
HBase 原理
遗留问题:
数据在更新时首先写入Log(WAL log)和内存(MemStore)中,MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。于此同时,系统会在zookeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了。(minor compact)
当系统出现意外时,可能导致内存(MemStore)中的数据丢失,此时使用Log(WAL log)来恢复checkpoint之后的数据。
这个checkpoint 和 redo point 怎么用?
redo point 记录持久化到那里了
先写Hlog再写内存?
些Hlog不影响速度吗?不是随机读写,是顺序写入,连续写入 ; 异步
Regin 信息放在zookper中,HBAse的元数据信息,表,列族信息也在zookper中
hbase中的数据flush到hfile之后还修改吗?这个时候如果再更新是怎么做的?又是怎么做到更新后依然排序的?
物理存储
split
compact
为什么HBASE快
HBase是无类型的数据库
实际应用中强烈建议使用单列族? 为什么
Zookeeper负责存储Schema信息,包括有哪些表,表有哪些column family,但是HMaster负责处理schema的更新处理请求,他们怎么配合的?
无法进行region的合并,但是split可以进行,因为split只有HRegion server参与,所以合并是由Hmaser做的,但是split由hregion server自己完成?、
1.数据模型
HBase以表的形式存储数据。表有行和列组成,列划分为若干个列族,如图所示:

- 逻辑数据模型

- 物理数据模型

2.物理存储
- HBase所有行按照Rowkey进行字典排序,Table在行的方向分割为多个region

- Region 按照大小进行分割,每个table最初只有一个Region,随着数据的不断插入,Region不短增大,当增加到一定阈值后,从中间分裂成两个Region。 Table中的数据不断增加,就会有越来越的Region

- Region是HBase分布式存储和负载均衡的最小单元,一个region只能在一个RegionServer上。
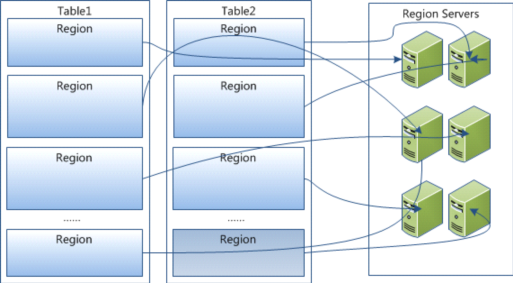
- Region虽然是分布式存储的最小单元,但不是存储的最小单元(内部有更详细的结构)。内部划分为多个Store,一个Store对应一个Column Family。 Store内部又分为一个MemStore和零到多个Storefile。Storefile以Hfile的形式存储在HDFS上

- 每个Region server 管理大约1000个HRegion。(Why:这个1000的数字应该是从BigTable的论文中来的(5 Implementation节):Each tablet server manages a set of tablets(typically we have somewhere between ten to a thousand tablets per tablet server))
3.系统架构

下面的架构图来自于《An In-Depth Look at the HBase Architecture》

这个架构图比较清晰的表达了HMaster和NameNode都支持多个热备份,使用ZooKeeper来做协调;
ZooKeeper并不是云般神秘,它一般由三台机器组成一个集群,内部使用PAXOS算法支持三台Server中的一台宕机,
也有使用五台机器的,此时则可以支持同时两台宕机,既少于半数的宕机,然而随着机器的增加,它的性能也会下降;
RegionServer和DataNode一般会放在相同的Server上实现数据的本地化。
系统架构细化如下:

也可以细化如下:

- Client
Client 包含访问HBase的接口
维护cache加快对HBase的访问
- Zookeeper
保证集群中只有一个HMaser;
监控HRegion Server的状态,及时将上线下线的HRegion Server信息通知HMaster;
记录所有HRegion的寻址入口;
存储Schema信息,包括有哪些表,表有哪些column family
- HMaster
为 HRegion 分配HRegion Server;
负责 HRegion Server的负载均衡;
发现失效的HRegion Serve,并重新分配其上的Region;
GSF上的垃圾文件回收;
处理Schema的更新处理请求
- Region Server
处理region的IO请求
对到达阈值的HRegion进行分裂
所以Client访问HBase的数据不需要HMaster的参与。从Zookeeper中寻址,然后到HRegion Server上进行读写操作。
4 读写过程
- 写入
首先在HLog中记录日志,然后写入到MemStore中,直接返回成功,不需要等待写入HDFS的结果,所以速度很快。
MemStore中的记录达到一定阈值时,会创建一个新的MemStore,并将旧的MemStore添加到Flush队列,有专门的线程负责Flush到StoreFile中去,同时在Zookeeper中记录redo point,表明这之前的记录都已经持久化过
写入到StoreFile中的文件只能写入,不能修改(由HDFS的特性决定的), 因此数据修改的过程是不断创建Storefile的过程,因此对应于同一记录,可能有很多历史版本,很多可能是垃圾数据。当Storefile个数到一定阈值时,系统会进行合并,将同一记录的垃圾数据清理掉。 当合并的文件大小超过一定阈值时,进行分裂,防止文件过大。
系统崩溃时,系统会根据redo point /check point? 和HLog中的记录来恢复MemStore中丢失的数据
- 读出
读出的数据是MemStore和Storefile中的数据的总和。 由于是按照Rowkey排序的,所以合并也很快。而且真正的合并是索引的合并,所以很快
7 分裂
8 压缩
参考文献:
https://mapr.com/blog/in-depth-look-hbase-architecture/
http://www.blogjava.net/DLevin/archive/2015/08/22/426877.html
