
并发编程------进程
进程理论知识
一、什么是进程
程序:静态的,不运行的就是程序
进程:运行起来的程序就是进程
进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一。操作系统的其他所有内容都是围绕进程的概念展开的。
没有进程的抽象,现代计算机将不复存在。
二、进程调度
要想多个进程交替运行,操作系统必须对这些进程进行调度,这个调度也不是随即进行的,而是需要遵循一定的法则,由此就有了进程的调度算法。
先来先服务调度算法
短作业优先调度算法
时间片轮转法
多级反馈队列
三、进程的并行与并发
并行 : 并行是指两者同时执行,比如赛跑,两个人都在不停的往前跑;(资源够用,比如三个线程,四核的CPU )
并发 : 并发是指资源有限的情况下,两者交替轮流使用资源,比如一段路(单核CPU资源)同时只能过一个人,A走一段后,让给B,B用完继续给A ,交替使用,目的是提高效率。
区别:
并行:是从微观上,也就是在一个精确的时间片刻,有不同的程序在执行,这就要求必须有多个处理器。 有多个CPU在同时执行任务
并发:是从宏观上,在一个时间段上可以看出是同时执行的,比如一个处理器同时处理多个session。 只有一个CPU,交替执行多个任务
四、同步异步阻塞非阻塞
1.进程三态


2.同步和异步
同步:先洗衣服再做饭 串行 顺序执行
3.同步阻塞和异步阻塞
4.同步非阻塞和异步非阻塞
五、进程的创建与结束
1.创建新进程
所有的进程都是通过它的父进程来创建的。

2.进程的结束

进程操作(代码)
为了方便大家归类记忆,我将这部分大致分为四个部分:创建进程部分,进程同步部分,进程间通信、进程之间数据共享,进程池部分
一、创建进程-----Process模块
注意:
if __name__ == '__main__' :
# 使用python都是调用操作系统的命令来启动进程
# 同样使用python 不同的操作系统的操作时不同的
# 对于Windows来说,必须加if __name__ == '__main__' :
# 对于linux,ios来说,不必须加if __name__ == '__main__' :
1.如何开启一个子进程
multiprocessing.Process
# 第一种创建方式
实例化创建一个进程
start开启一个进程
# 第二种方式(在下面的 7 里)
采用面向对象的形式来创建进程
继承Process
重写run方法
如果要传递参数:自定义__init__,需要执行父类的__init__方法
import os from multiprocessing import Process def func(): print('我的pid:%s,父进程的pid:%s' % (os.getpid(),os.getppid())) # 3. 我的pid:10552,父进程的pid:12652 if __name__ == '__main__': print(os.getpid(),os.getppid()) # 1. 12652(父进程,即当前python运行程序) 11400(爷爷进程,即pycharm) p = Process(target=func) # 创建了一个进程对象 p.start() # 开启了一个子进程 向操作系统提交了一个开启一个子进程的申请 # 2. 启动子进程之后,运行func下面的代码,即子进程
2.进程与进程之间有什么关系?
父进程必须要等待子进程结束之后回收子进程的资源
异步:父子进程之间的工作是互不干扰的
import os import time from multiprocessing import Process def func(): time.sleep(1) print('我的pid:%s,父进程的pid:%s' % (os.getpid(),os.getppid())) # 3. 我的pid:6512,父进程的pid:5588 if __name__ == '__main__': print(os.getpid(),os.getppid()) # 1. 5588 1440 p = Process(target=func) # 创建了一个进程对象 p.start() # 开启了一个自己进程 print('主进程代码结束') # 2. 主进程代码结束
注意:p.start() 只是向操作系统提交了一个开启一个子进程的申请,所以开启子进程需要一定的时间开销;而从上往下按顺序执行是很快的,所以 print('主进程代码结束')要先打印
3.进程有什么特点?
①父进程必须要等待子进程结束之后回收子进程的资源
②进程与进程之间数据隔离
③进程与进程之间是异步的,有异步的特点-----并发
import os import time from multiprocessing import Process n = 0 def func(): global n n = 100 time.sleep(1) print('我的pid:%s,父进程的pid:%s' % (os.getpid(),os.getppid())) # 3. if __name__ == '__main__': print(os.getpid(),os.getppid()) # 1. p = Process(target=func) # 创建了一个进程对象 p.start() # 开启了一个自己进程 time.sleep(1) print('主进程代码结束') # 2. 因为开启进程是非常慢的,而按顺序往下执行时非常快的(要是睡时间较长的话就是开启进程比较快了) time.sleep(4) print('n:',n)
4.子进程传参数
import os import time from multiprocessing import Process n = 0 def func(num): global n n = 100 print(num) # 3. time.sleep(1) print('我的pid:%s,父进程的pid:%s' % (os.getpid(),os.getppid())) # 4. if __name__ == '__main__': print(os.getpid(),os.getppid()) # 1. p = Process(target=func,args=(666,)) # 创建了一个进程对象 参数必须传一个可迭代的,一般情况下传元组 p.start() # 开启了一个自己进程 print('主进程代码结束') # 2 time.sleep(5) print('n:',n) # 5.
5.子进程有返回值?
进程与进程之间数据隔离,不能直接获取到子进程执行的函数的返回值。
# 子进程的执行结果父进程获取不到
# 那要是父进程依赖子进程的执行结果呢?父进程如何获取到子进程的执行结果?
# 父子进程之间通过socket通信
6. join()方法---- 使进程由异步变为同步 -------- 一批任务使用join,一个子进程没必要用join
主进程需要在子进程都运行结束之后再做某件事情,用join对子进程进行控制
import time import random from multiprocessing import Process def wahaha(num): print(num) time.sleep(random.random()) print(num * '-') if __name__ == '__main__': p = Process(target=wahaha,args=(1,)) p.start() p.join() # 一直阻塞直到这个子进程执行完毕 print('结束')
开启多个子进程,将全部p放入列表后,遍历列表,对每个p进行join阻塞
import time import random from multiprocessing import Process def wahaha(num): print(num) time.sleep(random.random()) print(num * '-') if __name__ == '__main__': p_lst = [] for i in range(10): p = Process(target=wahaha,args=(i,)) p.start() # 启动进程是操作系统来调度的,至于他先调度谁后调度谁,不是人可以控制的 p_lst.append(p) for p in p_lst: p.join() print('结束')
7.面向对象开启子进程
不传参数
import time from multiprocessing import Process class MyProcess(Process): def run(self): time.sleep(1) print('wahaha') if __name__ == '__main__': for i in range(10): MyProcess().start()
传参数
import time from multiprocessing import Process class MyProcess(Process): def __init__(self,name): super().__init__() # 执行父类中的同名方法: self.name = name def run(self): time.sleep(1) print('%s wahaha' % self.name) if __name__ == '__main__': for i in range(10): MyProcess('alex').start()
8.主进程结束之后,我不想让我的子进程运行了,怎么做?
terminate 非阻塞
非阻塞的原因是:terminate之后子进程不会立马被杀死,一定时间后,才会被杀死。
import time from multiprocessing import Process def wahaha(): i = 0 while i < 5: print('第%s秒' % i) time.sleep(1) i += 1 if __name__ == '__main__': p = Process(target=wahaha) p.start() time.sleep(3) print('主进程') print(p.is_alive()) # 判断一个子进程是否活着 p.terminate() # 结束一个子进程 print(p.is_alive()) # 判断一个子进程是否活着 time.sleep(0.1) print(p.is_alive()) # 判断一个子进程是否活着
9.守护进程
注意:只能守护主进程的代码,不能守护整个进程
作用:报活
① 守护进程的属性,默认是False,如果设置成True,就表示设置这个子进程为一个守护进程
② 设置守护进程的操作应该在开启子进程之前
③ 设置成守护进程之后,会有什么效果呢?
守护进程会在主进程的代码执行完毕之后直接结束,无论自己是否执行完毕
import time from multiprocessing import Process def func(): while True: print('is alive') time.sleep(0.5) if __name__ == '__main__': p = Process(target=func) p.daemon = True # 这个p进程就成为守护进程了 p.start() time.sleep(3) print('主进程')
import time from multiprocessing import Process def func(): while True: print('is alive') time.sleep(0.5) def wahaha(): i = 0 while i < 5: print('第%s秒' % i) time.sleep(1) i += 1 if __name__ == '__main__': Process(target=wahaha).start() p = Process(target=func) p.daemon = True # 这个p进程就成为守护进程了 p.start() time.sleep(3) print('主进程')
如果非要等到子进程(守护进程之外的子进程)结束守护进程才结束,怎么做?
对子进程加join
import time from multiprocessing import Process def func(): while True: print('is alive') time.sleep(0.5) def wahaha(): i = 0 while i < 5: print('第%s秒' % i) time.sleep(1) i += 1 if __name__ == '__main__': p2 = Process(target=wahaha) p2.start() p = Process(target=func) p.daemon = True # 这个p进程就成为守护进程了 p.start() time.sleep(3) print('主进程') p2.join() # 守护进程会等待p2子进程结束之后才结束守护
二、进程同步
1.锁(互斥锁) ***** Lock
# 当多个进程共享一段数据的时候,数据会出现不安全的现象
# 需要加锁来维护数据的安全性。
# 维护了数据的安全,但却降低了程序的效率
# 所有的效率都是建立在数据安全的角度上的
# 但凡涉及到并发编程都要考虑数据的安全性
# 我们需要在并发部分对数据修改的操作格外小心,如果涉及到数据的不安全,就需要进行加锁控制。

# 为了避免同一段代码被多个进程同时进行,所以加上锁 from multiprocessing import Lock lock = Lock() # 创造一个锁
lock.acquire() # 想拿钥匙 print(1) lock.release() # 还钥匙 lock.acquire() # 想拿钥匙 print('拿到钥匙了') lock.release() # 还钥匙
查票的例子
# 查票的例子 import time import json from multiprocessing import Process,Lock def search(i): with open('db',encoding='utf-8')as f: dic = json.load(f) time.sleep(0.2) print('Person %s 正在查票,余票为:%s' %(i,dic['count'])) def buy(i): with open('db',encoding='utf-8')as f: dic = json.load(f) time.sleep(0.2) if dic['count'] > 0: dic['count'] -= 1 print('Person %s 买到票' % i) time.sleep(0.2) with open('db','w',encoding='utf-8')as f: json.dump(dic,f) def get_target(i,lock): search(i) lock.acquire() buy(i) lock.release() if __name__ == '__main__': lock = Lock() for i in range(10): Process(target=get_target,args=(i,lock)).start()
2.信号量(锁 + 计数器)*** Semaphore
多把钥匙对应一把锁
from multiprocessing import Semaphore sem = Semaphore(4) # 放4把钥匙 sem.acquire() # 想拿钥匙 print(1) sem.acquire() # 想拿钥匙 print(2) sem.acquire() # 想拿钥匙 print(3) sem.acquire() # 想拿钥匙 print(4) sem.release() sem.acquire() # 想拿钥匙 print(5)
KTV的例子
import time import random from multiprocessing import Process,Semaphore def ktv(sem,i): sem.acquire() # 想拿钥匙 print('%s走进ktv' % i) time.sleep(random.randint(1,3)) print('%s走出ktv' % i) sem.release() if __name__ == '__main__': sem = Semaphore(4) # 放4把钥匙 for i in range(10): p = Process(target=ktv,args=(sem,i)) p.start() # 上下文管理节省代码:节省acquire和release import time import random from multiprocessing import Process,Semaphore def ktv(sem,i): with sem: # 想拿钥匙 print('%s走进ktv' % i) time.sleep(random.randint(1,3)) print('%s走出ktv' % i) if __name__ == '__main__': sem = Semaphore(4) # 放4把钥匙 for i in range(10): p = Process(target=ktv,args=(sem,i)) p.start()
3.事件 ** Event
控制子进程执行还是阻塞的一个机制-----事件
wait方法:
在事件中有一个标志
如果这个标志是True,wait方法的执行效果就是pass
如果这个标志是False,wait方法的效果就是阻塞
判断标志状态的方法:
is_set
控制标志状态的方法:
set方法,将标志设置为True
clear方法,将标志设置为False
from multiprocessing import Event e = Event() print(e.is_set()) e.wait() # 一直阻塞,说明事件在创建之初标志的状态是False e.set() # 将标志改为True print(e.is_set()) e.wait() # 当标志为True 不阻塞
e.wait(timeout=10)
如果信号在阻塞10秒之内变为True,那么不继续阻塞直接pass,
如果信号在阻塞10秒之后状态还是没变,那么也不继续阻塞,但是状态仍是False
print(e.is_set())
无论前面的wait的timeout是否通过,我的状态都不会因此改变
import time from multiprocessing import Event,Process def func1(e): print('start funci') e.wait() print('end funci') if __name__ == '__main__': e = Event() Process(target=func1,args=(e,)).start() time.sleep(3) e.set()
import time from multiprocessing import Event,Process def func1(e): print('start func1') e.wait(1) print('end func1') if __name__ == '__main__': e = Event() Process(target=func1,args=(e,)).start() time.sleep(3) e.set()
红绿灯的例子
import time import random from multiprocessing import Event,Process def trafic_light(e): print('\033[1;37;41m红灯亮\033[0m') while True: time.sleep(2) if e.is_set(): print('\033[1;37;41m红灯亮\033[0m') e.clear() else: print('\033[1;37;42m绿灯亮\033[0m') e.set() def car(i,e): if not e.is_set(): print('%s正在等待通过' % i) e.wait() print('%s通过' % i) if __name__ == '__main__': e = Event() light = Process(target=trafic_light,args=(e,)) light.daemon = True light.start() car_lst = [] for i in range(20): p = Process(target=car,args=(i,e)) p.start() time.sleep(random.randint(2,3)) car_lst.append(p) for car in car_lst: car.join()
三、进程间通信 -------- IPC Queue
1.队列 ----- 子进程的返回值给父进程
队列 = 管道 + 锁
自带进程锁
维护了一个先进先出的顺序
保证了数据在进程之间的安全

from multiprocessing import Queue q = Queue() q.put(1) q.put(2) q.put(3) q.put('aaa') q.put([1,2,3]) q.put({'k':'v'}) # 先进先出 print(q.get()) print(q.get()) print(q.get()) print(q.get()) print(q.get()) print(q.get())
from multiprocessing import Queue q = Queue(5) # 队列只能容纳5个值,若不填数字,则能容纳无穷 q.put(1) q.put(2) q.put(3) q.put('aaa') q.put([1,2,3]) print(q.empty()) # 判断队列是否为空 print(q.full()) # 判断队列是否满了 q.put({'k':'v'}) # 满了之后再放就会在这里一直阻塞
from multiprocessing import Queue q = Queue(5) # 队列只能容纳5个值,若不填数字,则能容纳无穷 # q.get() # 当队列里没有值,还要取值的时候,就会一直阻塞 try: q.get_nowait() # 当队列里没有值,还要取值的时候,就会报错,所以来个异常处理 except: print('队列里没有值')
from multiprocessing import Queue q = Queue(4) # 队列只能容纳5个值,若不填数字,则能容纳无穷 q.put(1) q.put(2) q.put(3) q.put('aaa') # q.put([1,2,3]) # 队列满了之后在放值就会阻塞 try: q.put_nowait([1,2,3]) except: print('丢失了一个数据')
# 使用队列进行进程间的通信 # 例子: from multiprocessing import Process,Queue def func(num,q): q.put({num:num ** num}) # print(66666666666) if __name__ == '__main__': q = Queue() for i in range(10): p = Process(target=func,args=(i,q)) p.start() # print(111) for i in range(10): print(q.get()) # print(222)
生产者消费者模型 ---- 主要解决供销数据不平衡
# 解决生产数据和消费数据的效率不平衡问题
# 把创造数据 和 处理数据 放在不同的进程中
# 根据他们的效率来调整进程的个数
# 生产数据快,消费数据慢,造成内存空间的浪费
# 消费数据快,生产数据慢,造成效率低下
# 生产者消费者模型---包子的故事 # 简单版 import time import random from multiprocessing import Process,Queue def consumer(q): while True: obj = q.get() # print(obj) print('消费了一个数据%s'% obj) time.sleep(random.randint(1,3)) if __name__ == '__main__': q = Queue() p = Process(target=consumer,args=(q,)) p.start() for i in range(10): time.sleep(random.randint(1,5)) q.put('food%s'% i) print('生产了一个数据food%s'% i)
有一些问题:
# consumer结束不了
# 生产者消费者速度不一致,生产慢
解决问题:
# 让consumer停下来的方法
# 在所有生产者结束生产之后,向队列中放入一个结束符
# 有几个consumer就向队列中放几个结束符
# 在消费者消费的过程中,接受到结束符,接结束消费的进程
# 解决生产慢的方法
# 多开几个生产者的进程
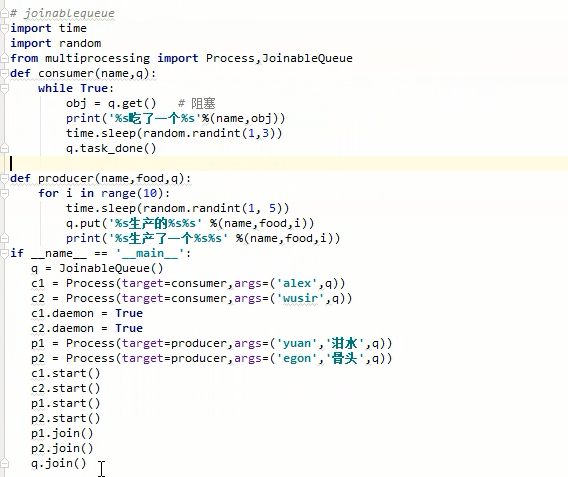
# 生产者消费者模型 import time import random from multiprocessing import Process,Queue def consumer(name,q): while True: obj = q.get() if obj is None:break print('%s消费了一个数据%s'% (name,obj)) time.sleep(random.randint(1,3)) def producer(name,food,q): for i in range(10): time.sleep(random.randint(1,5)) q.put('%s生产的%s%s'% (name,food,i)) print('%s生产了一个数据%s%s'% (name,food,i)) if __name__ == '__main__': q = Queue() Process(target=consumer,args=('alex',q)).start() Process(target=consumer,args=('taibai',q)).start() p1 = Process(target=producer,args=('yuan','泔水',q)) p1.start() p2 = Process(target=producer,args=('egon','骨头',q)) p2.start() p1.join() p2.join() q.put(None) q.put(None)
【扩展】
joinablequeue
# 提供q.join() 这个方法,该方法对队列进行阻塞,
# 当这个队列中的所有的值被取走,且每次执行了一个task_done的时候,对队列结束阻塞。
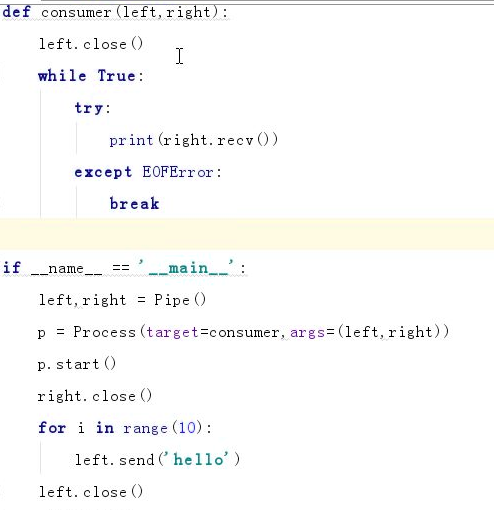
2.管道------ 双向通信的机制
队列就是基于管道实现的
队列 ---- 数据安全
管道 ---- 数据不安全
队列 = 管道 + 锁
# 在这一个进程中,如果不再用这个端点了,应该close
# 在recv的时候,如果其他端点都被关闭了,就能够知道不会再有新的消息传进来
# 此时就不会在这里阻塞等待,而是抛出一个EOFError
# close 并不是关闭了整个管道,而是修改了操作系统对管道端点的引用计数的处理
# 进程通信时数据不安全,存在资源抢占的问题 from multiprocessing import Pipe lp,rp = Pipe() # left,right lp.send([1,2,3]) print(rp.recv()) rp.send('aa') print(lp.recv())
四、进程之间的数据共享 Manager
数据不安全,需加锁
五、进程池 Pool
# 多进程和进程池的对比
# 对于纯计算型的代码,使用进程池更好 ----- 真理
# 对于高IO的代码,直接使用多进程更好 ----- 相对论
# 使用进程池提交任务
# apply 同步提交任务,没有多进程的优势
# apply_async 异步提交任务 常用 可以通过get方法获取返回值
# close 关闭进程池,阻止往池中添加新的任务
# join join依赖close,一个进程池必须先close再join

from multiprocessing import Pool,Process def wahaha(i): print(i) if __name__ == '__main__': p = Pool(5) # for i in range(100): # p.apply_async(func=wahaha,args=(i,)) # p.close() # p.join() p.map(func=wahaha,iterable=range(100))
import time from multiprocessing import Pool,Process def wahaha(i): print(i) time.sleep(1) return i*'-' if __name__ == '__main__': p = Pool(5) r_lst = [] for i in range(100): r = p.apply_async(func=wahaha,args=(i,)) r_lst.append(r) for r in r_lst: print(r.get()) p.close() p.join()
import os import time from multiprocessing import Pool def wahaha(): time.sleep(1) print(os.getpid()) return True if __name__ == '__main__': p = Pool(5) ret_lst = [] for i in range(10): ret = p.apply_async(func=wahaha) #异步的 ret_lst.append(ret) p.close() p.join() for ret in ret_lst: print(ret.get()) # 这样可以有异步的效果,但是打印效果是任务全都结束后才打印返回值
回调函数
在主进程中执行
有异步的效果,打印效果是任务和返回值交替打印
# 回调函数 import time from multiprocessing import Pool def wahaha(i): time.sleep(0.1) print(i) return True def call(argv): print(argv) if __name__ == '__main__': p = Pool(5) for i in range(10): p.apply_async(func=wahaha,args=(i,),callback=call) p.close() p.join()
