


从MySQL大量数据清洗到TiBD说起
从MySQL大量数据清洗到TiBD说起
一、业务场景:
公司主要做的业务是类似贝壳的二手房租售,数据库中存了上亿级别的房源数据,之前数据库使用的是 mysql,后面需要将 mysql 数据库切换成了 Tidb,在切换的过程中,需要将老库的数据经过数据清洗后再存入新库(因为有一些表结构的设计变了),其中我们处理的一个逻辑就是将房间下业主信息从老库清洗到新库:我们需要按照城市维度,查询新库所有的房间,然后拿着新老库的房间对应关系,再到老库中找到所有对应的房间,然后通过房间再找到每个房间对应的业主信息,最后将业主的不同维度信息(一共5个维度信息)清洗到新库的不同数据表中。下面我就简单描述一下数据清洗过程中遇到的各种问题以及解决方案,所有问题都会附上真实的案例和说明
二、从问题入手选定处理方案:
问题:
1、在清洗过程工,我们无法将某个城市的几百万甚至上千万的房间信息一次性查询出来,再去找所有房间的业主信息,这样内存肯定会撑爆;
2、数据清洗过程中肯定不能一条一条的新增数据,这样的话几百万(举例300W)的房间数据,有5个维度需要新增数据,那么就会一条一条的新增300W房间对应维度的数据,就会操作 300W*5 次,效率低下;
3、数据清洗后批量插入新表的时候也不能一次性插入300W(每个表插入300W,5个维度分别插入5个表,即插入5次300W的数据)。
处理方案:
先查询出需要清洗的数据总量,然后按照某个量(比如:1000条)进行分页查询出具体的数据,然后清洗这1000条房间对应维度的数据并插入新库中,再清洗下一个1000条数据,直到把所有数据清洗完成。
三、按照上面选定的处理方案,分页进行清洗数据
在上面处理方案出来后,下面就是在程序开发过程中遇到的一些具体问题,分页查询的逻辑其实就是常用的 SQL 的 limit m, n,通过 page 和 pageSize 来进行分页查询,再使用 limit m,n 进行分页查询的时候又遇到下面几个问题:
a、分页查询查询和处理新增数据,按照多大的量来进行分页查询,是一次性查询5000条房间还是1000条房间来处理对应数据的清洗,使得查询和处理的效率最高效?
b、如果一次性查询和处理较少的数据量,比如每次分页查询出100条数据来进行清洗,如果某城市有800W的数据,分页查询需要查询处理80000次,这个处理次数是否过多?
c、使用常规的 limit m,n 的方式进行分页查询,那么越查询到靠后的页数( limit m,n 语句的查询时间与起始记录的 m 位置成正比)查询就会变得越慢,如何处理?
解决方案:
注:下面所有的数据都是在公司的机器上面得出的效率数据,大家在使用的时候以实际为准,这里只是提供解决思路
1、下面先附上一张我们和DBA的聊天来引出问题:
公司大量业务都开始使用TiDB,很多数据都需要从MySQL迁移到TiDB,在迁移过程中,批量新增都会遇到一个问题,就是随着批量新增的数据量变大,耗时巨慢,DBA说的是100条以内就非常快,那么这个条数多少条对于我们业务处理是最合理的啦?下面就是一个论证过程。
下面直接上数据,后面会对数据进行说明:
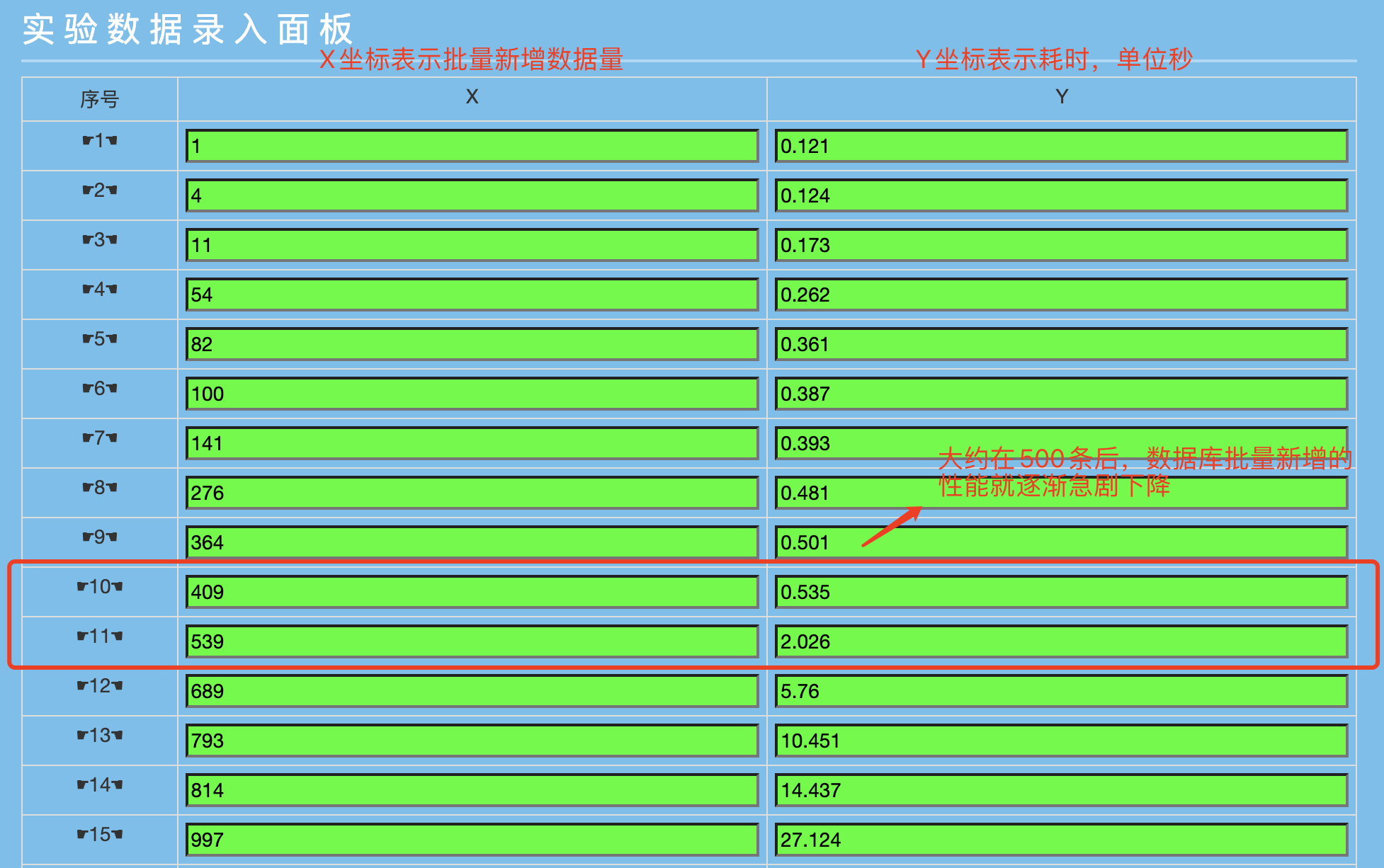
关注(注意横纵坐标的含义):
批量新增409条数据变成539条数据,耗时却从0.535变到2.026秒,多了130数据,耗时却多了1.5秒左右;
批量新增536条数据到689条,多了150条数据,耗时却多了3秒多;
批量新增689条到793条,数据多了104条数据,耗时却多了5秒;
批量新增793条到997条,数据多了204条,耗时却多了17秒。
根据上图生成的数据耗时性能坐标图,斜率越低说明性能越好。

从图中粗略的可以看出,在409到539条之间,应该有一个合理的性能保证值,我们姑且认为大概在批量处理500条(更为精确的值需要在409-539之间进行更细的数据进行测试)的时候,性能是一个分水岭,即:在批量处理500条房间以内对应的数据,性能较好,超过500条后性能开始按照指数增长的方式下降。(注:为了表明数据的真实性,不是我自己瞎编乱造的数据,附上公司数据清洗的几张 log 日志图,用于说明情况。)

批量处理1条房间对应的数据,耗时0.121秒

批量处理54条房间对应的数据,耗时0.262秒

批量处理276条房间对应的数据,耗时0.481秒

批量处理409条房间对应的数据,耗时0.535秒

批量处理539条房间对应的数据,耗时2.026秒
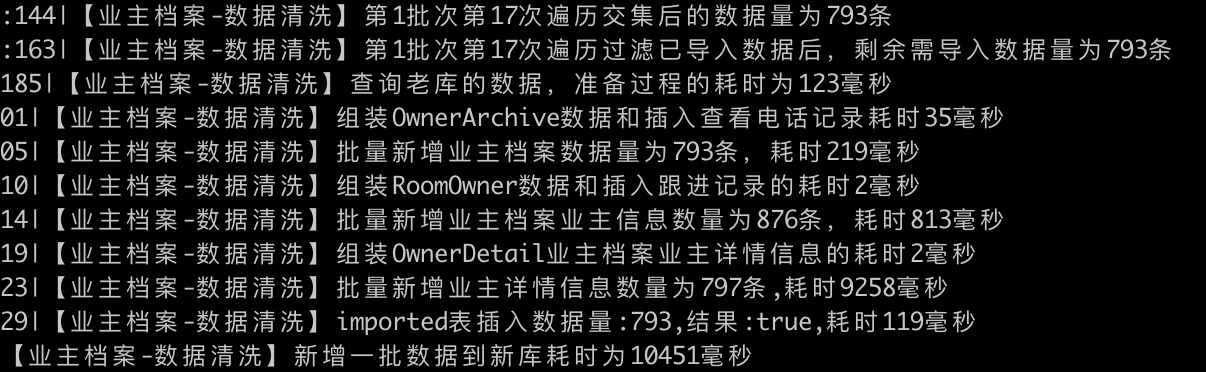
批量处理793条房间对应的数据,耗时10.451秒

批量处理997条房间对应的数据,耗时27.124秒
说明:从日志可以看出,我们批量新增对应 m 个房间对应的数据,实际上需要处理6个维度(5个业务维度+1个清洗记录维度)的数据:
1、房间对应【业主档案维度】;
2、房间对应【查看电话记录信息维度】;
3、房间对应【跟进记录信息维度】;
4、房间对应【业主基本信息维度】;
5、房间对应【业主详情信息维度】;
6、房间对应【导入记录维度】(防止重复导入)。
即:一个房间信息,可能下面没有联系人的信息,所以该房间就没有业主档案,也可能有多个联系人,那么这时就会有业主档案,并且该业主档案就对应多个业主信息(业主详情信息要根据查询看是否存在业主详情信息),并且该房间下的业主,如果经济人跟进维护及时,那么就会有多条查看电话记录信息和跟进记录。
所以在查询1000条的房间信息的时候,实际导入数据的效率取决于我们剩下5个业务维度的数据量,在此次文档中我们暂且按照1个房间信息分别对应1条业务维度来说明,实际业务可以根据自身实际导入时间来处理。我们来看下面这两个1000条房间对应998条数据的导入时间:

从上面也可以看出来,处理998条房间时,对应5个业务维度(业务维度数据字段较多)都比较耗时,其中批量新增查看电话记录耗时10秒+(这个日志当时没有记录插入多少条记录查看电话记录数据,后期优化一下以便更加清楚的查看插入数据的耗时情况),而批量新增业主档案信息也是在1300+条数据,耗时也是在10秒左右。就这个也不难看出,单独批量插入1000条左右的数据,性能也比较低。
总结如下,在批量新增数据的时候,插入数据的耗时:
(1)和你的业务数据复杂度有关,插入1000条2个字段肯定比你插入1000条同级别类型的20个字段数据快很多(大家这时回看上面的所有日志,从1条到998条,会发现倒数第二行插入imported表的数据都比较快,都在是150毫秒以内,是因为我们imported和业务无关,是用来记录我们哪些房间数据已经被清洗了,下一次清洗的时候防止重复清洗,所以插入的数据字段较少,性能从1到998变化不大,但不大并不表示没有,观察发现随着数据量增多耗时也在增多,如果单独统计imported的批量新增性能变化点可能是在5000,也可能是在8000,但是这个对于我们业务没有意义,也不是我们这个清洗的瓶颈点,所有我们整篇讨论是建立处理对应N条房间的维度,而不是某一个业务维度的耗时,因为单个维度耗时对于我们业务是没有统计意义,也无法对我们整体数据清洗性能优化提供太多的帮助)。
(2)插入的数据在某个值的时候性能会变低,那么我们在批量新增的时候尽量不要超过这个值,按照我们业务测试来看是在500条左右。
2、上面讨论的是每一次处理,即批量处理大概在多少条数据比较合理,下面讨论的就是我们在处理分页查询的问题。
在分页查询时,我们使用普通的 limit m,n 每次查询1000条房间数据来处理,整个过程如下:
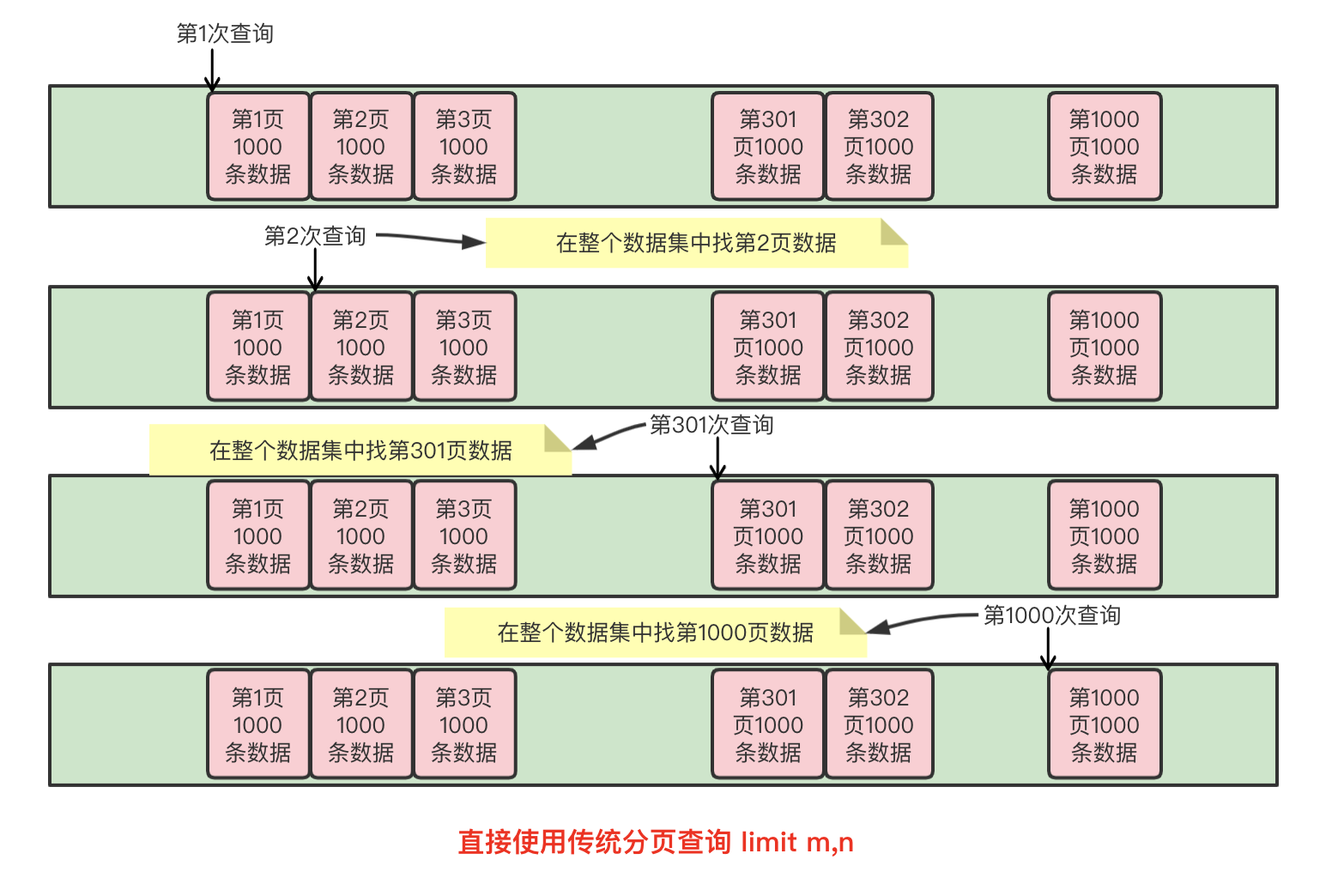
使用常规的 limit m,n 的方式进行分页查询,那么越查询到靠后的页数查询就会变得越慢( limit m,n 语句的查询时间与起始记录的 m 位置成正比),日志分页查询变慢截图如下:
![]()
![]()
![]()
![]()
![]()
从上面几张图可以明显看出,当查询到后面分页的数据的时候,耗时明显增加(这个是最早开始清洗的时候,已经没有日志文件了,截图是之前和DBA聊天的截图,所以比较模糊,系统只保留最近一个月的日志记录,从截图看查询速度还比较快,是因为刚开始清洗到系统的房间较少,所以查询前几十页都是几百毫秒内,但是当查询到第300批次(页)的时候,就变成了2627毫秒了)。
那么如何解决这种查询啦?那么我们可以通过主键来限制每次查询的数据集,即后一次查询的查询范围应该排除之前已经查询过的数据,这种思想有点类似于移动游标,每次查询通过主键 rid,查询的范围保证 rid> m ,这个 m 是上一次查询记录的最大值(所以在查询的时候需要主键排序),于是查询就变成了where rid > m limit 0 , n ,其中 m 就充当了游标点,通过移动游标,查询指定 n 条数据,这时游标的作用就有两个:1、定位查询的数据 2、缩小查询数据集范围。
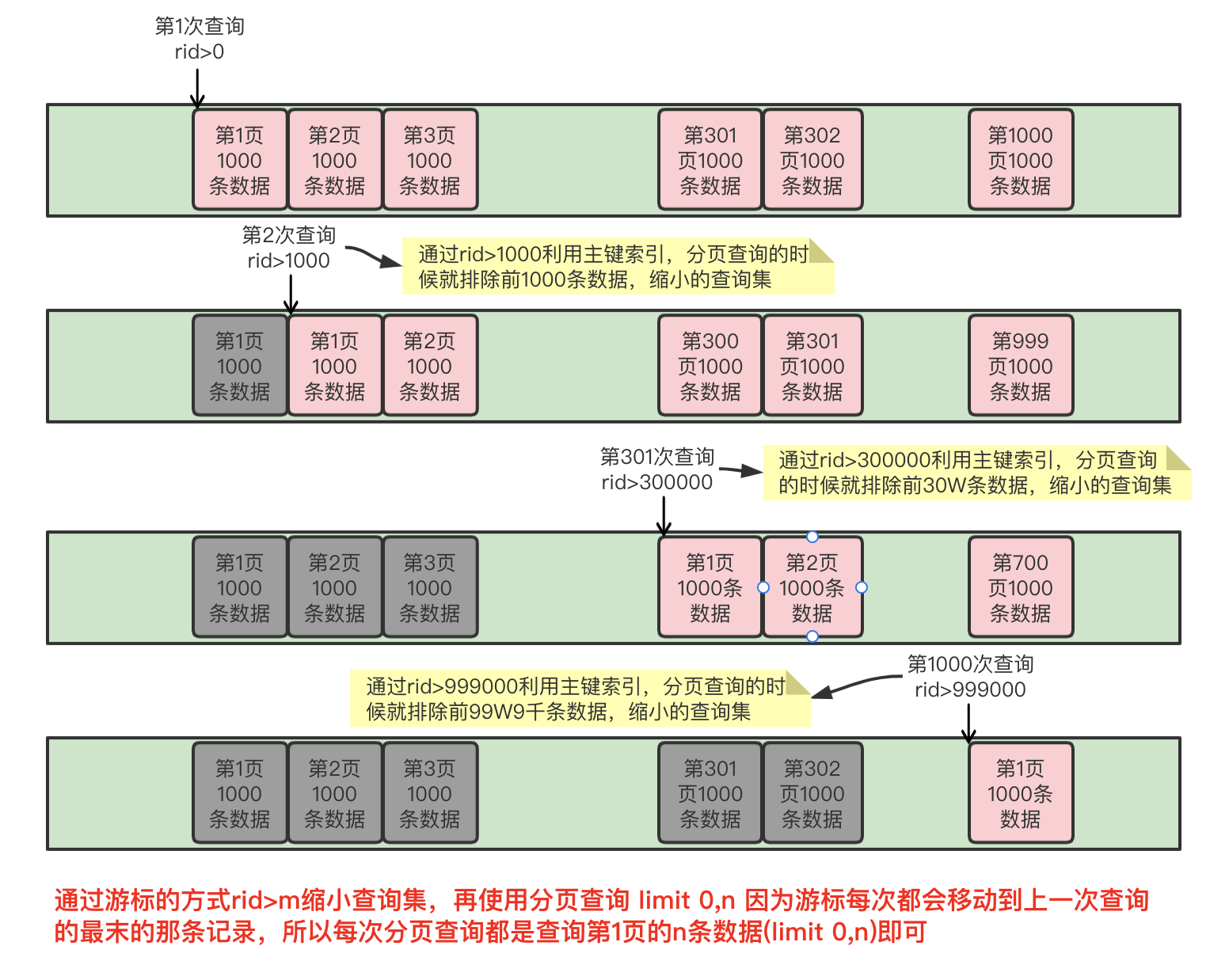
总数据量是3430173条数据,1000条清洗一个批次,需要清洗3431批次,从0开始计数要清洗到3430批次结束

加入游标后查询的速度加快,日志截图如下(查询的数据最开始是在6秒左右,是因为现在清洗过来的房间数据已经好1000W+的数据,所以大家看到查询的数据是从6秒开始)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
总结:通过主键id值的移动来实现游标的方式控制查询的数据集的大小,将查询耗费时间随着查询分页的后移来而变得越来越短。
3、我们虽然优化了分页查询效率的问题,但是从上图我们不难看出,如果100W的数据量进行分页查询还是会经历1000次的查询,那么我们如何解决多次查询的问题?我们最早的问题告知我们不能一次性查询百万或者千万条数据,因为这样内存吃不消,但是我们换种思路,也不是说一次只能查询最优分页查询的数据量(解决方案第1步中统计出来是500条左右),于是有了下面的演进:
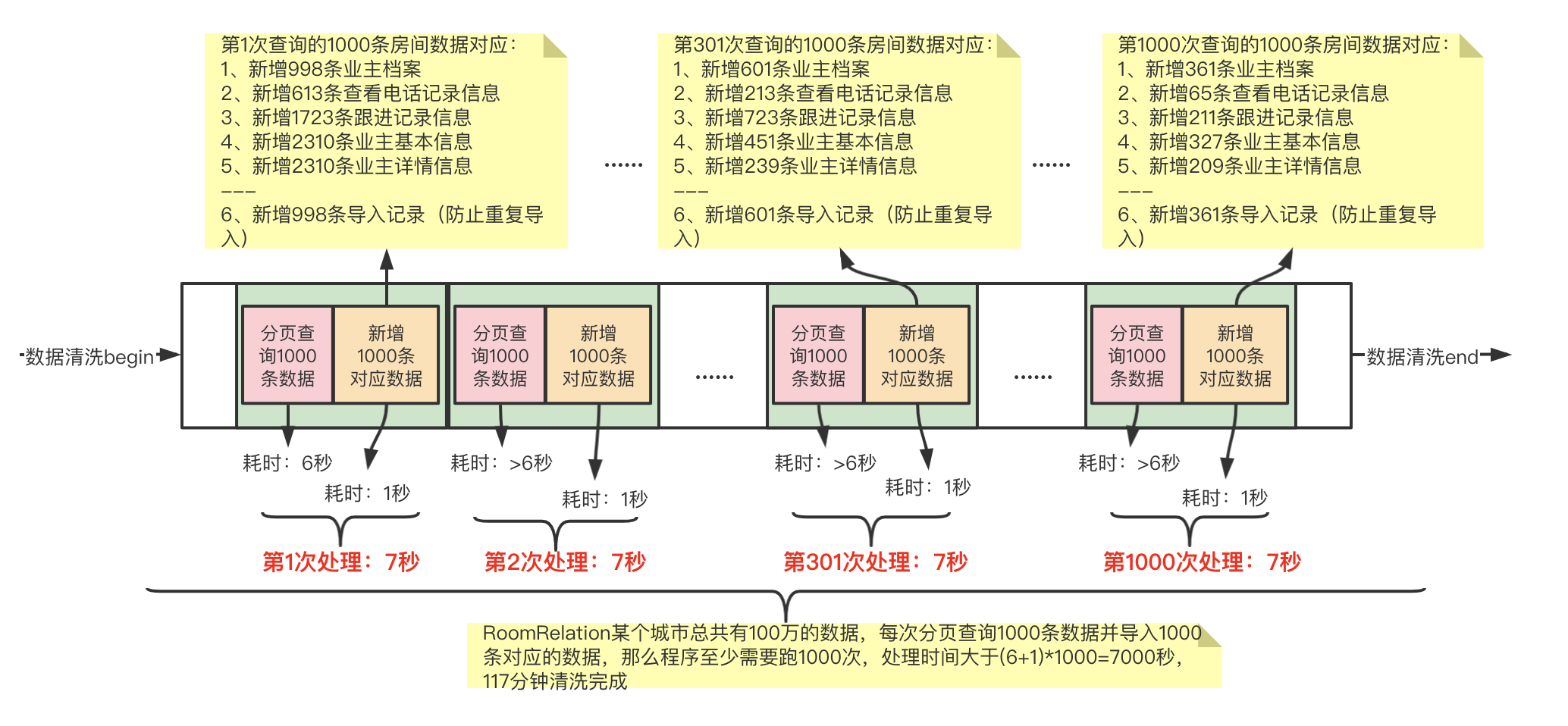
通过内存存储减少查询次数,我们给到外部的貌似是1000条一页一页的查询,实际我们会一次查询大于1000条数据,下面以2W举例,就是分页查询的时候我们是一次性查询2W条数据,然后遍历每1000条处理一次,直到2W条数据处理完成,在分页查询下一个2W条到内初进行处理,依次类推,直到处理完成。

总结:减少查询次数,不能一次性查询出上百万的数据,那我一次性查询出1W或者2W的数据,然后利用内存再将这2W的数据进行1000条按照一批次处理,这样就将20次分页查询变成了1次分页查询+20次内存运算处理。从而大大加快数据清洗的效率。
四、数据清洗说明
在实际数据清洗过程中,还有很多复杂逻辑,不过都是偏业务层面,没有分享出来的必要性;其次上面的数据,如各种性能的值需要根据各自业务数据的复杂性自行测试,找到各自性能的最优处理值。
思考:
下面贴一张截止到2021年8月22日靠前的几个城市的房间数据:
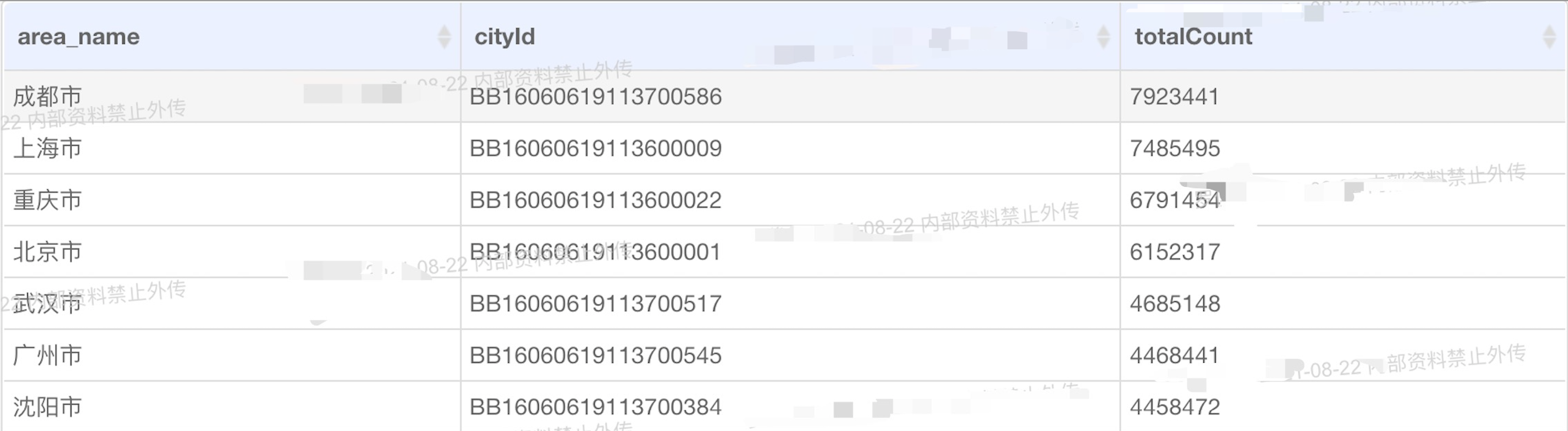
1、由于我们业主档案列表分页查询,查询过程因为是以房间为维度,关联项目表、分期表、楼栋表、单元表、业主档案表(后面还加了7天联系记录)等,从上图大家可以看到成都、上海的房间数据都超过了700W+的数据,那么在关联多个表查询,固然会存在查询效率慢的原因,我们除了在SQL层面本身进行优化,是否可以利用到上面的一些思想?比如用户查询1、2、3、4...等分页(假如每页20展示条)数据,我们是否只需要真实的查询出第一页数据(快速响应),然后利用假分页,如查询出200条数据放入缓存,并设置过期时间,假如用户翻页到9页(一共缓存10页数据)的时候(预估用户行为,提前到第9页就进行下一次查询,防止用户翻到第10页在进行查询花费大量时间),提前把下一个200条数据查询出来。对于客户来说,他的分页是正常分页,而我们在底层代码通过假分页和真分页呈现数据,并且因为我每次只缓存了200条数据,多个用户操作,不会影响我缓存的内存,其次因为我缓存数据较少,且都设置过期时间,数据实时性也能得以保障。另外如果有统计功能,其实第一页也是可以通过分析用户的查询行为进行定期缓存。这样就在满足业务复杂业务需求的同时,保证客户的使用体验。
2、数据清洗的量进行动态配置,下面先来两张图片说明情况:

这个是某次清洗房间关联表(新库房间id和老库房间id的对应关系)84W+的数据,而其中存在业主档案的数据量却只有28974,大概就是每1000个房间有34条对应业主档案可能需要清洗。

而第二张图是另外一个城市,房间关联表只有27171条数据,对应的可能存在业主档案的数据有22635条,就是大约1000条房间数据有833条对应业主档案可能需要清洗。
因为我们默认是每1000条房间清洗一次,那么上面第一种情况每一批次1000条数据只有34条左右的业主档案被清洗到新库中,离性能最优点500差的有点远,故性能有点浪费。第二种情况每一批次1000条数据又有833条左右的业主档案需要被清洗到新库中,离性能最优点500也差的有点远,这时我们这个每批次清洗1000条对应房间的数据就有点设置不太合理,于是我们可以通过这几个值动态生成需要清洗每批次的数据量,来保证每批次清洗数据在500条左右,使得每次清洗都可以在最优的效率下执行。

