

图机器学习基本概念
目录
图数据
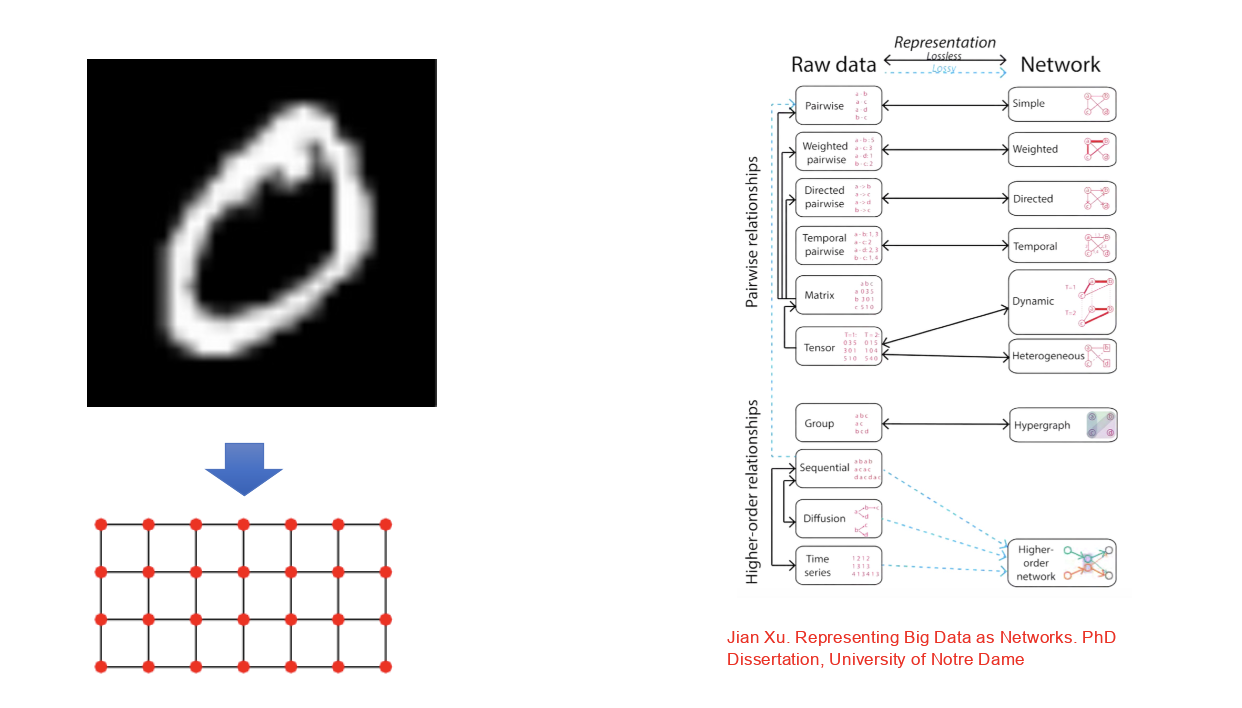
- 显式图数据和隐式图数据,如下图所示:
图定义
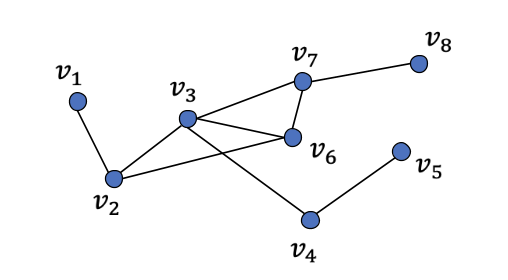
- \(\mathcal{V}=\{v_1,...,v_N\},\mathcal{E}=\{e_1,...,e_M\},\mathcal{G}=\{\mathcal{V},\mathcal{E}\}\),如下图所示:
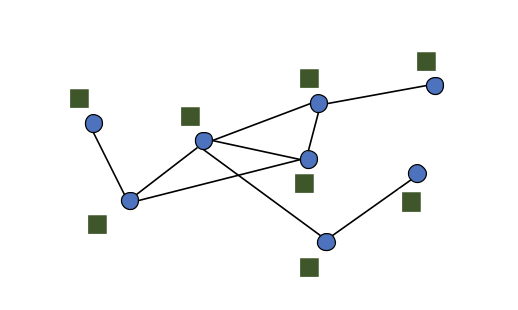
- 图信号:\(f:\mathcal{V}\to R^N\),如下图所示:
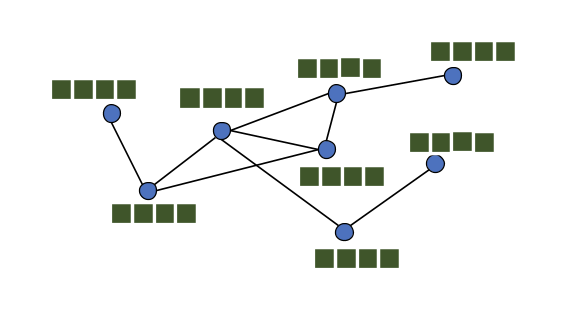
- 图的表示:
- 矩阵表示:邻接矩阵A、度矩阵D=\(diag(degree(v_1),...,degree(v_N))\),拉普拉斯矩阵L=D-A
- 边列表
- 邻接列表:结点及其对应的邻居
- 无向图的平均度:\(\frac{2E}{N}\);有向图中定义入度和出度,一个结点的度是入度和出度之和,源结点入度为0,sink结点出度为0,平均入度和平均出度相等,都等于\(\frac{E}{N}\)
- 强连通有向图:每个结点到所有其他结点均有路;弱连通有向图:若无视边的方向则是连通的
- 强连通成分(SCC),In-component:结点可以到达SCC,Out-component:从SCC可以到达的结点
图任务
- 连接预测
- 结点分类/半监督学习
- 社区检测/无监督学习
- 图分类/有监督学习
- 文档分类:为整个文档获得一个表示
- 图生成
- 图匹配
- 图可视化
- 图的结构学习:联合学习图的结构和图嵌入
- 图到X的学习:图为输入,X为输出
- 具体任务:社交网络、交通、视觉、meshs、生物化学、物理、code、算法问题、推荐系统
结点级别任务
- 结点分类
- 结点度、结点中心性、聚类系数、Graphlet
- 结点度没有考虑邻居结点的重要性,结点中心性则考虑
- 不同方式建模重要性:
- 特征向量中心性:如果结点v被重要的邻居结点围绕,则v也是重要的;建模结点v的中心性为邻居结点中心性之和:\(c_v=\frac{1}{\lambda}\sum_{u\in N(v)}c_u\),\(\lambda\)是某个正常数;上述等式以递归的方式建模中心性;将递归等式写成矩阵形式:\(\lambda \vec{c}=A\vec{c}\),\(\vec{c}\)是中心性向量,即特征向量,最大特征值\(\lambda_{max}\)总是正的且唯一,leading特征向量\(\vec{c}_{max}\)用于中心性
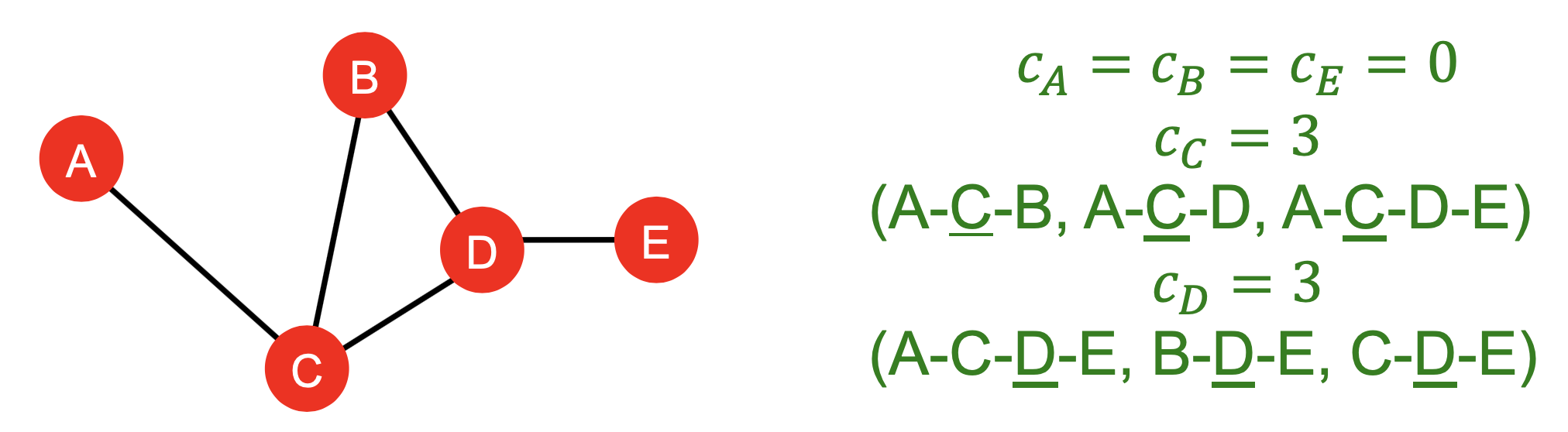
- Betweenness中心性: 当一个结点处在多条最短路上,则该结点是重要的,即\(c_v=\sum_{s\ne v \ne t}\frac{\text{#(shortest paths between s and t that contains v)}}{\text{#(shortest paths between s and t)}}\),下图是个例子:
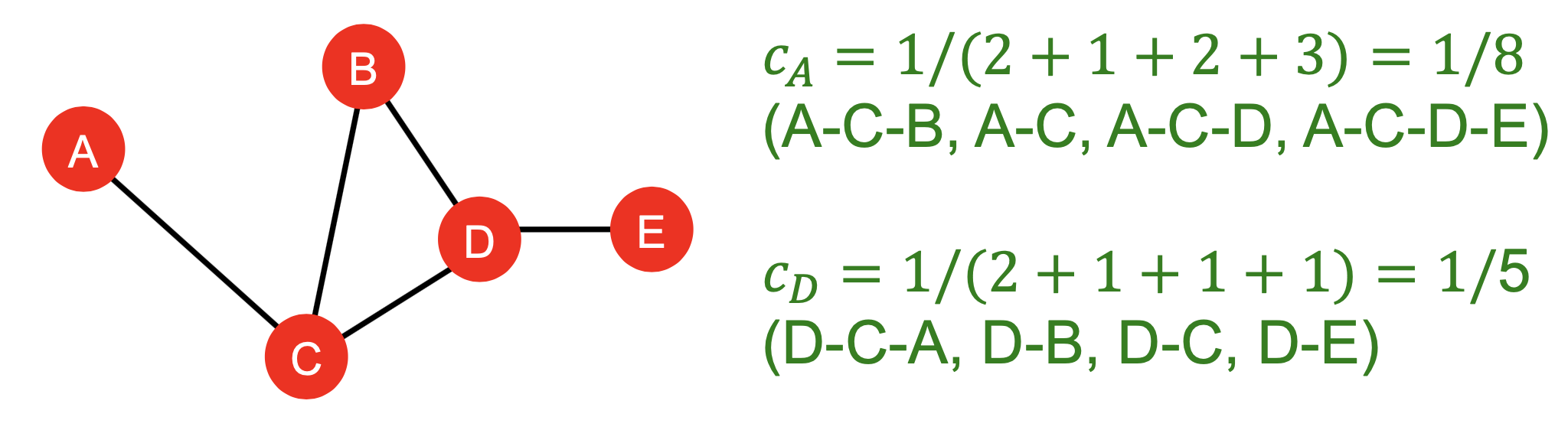
- Closeness中心性:当一个结点到所有其他结点有最短路径长度时它是重要的,即\(c_v=\frac{1}{\sum{u\ne v}\text{shortest path length between u and v}}\),下图是个例子:
- 不同方式建模重要性:
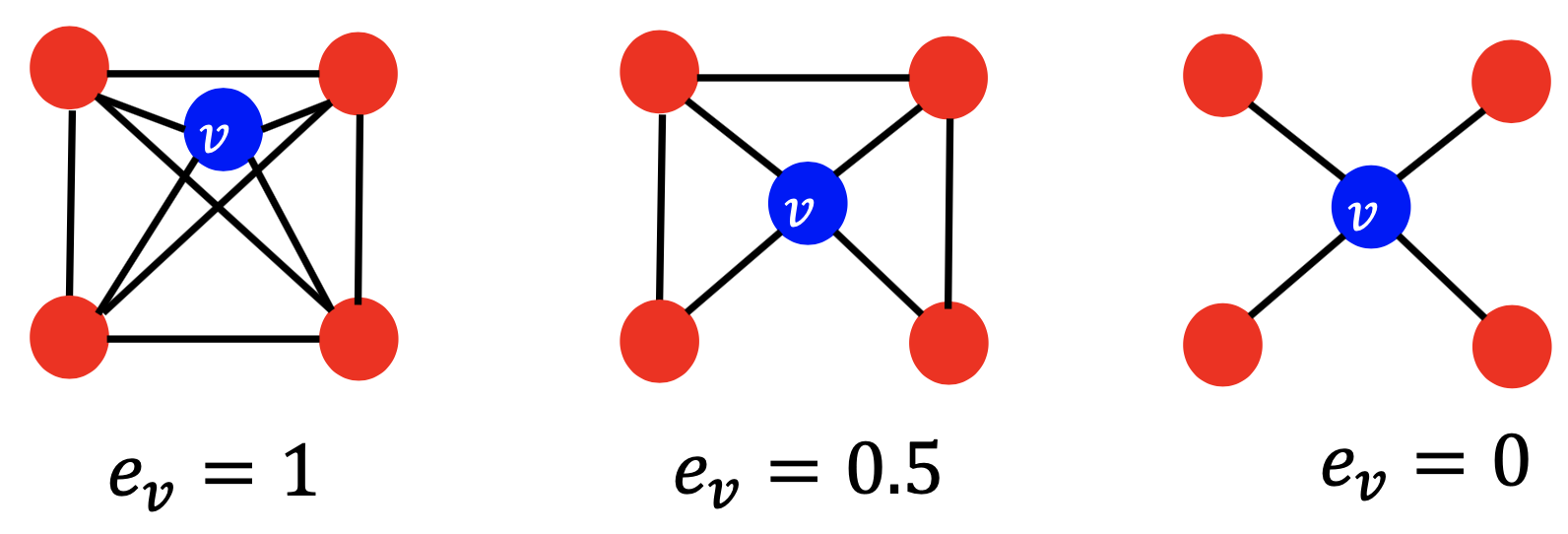
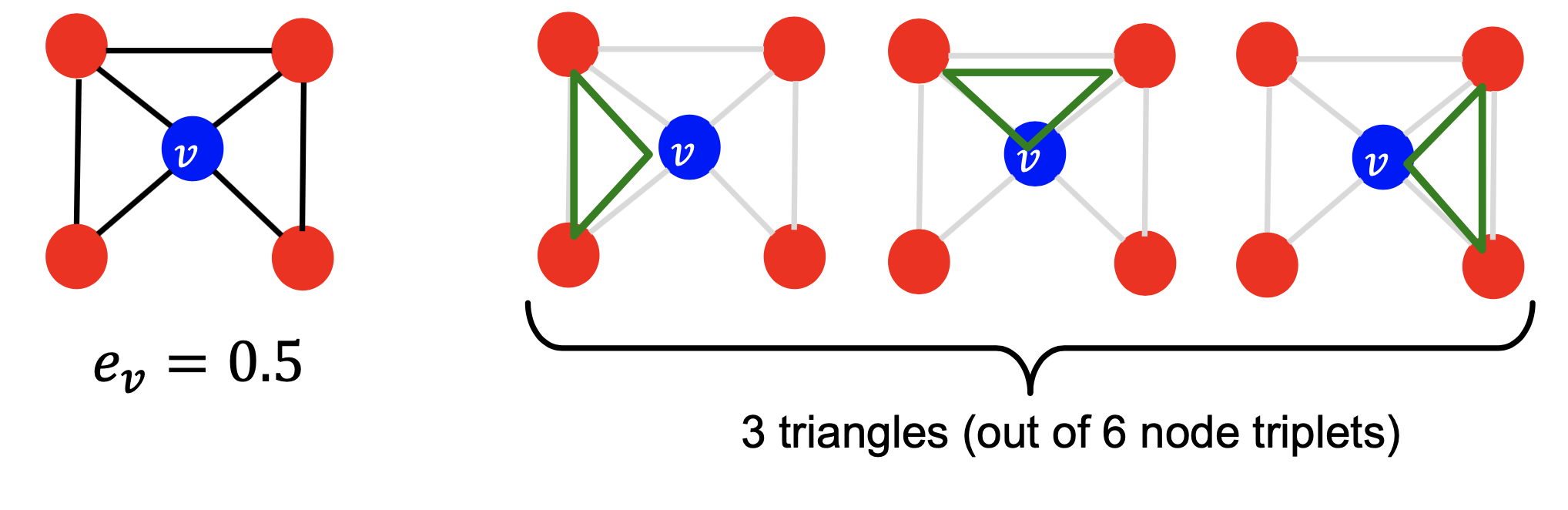
- 聚类系数:衡量v的邻居结点的连通性,即\(e_v=\frac{\text{#(edges among neighboring nodes)}}{\begin{pmatrix} k_v \\ 2 \end{pmatrix}}\in [0,1]\),其中\(\begin{pmatrix} k_v \\ 2 \end{pmatrix}\)表示\(\text{node pairs among} k_v \text{neighboring nodes}\),下图是个例子:
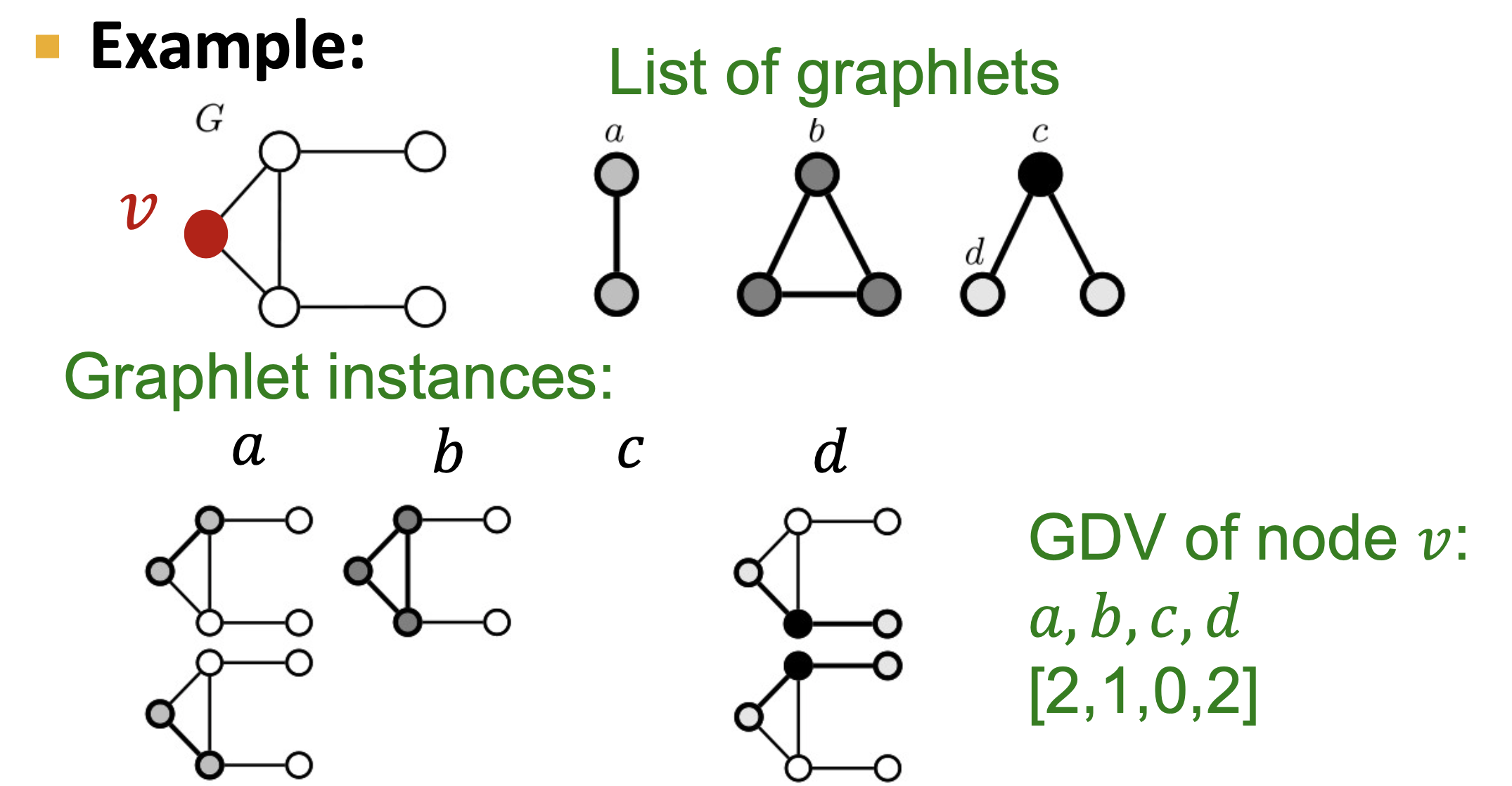
- Graphlet
- 聚类系数统计ego-network中的\(\text{#(triangles)}\),如下图所示。可通过统计\(\text{#(pre-specified subgraphs, i.e., graphlets)}\)来进行推广
- Graphlet Degree Vector (GDV):基于Graphlet的结点特征;度统计一个结点接触的\(\text{#(edges)}\),聚类系数统计一个结点接触的\(\text{#(triangles)}\),GDV统计一个结点接触的\(\text{#(graphlets)}\),如下图所示:
- 聚类系数统计ego-network中的\(\text{#(triangles)}\),如下图所示。可通过统计\(\text{#(pre-specified subgraphs, i.e., graphlets)}\)来进行推广
连接级别任务
- 连接预测:基于现有的连接预测新的连接
- 预测任务的两种构成:
- 随机移除一组连接,然后预测它们
- 随时间变化的连接:给定一个直到时间\(t_0^{'}\)的图\(G(t_0,t_0^{'})\),输出一个排好序的连接列表(没有出现在\(G(t_0,t_0^{'})\),预测在\(G(t_1,t_1^{'})\)中出现),如下图所示:
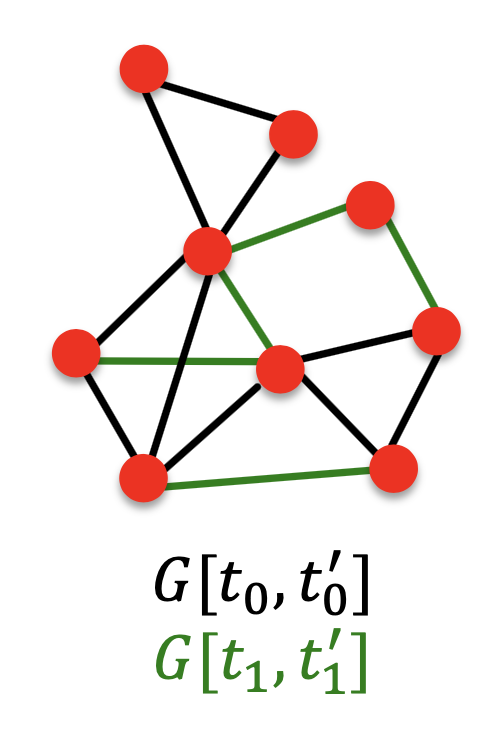
- 评估:在测试时出现的新边\(n=|E_{new}|\),取输出列表的前n个元素并统计正确的边
- 通过proximity进行连接预测
- 对于每一对结点计算一个分数\(c(x,y)\),\(c(x,y)\)可以是x和y的共同邻居数目;以分数降序排列对
- 连接级别的特征
- 基于距离的特征
- 最短路距离,但这个无法捕获邻域重叠的程度
- 局部邻域重叠:捕获两个结点之间共享的邻居结点
- 共同Common邻居:\(|N(v_1)\cap N(v_2)|\),如下图:\(|N(A)\cap N(B)|=|\{C\}|=1\)
- Jaccard’s系数:\(\frac{|N(v_1)\cap N(v_2)|}{|N(v_1)\cup N(v_2)|}\),如下图:\(\frac{|N(A)\cap N(B)|}{|N(A)\cup N(B)|}=\frac{|\{C\}|}{|\{C,D\}|}=\frac{1}{2}\)
- Adamic-Adar索引:\(\sum_{u\in N(v_1)\cap N(v_2)}\frac{1}{log(k_u)}\),如下图:\(\frac{1}{log(k_C)}=\frac{1}{log4}\)
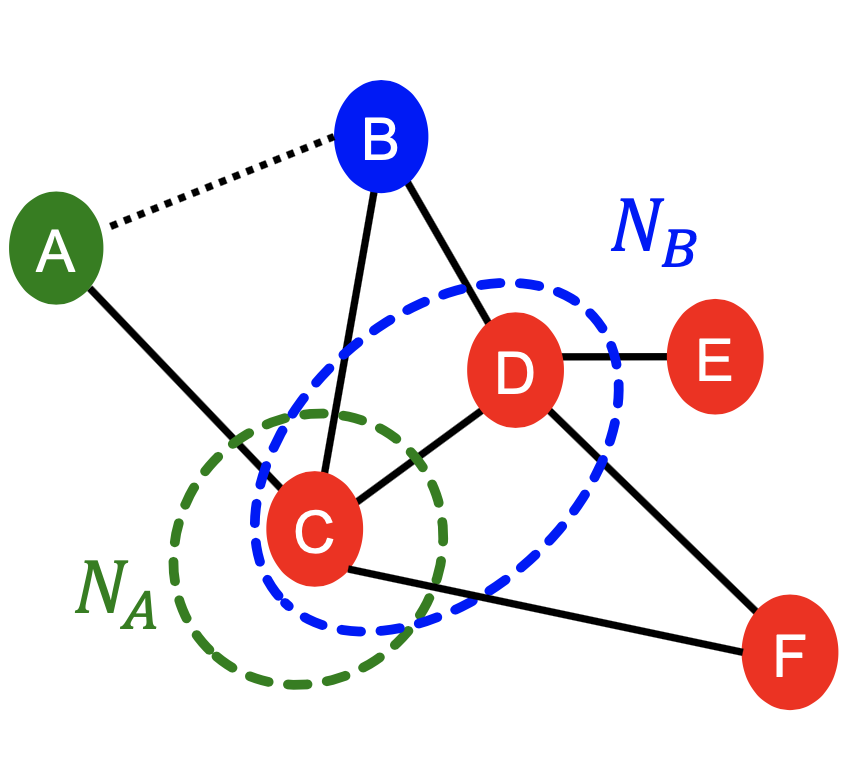
- 全局邻域重叠
- 局部邻域特征的限制:如果两个结点没有任何共同的邻居,则度量总是零;但这两个结点在将来仍然可能连接;全局邻域重叠度量通过考虑整个图来解决这一局限性
- Katz索引:统计给定一对结点之间所有长度的路径数;使用图邻接矩阵的幂来统计两个结点之间的路径数
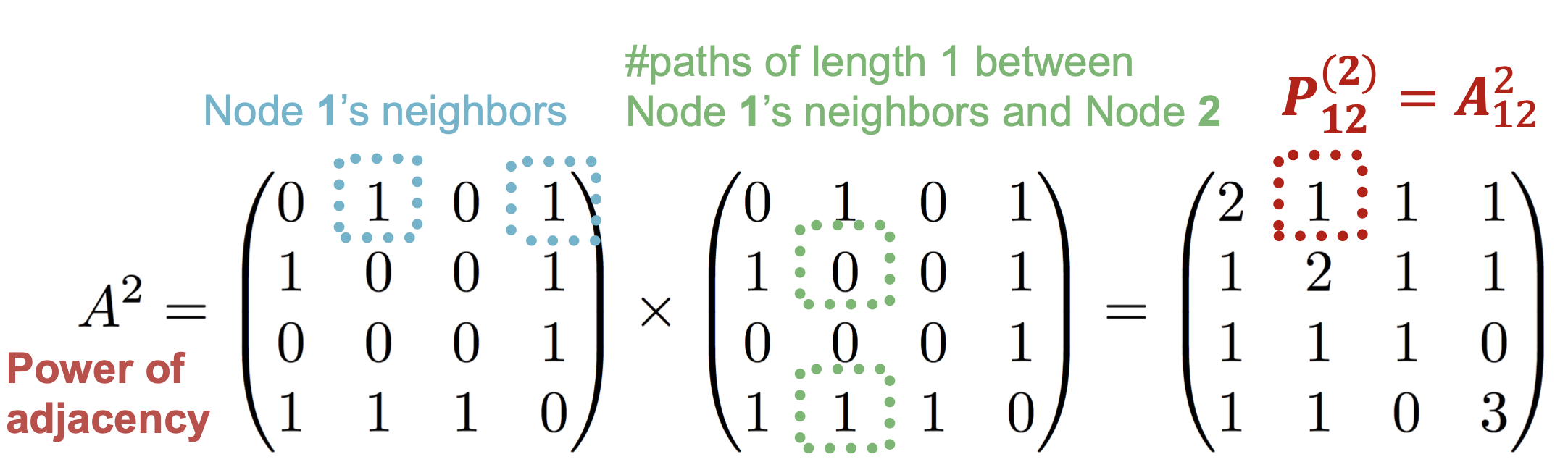
- \(P_{uv}^{(K)}\)为u和v之间长度为K的路径数
- \(P^{(K)}=A^k\): 首先,\(P_{uv}^{(1)}=A_{uv}\);然后,\(P_{uv}^{(2)}=\sum_{i}A_{ui}*P_{iv}^{(1)}=\sum_{i}A_{ui}*A_{iv}=A_{uv}^2\),如下图所示
- Katz索引为:\(S_{v_1v_2}=\sum_{l=1}^{\infty}\beta^lA_{v_1v_2}^l\),其中\(0<\beta<1\)是discount因子
- Katz索引矩阵以closed-form被计算,如下图所示:
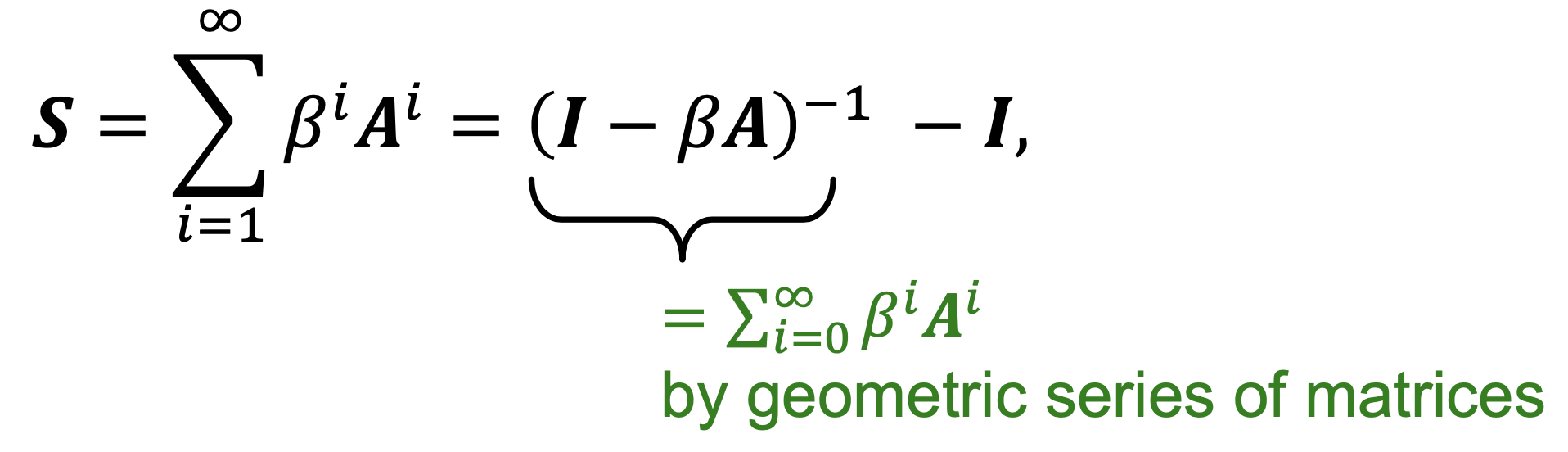
- 基于距离的特征
图级别任务
- 图级别特征:能够描述整个图的结构
- 核方法:是针对图级别预测广泛使用的传统机器学习方法
- 设计核而非特征向量
- 核\(K(G,G^{'})\in R\)衡量数据之间的相似性;核矩阵\(K=(K(G,G^{'}))_{G,G^{'}}\)必须是半正定positive semidefinite,即有正的特征值;存在一个特征表示\(\phi(·)\)使得\(K(G,G^{'})=\phi(G)^T\phi(G^{'})\);一旦定义了核,就可以使用现成的ML模型(如核SVM)进行预测
- 图核:衡量两个图之间的相似性
- Graphlet核
- Weisfeiler-Lehman核
- Random-walk核、最短路图核等
- 图核的关键思想:设计图特征向量\(\phi(G)\);图的词袋(BoW)(将结点看作词,统计词数,如下面第一张图所示);考虑结点度的袋,如下面第二张图所示
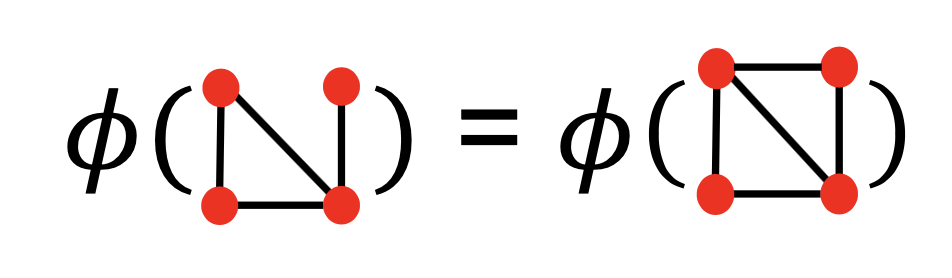
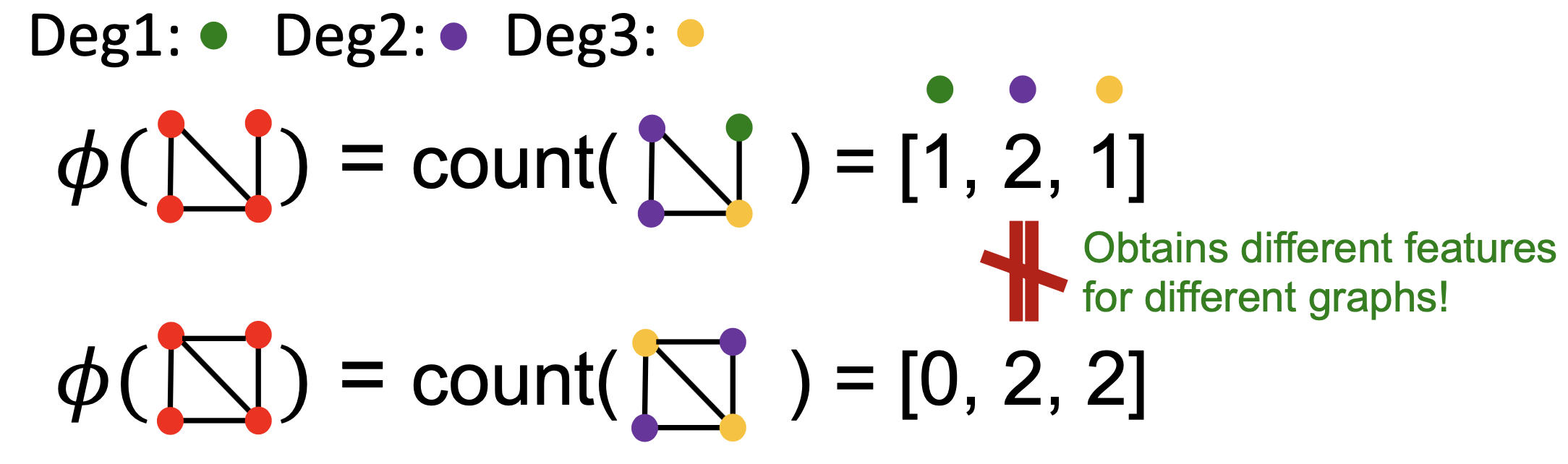
- Graphlet核和Weisfeiler-Lehman核均使用图的
Bag-of-*表示,但*比结点度更复杂 - Graphlet特征:统计图中不同graphlets的数目(这里的graphlets的定义与结点级别的特征不同;两个不同:这里的graphlets中的结点不需要连接,即允许isolated结点/这里的graphlets不是rooted;如下图所示)
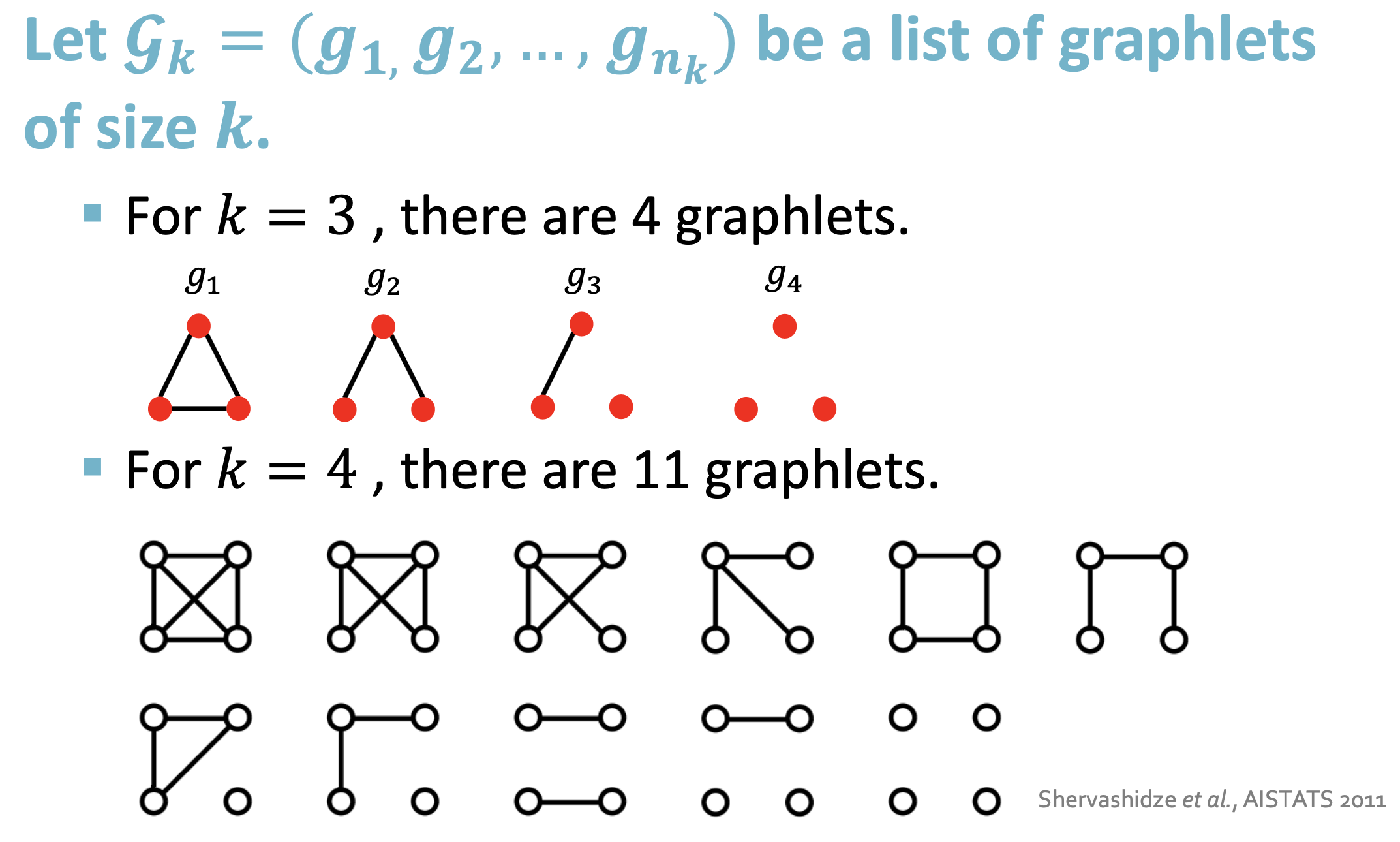
- Graphlet特征:给定图G和一个graphlet列表\(\mathcal{G}_k=(g_1,g_2,...,g_{n_k})\),定义graphlet统计向量\(f_G\in R^{n_k}\),如下图所示:
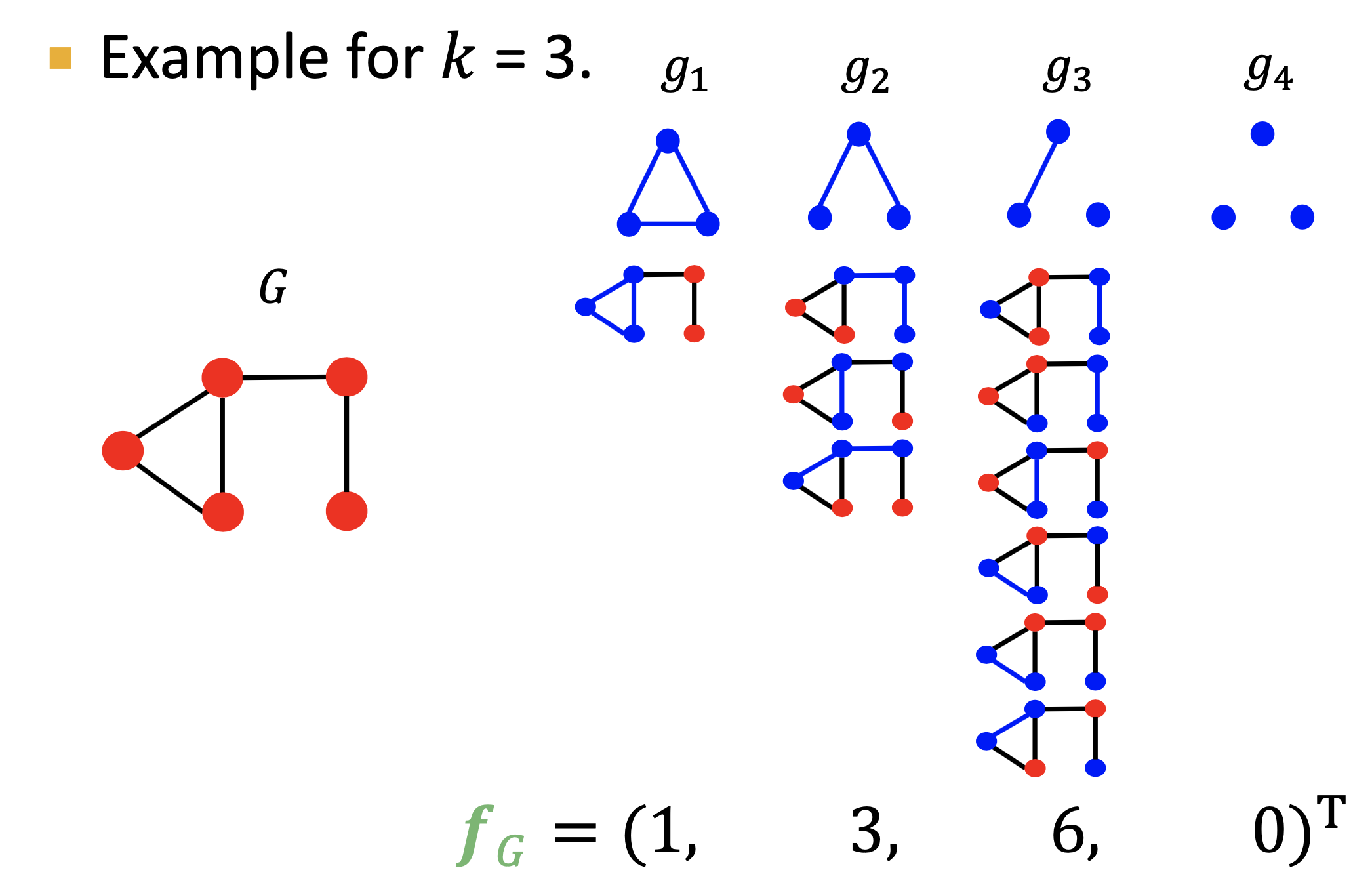
- Graphlet核:\(K(G,G^{'})=f_G^Tf_{G^{'}}\);若\(G\)和\(G^{'}\)大小不一样,则会使得值偏斜skew,方法是标准化每个特征向量,即\(h_G=\frac{f_G}{Sum(f_G)}\),\(K(G,G^{'})=h_G^Th_{G^{'}}\);Graphlet核的限制是计算graphlets是昂贵的,通过枚举统计大小为n的图中大小为k的graphlets需要花费\(n^k\)
- Weisfeiler-Lehman核: 设计一个有效的图特征描述器\(\phi(G)\)
- Graphlet核和Weisfeiler-Lehman核均使用图的
图与深度学习
- 传统机器学习假设实例之间相互独立,这在图中是不成立的
- 传统深度学习是为简单的网格或序列设计的,如用于固定大小的图像/网格的CNNs,用于文本/序列的RNNs
- CNN的主要属性:平移不变;空间的局部过滤器;多层
- 图上结点具有不同的联系
- 任意邻居大小
- 复杂拓扑结构
- 无固定结点顺序
- 结点嵌入方法:DeepWalk, Node2Vec
- GNN:基于局部邻域生成结点嵌入
- 直接作用于图上
- 可以处理相似性以外的关系;隐式正则
- 从结点嵌入的概念出发,将结点映射到一个低维嵌入空间,希望图中相似的结点在嵌入空间中靠的近(嵌入空间中的相似性能近似网络中的相似性),如下第一张图所示。希望encoder函数实现Locality(local network neighborhoods)、聚合信息和堆叠多层。通过使用一个计算图可以实现Locality信息;聚合由神经网络实现,如下第二张图所示,聚合是顺序无关的order-invariant,如求和、平均、最大,因为它们都是置换不变permutation-invariant函数;考虑GNN中的前向传播法则,具体需要三步来执行:1) 初始化激活单元:\(h_v^0=X_v(\text{feature vector})\),2) 网络中的每一层:\(h_v^k=\sigma(W_k\sum\frac{h_u^{k-1}}{|N(v)|}+B_kh_v^{k-1})\),3) 最后一层:\(z_v=h_v^K\)
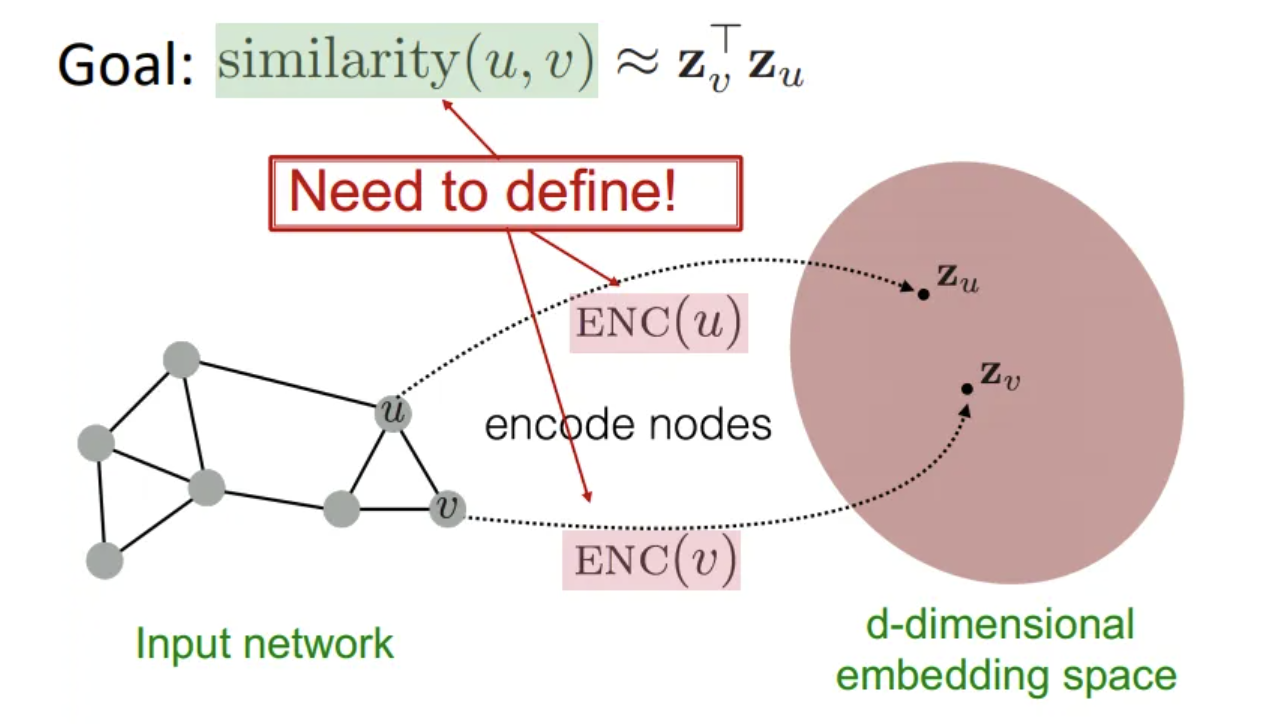
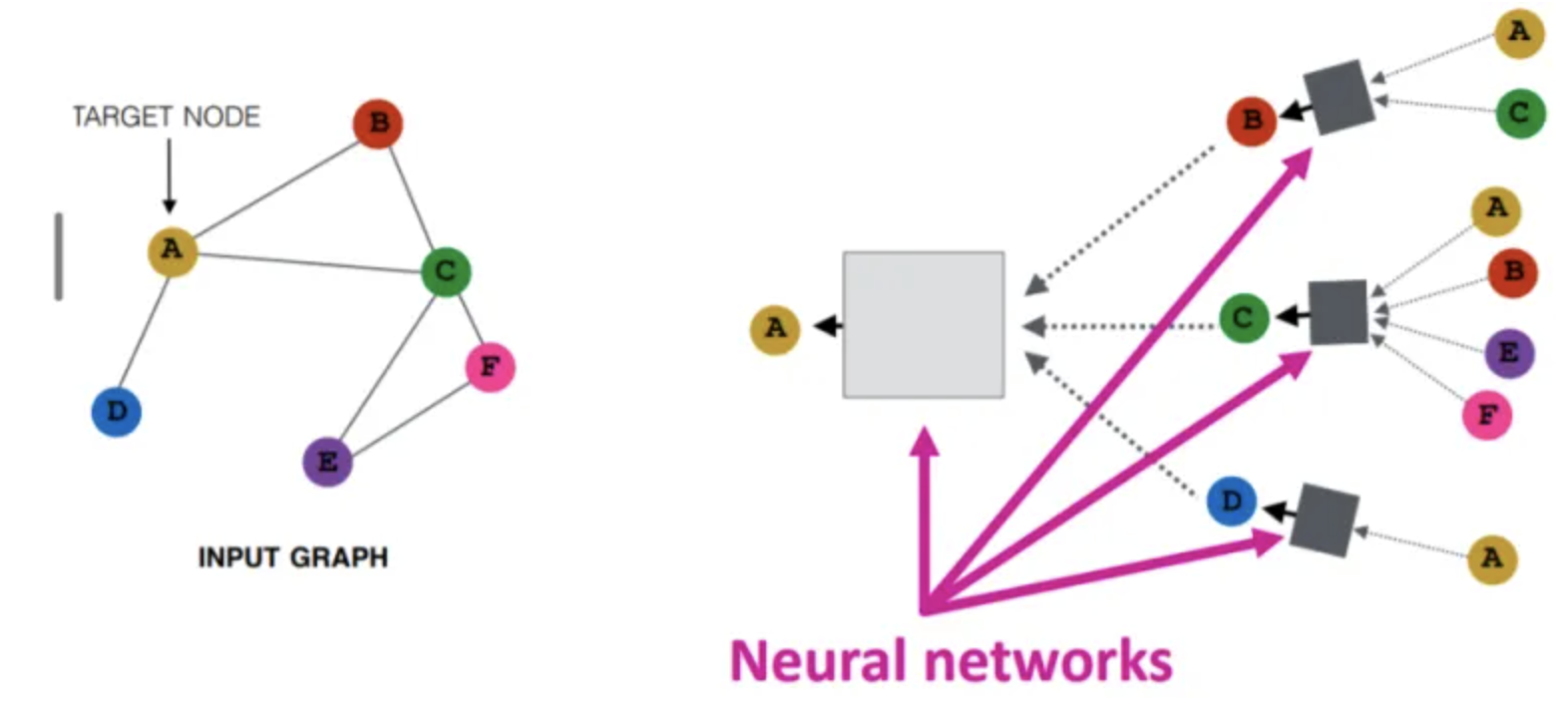
- 训练可以是无监督的,也可以是有监督的。无监督:只使用图结构,相似的结点具有相似的嵌入,无监督损失函数可以是基于结点proximity或随机游走的损失。有监督:执行结点分类任务
- 无监督表示学习:GraphSAGE、Graph Auto-Encoder (GAE)、Deep Graph Infomax (DGI)
- 图的池化
- 简单的max/mean池化:忽略结点顺序
- Graclus聚类算法
- Set2Set方法
- DiffPool可微池化
- 知识图谱和推断:TransE, BetaE
GCN[1]
- 最早由[15]提出
- GCN可由CNN+谱图理论得到,即\(h_v=f(\frac{1}{|N(v)|}\sum_{u\in N(v)}Wx_u+b), \forall v\in V\),其中W表示过滤矩阵,\(\sum_{u\in N(v)}Wx_u\)表示邻域聚合,\(\frac{1}{|N(v)|}\)表示归一化。该式只能捕获一跳结点,堆叠k层可捕获k跳,即\(h_v^{k+1}=f(\frac{1}{|N(v)|}\sum_{u\in N(v)}W^kh_u^k+b^k), \forall v\in V\)
- 对邻域没有限制,Graph Attention Networks (GAT)和Confidence-based GCN (ConfGCN)对此给出解决
GAT[2]
- 对GCN使用自注意力
- 输入特征为\(\mathbf{h}=\{\vec{h_1},\vec{h_2},...,\vec{h_N}\},\vec{h_i}\in R^F\);\(v_j\)相对于\(v_i\)的重要性:\(e_{ij}=a(W\vec{h_i},W\vec{h_j})\),\(\alpha_{ij}=softmax_j(e_{ij})\),\(\alpha_{ij}=\frac{exp(LeakyReLU(\vec{a}^T[W\vec{h_i}||W\vec{h_j}]))}{\sum_{k\in N_i}exp(LeakyReLU(\vec{a}^T[W\vec{h_i}||W\vec{h_k}]))}\)
- k是头的数目,\(\vec{h_i}^{'}=||_{k=1}^K\sigma(\sum_{j\in N_i}\alpha_{ij}^kW^k\vec{h_j})\),最后一层为:\(\vec{h_i}^{'}=\sigma(\frac{1}{K}\sum_{k=1}^K\sum_{j\in N_i}\alpha_{ij}^kW^k\vec{h_j})\)
ConfGCN[3]
- 计算结点重要性:\(r_{uv}=\frac{1}{d_M(u,v)}\),\(d_M(u,v)=(\vec{\mu}_u-\vec{\mu}_v)^T(\Sigma_u^{-1}+\Sigma_v^{-1})(\vec{\mu}_u-\vec{\mu}_v)\),其中\(\vec{\mu}_u\)和\(\vec{\mu}_v\)是标签分布,\(\Sigma_u\)和\(\Sigma_v\)是协方差矩阵
GIN[4]
GraphSAGE[5]
- 可预测新结点的嵌入,使用归纳学习
- 提出三种邻域聚合器(可推断新结点的嵌入)
- \(h_v^k=\sigma([W_k·AGG(\{h_u^{k-1},\forall u\in N(v)\})+B_kh_v^{k-1})\)
- Mean Aggregator: \(AGG=\sum_{u\in N(v)}\frac{h_u^{k-1}}{|N(v)|}\)
- LSTM Aggregator:将LSTM应用于邻居的一个随机排列,即\(AGG=LSTM([h_u^{k-1},\forall u\in \pi(N(v))])\)
- Pooling Aggregator: \(AGG=\gamma(\{Qh_u^{k-1},\forall u\in N(v)\})\),其中\(\gamma\)表示element-wise mean/max
- 损失函数借鉴Word2vec思想(负采样),相邻结点具有相似表示,远离结点表示不同
- \(J_G(\vec{z}_u)=-log(\sigma(\vec{z}_u^T\vec{z}_v))-Q·E_{v_n\sim P_n(v)}log(\sigma(-\vec{z}_u^T\vec{z}_{v_n}))\),第一项表示相邻的结点有相似的表示,Q表示负样本数目,\(P_n(v)\)表示负采样分布,第二项表示远离结点表示不同
Graph Auto-Encoder (GAE)[6]
- 基于VAE(encoder-decoder和采样),encoder使用GCN
- Encoder: \(\mu=GCN_{\mu}(X,A),\sigma=GCN_{\sigma}(X,A),GCN(X,A)=\hat{A}ReLU(\hat{A}XW_0)W_1\)
- Decoder: \(p(A|Z)=\prod_{i=1}^N\prod_{j=1}^NP(A_{ij}|\vec{z}_{i},\vec{z}_{j})\),\(P(A_{ij}=1|\vec{z}_{i},\vec{z}_{j})=\sigma(\vec{z}_{i}^T\vec{z}_{j})\)
- 损失函数:\(L=E_{q(Z|X,A)}[logp(A|Z)]-KL[q(Z|X,A)||p(Z)]\),其中第一项表示重建损失,第二项表示KL散度
Deep Graph Infomax (DGI)[7]
- 需要对图进行破坏,然后对破坏前后的图分别应用GCN
- 原图\((X,A)\),可得到\(H=\varepsilon (X,A)=\{\vec{h}_1,\vec{h}_2,...,\vec{h}_N\}\)
- 破坏后的图\((\tilde{X},\tilde{A})\),可得到\(\tilde{H}=\varepsilon (\tilde{X},\tilde{A})=\{\vec{\tilde{h}}_1,\vec{\tilde{h}}_2,...,\vec{\tilde{h}}_m\}\)
- Readout函数: \(R(H)=\sigma(\frac{1}{N}\sum_{i=1}^N\vec{h}_i)\)
- 最大化图的patch表示的互信息
动态图[8-9]
- RNN+GCN[10]
- DynamicGCN[14]
- 动态社会交互网络[11]: 建模行为模式/建模带有时间戳的社会交互,如人与人之间的眼神交流、说话和倾听,反映人的社会特征和关系
- 之前抽取模式的方法基本依赖复杂的专家知识且得到的特征通常用于特定的任务
- 基于动态网络表示学习的更一般的模型可以被应用,但是社会交互的独特特性导致了严重的模型失配和降低所获得表示的质量
- 动态社会交互网络的表示学习依赖于提取高度动态的节点属性和交互的交织
- 提出时序网络扩散的卷积网络TEDIC:具有某种self-explaining力量
- 采用结点属性在原始网络及其补充的组合上的扩散来捕获嵌入在人们进行或避免接触的行为中的长跳交互模式
- 利用带有层级集合池化操作的时序卷积网络来灵活提取长时间跨度内分散的不同长度交互的模式
- 定义动态图快照:\(\{G_t\}_{1\le t\le T}\),\(G_t=(V_t,E_t)\),假设\(V_t\)是固定的,都为V;动态结点属性\(\{X_t\}_{1\le t\le T}\)
- 网络扩散:以两类具有适当意义的参数参数化扩散过程,一是\(\beta\),区分人们进行交互和避免交互的含义;二是\(\Gamma _k\),描述动态网络中不同跳数交互的影响
- \(\beta \in [0,1]\): 考虑原始交互网络A及其补图\(\overline{A}=11^T-A\),其中\(11^T\)是all-one矩阵;融合这两个网络来得到一个新的邻接矩阵:\(A^{'}=\beta A+(1-\beta)\overline{A}=(2\beta-1)A+(1-\beta)11^T\);更大的\(\beta\)表明进行交互对预测任务更有帮助,更小的\(\beta\)则相反
- 给定属性的图扩散(不同跳),基于随机游走矩阵\(W^{'}=D^{'-1}A^{'}\)
- \(\Gamma _k\): 一组可学习参数\(\{\Gamma _k\}_{k\ge 0}\),k表明不同跳,\(\Gamma _k\)是对角矩阵,其中对角元素\(\gamma_{k,q}\)是第q个输出channel的权重,表明1)不同级别结点属性平滑度的权重2)结点的不同ranks;考虑初始结点属性的变化:\(X_t\in R^{N\times M},H_t=\sum_{k\ge 0}H_t^{(k)}\Gamma _k=\sum_{k\ge 0}(W_t^{'T})^kH_t^{(0)}\Gamma _k,H_t^{(0)}=f(X_t),f(·):R^{N\times M}\to R^{N\times M^{'}}\);\(\Gamma _k\in R^{M^{'}\times M^{'}}\)提供k跳扩散的权重,f可以是identity映射(\(M=M^{'}\))或是多层MLP;在实践中,通常前几跳会有帮助,因此可设置跳数的上限(5~10)
- 网络扩散:以两类具有适当意义的参数参数化扩散过程,一是\(\beta\),区分人们进行交互和避免交互的含义;二是\(\Gamma _k\),描述动态网络中不同跳数交互的影响
- 四个不同社会特征预测任务:欺诈检测、优势识别、紧张检测、社区检测
异质图[12-13]
知识图谱
知识图谱嵌入
- 常用转移距离模型(Translate Distance Model)
- TransE目标是使head实体embedding加上relation embedding接近tail实体embedding
- TransH解决一对多多对多关系,通过计算head和tail实体embedding在关系embedding上的投影,计算投影之间的关系
- TransR通过将head、tail embedding转换到relation embedding空间,使转换后的投影满足三元组的关系
参考文献
- [1] 2017 | ICLR | Semi-supervised classification with graph convolutional networks | Thomas N Kipf and Max Welling.
- [2] 2018 | ICLR | Graph attention networks | Petar Velickovic et al.
- [3] 2019 | Confidence-based Graph Convolutional Networks for Semi-Supervised Learning | Shikhar Vashishth et al.
- [4] 2019 | ICLR | How Powerful are Graph Neural Networks? | Keyulu Xu et al.
- [5] 2017 | NIPS | Inductive Representation Learning on Large Graphs | William L. Hamilton et al.
- [6] 2016 | Variational Graph Auto-Encoders | Thomas N. Kipf and Max Welling
- [7] 2019 | ICLR | Deep Graph Infomax | Petar Velickovic et al.
- [8] 2020 | Foundations and modelling of dynamic networks using Dynamic Graph Neural Networks: A survey | Joakim Skarding et al.
- [9] 2020 | Representation Learning for Dynamic Graphs: A Survey | Seyed Mehran Kazemi et al.
- [10] 2018 | Structured sequence modeling with graph convolutional recurrent networks | Youngjoo Seo et al.
- [11] 2021 | WWW | TEDIC: Neural Modeling of Behavioral Patterns in Dynamic Social Interaction Networks | Yanbang Wang et al.
- [12] 2015 | KDD | PTE: Predictive Text Embedding through Large-scale Heterogeneous Text Networks | Jian Tang et al.
- [13] 2017 | KDD | metapath2vec: Scalable Representation Learning for Heterogeneous Networks | Yuxiao Dong et al.
- [14] 2019 | KDD | Learning Dynamic Context Graphs for Predicting Social Events | Songgaojun Deng et al.
- [15] 2014 | Spectral Networks and Deep Locally Connected Networks on Graphs | Joan Bruna et al.
