
UniProt数据库怎么看
由于蛋白质组学的发展,使得蛋白质数据库也日益丰富,数据库的专一性及综合性均增强,而且,通过超文本的链接,可以使多个数据库进行相互的衔接。目前,关于蛋白质的结构,蛋白质质谱等数据库均较多,今天就来讲讲使用频率最高且冗余度最低的uniprot数据库。
拿到蛋白质组学鉴定结果后,看懂数据库当然是第一步的。
以常见的牛血清白蛋白(BSA)为例,首先下载BSA的数据库信息

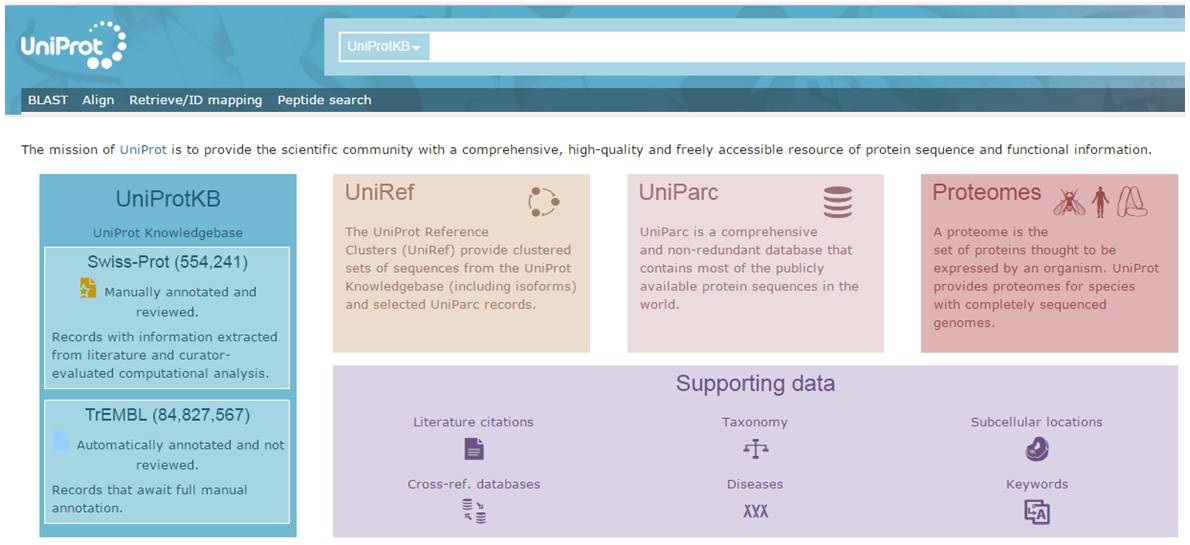
首先sp表示,Swiss-Prot数据库是注释精炼的蛋白序列库,它的所有序列都经过了科学家的查阅文献核实(reviewed, manually annotated) 。
P02769是蛋白在uniprot上的ID号,即蛋白的身份证号。
ALBU_BOVIN是蛋白在uniprot上的登录名,跟P02769是一个作用。
Serum albumin是蛋白名称,即蛋白的姓名啦。
OS表示Organism,也就是物种名称,数据库中的物种名称一般为拉丁名称,牛血清白蛋白Bostaurus当然是牛的拉丁。
GN表示gene name,即基因名称。
PE表示ProteinExistence,即蛋白的可靠性,PE=1、2、3、4、5分别对应如下,可以看出数字越小可靠性越高:
1. Experimental evidence at protein level
2. Experimental evidence at tranlevel
3. Protein inferred from homology
4. Protein predicted
5. Protein uncertain
SV表示SequenceVersion,即序列版本,即蛋白的身份证第二代,第三代……
这里需要指出的是,除了sp,有时还会出现下图的情况。

唯一不同的只有Tr,这里Tr,TrEMBL数据库全称“Translation of EMBL”,是从EMBL中的cDNA序列翻译得到的,其中TrEMBL收录的是未经人工注释的编码DNA序列翻译数据。(unreviewed, automatically annotated),不难看出,相比之下,sp数据库更可靠。
登陆uniprot官方网站(http://www.uniprot.org/,见截图)即可看到,目前uniprot网站收录的sp数据库有554241条蛋白条目,tr数据库有84827567条。当然这一数据每天都有更新。更多数据库参考信息相关链接:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号