python爬虫
1 导入url模块
from urllib.request import urlopen
2 打开url
指定url
url = "http://www.baidu.com"
webpage_request = urlopen(url)
3 解码
print(webpage_request.read().decode("utf-8"))
数据解析
1 re解析(正则表达式)
导入re模块
import re
list = re.findall(r"\d{11}","电话号码: 18963157596;家庭电话: 17530159745")
print(result)
匹配的是字符中所有的内容,返回的是迭代器,从迭代器拿到内容需要用.group()
it = re.finditer(r"\d{11}","电话号码: 18963157596;家庭电话: 17530159745")
for i in it:
print(i.group())
# search,匹配到一个结果直接返回,拿到数据需要用.group()
yz = re.search(r"\d{11}","电话号码: 18963157596;家庭电话: 17530159745")
print(yz.group())
# match 从头开始匹配
rr = re.match(r"\d{11}","电话号码: 18963157596;家庭电话: 17530159745")
print(rr.group())
正则表达式预加载
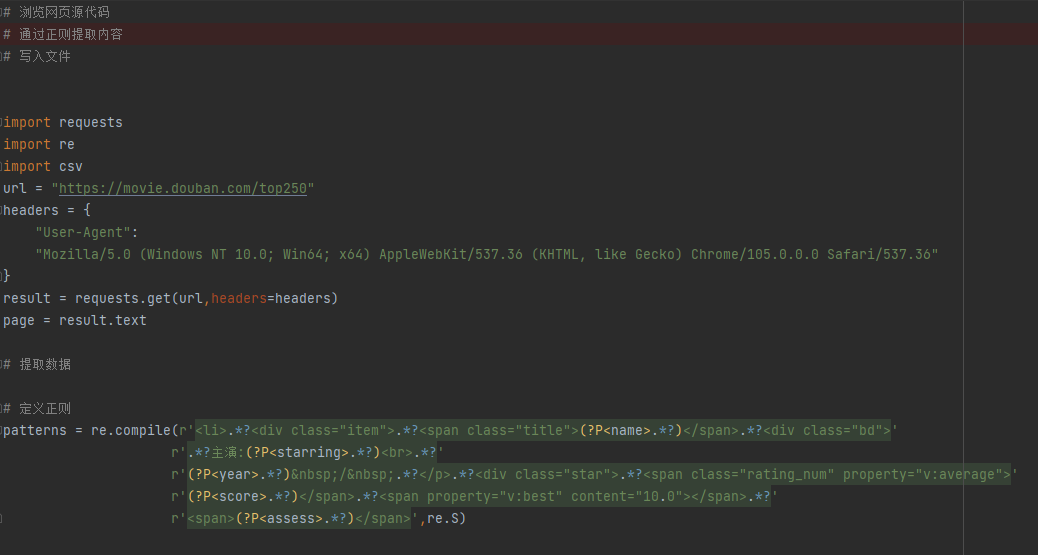
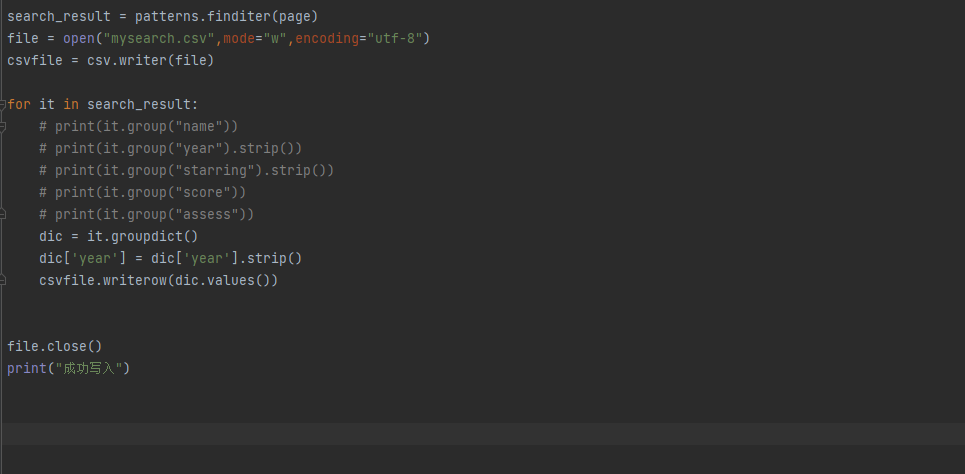
说明:strip的作用去除前面的空格,顶格显示
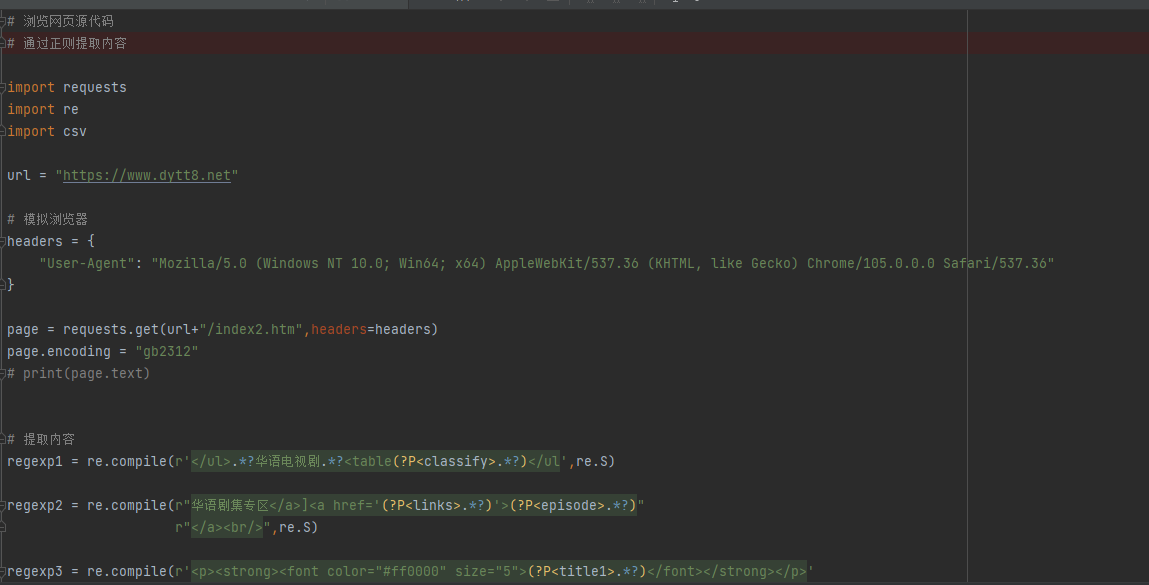
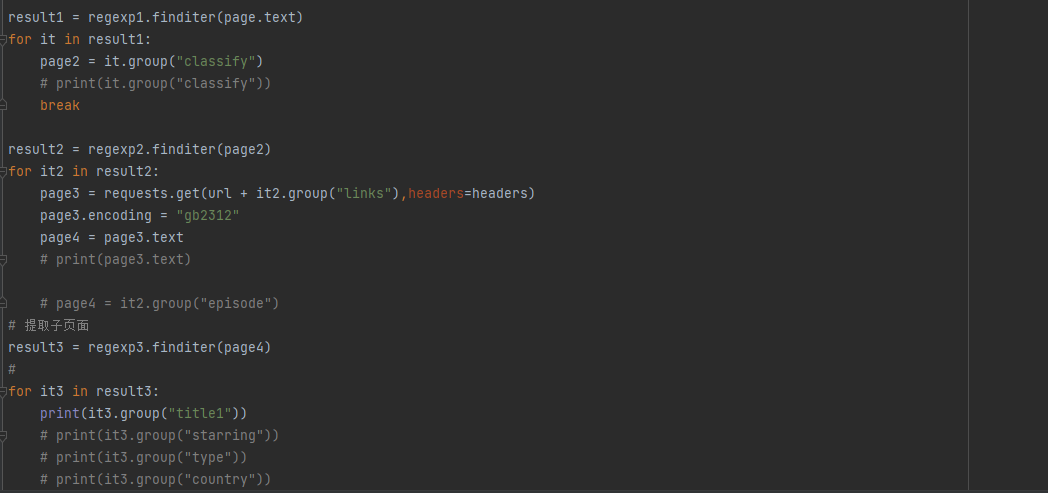
2 bs4解析 (beautifulsoup模块)
这个模块只有两个函数 find findall
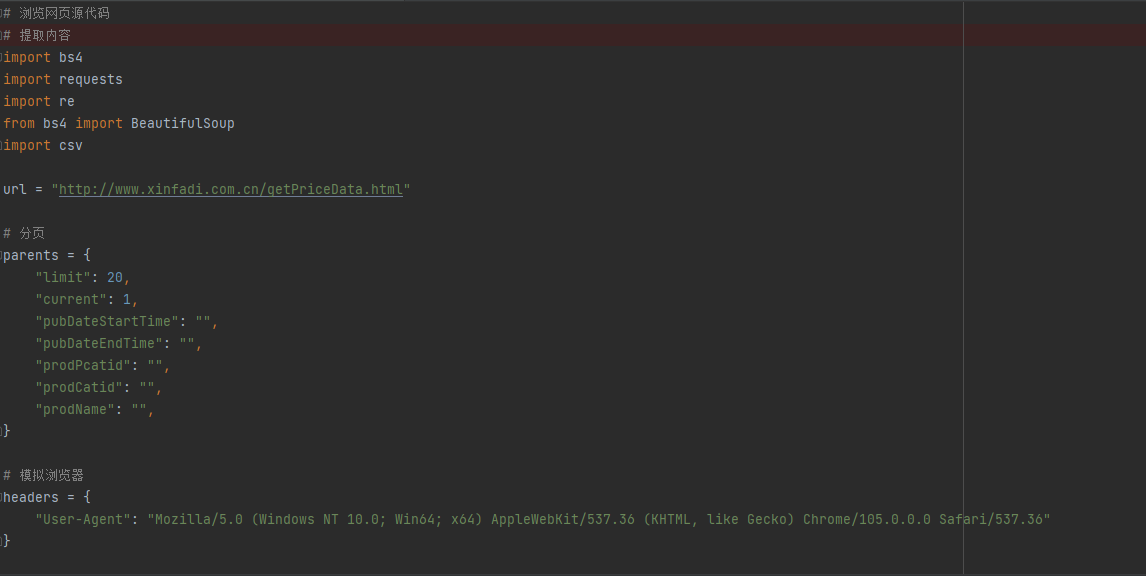
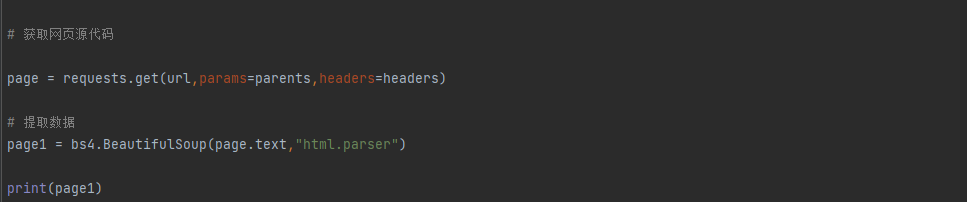
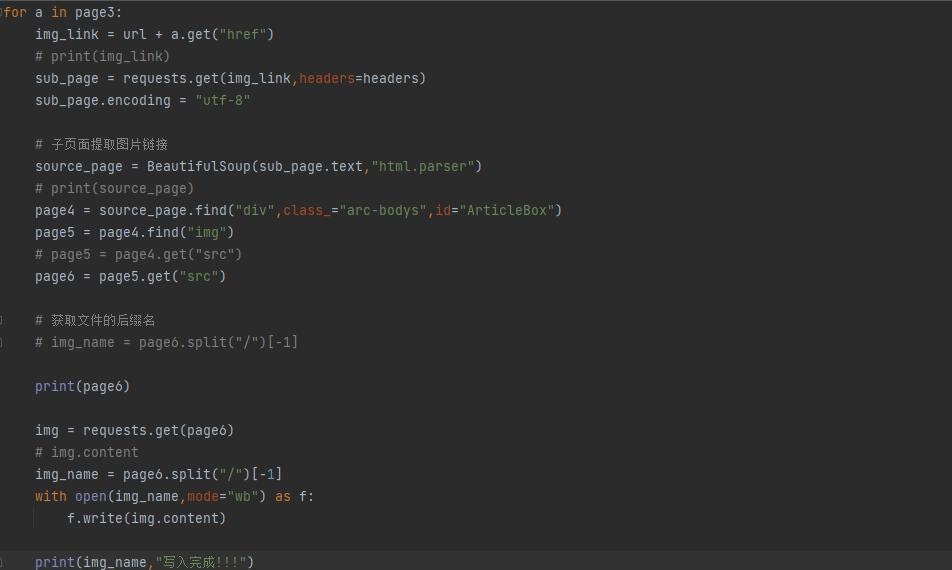
爬取图片
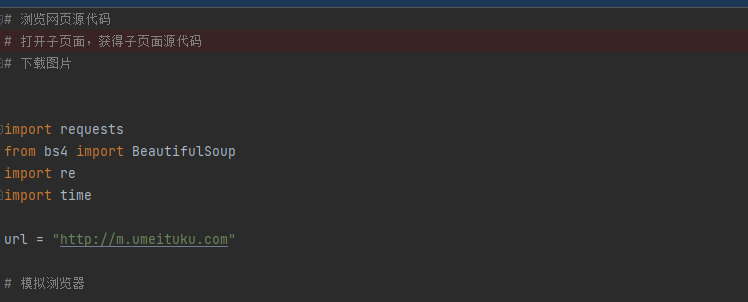
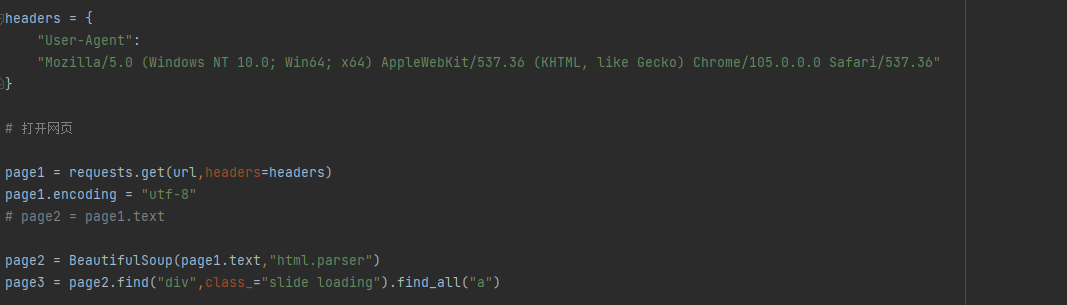
3 xpath解析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号