python开发语言学习过程
python
执行python程序的三种方式
解释器---- python/python3
交互式---- ipython (支持自动补全 自动缩进 支持shell命令 内置功能函数)
集成开发环境---- PyCharm (图形界面 代码编辑器 解释器 调试器)
python源程序的基本概念
1 python源程序就是一个特殊的文本文件
2 python程序的文件扩展名称通常都是 .py 文件命名的
3 每行代码只完成一个动作
python变量的类型
1 数据类型和非数据类型
数据类型
整数型 int
浮点型(小数型)float
bool型 非零即真
非数据类型
字符串型 string
列表 list
元素 element
字典 dictionary
函数 type print input
不同类型的相互转换
weight = "130"
float(weight)
passwd = input("qingshurumima")
格式化输出 % (这里的%是一个占位符)
格式化输出的类型
%s 字符串输出
%f 浮点型输出 %.2f #表示显示2位小数
%d 整数型输出 %06d #表示显示6位整数,不足六位以0补足,超过六位实际显示
%% %输出
查看python内置的函数
import keyword
print(keyword.kwlist)
python标识符(变量 函数)
python的标识符是区分大小写的
标识符的命名规则
1. 使用小写字母
2. 多个单词之间以下划线连接
3.驼峰命名法(每个单词首字母大写)
if判断
python模块使用
import random (导入random模块,查看使用方法 在ipython中 random.)
while 循环使用
定义变量
i=1
条件判断
while (i<=5):
print("nihao")
条件处理
i=i+1
嵌套循环 嵌套判断
break 条件满足,停止执行
continue 条件满足,跳过继续执行后续的条件任务
python转义字符说明
end="" print函数在输出的时候,可以不换行输出
\t 表示在垂直方向上对齐
\n 表示换行输出
\\
\'
\"
函数定义的语法格式:
def 函数名称():
封装的代码
函数的参数的使用
def sum_number(num1, num2):
"""两个数字的求和"""
# num1 = int(input("请输入您的第一个数字: "))
# num2 = int(input("请输入您的第二个数字: "))
sum = num1 + num2
print("%d" % sum)
return sum
f_sum=sum_number(16, 45)
参数与参数之间用逗号隔开
形参 : 定义函数时小括号中使用的参数,num1就是形参
实参 : 调用函数时传递的参数,16就是实参
return 获取函数的返回结果,并且用一个变量获取返回值
注意:::: return 返回之后,return后面的同级后续代码不会被执行!!!!
模块的使用规则
任何一个以.py结尾的文件都是一个模块文件
模块的使用
使用import导入模块
模块名.使用的函数或者变量名
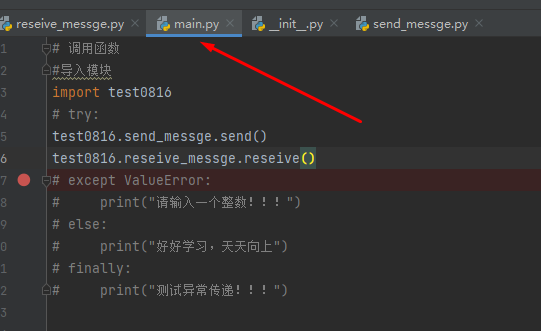
import test
test.print_line("op", 20)
test.print_times("89",3)
print(test.name)
pyc文件的说明
pyc结尾的文件是python编译过的文件,一般位于_pycache_的目录里面,这个文件是由python解释器将模块的源码转换位字节码,是对python程序执行速度的优化
python非数据类型的介绍使用
list(列表)
1 python语言中使用频率非常高的数据类型,在其他语言中叫做数组
2 用来存储一串信息的
3 列表用 []定义,数据之间使用逗号(,)
4 列表的索引是从数字0开始计算的
del 列表名称[] ## 表示把变量从内存中删除,后续的代码就不能在继续使用这个变量
迭代遍历循环
for name in name_list:
print(name) ### 依次从列表中取出数据存放在name这个变量当中
元组 tuple
1 元组跟列表有些类似,但是元组的元素一旦定义是不能修改的
2 多个元素之间用逗号,隔开
3 元组用小括号()表示
4 元组的索引也是从0开始计算的
元组只有一个数据类型的情况下,如果不用逗号,那么系统就会自动判断他的数据类型,在这种情况下,元组只有一个元素的时候,不能省略逗号
在python中,for循环可以遍历所有非数据类型的变量,比如 列表 元组 字典 字符串
在实际开发应用中,元组可以用在函数的参数和返回值中,同时元组的不可修改的性质,也能很好的保护数据的安全
元组和列表的转换
list(元组)
tuple(列表)
字典(dictionary)
字典与列表的区别
列表是有序的集合
字典是无序的集合
字典是用{}表示的,同样可以赋予多个数据,数据与数据之间用逗号,隔开
key 是索引
value 是数据
键与值之间用冒号:分隔
键必须是唯一的
值可以取各种数据类型 但键只能使用字符串 数字 或者元组
比如
test_dictionary = {"name": "xiaoming","nianling": 18,"shengao": 1.68} #### 特别提醒 一个键值对单独占用一行代码
字典的增删查改
取值
print(test_dictionary["name"])
增加
test_dictionary["jiguan"] = "jilin"
修改
test_dictionary["name"] = "xiaoxiaoming"
删除
test_dictionary.pop("shenggao")
在实际应用中,一个字典可以存储一个物体或者对象的相关信息,将多个字典存储在一个列表中,再进行循环遍历,得到相同的处理
card_list = [{"name": "zhangsan", "age": 15, "gender": True}, {"name": "lisi", "age": 23, "gender": False}]
for j in card_list:
print(j)
字符串
字符串的定义可以使用双引号"",也可以使用单引号'',但是在大多数的编程语言中都是使用双引号表示字符串的
字符串的操作类型
1 判断类型
2 查找和替换
3 大小写转换
4 文本对齐
5 去除空白字符
6 拆分和连接
python常见函数
print type input del len max min
完整的for循环
poetry = ["回乡",
"杜牧",
"少小离家老大回",
"乡音无改鬓毛催",
"借问酒家何处有",
"牧童遥指杏花村"]
for str in poetry:
print(str.center(3," "))
continue
else:
print("dajiahao")
## 只有for遍历循环完成,才会执行else下面的语句
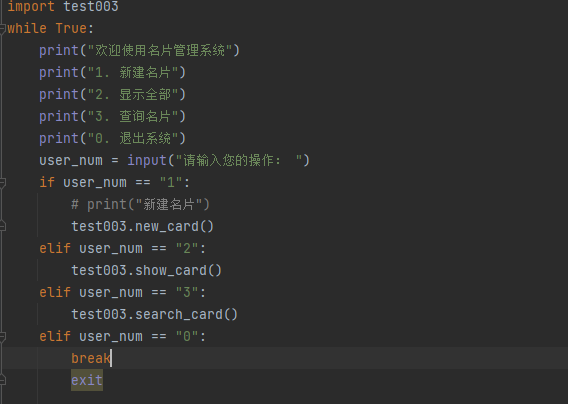
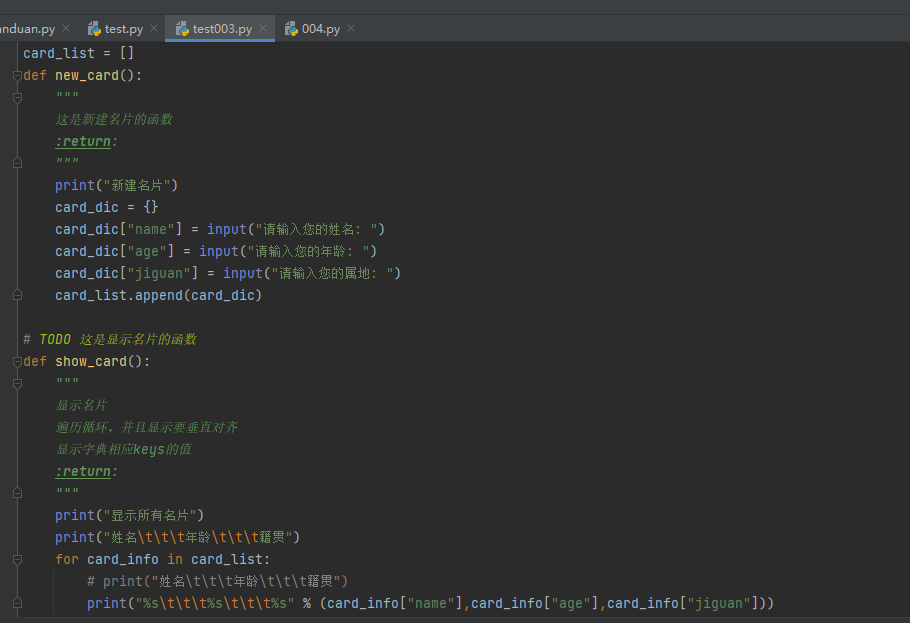
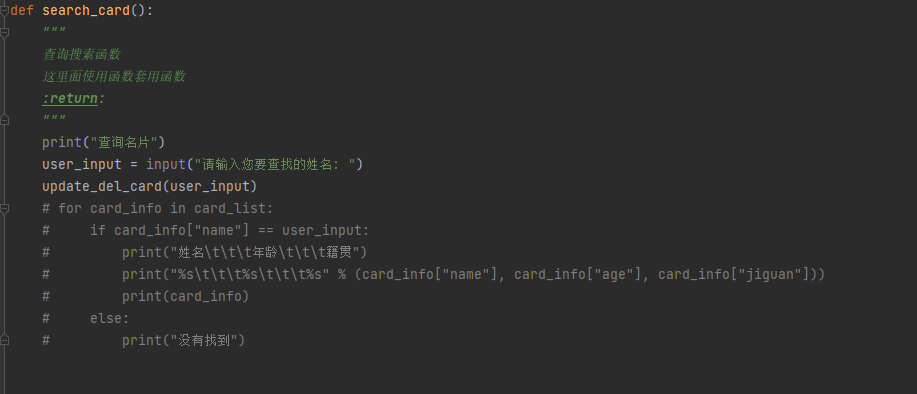
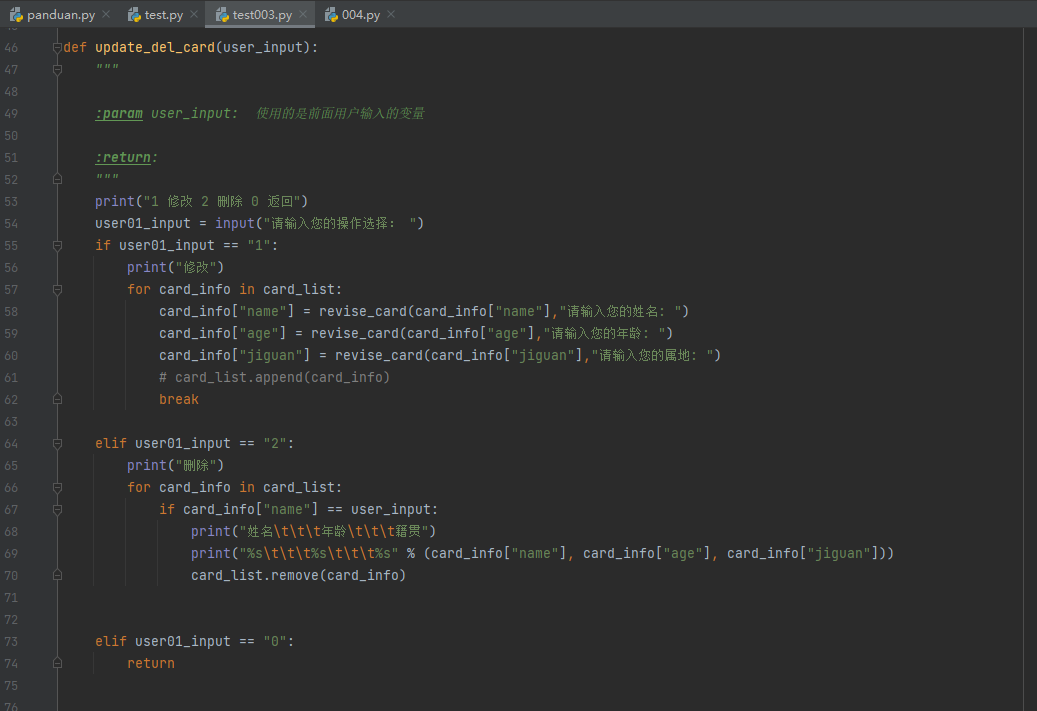
第一个实战小程序------名片编写
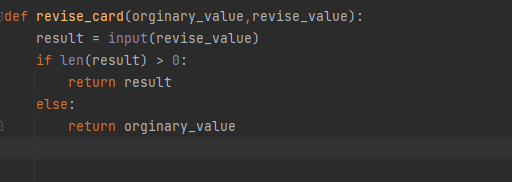
不可变类型
数据类型 元素 字符串
可变类型
列表 字典
局部变量
定义在函数内部的,只能在函数内部使用的变量
全局变量
定义在函数外部的变量
全局变量的修改
1.在一个函数内部重新给变量赋值的形式修改全局变量的值,只在函数内部有效。
2.在函数中声明全局变量(global)
global 全局变量名称
函数的返回结果是一个元组,可以使用多个变量接受函数的返回结果,定义的变量个数必须要与元组的元素的数量保持一致
g_tem,g_hum = temp()
函数的缺省参数
1.缺省参数需要使用最常见的值作为默认值
2.如果一个参数的值不能确定,就不能使用缺省参数
3.缺省参数必须放在参数列表的末尾
多值参数
python有两种多值参数
参数名前增加一个* 可以接受元组
参数名前增加两个** 存放字典参数,前面有两个 **
一般在给多值参数命名时的习惯使用惯例
*args --- 存放元组参数
**kwargs ---存放字典参数,前面有两个
拆包语法
在函数传递参数时,在参数前面加* 表示传递的是元组,在参数前面加两个** 表示传递的是列表
使用拆包语法能够简化元组变量或者列表变量的传递
函数的递归(函数调用自身的函数)
1 必须传递参数
2 达到条件停止执行,否则出现死循环
面向对象 vs 面向过程
面向过程
在开发复杂项目时,没有固定套路,开发难度大
面向对象
相比较函数而言,是更大的封装,根据功能在一个对象中封装多种方法
更加注重对象和职责 ,不同的职责不同的对象承担,是专门针对复杂项目开发的方法,在面向过程的基础上学习新的语法
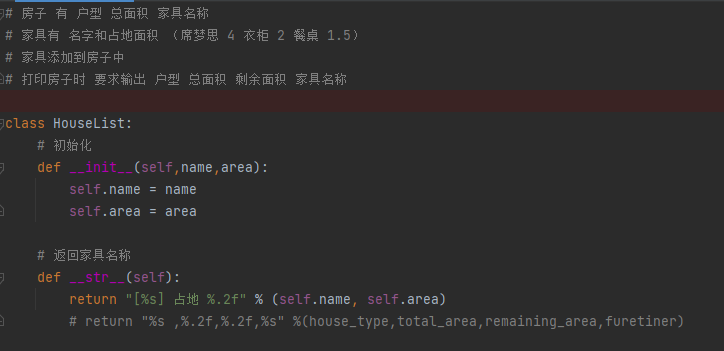
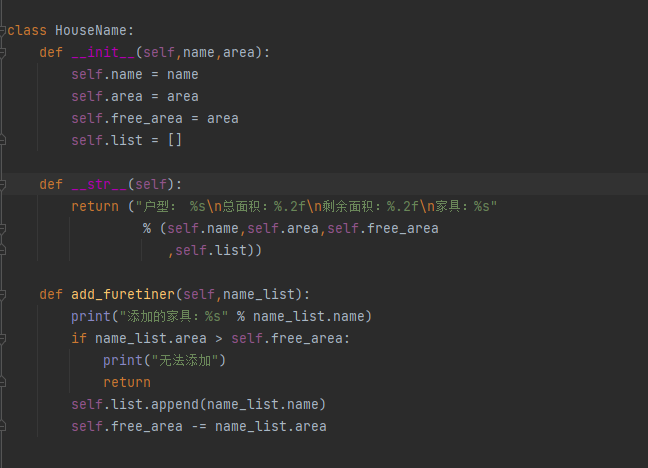
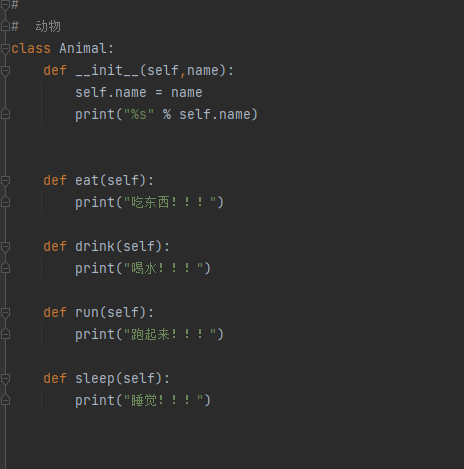
类和对象
类和对象是面向对象编程的两个核心概念
类是对一群具有相同特征或者行为的事物的一个统称,特征即属性 行为即方法
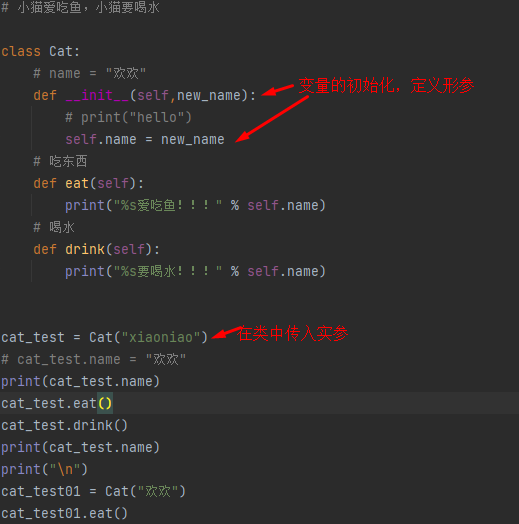
类的定义和通过类创建对象的基本格式
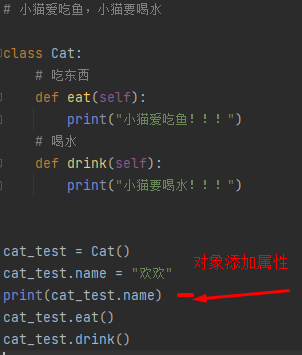
self 参数的说明
哪一个对象调用的方法,self哪一个对象的引用
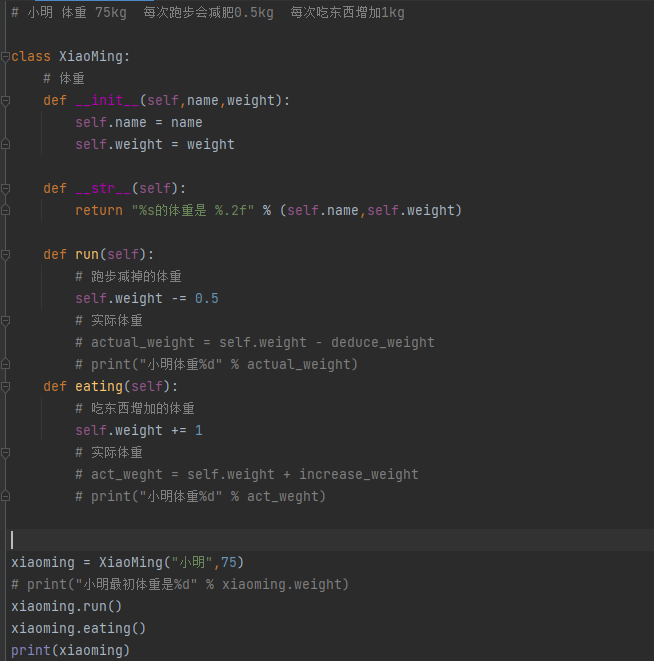
对象的初始化
__init__自动调用这个方法,指定对象有哪些属性
self.属性名称 = 初始化值
__str__ 字符串的方法的调用,返回值必须是一个字符串
遇到一段代码很长的时候,不方便阅读和审查,把代码用一个括号收入其中,python能够自动将其中的代码视为一个整体的代码

身份运算符
is 判断两个标识符是否引用同一个对象
is not
== 表示判断引用的变量的值是否相等
一个类的属性是另一个类创建的对象
当一个属性的初始值不好定义时使用None
对于用None定义的值作比较时用is表示更为合适
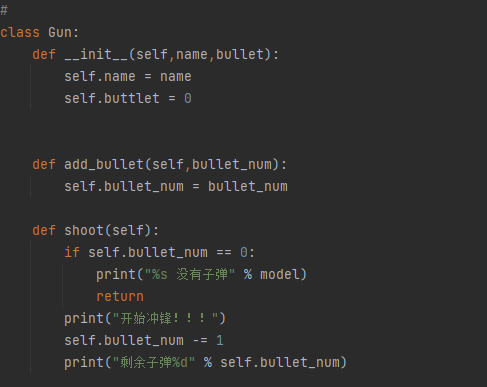
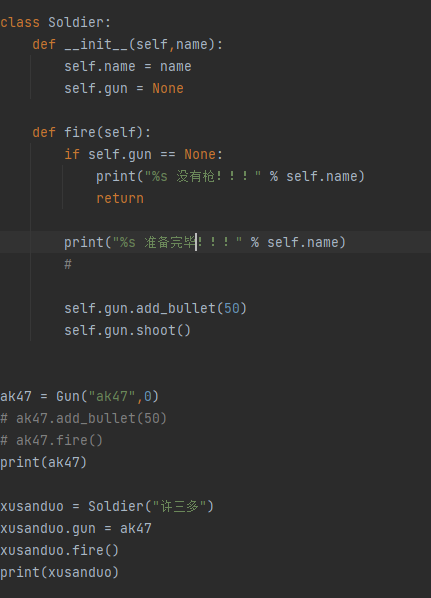
私有属性:对象不希望公开的属性
私有方法:对象不希望公开的方法
定义方式
在属性或者方法前面使用两个下划线__ 就表示私有属性或者私有方法
在python中没有绝对的私有属性和私有方法(伪私有)
在调用方法或者属性的前面加上下划线_类名然后在跟属性或者方法即可
面向对象的三大特性
封装 (根据特征和行为也就是属性和方法封装到一个类中)
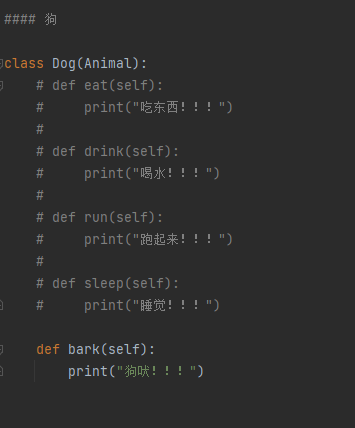
继承 简单地说,就是实现代码的重复使用,相同的功能代码不需要重复编写(单继承 多继承)
多态 不同的对象调用相同的方法产生不同的结果,增加代码的灵活度,多变性
继承的语法格式
class 子类名(父类名):
pass
继承的传递性
方法的重写
1 覆盖父类的方法(在子类中定义一个跟父类同名的方法)
2 在父类中利用super().父类方法 进行扩展,编写子类特有的功能或者方法
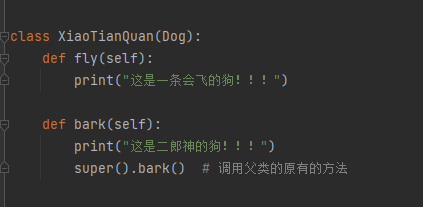
在python2.0的早期版本中,是没有super(),如果想调用父类的方法 父类名.方法(self),一般不推荐使用这种方式
子类不能直接访问父类的私有属性和私有方法,但是可以通过父类的公有属性和公有方法访问到父类的私有属性和私有方法
多继承
子类可以拥有多个父类的方法和属性。
class 子类名(父类名1,父类名2,父类名3)
多继承的注意事项
在不同的父类中存在同名的方法或者属性,不要使用多继承,这样会发生混淆!!!
print(C.__mro__) mro主要是查看多继承调用方法的顺序
新式类和旧式(经典)类
object 是python所有对象的基类,提供有一些内置的属性和方法,可以使用dir函数查看
新式类 以object为基类的类,推荐使用
经典类 不以object为基类的类,不推荐使用
class 类名(object):
pass
多态
不同的子类对象调用相同的父类方法产生不同的结果
优点
以继承和重写父类方法为前提的
增加代码的灵活度,可用性
创建出来的对象叫做类的实例
创建对象的动作叫做实例
对象的属性叫做实例属性
每一个对象都有自己独立的内存空间,保存各自不同的属性
多个对象的方法,在内存中只有一份,在调用方法时,需要把对象的引用传递方法的内部
python中一切皆对象
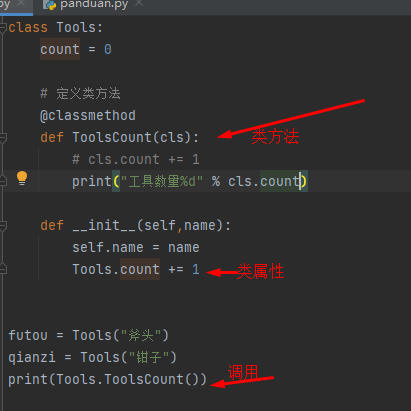
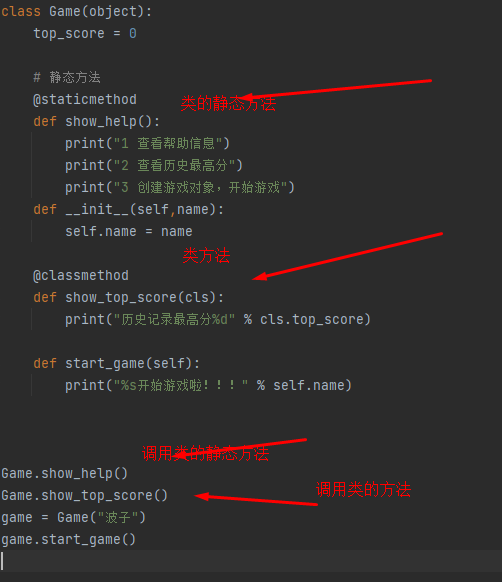
类属性 类方法
类名.属性 》》》 类属性
类名.方法名() >>> 类方法
类名() >>> __init__ 定义 实例属性
对象名.方法名() >>>> 实例方法
类属性就是针对类对象定义的属性
类方法就是针对类对象定义的方法
语法格式
@classmethod
def 类方法名.(cls):
pass
@classmethod 标识符,告诉解释器这是一个类方法
类方法的第一个参数时cls
cls 类似self
可以通过cls.属性名 访问类的属性
可以通过cls.方法名 访问类的方法
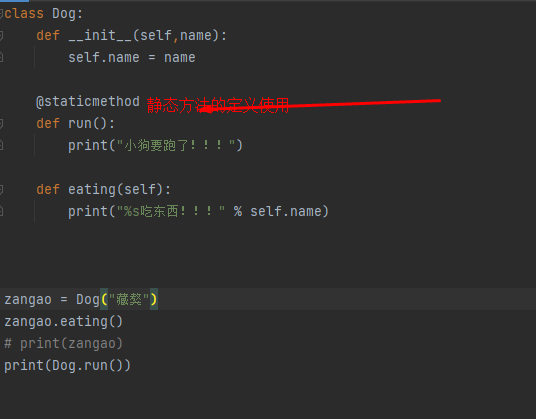
静态方法
在类中封装一个方法,既不需要访问类的属性或者实例属性,也不需要访问类的方法或者实例方法
语法格式
@staticmethod
def 静态方法名():
pass
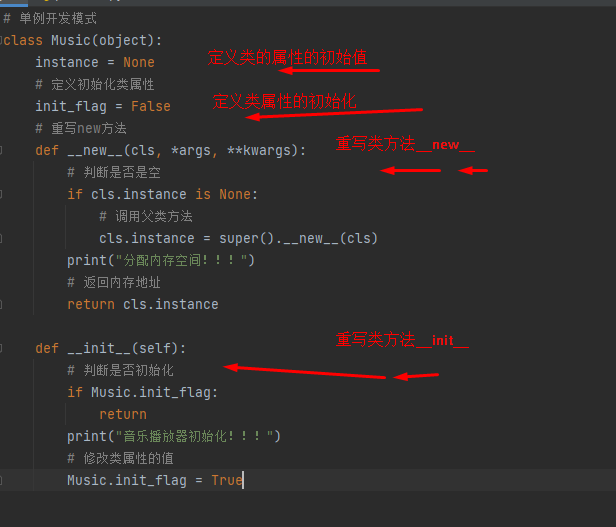
单例设计模式 (针对某一特定问题总结归纳的成熟的解决方案)
让类创建的对象,在系统中只有唯一的一个实例
每一次执行 类名() 返回的对象,内存地址是相同的
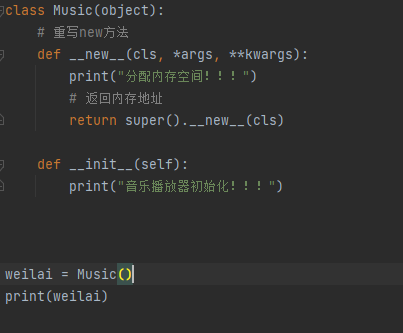
__new__方法
是一个有object基类提供的内置的静态方法 主要功能有两个:
1 在内存中为对象分配空间
2 返回对象的引用
重写__new__方法的代码非常固定
重写__new__方法一定要 return super().__new__(cls)
否则python的解释器得不到分配了空间的对象引用,就不会调用对象的初始化方法
注意: __new__是一个静态方法,在调用时需要主动传递 cls 参数名前增加一个*
单例 让类创建的对象在系统中只有唯一的一个实例
定义一个类属性,初始值设为None 用于记录单例对象的引用
重写__new__方法
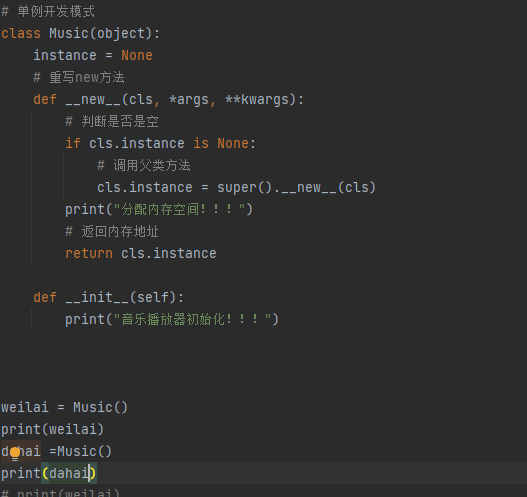
只执行一次初始化
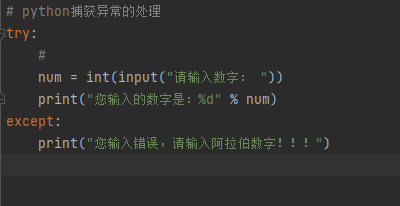
异常
我们通常要对程序异常进行捕获作特殊处理,以保证程序运行的稳定性和健壮性
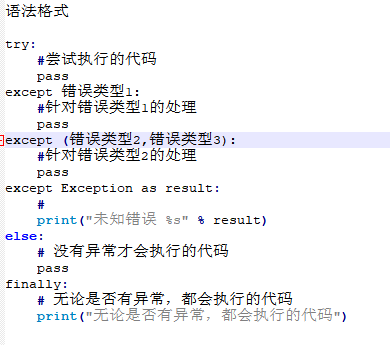
捕获异常的语法
try:
尝试执行的代码
except:
出现错误的处理
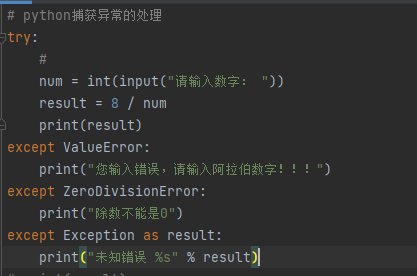
在程序的开发中,会遇到不同类型的异常错误,也就需要设置不同类型异常的捕获
错误类型就是最后一行报错的第一个单词
语法格式
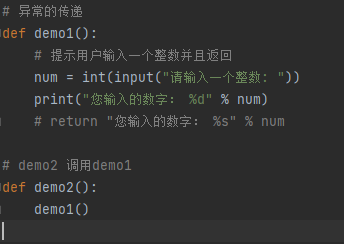
异常的传递
当函数或者方法执行出现异常,会将异常传递给方法或者函数,如果传递到主程序,仍然没有处理,程序才会停止运行。
在开发中,可以在主函数中增加异常捕获,只要主函数调用其他函数,出现异常,都会传递到主函数的
异常捕获中,由此就不必要增加大量的异常捕获,从而保证代码的整洁性

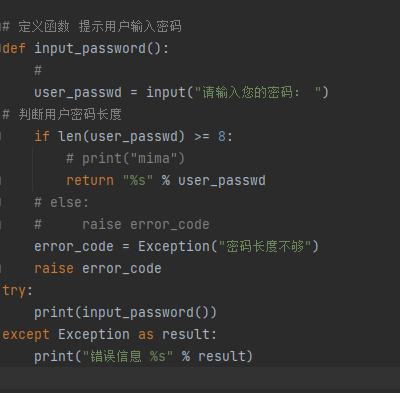
抛出raise异常
在开发中,除了代码执行出错抛出异常,还可以根据业务需要主动的抛出异常
python中提供了一个Exception 异常类
1 创建一个Exception对象
2 使用raise 关键子抛出异常
模块
模块是python程序语言的一个核心概念
1.每一个以.py结尾的python源文件都是一个模块
2.模块名同样也是一个标识符,需要符合标识符的命名规则
3.模块中定义的全局变量 函数 类 都是提供外界直接使用的工具
4.模块就是一个工具包,若想使用工具包中的工具,就要先导入这个工具包
模块的导入方式
1. 一次导入多个模块,模块名之间以逗号相隔
import 模块名1,模块名2
2 每次导入一个模块(推荐使用)
import 模块名1
import 模块名2
使用as给模块定义别名(针对模块名称太长)
import 模块1 as 模块别名
模块别名需要符合大驼峰命名法
3. from .. import 导入
这种导入模块是只导入模块中的一部分,适用于我们只需要使用模块中的部分工具
语法格式
from 模块名 import 工具名
导入之后不需要通过模块名.的方式
如果两个模块存在相同的函数名称,可以通过别名的方式处理
from 模块名 import 函数名 as 别名
python文件的取名不要跟系统的模块名相同,否则使用不了系统的模块
注意:导入的模块文件,该文件所有没有缩进的代码都会被执行一遍
__name__ 属性
作用: 测试模块的代码只在测试情况下执行,而在被导入之后不会被执行
__name__ 属性是python的一个内置属性,记录这一个字符串
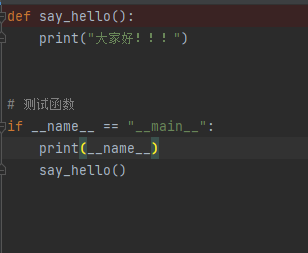
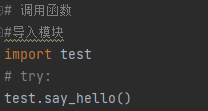
在今后的开发中,可以看到很多的python文件看到下面的格式代码

包
1包是一个包含多个模块的特殊目录
2目录下有一个特殊的文件 __init__.py
3包名的命名方式和变量名一致 小写字母*
优点
使用import包名 可以一次性导入包中所有的模块
__init__.py
注意: 要在外界使用包中的模块,需要在__init__.py 中指定对外界提供的模块列表
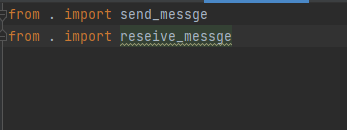
# 从当前目录导入模块列表
from . import send_message
from . import recevie_meesage
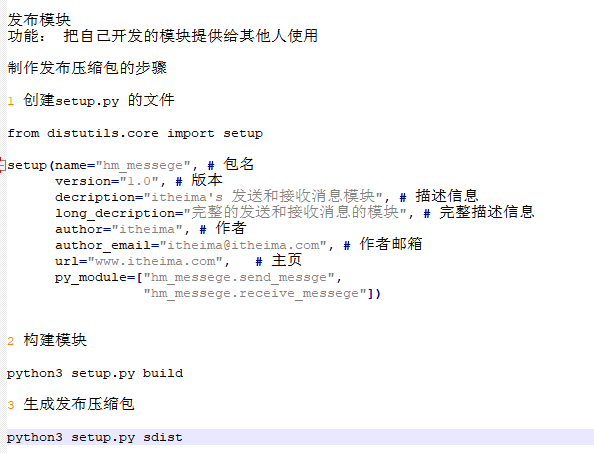

pip 安装三方模块
pygame是一套非常成熟的游戏开发模块
pip是一个现代的 通用的python包管理工具,提供了python包的查找 下载 安装 卸载等功能
文件的操作三步骤
打开文件 读写文件 关闭文件
操作文件的函数或者方法
1 open 打开文件
2 read 读文件
3 write 写
4 close 关闭文件
read方法
open函数的第一个参数是要打开的文件名(文件名区分大小写)
如果文件存在,返回文件操作对象
如果文件不存在,就会抛出异常
read方法可以一次性的读取并返回文件的内容
close 方法负责关闭文件
如果忘记关闭文件,会造成系统资源的浪费,同时也会影响后续的访问
语法格式
打开文件
file = open("README")
读取
text = file.read()
print(text)
关闭
file.close()
文件指针
标记从哪个位置开始读取数据,第一次打开文件,通常文件指针都会指向文件的开始位置,
当使用了read的方法后,文件指针会移动到文件的末尾位置
打开文件的方式
open函数默认是以只读方式打开文件的,并且返回文件对象
语法格式
f = open("文件名","访问方式")
r 只读,如果文件不存在,抛出异常
w 只写,如果文件存在会被覆盖,如果文件不存在会被创建
a 以追加的方式打开文件,如果文件存在,文件指针将会放在文件的末尾,如果不存在,创建新文件写入
r+ 以读写的方式打开文件,文件的指针将会放在文件的开头,如果文件不存在,抛出异常
w+ 以读写的方式打开文件,如果文件存在会被覆盖,如果不存在,创建新文件
a+ 以读写的方式打开文件,如果文件存在,文件指针将会放在文件的结尾,如果文件不存在,创建新文件写入
按行读取文件内容
readline方法默认会把文件的内容一次性读取到内存
方法执行后,文件指针移动到下一行,准备再次读取
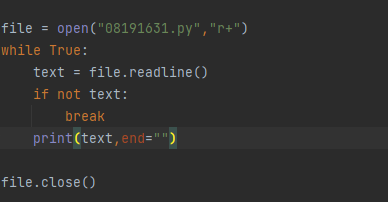
读取大文件的正确格式:
# 打开文件
file = open("1.txt")
while True:
# 读取一行内容
text = file.readline()
# 判断是否读取到内容
if not text:
break
# 每读取一行的末尾已经有了一个"\n"
print(text,end="")
# 关闭文件
file.close()
文件读写案例---文件复制
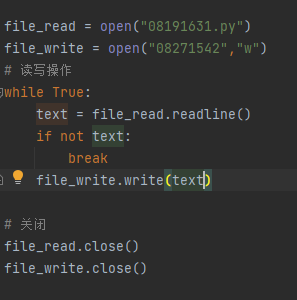
文件目录的常用管理操作
创建 重命名 删除 改变路径 查看目录内容
文件操作
1 rename 重命名文件方法 范例: os.rename(源文件名,目标文件名)
2 remove 删除文件 范例: os.remove(文件名)
目录操作
1 listdir 目录列表 范例: os.listdir(目录名)
1 mkdir 创建目录 范例: os.mkdir(目录名)
1 rmdir 删除目录 范例: os.rmdir(目录名)
1 getcwd 获取当前目录 范例: os.getcwd()
1 chdir 修改工作目录 范例: os.chdir(目标目录)
1 path.isdir 目录列表 范例: os.path.isdir(文件路径)
备注: 文件或者目录操作都支持相对路径和绝对路径
文本文件的编码格式
字符编码 ASCII UNICODE
python2 默认使用ASCII编码
python3 默认使用UTF-8编码
计算机只有256个ASCII字符
ASCII编码在内存中占用一个字节
UTF-8编码格式
计算机使用1到6个字节来表示UTF-8字符,涵盖了地球上几乎所有的文字
大多数汉字使用3个字节表示
eval函数
eval函数十分强大 ---- 将字符串当成有效的表达式来求值并返回计算结果
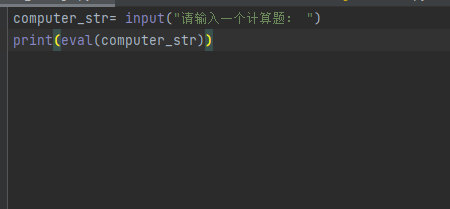
注意:不要滥用eval
在开发时千万不能使用eval直接转换input的结果
eval函数能够暴露我们的内部文件,能让用户创建或者删除我们系统的文件,这样的话,非常危险!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号