
IQMath定点数运算库性能测试
基本信息
单片机:GD32F303RC,运行主频:120MHz,SRAM:48KB,Flash:256KB,带单精度FPU
编译环境:ARMCC 5.06 update6 (build750)
由于iq数的底层数据类型是4字节的int32_t因此_iq30 ~ _iq1 尽管表示的精度不同,但是运算速度是相同的。下列测试使用_iq15作为被测数据类型,能表示的范围从-65536到65535.999969483,精度是0.000030518/LSB。
测试代码
声明数组变量用于存储两个操作数向量和一个结果向量
#define CONST_PI_VAL 3.1415926f
#define VECTOR_SIZE 1000
static _iq15 ResultVector[VECTOR_SIZE];
static _iq15 VectorA[VECTOR_SIZE];
static _iq15 VectorB[VECTOR_SIZE];
static float ResultVectorF[VECTOR_SIZE];
static float VectorAF[VECTOR_SIZE];
static float VectorBF[VECTOR_SIZE];
测试数组的初始化,_IQ15(1.0221f)这种IQ立即数在编译时就已确定,因此VectorA[index] = _IQ15(1.0221f) * index; 等效于两个32位数据相乘,数组初始化不计入测试时间。
static void BenchmarkVectorIQArrayInit(void) {
unsigned int index = 0u;
for(index = 0; index < VECTOR_SIZE; index++) {
VectorA[index] = _IQ15(1.0221f) * index;
VectorB[index] = _IQ15(2.127f) * index;
ResultVector[index] = 0;
}
}
static void BenchmarkVectorFloatArrayInit(void) {
unsigned int index = 0u;
for(index = 0; index < VECTOR_SIZE; index++) {
VectorAF[index] = 1.0221f * index;
VectorBF[index] = 2.127f * index;
ResultVectorF[index] = 0.0f;
}
}
IQ数累加和浮点数累加
static void VectorIQAdd(_iq15 *vectorA, _iq15 *vectorB, _iq15 *result) {
unsigned int index = 0u;
for(index = 0; index < VECTOR_SIZE; index++) {
result[index] = vectorA[index]+ vectorB[index];
}
}
static void VectorFloatAdd(float *vectorA, float *vectorB, float *result) {
unsigned int index = 0u;
for(index = 0; index < VECTOR_SIZE; index++) {
result[index] = vectorA[index] + vectorB[index];
}
}
IQ数相乘和浮点数相乘
static void VectorIQMultiply(_iq15 *vectorA, _iq15 *vectorB, _iq15 *result) {
unsigned int index = 0u;
for(index = 0; index < VECTOR_SIZE; index++) {
result[index] = _IQ15mpy(vectorA[index], vectorB[index]);
}
}
static void VectorFloatMultiply(float *vectorA, float *vectorB, float *result ) {
unsigned int index = 0u;
for(index = 0; index < VECTOR_SIZE; index++){
result[index] = vectorA[index] * vectorB[index];
}
}
IQ数除法和浮点数除法
static void VectorIQDiv(_iq15 *vectorA, _iq15 *vectorB, _iq15 *result) {
unsigned int index = 0u;
for(index = 0; index < VECTOR_SIZE; index++) {
result[index] = _IQ15div(vectorA[index], vectorB[index]);
}
}
static void VectorFloatDiv(float *vectorA, float *vectorB, float *result) {
unsigned int index = 0u;
for(index = 0; index < VECTOR_SIZE; index++) {
result[index] = vectorA[index] / vectorB[index];
}
}
IQ数乘加和浮点数乘加,y=kx+b
static void VectorIQScale(_iq15 *vectorA, _iq15 *vectorB, _iq15 *result) {
unsigned int index = 0u;
for(index = 0; index < VECTOR_SIZE; index++) {
result[index] = _IQ15mpy(vectorA[index], _IQ15(CONST_PI_VAL));
result[index] += vectorB[index];
}
}
static void VectorFloatScale(float *vectorA, float *vectorB, float *result) {
unsigned int index = 0u;
for(index = 0; index < VECTOR_SIZE; index++) {
result[index] = (vectorA[index] * CONST_PI_VAL) + vectorB[index];
}
}
性能测试使用Cortex-m4自带的32位DWT计数器,计数频率和CPU主频相同。
static void hw_dwt_init(void) {
// DWT timer enable
CoreDebug->DEMCR = 0x1000000;
// clear Cycle Count Register
DWT->CYCCNT = 0x0;
// enable Data Watchpoint and Trace Register
DWT->CTRL = 0x1;
}
测试代码模板,由于测试代码执行时间较短,不用考虑DWT计数器溢出问题。
start = DWT->CYCCNT;
// 此处运行测试代码
end = DWT->CYCCNT;
diff = end - start;
rt_kprintf("elapse:%d\n", diff);
测试结果
IQ数和单精度软浮点数对比,单片机未开启FPU,代码优化等级-O3,计算次数1000。

DWT计数原始数据:120MHz
| 数据类型 | 加法 | 乘法 | 除法 | 乘加 |
|---|---|---|---|---|
| iq15 | 11006 | 41007 | 155487 | 49006 |
| 软浮点 | 64454 | 57436 | 240989 | 116753 |
DWT换算时间:微秒
| 数据类型 | 加法 | 乘法 | 除法 | 乘加 |
|---|---|---|---|---|
| iq15 | 91.716 | 341.725 | 1295.725 | 408.383 |
| 软浮点 | 537.116 | 478.633 | 2008.2416 | 972.9416 |
IQ数和单精度硬浮点数对比,单片机开启单精度FPU,代码优化等级-O3,计算次数1000。
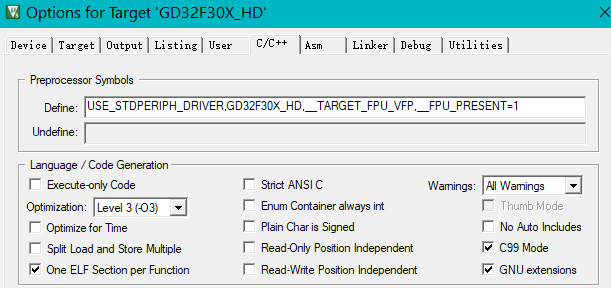

DWT计数原始数据:120MHz
| 数据类型 | 加法 | 乘法 | 除法 | 乘加 |
|---|---|---|---|---|
| iq15 | 11006 | 41007 | 155454 | 49006 |
| 硬浮点 | 17007 | 17007 | 30007 | 19039 |
DWT换算时间:微秒
| 数据类型 | 加法 | 乘法 | 除法 | 乘加 |
|---|---|---|---|---|
| iq15 | 91.716 | 341.725 | 1,295.45 | 408.383 |
| 硬浮点 | 141.725 | 141.725 | 250.0583 | 158.6583 |
总结
IQ数相比软浮点数性能提升
| 加法 | 乘法 | 除法 | 乘加 | |
|---|---|---|---|---|
| 提升百分比 | 82.92% | 28.604% | 35.47% | 58.02% |
IQ数相比硬浮点数性能提升(下降)
| 加法 | 乘法 | 除法 | 乘加 | |
|---|---|---|---|---|
| 提升/下降百分比 | 35.28% | -58.52% | -80.697% | -61.149% |
在单片机有浮点数加速单元的情况下,开启浮点数协处理器CP10,并且打开编译器的硬浮点代码生成,乘法和除法直接使用float数据类型进行计算的速度是最快的;而IQ定点数只在加法和减法有优势,由于IQ定点数可以和浮点数相互转换,某些精度和值范围确定的场合可以结合两者使用。但我认为性能提升有限或者没有,毕竟调用函数__IQNtoF将IQ定点数转成浮点数也需要代码执行时间,定点数加减计算+转换为浮点数的总时间不一点比直接浮点数加减来的快。
在没有FPU的单片机,例如不带FPU的Cortex-M4,Cortex-M0/M0p,ARM9等内核,使用IQMathlib提供的定点数替代软浮点数会带来性能的提升。
即使是精心优化的软件代码也难以敌过硬件加速器带来的性能提升,有浮点数运算需求尽量选择带FPU的单片机。
资料下载
本例程用到的iqmath定点库源码:
https://files.cnblogs.com/files/blogs/575121/iqmath.zip
iqmath在线用户指南
https://software-dl.ti.com/msp430/esd/MSPM0-SDK/1_10_01_05/docs/chinese/middleware/iqmath/doc_guide/doc_guide-srcs/Users_Guide_CN.html
https://software-dl.ti.com/msp430/esd/MSPM0-SDK/1_10_01_05/docs/chinese/middleware/iqmath/doxygen/api_guide/html/index.html

