站在浏览器角度谈前端优化
了解一个网址转变到一个网页的过程中浏览器做的工作,有助于我们的优化工作,使网址达到一个极优的速度。
与服务器建立连接,发起请求拿到资源
1.用户输入url并敲击回车
2.浏览器缓存查看
强缓存:浏览器会先获取该资源的Header信息,根据其中的exoires和cahe-control是否命中强缓存,如果有直接使用自身的缓存不发送请求。
协商缓存:如果没有命中强缓存,浏览器会发送请求到服务器,该请求会携带第一次请求返回的有关于缓存的header字段信息(Last-Modefied/IF-Modified/Etag-None-Match),若命中则更新缓存中的Header信息,直接从缓存中使用。
3.DNS解析
如果用户输入的使IP地址,则直接进入第四条。毫无规律又冗长的IP地址显然不是我们想要的,我们通常都是输入域名,这时就会进行DNS解析。所谓DNS(Domain Name System)指域名系统。通过域名映射到IP地址,使用户更方便的访问互联网。通过域名最终得到主机对应IP的过程叫做域名解析(主机解析)。
浏览器拿到域名后首先会搜索浏览器自身DNS缓存(缓存时间比较短)。如果找到对应DNS缓存则DNS解析结束。如果没有找到,浏览器会发起一个本地DNS的系统调用,就会向本地配置的首选DNS服务器发起域名解析请求(通过UDP协议向运营商的DNS服务器发起该域名的IP请求),运营商的DNS服务器首先查找自身的缓存,如果有缓存则返回,DNS解析成功。如果没有运营商的DNS服务器待我们的浏览器发起迭代DNS解析的请求,它首先会找到根DNS的IP地址,然后向其发出请求。这样递归请求,最终找到域名对应的真正地址,于是把找到的结果返回给运营商的DNS服务器,这时运营商DNS服务器拿到这个域名+对应IP返回给客户端Windows系统内核,内核又把结果返回给浏览器,解析成功。
简单理解为:客户端->本地DNS->运营商DNS->我们在运营商买的服务器的DNS,依次查询,碰到有返回就不在向下查询了。
4.发送请求
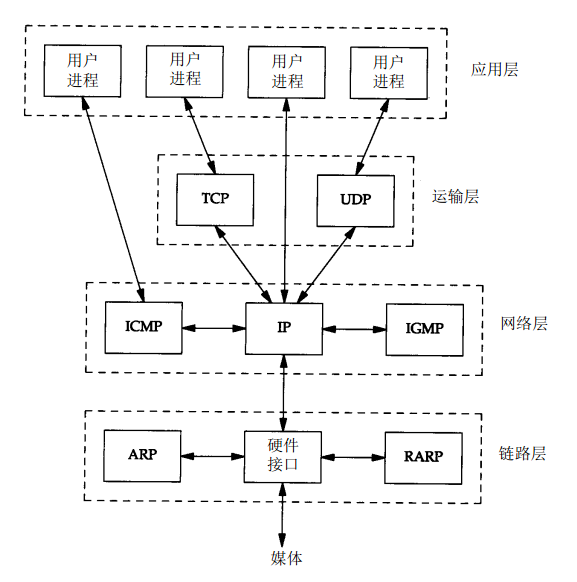
拿到域名对应IP后,浏览器会以一个随机端口(1024~65535)向服务器(Nginx,Apache等)发出连接请求,经过TCP/IP(应用层,传输层,网络层,数据链路层)4层模型,进入网卡,然后进入内核的TCP/IP协议栈,还有可能经过防火墙,最终到达WEB程序。
简单理解为连接之前先经过一大堆验证,成功后才让你去连接。
3次握手
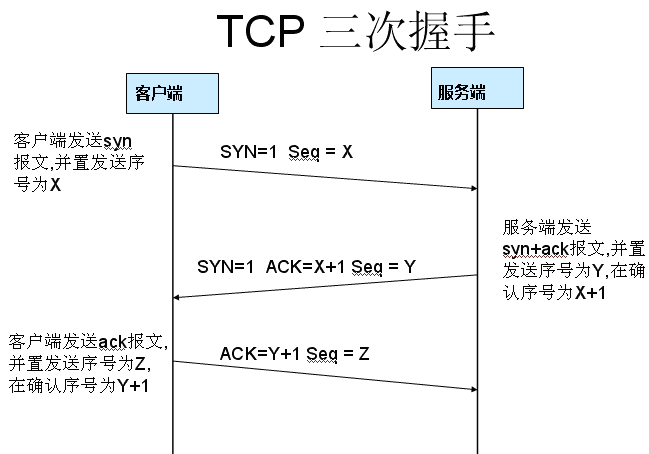
简单理解为:(1)客户端说:“我可以和你连接吗?”。(2)服务器说:“可以”。(3)客户端说:“好的,那我连接了。”建立链接成功
请求报文
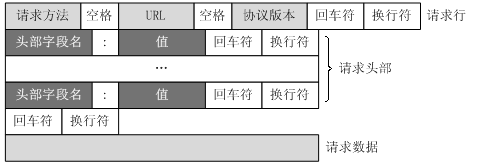
一个HTTP请求报文由请求行、请求头、空行和请求数据组成。
(1)请求行:请求方法、请求地址,协议版本。
(2)请求头:
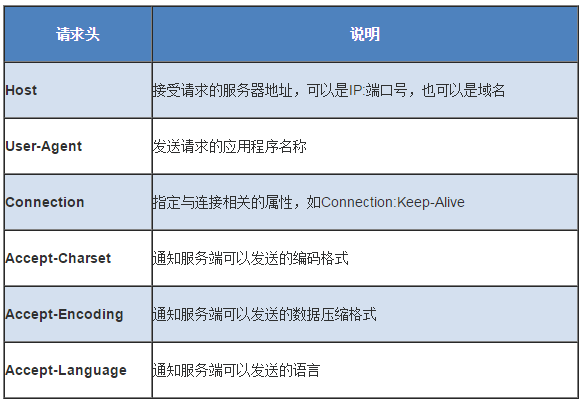
使用content-encoding:gzip;开启gzip压缩能减小文件体积。
(3)请求数据:请求携带的参数
响应报文

响应报文主要由状态行、响应头部,空行和响应数据组成。
(1)状态行:协议版本、状态码、状态码描述
状态码
1XX:指示信息-表示已经接口,继续处理
2XX:成功
3XX:重定向
4XX:客户端错误
5XX:服务端错误
(2)响应头
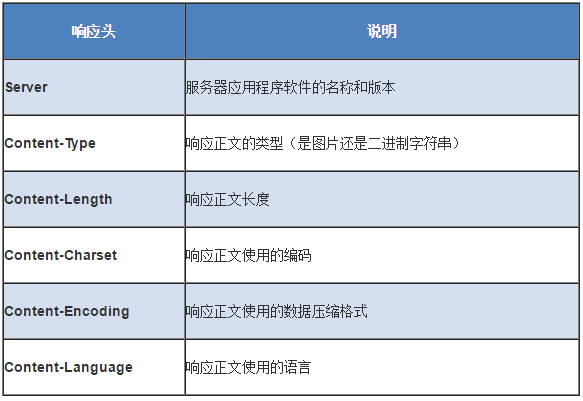
(3)响应数据:用于存放需要返回给客户端的数据信息。
通过压缩减小文件传输体积,加快传输速度。
简单理解:请求报文是请求需要的所有参数,响应报文是响应所需要的所有参数和数据。
TCP4次挥手
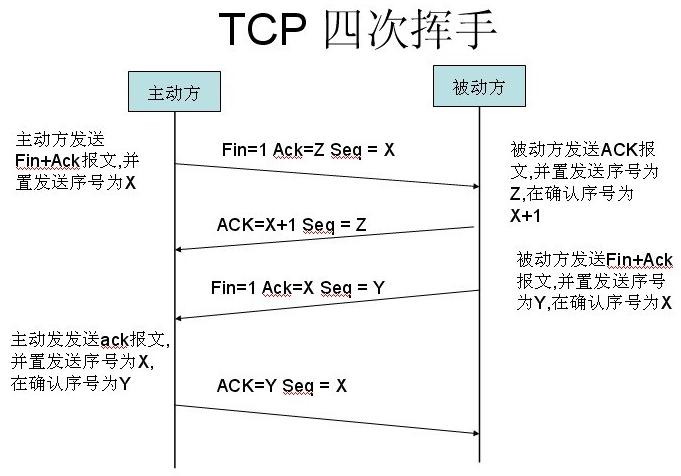
简单的理解为,(1)客户端发送个请求说我要断开连接了(2)服务器回应好的(3)服务器发送我要断开连接了(4)客户端回应好的。断开连接
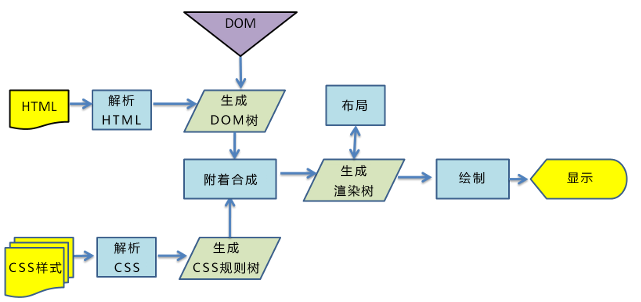
解析html代码,渲染整个页面
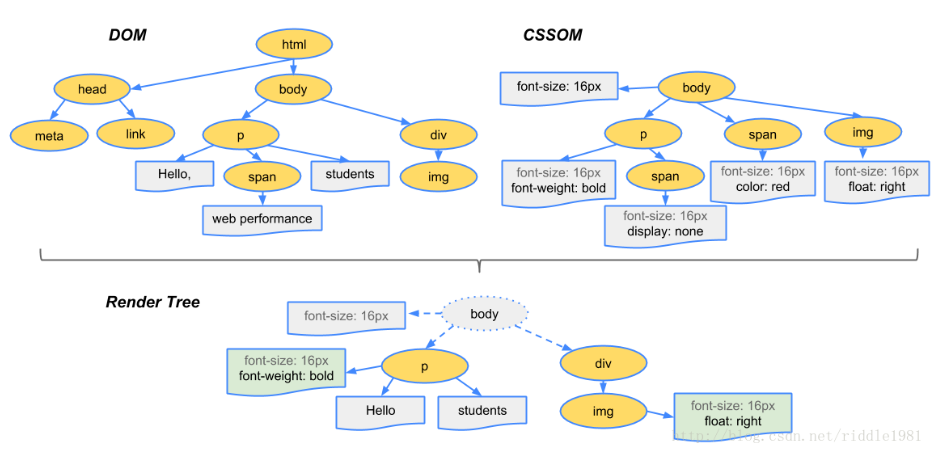
大概流程:浏览器拿到HTML文档时会先进行HTML文档解析,构建DOM树。遇到link标签或者style的时候开始解析CSS树。DOM树和CSS树构建是相互独立的并不会造成冲突(所以通常将css放到head中)。当遇到script标签的时候阻塞DOM树构建会先执行脚本(因为js可以增删元素和动态改变样式,所以等js解析完毕后DOM树和CSS树才开始合成render树)。当DOM树和CSS树构建完成就可以进行渲染树构建了。渲染树构建完成将会进行布局,布局使用流模型的Layout算法,从左到右从上到下执行一遍即可完成渲染。
1.html构建
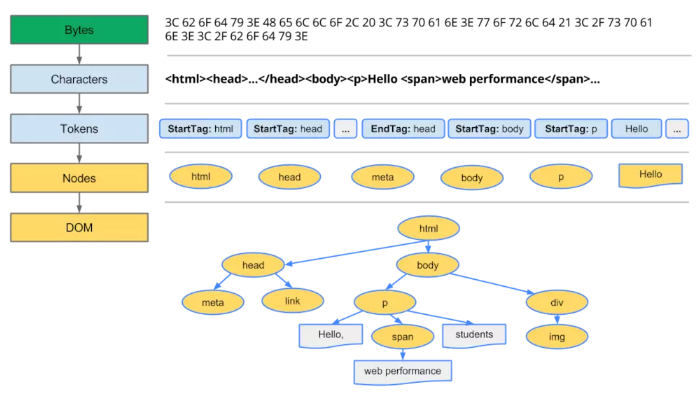
HTML解析是一个将字节转化为字符,字符转化为标记,标记生成节点,节点构建树的过程。
HTML解析分为标记化和树构建两个阶段,下面例子
标记化算法
是词分法过程,将内容解析成多个标记。HTML标记的过程包括起始标记,结束标记,属性名称,属性值。标记生成器标识标记,传递给树构造器,直到输入结束。
构建树算法
标记生成器发送的每个节点都会由树构建处理,以Document为根节点的DOM树会不断修改,向其中添加各种元素
例子:
<html>
<body>
Hello world
</body>
</html>
标记化:初始化状态为数据状态,当遇到字符<状态更改为“标记打开状态”。接收a-z字符串会创建“起始标记”,标记状态为“标记名称状态”。这个状态会一直持续到遇到>字符时。在此间接收的每一个状态都会附加到标记名称上,发送当前的标记给构建树。html和body标记已经发出,我们回到“数据状态”。接收到Hello world中的H时,创建并发送字符标记,直到接收到<。Hello World每个字符都会发送一次标记。接收到<回到“标记打开状态”,接收输入的字符为/时,会创建end tag token并改为“标记名称状态”,直到接收>然后将标记发出,并回到“数据状态”。这样重复以往,将所有的处理完毕。
构建树:接收第一个来自标记化阶段的标记序列,第一个模式为“intial mode”,接收HTML标记后转为“before html”模式,并在这个模式下重新处理标记,这样会创建一个HTMLHtmlElement元素并附加到Document上。然后状态改为“before head”。此时我们接收“body”标记,没有“head”标记,系统会隐式创建一个HTMLHeadElement,并将其添加到树上。然后在添加HTMLBodyElement到树上。接收Hello World的字符串,接收第一个字符的时候创建并插入“text”节点。接收到body的结束标记会触发“after body”模式。然后接收html的结束标记,然后进入“after after body”模式,解析结束。
简单理解为:解析html遇到<a-z>标签发送信号给构建树创建对应Element添加到Document,遇到字符串每一个一发送并创建text将其包裹添加到Document,遇到</a-z>创建结束标识。直到</html>后结束。
HTML解析完毕后,浏览器文档标注为交互状态。从这一刻开始解析那些处于“deffered”模式的脚本。
2.css层叠规则
css的重叠规则根据CSS Specificity来判定。由一个四个数组成的一个组合,用a,b,c,d代表四个位置。先比a值大小,如果a值相同比比较b值得大小,这样一次比较。
a规则:如果HTML标签的”style“属性中样式存在,则a标记为1.
b规则:如果由id选择器,则b标记为1.
c规则:其他属性以及伪类的总数量时的值
d规则:元素名和伪元素的数量时d值
W3C给的例子

总结:

3.css的解析
请求一个style.css,返回内容是这样的。
body { font-size: 16px }
p { font-weight: bold }
span { color: red }
p span { display: none }
img { float: right }

css的解析过程是字节、字符、符号、节点、对象模型。
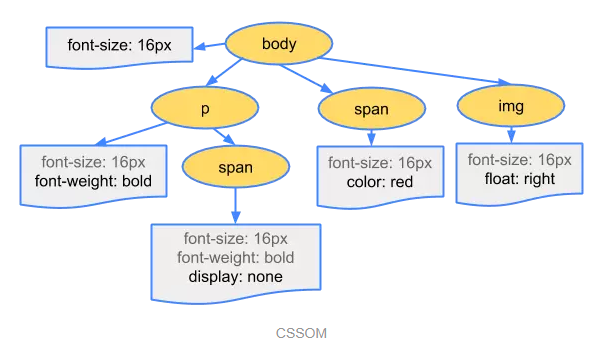
解析完形成CSSOM树状结构。
(1)Firefox的规则树和样式上下文树
样式上下文包含端值,要计算出这些值,应按照正确的顺序应用所有匹配规则。并将其从逻辑值转化为具体的值。例如逻辑值是屏幕大小的百分比,则需要换成绝对的单位,规则树的点子真的很巧妙,它使得节点共享这些值,以避免重复的计算,还可以节约空间。
所有匹配规则都储存在树中。路径中的底层节点拥有较高的优先级。规则树包含所有已知规则的匹配的路径。规则的储存值是延时进行的。规则树不会在开始的时候就为所有节点进行计算,而是当某个节点样式需要进行计算时,才会向规则树添加计算的路径。这个想法相当于将规则树是为词典中的单词。如果我们已经计算出如下的规则树:
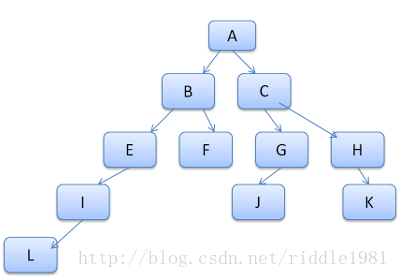
假设我们需要为内容树中的另一个元素匹配规则,并且找到匹配路径是B-E-L(按照次顺序)。由于我们的树种已经计算出了路径A-B-E-L-I,因为我们已经有了此路径,这就减少了现在所需的工作量。
举个例子:
html
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
css
div {margin:5px;color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
形成的规则树如下:
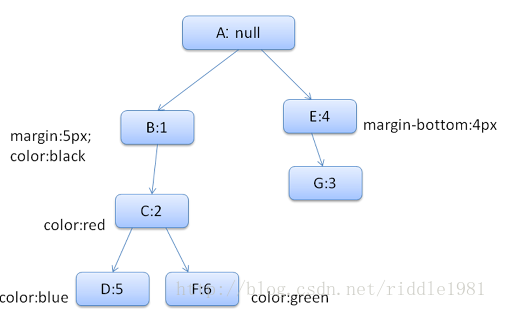
上下文树如下:
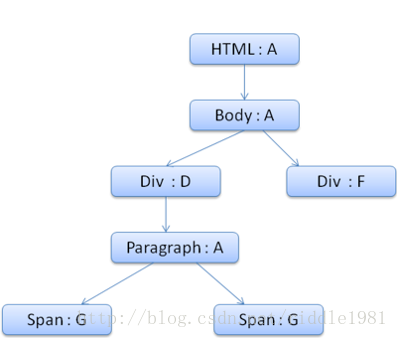
假设我们解析HTML时遇到第二个<div>标记,我们需要为此节点构建样式上下文,并填充样式结构。
经过规则匹配,我们发现该<div>的匹配规则时1,2,6条。这意味着规则树中已经有一条路径可供我们的元素使用,我们只需要在为其添加一个节点以匹配规则第6条规则(规则树种的F节点)。
我们将创建样式样式下文并将其放入上下文树中。新的样式上下文将指向规则树中的F节点。
现在我们需要填充样式结构。首先要填充的时margin结构。由于最后的规则节点(F)并没有添加到margin结构,我们需要上溯规则树。直至我们找到在先前节点插入计算过的缓存结构,然后使用该结构。我们会在指定margin规则的最上层节点(即B节点)上找到该结构。我们已经有了color结构的定义,因此不能使用缓存的结构。由于color有一个属性,我们无需上溯规则树以填充其他属性。我们将计算端值(将字符串转化为RGB等)并在此节点上缓存经过计算的结构。
可以共享整个上下文了,只需指向之前span的上下文即可。
对于包含了继承自父代的规则的结构,缓存实在上下树中进行的(事实上color属性是继承的,但是Firefox将其视为reset属性,并缓存到规则树上)。
p {font-family:Verdana;font size:10px;font-weight:bold}
例如给某个段落添加font规则,该上下树中的子代,就会共享与其父相同的font结构(前提时子代没有制定font规则)。
简单理解为当第一次渲染div时,创建规则树的div这条规则,当渲染下一个div时检查缓存规则树已经有,则使用这个条规则。如果本身有这条规则不使用缓存。
(2)Webkit样式解析
Webkit中没有规则树,因此会对匹配声明遍历4遍。首先应用非常重要高优先级的属性(由于作为其他属性的依据而应首先应用的属性,例如display),接着是高优先级重要规则,然后是普通优先级重要规则,最后是普通优先级非重要规则。这意味着多次出现的属性会根据正确的重叠顺序进行解析,最终生效。
(3)解析规则
CSSOM是阻塞渲染,意思是css没处理好之前所有的东西都不会展示。虽然css文件会缓存,但是CSSOM每次都会从新构建,CSSOM构建慢意味着会有更长的白屏时间。
CSS解析是自右向左逆向解析的,嵌套的越多越增加浏览器的工作量。
例如【div ul li .title】如果从最上层向下找,就得先找到最上层的div,然后再去匹配下层的ul,然后在依次,经过若干次匹配找到正确的对应,这样效率很低。从下往上找则会先找到所有的.title,然后在取匹配上层的li,这样的速度很快。
4.渲染树的构建
CSS树和DOM树连接在一起形成渲染树,渲染树用来计算(Layout)可见元素的布局并且作为将像素渲染到屏幕的过程输入。
父节点确定自己的宽度
父节点完成子节点的放置,确定其相对坐标
节点确定自己的宽度的高度
父节点依据所有子节点的高度计算自己的高度
浏览器渲染过程中需要了解的概念
Repaint(重绘):屏幕一部分要重画,比如css背景颜色变了,但是元素的几何尺寸没有变。
Reflow(重排):元素的集合尺寸变了,我们需要重新计算渲染树。重排由部分重排和全部重排,尽量避免全部重排。
DOMContentLoaded事件:当DOM树加载完成的事件。
onload事件:页面上所有的DOM,样式表,脚本,图片等全部加载完成的事件。
首屏时间:浏览器显示第一屏所消耗的时间。
白屏时间:指浏览器开始显示内容的时间。
页面性能检测
(1)打开chrome调试工具,找到Network>Online将网络调到3G模式,在网络速度慢的情况下能更好的观测到渲染的过程。
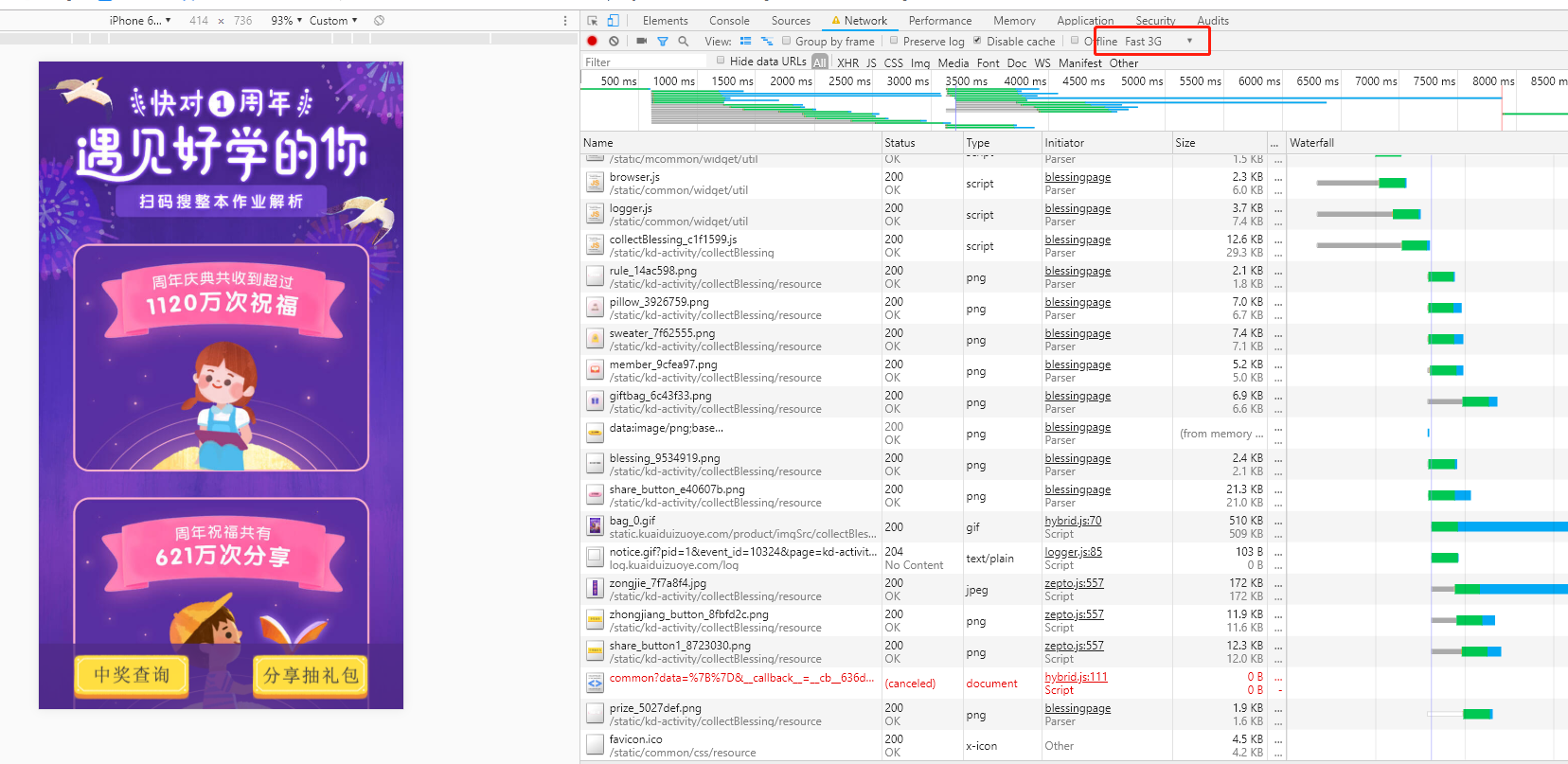
看到有很多请求前会有灰条,这是请求Stalled,原因为浏览器解析每个域名下的资源有一定的并发数量,达到一定上线后就会进入stalled状态。
浏览器http并发数:https://blog.csdn.net/jueshengtianya/article/details/38271081
(2)chrome版本低会有Timeline,能从页面上观察到资源加载页面渲染的情况。高版本的chrome取消了Timeline,增加了window.performance能检测到我们的浏览器性能--前端性能分析-Performance
(3)Google的网页载入速度检测工具PageSpeed Insights,能够分析页面载入的各个方面,并给你优化建议。
PageSpeed Insights:https://developers.google.com/speed/pagespeed/insights/(需要FQ)
页面优化的方案
1.减少http请求
(1)合并资源
(2)CSS Sprites
(3)使用图标替代图片
(3)避免大文件
(4)图片压缩,使用webp格式的资源
(5)添加Expires头增加缓存时间
2.减小文件体积
(1)服务端启用gzip压缩
(2)压缩外部链接js和css
3.请求优化
(1)使用cdn加速
(2)dns预解析
(3)根据域名划分内容(防止请求Stalled现象)
4.代码优化
(1)css放在最上面,js放在最下面
(2)css表达式不宜过长,优先级越高越好查找
(3)减少dom的操作--为什么说js操作DOM很慢
(4)css动画开启硬件加速
(5)首屏加载策略,异步css和js
(6)图片懒加载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号