
score += k
return k#单对
k=0.9 / (1300.0 + 130.0 + 13.0)*((ans_3[3].num - 1) * 100 + (ans_3[2].num - 1) * 10 + (ans_3[1].num - 1))
score += k
return k #散牌
性能分析与改进
-
改进的思路
一开始的时候由于用python写速度会比较慢一些,运行时间到了10几秒
经过性能分析,发现在每次抓组合数时候的桶排dict_init()还有constrast()判断函数消耗了很大一部分的时间,于是进行了优化,
最后成功让算法的性能有所提高,达到了5-6秒钟作业。 -
性能分析图和程序中消耗最大的函数
性能分析图如下所示消耗最大的函数是Second,就是计算中墩的函数。
改进后,发现在判断连对和炸弹等嵌套情况可以暂时储存数据,
同时按牌数循环,将原有的O(n3)复杂度降到了O(n2),大大减少了中墩和后墩消耗的时间
最后进行了搜索剪枝优化,将原有的一次耗时8-9秒降低80%,完成了1秒内出答案
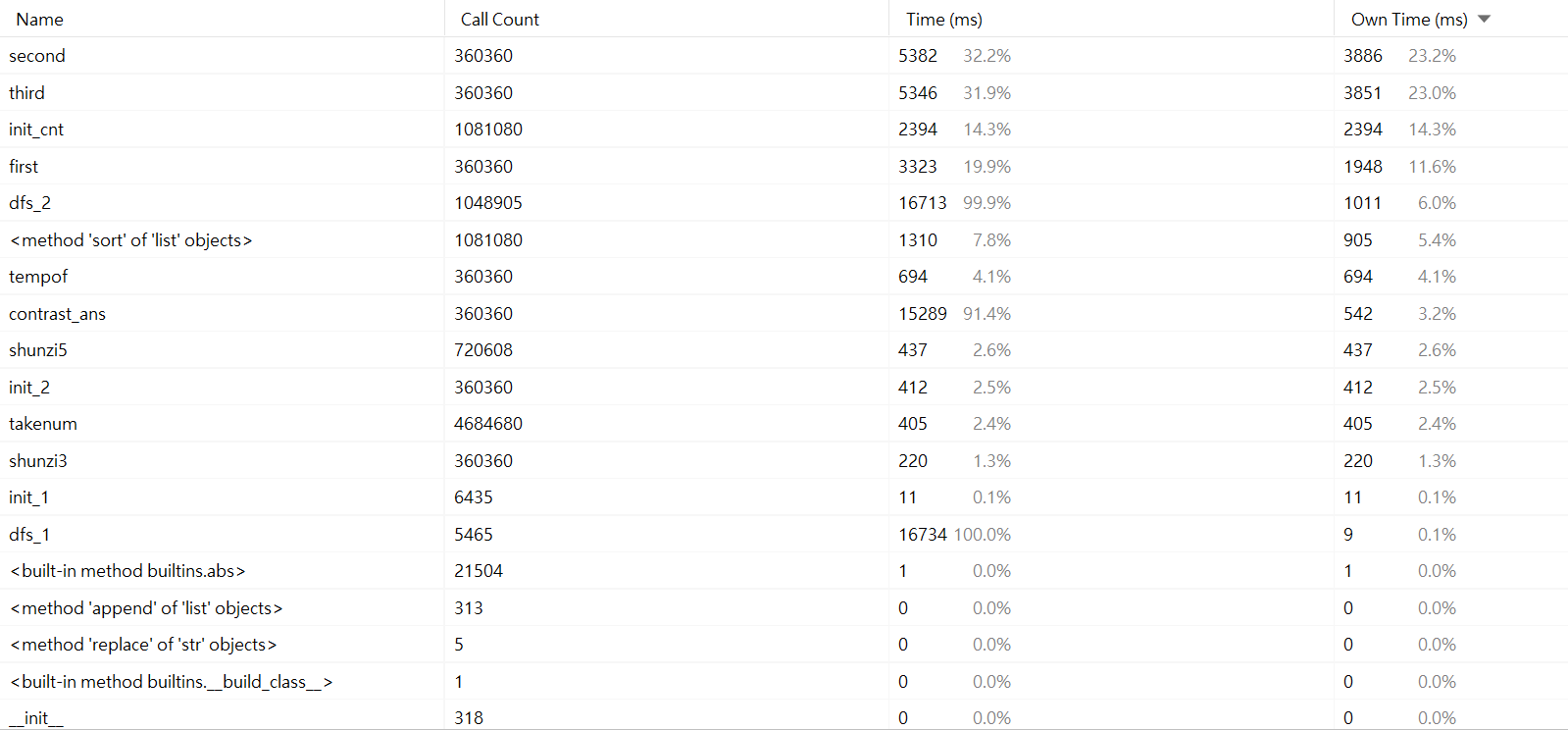
单元测试
单元测试这部分我们测试主要对三个函数进行测试,其他函数因为功能十分简单,所以就没有进行测试。测试的三个函数分别是得到前墩、中墩、后墩的三个函数,由于结构基本一样,只有变量的改变,所以只给出一部分的代码。各测试数据都是在手机app“大头十三水”读出的数据,然后为了提高一些代码的覆盖,我们尽可能的挑选了不同的数据进行测试,尽可能的覆盖更多的代码分支。而且由于前墩中墩后墩的结果会互相影响,即前墩挑出后要先把前墩的牌剔除再放入中墩函数进行计算,所以中墩的测试数据是在手动剔除前墩的基础上得到的,后墩同理。最后得出的结果与我们设计的算法的思路是一致的。
覆盖率:

class MyTestCase(unittest.TestCase):
def testfirst(self):
weig0 = 10
weig1 = 7
weig2 = 6
self.assertEqual(shisanshui.first(str0), weig0)
self.assertEqual(shisanshui.first(str1), weig1)
self.assertEqual(shisanshui.first(str2), weig2)
def testsecond(self):
weig0 = 10
weig1 = 9
weig2 = 8
self.assertEqual(shisanshui.second(str0), weig0)
self.assertEqual(shisanshui.second(str1), weig1)
self.assertEqual(shisanshui.second(str2), weig2)
def testthird(self):
weig0 = 10
weig1 = 9
weig2 = 8
self.assertEqual(shisanshui.second(str0), weig0)
self.assertEqual(shisanshui.second(str1), weig1)
self.assertEqual(shisanshui.second(str2), weig2)
Github的代码签入记录

遇到的代码模块异常或结对困难及解决方法
- 问题描述
前端这一部分的编写。
结对沟通的问题。
除了算法其实都有问题,之前没有做过一个稍微完整的项目,所以很多东西都没有学过,也没有这方面的知识。
python性能太慢,每一次抓取循环需要8-9秒 - 做过哪些尝试
因为刚开始讨论的时候算法用C++来写,而前端决定用python写,后来听到有人说什么python写出来的前端会有问题,导致进度一度拖着……后面dzy强势肝完了这些问题,把C++转成java又转python,学习pygame、pyqt…学的东西真的多。
结对问题就用聊天工具,就差聊出火花了。
对没有学习的东西,只能靠搜索引擎和B站了。
对搜索算法进行了剪枝,优化80%以上,只需要1秒便能得到答案 - 是否解决
都解决了都解决了,没解决就写不出这个博客了… - 有何收获
感受就是速成太难受了,计算机的世界太复杂。
原来为了学习也能够聊出火花。
再次强调,搜索引擎是个好东西。
评价你的队友
- 值得学习的地方
学习主动性强,认真负责,讨论时比较积极 - 需要改进的地方
短期内学习内容太广了以致于都只是了解,没有很深入学习
学习进度条
|第N周|新增代码(行)|累计代(行)|本周学习耗时(小时)|累计学习耗时(小时)|重要成长|
| :------: | :------: | :------: | :-----: |
|1 | 100 | 100 | 5 | 5| 学习了Axure RP的基本使用|
|2 | 300 | 400 | 10 | 15 |学习了JAVA的常用语法与mySQL数据库的基本操作|
|3 | 800 | 1300 | 15 | 30 |学习了python接口的使用|
|4 | 300 | 1500 | 10 | 40 |学习了pyqt和pygame的使用|
参考资料
北京-宏哥 的:python接口自动化(八)--发送post请求的接口(详解):https://www.cnblogs.com/du-hong/p/10559603.html
AI迟到的人 的:Python爬虫—requests库get和post方法使用:https://www.imooc.com/article/48845?block_id=tuijian_wz
luckycyong 的:Python之pygame,从入门到精通-系列:https://blog.csdn.net/qq_38526635/article/details/82688786
Despacito_lgq 的:解决PyCharm下载Python第三方库时速度慢的问题:https://blog.csdn.net/weixin_42128329/article/details/100005642
幽蓝丶流月 的:教你用Python写界面:https://blog.csdn.net/qq_37482202/article/details/84201259
YangDxg 的:Python使用API(Request):https://www.jianshu.com/p/40382f6d5e35
Python 基础教程与语法:https://www.runoob.com/python/python-tutorial.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号