

语言模型
目录
定义
- \(p(w_1,...,w_n)=\prod_{i=1,...,n}p(w_i|w1,...,w_{i-1})\),\(p(w_i|w1,...,w_{i-1})\)通常是一个(循环)神经网络
- 2018年之前用于文本生成,如机器翻译和语音识别;2018年之后,在大量数据上预训练,在任何特定任务上微调
词嵌入
Word2Vec[7,8]
- 用一个向量(数字)来表征单词的语义和词间的联系,以及语法联系;可用大量文本数据对模型进行预训练从而得到嵌入(预训练词向量)
- 前馈神经网络语言模型(NNLM)、循环神经网络语言模型(RNNLM):大部分复杂度是由模型中的非线性隐含层引起的
- 神经网络语言模型训练可分两步成功训练:
- 用简单模型学习连续词向量
- N-gram NNLM基于这些词分布式表示被训练
- 神经网络语言模型训练可分两步成功训练:
- 两种模型架构(Log-linear模型,更简单的模型,不像神经网络那样能精确表示数据,但可在更多数据上进行有效训练),计算词的连续向量表示(分布式表示),最小化计算复杂度,这些表示在词相似性任务上衡量
- CBOW(Continuous Bag-of-Words):根据上下文预测当前词
- 与前馈NNLM相似,非线性隐含层被移除,历史中词的顺序不会影响映射,映射层被所有词共享
- 建立一个Log-linear分类器,以4个未来和4个历史词作为输入,训练标准正确分类当前词
- 训练复杂度是:\(Q=N\times D+D\times log_2(V)\),其中映射层维数为\(N\times D\)
- 与标准Bag-of-Words模型不同,它使用连续分布式上下文表示
- (Continuous)Skip-gram:根据当前词预测周围词
- 使用当前词作为Log-linear分类器的输入,预测在当前词之前和之后一个具体范围内的词;增大范围可改善结果词向量的质量,但也增加了计算复杂度
- 训练复杂度是:\(Q=C\times (D+D\times log_2(V))\),其中C表示词的最大距离
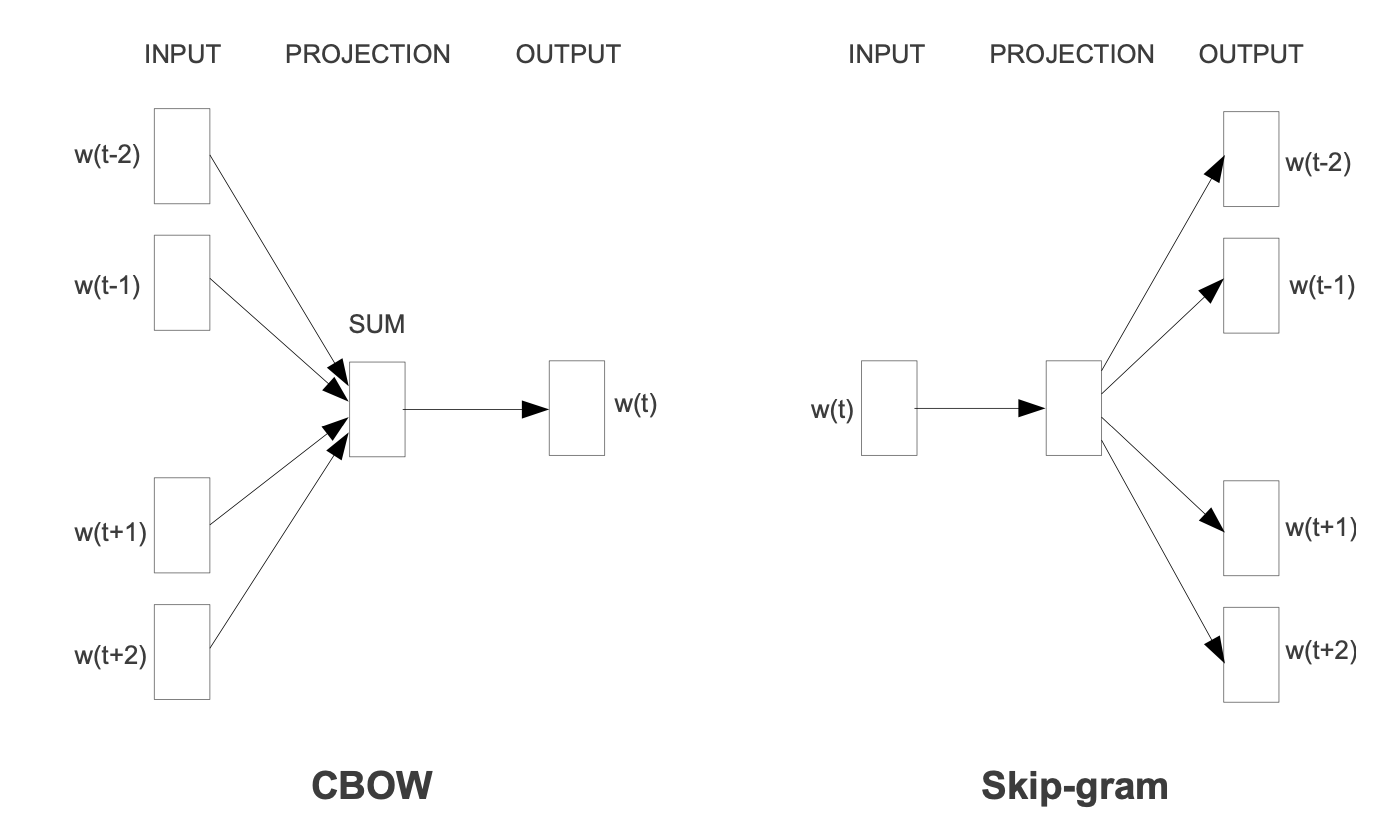
- CBOW(Continuous Bag-of-Words):根据上下文预测当前词
- 使用hierarchical softmax或负采样negative sampling
ELMo[1]
- 训练两个语言模型,从左到右和从右到左
- 用双向 LSTM 来获取双向语境
- 从网络中抽取上下文化向量
- 词嵌入不应该是不变的
- 上下文词嵌入:\(f(w_k|w_1,...,w_n)\in R^N\)
- \(f(\text{play}|\text{Elmo and Cookie Monster play a game.})\ne f(\text{play}|\text{The Broadway play premiered yesterday.})\)
注意力
- 注意力机制[9]里主要有三个向量: key/K, query/Q 和 value/V
- 注意力计算过程:Q 和 K 首先会计算联系程度(这里用的是 dot-product),然后通过 scale 和 softmax 得到最后的注意力值,这些注意力值跟 V 相乘,然后得到最后的矩阵
- RNN解决机器翻译任务时,待翻译的序列(X)的信息被总结在最后一个hidden state(\(h_m\))中,带着原始句子的所有信息的\(h_m\)最终被用来生成被翻译的语言(Y)。但当句子很长的时候,很容易丢失重要信息
- 注意力给出解决方案:仍是encoder-decoder结构,encoder是双向 RNN;开始但流程是一致的,encoder 获得了输入序列 X 的 hidden state(h),然后decoder就可以开始工作了;decoder在生成\(s_t\)和\(y_t\)时,要先利用\(s_{t-1}\)和各个hidden state的联系度,来获得注意力(a),这些注意力最终作为权重对各个h进行加权求和从而得到上下文向量(context),\(y_t\)基于\(s_{t-1}\)、\(y_{t-1}\)和上下文向量生成
- transformer: 使用两种注意力——自注意力和encoder-decoder注意力
- 自注意力抛弃LSTM,RNN,CNN 等,指的不是目标和源之间的注意力机制,而是源内部元素之间或者目标内部元素之间发生的注意力机制
- 自注意力在 encoder 和 decoder 中是不一样的,decoder只能看到前面的信息,但是encoder可以看到完整的信息(双向信息)
- encoder-decoder注意力连接 encoder 和 decoder
- 自注意力抛弃LSTM,RNN,CNN 等,指的不是目标和源之间的注意力机制,而是源内部元素之间或者目标内部元素之间发生的注意力机制
- Transformer-decoder[10]
- 去掉encoder,本来Transformer中的decoder是要接收encoder那边对输入(m)处理后得到的信息,然后得到最终输出y,而且在得到后面的y的时候,要考虑前面已经生成的y,因此在去掉encoder之后,decoder在考虑y的同时也得考虑m的信息
- Transformer-XL[12]
- 让Transformer回归了自回归的本性,也让Transformer可以处理的序列更长了
语言模型预训练
GPT[2]
- 训练transformer语言模型(预训练一个常见架构)
- 在更长的文本上训练,具有自注意力,能很好地进行扩展(如GPT-2[13]和GPT-3[6]),不是双向的
- GPT-2和GPT-3取消了微调,前者模型会自动识别出来需要做什么任务
- GPT-3采用一个新的评估策略: zero shot,假设没有有标签数据;该模型是目前最大的密集模型之一;few shot性能很惊人,
BERT[3]
- 训练遮蔽语言模型,联合建模左右上下文
- 引入新任务:预测遗失/遮蔽词
- 双向推理对许多任务是重要的
- 自编码模型,假设那些被遮蔽的token是独立的
- BERT在预训练期间使用的 [MASK] 等人工符号,也就是在输入中加入了部分噪音,这会导致预训练和微调之间出现差异
RoBERTa[4]
- 扩展数据而非模型大小,增加批大小,简化损失
ALBERT[14]
- 通过几种优化策略来获得比BERT小得多的模型
T5[5]
- 扩展双向模型
- 将所有任务统一进一个seq2seq框架
- seq2seq添加了很多灵活性
- 使用seq2seq填充遮蔽spans
- 每个任务是text-to-text
XLNet[11]
- 自回归模型,使用乘积法则对联合概率进行建模
- 解决双向语境问题:将输入乱序,找到所有的排列组合,并按照这些排列组合进行因式分解
预训练的限制
- 模型训练只可能出现在高资源实验室中
微调
few-shot learning
semi-supervised learning
参考文献
- [1] 2018 | Deep contextualized word representations | Matthew E. Peters et al.
- [2] 2018 | Improving Language Understanding by Generative Pre-Training | Alec Radford et al.
- [3] 2018 | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | Jacob Devlin et al.
- [4] 2019 | RoBERTa: A Robustly Optimized BERT Pretraining Approach | Yinhan Liu et al.
- [5] 2019 | Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer | Colin Raffel et al.
- [6] 2020 | Language Models are Few-Shot Learners | Tom B. Brown et al.
- [7] 2013 | Efficient Estimation of Word Representations in Vector Space | Mikolov, Tomas et al.
- [8] 2013 | Distributed Representations of Words and Phrases and their Compositionality | Tomas Mikolov et al.
- [9] 2017 | Attention is all you need | Ashish Vaswani et al.
- [10] 2018 | Generating Wikipedia by Summarizing Long Sequences | Peter J. Liu et al.
- [11] 2020 | XLNet: Generalized Autoregressive Pretraining for Language Understanding | Zhilin Yang et al.
- [12] 2019 | Transformer-xl: Attentive language models beyond a fixed-length context | Zihang Dai et al.
- [13] 2018 | Language Models are Unsupervised Multitask Learners | Alec Radford et al.
- [14] 2020 | ICLR | Albert: A lite bert for self-supervised learning of language representations | Lan Z et al.
