自然语言处理基本概念
目录
NLP与深度学习
任务
- 词性标注(Part Of Speech Tagging): 为每个词确定词性
- 句法分析(Parsing): 为一个句子创建一个语法树
- 命名实体识别(Named Entity Recognition): 在一个句子中识别人、地点等
- 语言建模(Language Modeling): 生成自然的句子
- 翻译(Translation): 将一个句子翻译成另一种语言
- 句子压缩(Sentence Compression): 删除词来概括一个句子
- 摘要(Abstractive Summarization): 用新的词概括一段话
- 问答(Question Answering): 给一段话,回答一个问题
word2vec[1-2]
- 用一个向量(数字)来表征单词的语义和词间的联系,以及语法联系;可用大量文本数据对模型进行预训练从而得到嵌入(预训练词向量)
- 前馈神经网络语言模型(NNLM)、循环神经网络语言模型(RNNLM):大部分复杂度是由模型中的非线性隐含层引起的
- 神经网络语言模型训练可分两步成功训练:
- 用简单模型学习连续词向量
- N-gram NNLM基于这些词分布式表示被训练
- 神经网络语言模型训练可分两步成功训练:
- 两种模型架构(Log-linear模型,更简单的模型,不像神经网络那样能精确表示数据,但可在更多数据上进行有效训练),计算词的连续向量表示(分布式表示),最小化计算复杂度,这些表示在词相似性任务上衡量
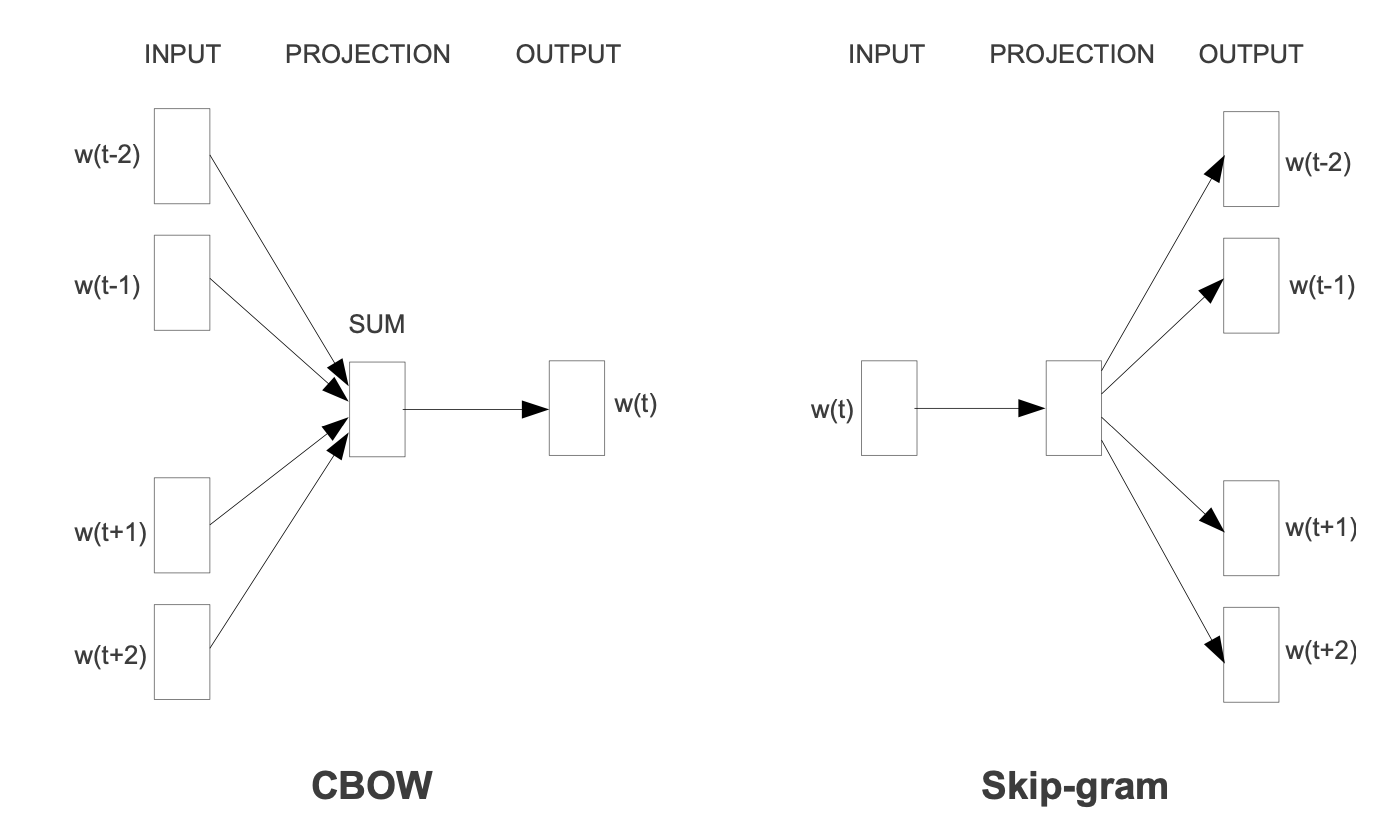
- CBOW(Continuous Bag-of-Words):根据上下文预测当前词
- 与前馈NNLM相似,非线性隐含层被移除,历史中词的顺序不会影响映射,映射层被所有词共享
- 建立一个Log-linear分类器,以4个未来和4个历史词作为输入,训练标准正确分类当前词
- 训练复杂度是:\(Q=N\times D+D\times log_2(V)\),其中映射层维数为\(N\times D\)
- 与标准Bag-of-Words模型不同,它使用连续分布式上下文表示
- (Continuous)Skip-gram:根据当前词预测周围词
- 使用n-gram的方法生成词对作为训练数据
- 使用当前词作为Log-linear分类器的输入,预测在当前词之前和之后一个具体范围内的词;增大范围可改善结果词向量的质量,但也增加了计算复杂度
- 训练复杂度是:\(Q=C\times (D+D\times log_2(V))\),其中C表示词的最大距离
![图片名称]()
- CBOW(Continuous Bag-of-Words):根据上下文预测当前词
- 两种加速训练的trick: hierarchical softmax或负采样negative sampling
- 负采样:在输出层中,我们抽取几个应该为0的维度(根据单词在语料库中出现的次数来决定。出现次数越多,那么越有可能被抽中),再加上为1的维度,来进行训练。这样我们就将softmax问题转换为V个logistic二分类问题(判断当前词和词样本是否是邻居),并且我们每次只更新其中K个负样本与一个正样本的参数,从而大大降低了计算成本
- hierarchical softmax:采用Huffman树。Huffman树的叶子结点就是词汇表中的单词,从根节点到叶子结点的路径就表示单词的概率。这样一样,我们就不需要对所有单词的得分进行求和,就大大降低了计算成本。注意:在构造Huffman树的时候,常用的词的深度会更小一些,即更靠近根节点;而不常用的词会更深一点
- Skip-gram训练开始之前,随机初始化嵌入矩阵和上下文矩阵,前者对应当前词,后者对应词样本,然后计算点积,再使用sigmoid转换成概率;停止训练后,丢弃Context矩阵,并使用Embeddings矩阵作为下一项任务的已被训练好的嵌入
GloVe[15]
- 目标是得到单词的词向量,让其尽可能的包含语义与语法信息
- 思路是从语料库中统计共现矩阵,然后根据共现矩阵与GloVe模型来学习词向量
- GloVe模型与word2vec的对比:
- GloVe模型最大的优点是利用了全局的信息,而word2vec中,尤其是skip-gram,只利用了目标词周边的一小部分上下文。尤其当引入negative sampling训练的时候,丧失了词与词之间的关系信息
- GloVe模型能够加快模型训练速度,并且能够控制词的相对权重
fastText[16-17]
- 和CBOW模型非常地像,其创新的地方在于子词嵌入的引入
- 子词嵌入的好处:对低频词汇的词向量训练效果会更好,因为它可以和其他词共享n-gram
- 输入是一段序列,输出是这段序列的标签类别。中间层仍然是线性的。输出层仍然是softmax。并且在训练的时候,使用hierarchical softmax来加速训练
textCNN
- 对于一些语料中n-gram特征明显的语句,CNN无疑是一个很理想的选择
- 输入层是将语料经过预训练好的Word2Vec模型得到的词向量表达
- channel会是2,考虑静态和非静态,即考虑嵌入是否可调整
- 设句子的长度为n, 词向量的维度为k,得到一个nk的二维矩阵,在此基础上做卷积,设卷积核大小为hk
- 由于卷积核的权重是共享的,因此一个卷积核只能提取到某一类特征;我们有必要采取不同大小的卷积核进行卷积,如h分别为2,3,4的相当于语言模型中的2-gram,3-gram, 4-gram
- 词向量将每个词表达成k维的特征表示,若卷积核宽度小于k,会造成不小的信息损失
ELMo[3]
- 训练两个语言模型,从左到右和从右到左
- 用双向 LSTM 来获取双向语境
- 从网络中抽取上下文化向量
- 词嵌入不应该是不变的
- 上下文词嵌入:\(f(w_k|w_1,...,w_n)\in R^N\)
- \(f(\text{play}|\text{Elmo and Cookie Monster play a game.})\ne f(\text{play}|\text{The Broadway play premiered yesterday.})\)
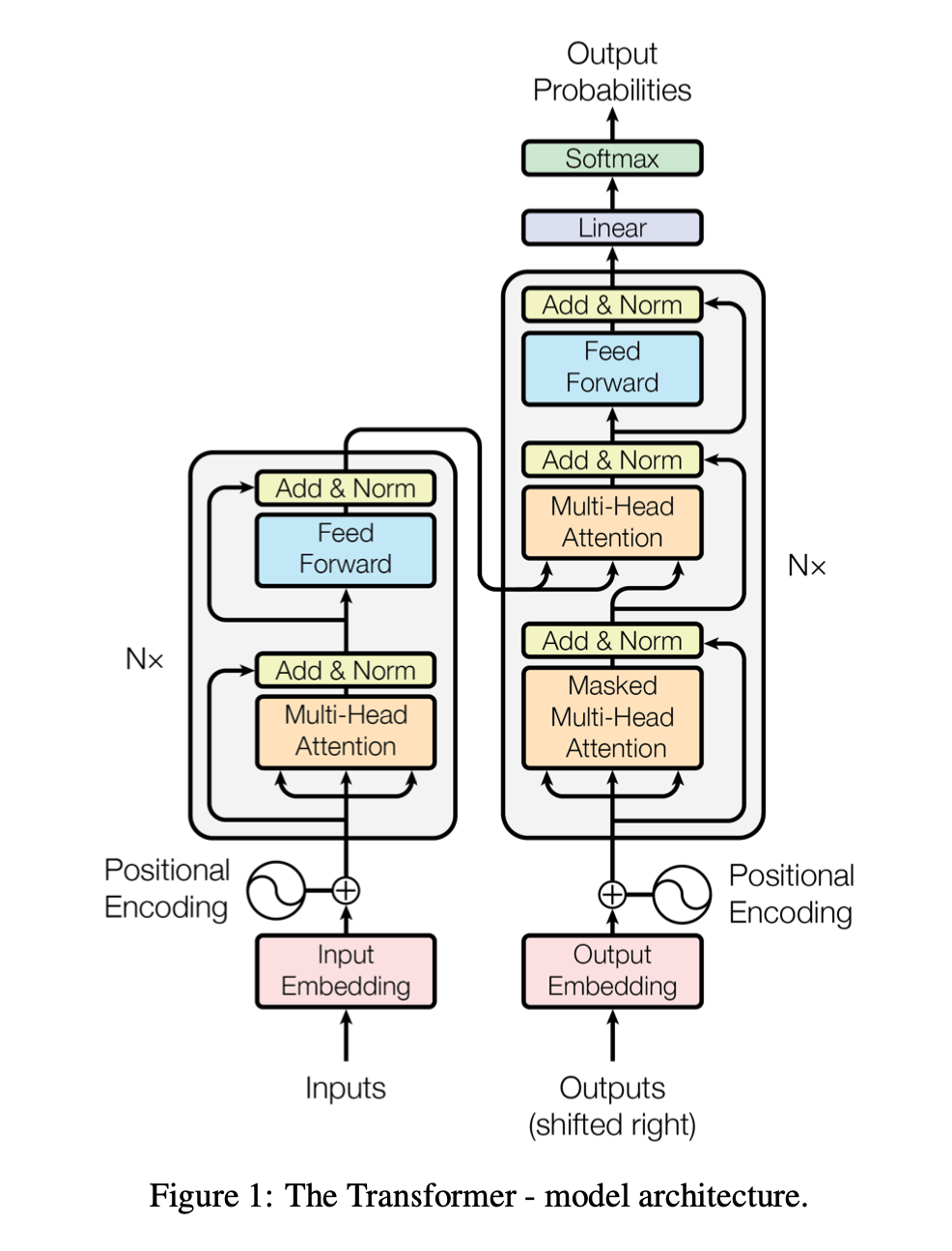
transformer[4]
- encoder-decoder结构
- encoder将输入symbol表示序列\(x_1,...,x_n\)映射成一个连续表示序列\(z_1,...,z_n\)
- decoder在给定\(\vec{z}\)的情况下生成symbol的输出序列\(y_1,...,y_m\),一次一个元素,每一次模型都是自回归的,需要之前生成的symbols作为额外的输入
- RNN解决机器翻译任务时,待翻译的序列(X)的信息被总结在最后一个hidden state(\(h_m\))中,带着原始句子的所有信息的\(h_m\)最终被用来生成被翻译的语言(Y)。但当句子很长的时候,很容易丢失重要信息
- 注意力给出解决方案:仍是encoder-decoder结构,encoder是双向RNN;开始的流程是一致的,encoder获得了输入序列 X 的 hidden state(h),然后decoder就可以开始工作了(在decoding阶段之前对input中的信息赋予不同权重);decoder在生成\(s_t\)和\(y_t\)时,要先利用\(s_{t-1}\)和各个hidden state的联系度,来获得注意力(a),这些注意力最终作为权重对各个h进行加权求和从而得到上下文向量(context),\(y_t\)基于\(s_{t-1}\)、\(y_{t-1}\)和上下文向量生成
- transformer采用上述架构,encoder和decoder都采用堆叠的自注意力和逐点的全连接层,如下图所示
![图片名称]()
- encoder:由6个相同的层组成,每一层有2个子层,首先是一个多头的自注意力机制,然后是一个逐位置全连接前馈网络;每个子层都采用残差连接,然后紧随layer normalization(在特征水平上进行归一化),即\(LayerNorm(x + Sublayer(x))\);均要求维度为512,即\(d_{model}=512\)
- decoder: 也由6个相同的层组成,除了encoder中的两个子层外,还插入第三个子层,即基于encoder输出的多头注意力;也对每个子层采用残差连接,然后紧随layer normalization;修改了decoder中的自注意力子层,防止涉及后续的位置。这种遮蔽与输出嵌入被一个位置偏移的事实相结合确保位置i的预测只能依赖于位置小于i的已知输出
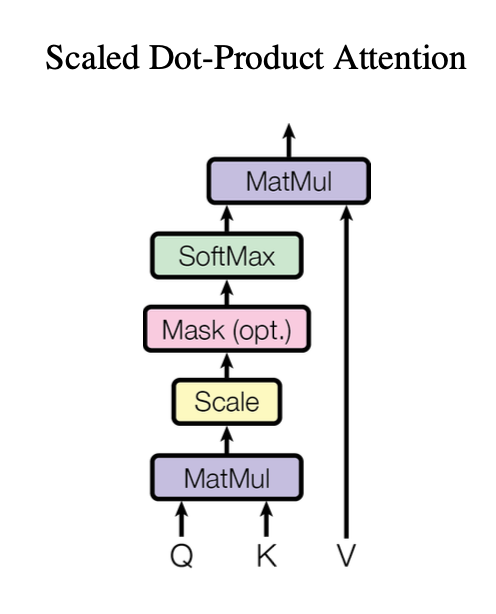
- 注意力:注意力函数可被描述成将一个query和一组key-value对映射到输出,其中query, keys, values和输出都是向量;输出是values的加权和,每个value的权重由query和对应的key的兼容函数计算得到;query和keys的维度为\(d_k\),values的维度为\(d_v\),scale为除以\(\sqrt{d_k}\)
- 一般会在一组queries上同时计算注意力函数,即矩阵Q;Q和K首先会计算联系程度(这里用的是dot-product),然后通过 scale 和 softmax 得到最后的注意力值,这些注意力值跟 V 相乘,然后求和得到最后的输出矩阵。如下图所示。输出为\(Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V\),也可以写成\(h_i^{l+1}=Attention(Q^lh_i^l,K^lh_j^l,V^lh_j^l)\),即\(h_i^{l+1}=\sum_{j\in S}w_{ij}(V^lh_j^l),w_{ij}=softmax_j(Q^lh_i^l·K^lh_j^l)\),其中\(j\in S\)表示句子中的词集合,\(Q^l,K^l,V^l\)是可学习线性权重。注意力机制可在每个词上并行执行。最常用的注意力函数是加注意力和点积注意力,点积注意力和上述算法类似,只是少了scale;加注意力使用具有一个隐含层的前馈网络计算兼容函数;点积注意力更快且更省空间;当\(d_k\)比较小时,这两种机制表现相似,但当\(d_k\)较大时,加注意力表现更好,可能是\(d_k\)变大使得点积注意力在幅度上变大,将softmax函数推到梯度特别小的区域,因此做了scale
![图片名称]()
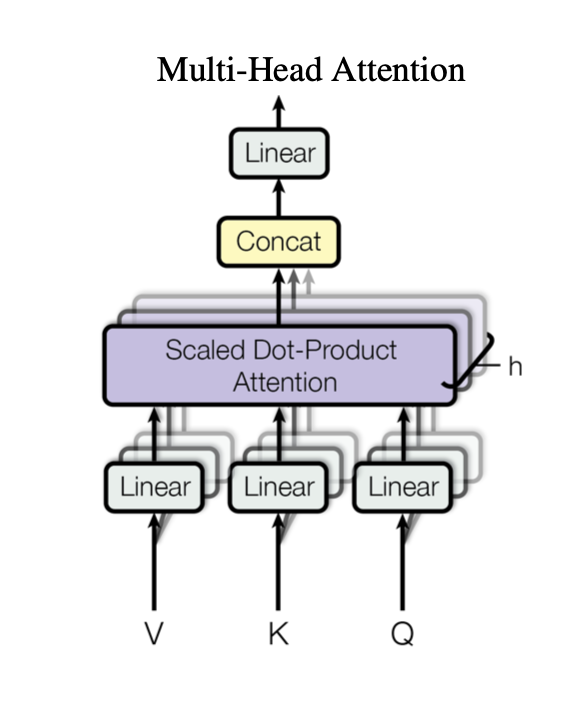
- 多头注意力:并行执行多个注意力函数,如下图所示。公式为\(MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O,head_i=Attention(QW_i^Q,KW_i^K,VW_i^V)\),其中参数矩阵为\(W_i^Q\in R^{d_{model}\times d_k},W_i^K\in R^{d_{model}\times d_k},W_i^V\in R^{d_{model}\times d_v},W^O\in R^{hd_v\times d_{model}}\)
![图片名称]()
- 一般会在一组queries上同时计算注意力函数,即矩阵Q;Q和K首先会计算联系程度(这里用的是dot-product),然后通过 scale 和 softmax 得到最后的注意力值,这些注意力值跟 V 相乘,然后求和得到最后的输出矩阵。如下图所示。输出为\(Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V\),也可以写成\(h_i^{l+1}=Attention(Q^lh_i^l,K^lh_j^l,V^lh_j^l)\),即\(h_i^{l+1}=\sum_{j\in S}w_{ij}(V^lh_j^l),w_{ij}=softmax_j(Q^lh_i^l·K^lh_j^l)\),其中\(j\in S\)表示句子中的词集合,\(Q^l,K^l,V^l\)是可学习线性权重。注意力机制可在每个词上并行执行。最常用的注意力函数是加注意力和点积注意力,点积注意力和上述算法类似,只是少了scale;加注意力使用具有一个隐含层的前馈网络计算兼容函数;点积注意力更快且更省空间;当\(d_k\)比较小时,这两种机制表现相似,但当\(d_k\)较大时,加注意力表现更好,可能是\(d_k\)变大使得点积注意力在幅度上变大,将softmax函数推到梯度特别小的区域,因此做了scale
- transformer使用三种多头注意力
- encoder-decoder注意力(连接encoder和decoder):queries来自之前的decoder,keys和values来自encoder的输出,使得decoder的每个位置都可以参与输入序列中的所有位置
- 自注意力抛弃LSTM,RNN,CNN等,指的不是目标和源之间的注意力机制,而是源内部元素之间或者目标内部元素之间发生的注意力机制;所有的keys, values和queries都来自相同地方
- 自注意力在encoder和decoder中是不一样的,decoder只能看到前面的信息,但是encoder可以看到完整的信息(双向信息)
- 自注意力、RNN、CNN均是将一个变长的symbol表示序列\(x_1,...,x_n\)映射成另一个等长的序列\(z_1,...,z_n\),其中\(x_i,z_i\in R^d\);之所以选择自注意力原因有三,一是每层总的计算复杂度,二是可并行的计算量(由需要的最小序列操作数来衡量),三是网络中远程依赖之间的路径长度
- 逐点前馈网络:单独应用于每个位置;包含两个线性变换和一个ReLU激活,即\(FFN(x) = max(0, xW_1 + b_1 )W_2 + b_2\);尽管不同位置的线性变换是一样,但不同层使用不同参数
- 还可以是两个卷积,核尺寸为1,输入输出的维度为\(d_{model}\)
- 嵌入层:将输入tokens和输出tokens转换成维度为\(d_{model}\)的向量
- 位置编码:既然模型没有包含循环和卷积,为了使模型包含序列的顺序,将位置编码加到嵌入中;位置编码的维度为\(d_{model}\)
- \(PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}}),PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})\),其中pos是位置,i是维度,即位置编码的每个维度对应于一个sinusoid正弦波,波长形成一个几何级数progression,从\(2\pi\)到\(10000·2\pi\);之所以选择这个函数,是因为我们假设它可以让模型通过相对位置轻松地学习参与,即\(PE_{pos+k}\)可由\(PE_{pos}\)的一个线性函数表示;选择正弦版本,因为它可能允许模型外推序列长度比训练中遇到的更长
- 位置编码:既然模型没有包含循环和卷积,为了使模型包含序列的顺序,将位置编码加到嵌入中;位置编码的维度为\(d_{model}\)
- Transformer-decoder[5]
- 去掉encoder,本来Transformer中的decoder是要接收encoder那边对输入(m)处理后得到的信息,然后得到最终输出y,而且在得到后面的y的时候,要考虑前面已经生成的y,因此在去掉encoder之后,decoder在考虑y的同时也得考虑m的信息
- Transformer-XL[6]
- 让Transformer回归了自回归的本性,也让Transformer可以处理的序列更长了
预训练模型
GPT[7]
- 训练transformer语言模型(预训练一个常见架构)
- 在更长的文本上训练,具有自注意力,能很好地进行扩展(如GPT-2[10]和GPT-3[11]),不是双向的
- GPT-2和GPT-3取消了微调,前者模型会自动识别出来需要做什么任务
- GPT-3采用一个新的评估策略: zero shot,假设没有有标签数据;该模型是目前最大的密集模型之一;few shot性能很惊人,
BERT[8]
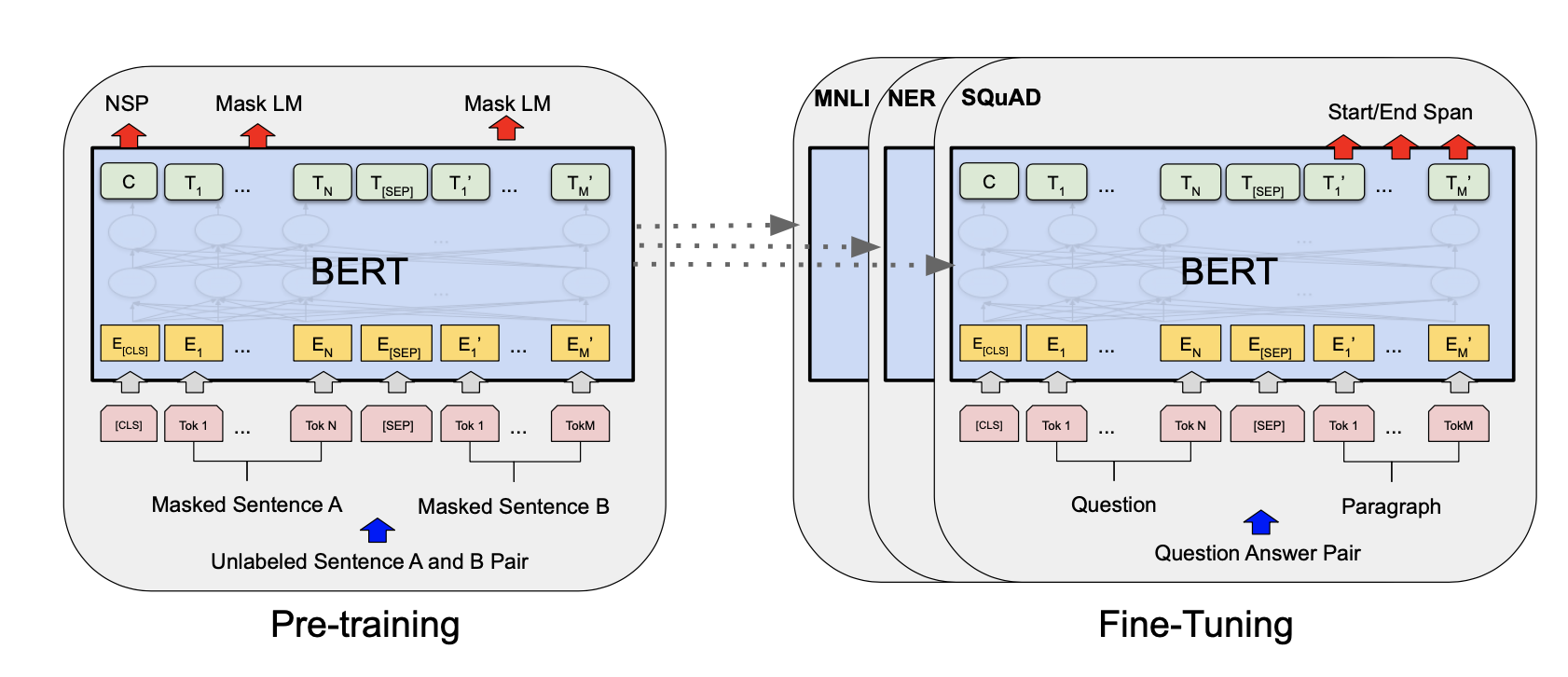
- 框架包含两步:预训练和微调;在预训练中,模型在不同的预训练任务中对未标记数据进行训练;在微调中,模型先以预训练参数初始化,然后使用来自下游任务的有标记数据对所有参数进行微调
- BERT的独特之处在于其跨不同任务的统一架构,预训练架构和最终的下游架构之间的差异很小
- 模型架构:多层双向Transformer encoder(双向自注意力)
- 每一层为一个Transformer block,共有L层;隐含尺寸为H;自注意力头数为A
- 输入输出表示:为了使BERT能够处理不同的下游任务,输入表示既可以表示单个句子,也可以表示一对句子,即<Question, Answer>;一个句子可以是一段任意长度的文本,而非一个真正的句子;BERT的一个输入序列可以是一个句子,也可以是两个句子
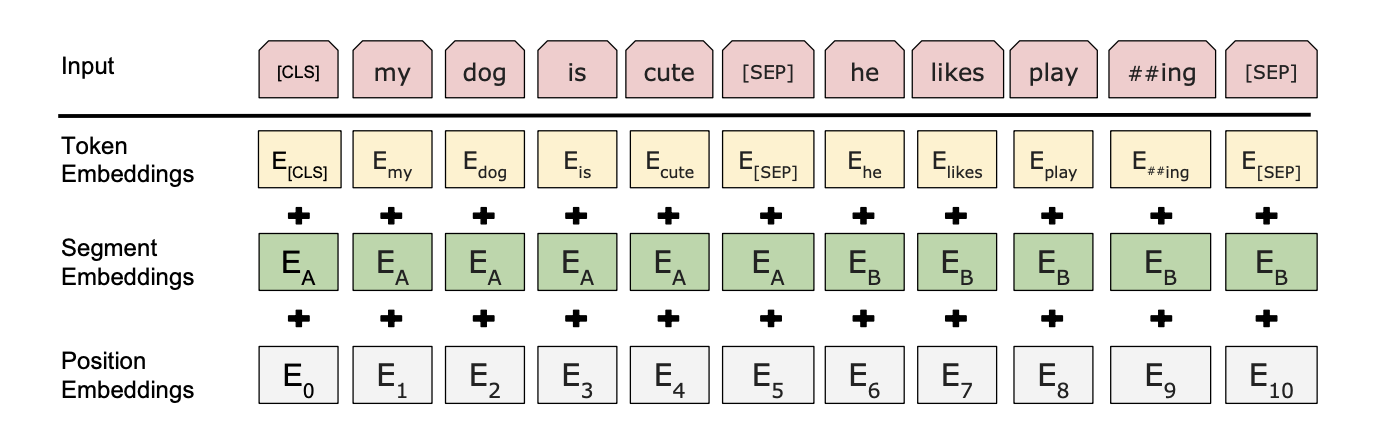
- 使用WordPiece嵌入,共有30000个token词汇;每个序列的第一个token总是一个特殊的分类token,即[CLS];对应于这个token的最后隐含状态用作分类任务的聚合序列表示
![图片名称]()
- 句子对被压缩成一个单一的序列;以两种方式区分句子,一是用一个特殊的token [SEP]分开它们,二是在每个token中添加一个学习到的嵌入来指明它是属于句子A还是句子B;如下图左侧所示,输入嵌入为E,[CLS]的最后隐含向量为\(C\in R^H\),第i个输入token的最后隐含向量为\(T_i\in R^H\)。输入的创建可见上图,由对应的token、segment和位置嵌入相加
![图片名称]()
- 使用WordPiece嵌入,共有30000个token词汇;每个序列的第一个token总是一个特殊的分类token,即[CLS];对应于这个token的最后隐含状态用作分类任务的聚合序列表示
- 预训练BERT:使用两个无监督的任务来预训练
- 遮蔽语言模型(MLM)(联合建模左右上下文):为了训练一个双向表示,随机遮蔽部分输入tokens,然后预测那些被遮蔽的tokens;被遮蔽的tokens的最后隐含向量被喂给输出softmax(词汇大小)
- 自编码模型,假设那些被遮蔽的token是独立的
- BERT在预训练期间使用的 [MASK] 等人工符号,也就是在输入中加入了部分噪音,这会导致预训练和微调之间出现差异;为了缓解这个问题,不总是用[MASK] token来替代遮蔽token,而是80%的时间使用[MASK] token来替代,10%的时间用随机token,剩余10%的时间不替换;\(T_i\)会被用来预测原始token(交叉熵损失函数)
- 下个句子预测(NSP):许多下游任务如问答(QA)和自然语言推断(NLI)都是基于理解两个句子之间的关系,不能直接由语言建模捕获;为了训练模型理解句子关系,预训练二元化下个句子预测任务,即每个预训练例子,50%的时间B是A下个句子,50%不是;C被用于下个句子预测
- 遮蔽语言模型(MLM)(联合建模左右上下文):为了训练一个双向表示,随机遮蔽部分输入tokens,然后预测那些被遮蔽的tokens;被遮蔽的tokens的最后隐含向量被喂给输出softmax(词汇大小)
- 微调BERT:微调是很简单的,因为Transformer中的自注意力机制允许BERT对许多下游任务建模——无论它们涉及单个文本还是文本对,都是通过交换适当的输入和输出;对于涉及文本对的应用,一种常见的模式是在应用双向交叉注意力之前对文本对进行独立编码;BERT使用了自注意力机制来统一这两个阶段,因为编码一个具有自注意力的串联文本对有效地包含了两个句子之间的双向交叉注意力
RoBERTa[9]
- 扩展数据而非模型大小,增加批大小,简化损失
ALBERT[12]
- 通过几种优化策略来获得比BERT小得多的模型
T5[13]
- 扩展双向模型
- 将所有任务统一进一个seq2seq框架
- seq2seq添加了很多灵活性
- 使用seq2seq填充遮蔽spans
- 每个任务是text-to-text
XLNet[14]
- 自回归模型,使用乘积法则对联合概率进行建模
- 解决双向语境问题:将输入乱序,找到所有的排列组合,并按照这些排列组合进行因式分解
参考文献
- [1] 2013 | Efficient Estimation of Word Representations in Vector Space | Mikolov, Tomas et al.
- [2] 2013 | Distributed Representations of Words and Phrases and their Compositionality | Tomas Mikolov et al.
- [3] 2018 | Deep contextualized word representations | Matthew E. Peters et al.
- [4] 2017 | Attention is all you need | Ashish Vaswani et al.
- [5] 2018 | Generating Wikipedia by Summarizing Long Sequences | Peter J. Liu et al.
- [6] 2019 | Transformer-xl: Attentive language models beyond a fixed-length context | Zihang Dai et al.
- [7] 2018 | Improving Language Understanding by Generative Pre-Training | Alec Radford et al.
- [8] 2018 | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | Jacob Devlin et al.
- [9] 2019 | RoBERTa: A Robustly Optimized BERT Pretraining Approach | Yinhan Liu et al.
- [10] 2018 | Language Models are Unsupervised Multitask Learners | Alec Radford et al.
- [11] 2020 | Language Models are Few-Shot Learners | Tom B. Brown et al.
- [12] 2020 | ICLR | Albert: A lite bert for self-supervised learning of language representations | Lan Z et al.
- [13] 2019 | Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer | Colin Raffel et al.
- [14] 2020 | XLNet: Generalized Autoregressive Pretraining for Language Understanding | Zhilin Yang et al.
- [15] 2014 | GloVe: Global Vectors for Word Representation | Jeffrey Pennington et al.
- [16] 2017 | Enriching Word Vectors with Subword Information | Piotr Bojanowski, Edouard Grave et al.
- [17] 2017 | Bag of Tricks for Efficient Text Classification | Armand Joulin et al.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号