
RTX5 内核中断配置详解
Cortex-M中断控制器
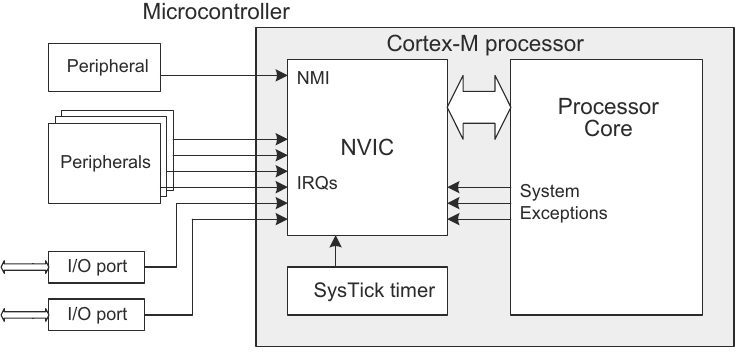
Cortex-M中断优先级机制
Cortex-M4的内核中断(也称异常)的优先级通过core_cm4.h文件中SCB_Type结构的SCB->SHP[0] ~ SCB->SHP[11]成员进行配置:
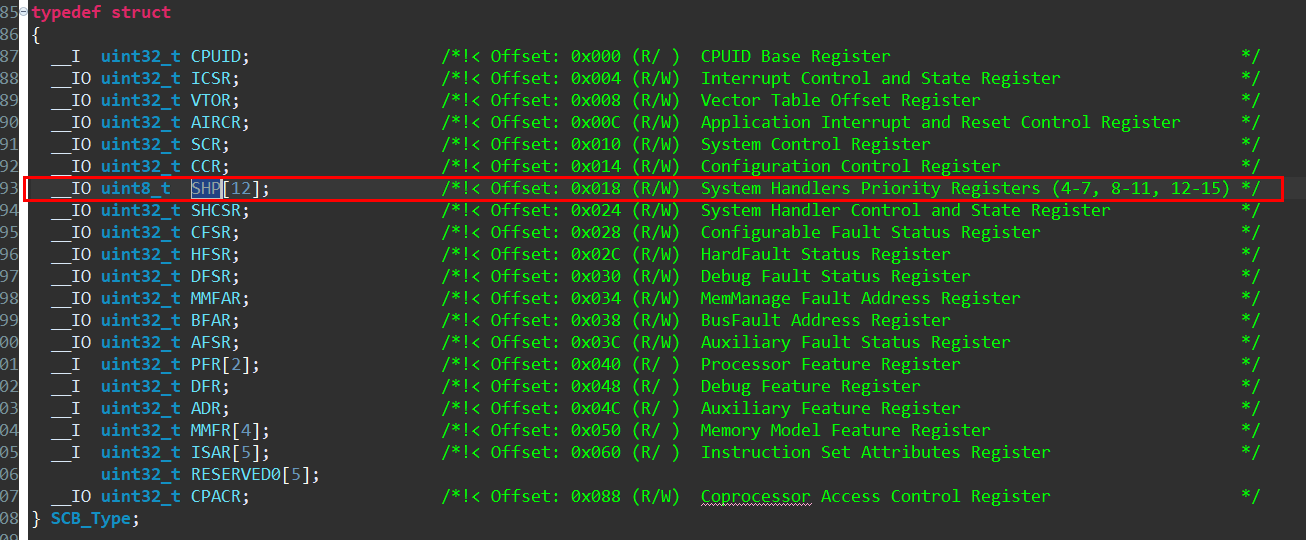
通过上图看到,该寄存器可以按字节寻址,那么每个优先级位实际值范围在0x00 ~ 0xFF之间,当然实际的芯片不会给这么多优先级,下面以GD32F303为例,只有4Bit用于配置优先级,这里的bit数量是按高位开始计算的,也就是说在GD32F303芯片中SCB->SHP[0] ~ SCB->SHP[11]只有高4位是有效的(这个优先级定义还同时对NVIC->IP寄存器有效)。

而这4bit还要分成抢占优先级和响应优先级,可以组成5个优先级组,需要注意的是优先级寄存器(SCB->SHP, NVIC->IP)的值高bit表示抢占优先级,低bit表示响应优先级。

-
NVIC_PRIGROUP_PRE0_SUB4,4bit全部表示响应优先级。范围
0~15没有中断嵌套,优先级高的先响应,和ARM9,Contex-A的IRQ中断类似。 -
NVIC_PRIGROUP_PRE1_SUB3,高1bit表示抢占优先级,低3bit表示响应优先级。因此有2种抢占优先级,0优先级组和1优先级组,其中0优先级组的任意一个中断可以抢占1优先级组的中断(发生嵌套);低3bit可以表示8种组内优先级,组内不会发生嵌套,组内优先级高的先响应,优先级低的则挂起等待。
-
NVIC_PRIGROUP_PRE2_SUB2,原理和NVIC_PRIGROUP_PRE1_SUB3相同,以此类推
-
NVIC_PRIGROUP_PRE3_SUB1,原理和NVIC_PRIGROUP_PRE1_SUB3相同,以此类推
-
NVIC_PRIGROUP_PRE4_SUB0,4bit全部表示抢占优先级,范围
0~15,相同抢占优先级的中断不会互相嵌套,高优先级的中断会抢占低优先级。
下面以函数nvic_irq_enable为例,介绍NVIC->IP寄存器优先级设置的过程,NVIC->IP和SCB->SHP寄存器的优先级定义通常是相同的。
void nvic_irq_enable(uint8_t nvic_irq, uint8_t nvic_irq_pre_priority,
uint8_t nvic_irq_sub_priority) {
uint32_t temp_priority = 0x00U, temp_pre = 0x00U, temp_sub = 0x00U;
/* use the priority group value to get the temp_pre and the temp_sub */
if(((SCB->AIRCR) & (uint32_t)0x700U)==NVIC_PRIGROUP_PRE0_SUB4){
// 4bit全表示响应优先级
temp_pre=0U;
temp_sub=0x4U;
}else if(((SCB->AIRCR) & (uint32_t)0x700U)==NVIC_PRIGROUP_PRE1_SUB3){
// 1bit抢占,3bit响应
temp_pre=1U;
temp_sub=0x3U;
}else if(((SCB->AIRCR) & (uint32_t)0x700U)==NVIC_PRIGROUP_PRE2_SUB2){
// 原理同上
temp_pre=2U;
temp_sub=0x2U;
}else if(((SCB->AIRCR) & (uint32_t)0x700U)==NVIC_PRIGROUP_PRE3_SUB1){
// 原理同上
temp_pre=3U;
temp_sub=0x1U;
}else if(((SCB->AIRCR) & (uint32_t)0x700U)==NVIC_PRIGROUP_PRE4_SUB0){
// 4bit全表示抢占优先级
temp_pre=4U;
temp_sub=0x0U;
}else{
// 默认情况
nvic_priority_group_set(NVIC_PRIGROUP_PRE2_SUB2);
temp_pre=2U;
temp_sub=0x2U;
}
// 以下4行代码是关键
/* get the temp_priority to fill the NVIC->IP register */
// nvic_irq_pre_priority表示抢占优先级, 取值 0x0 ~ 0xF
// nvic_irq_sub_priority表示响应优先级, 取值 0x0 ~ 0xF
// temp_priority 表示计算得到的优先级组合值, 取值 0x0 ~ 0xF
// 将抢占优先级左移 `4-抢占优先级bit数`,即将抢占优先级放在高位
// 当temp_pre = 0时,nvic_irq_pre_priority左移4,抢占优先级被移出取值范围,抢占优先级不生效。
// 当temp_pre = 1时,nvic_irq_pre_priority左移3,抢占优先级值只有最低1-bit有效。
// 当temp_pre = 4时,nvic_irq_pre_priority没发生左移操作,抢占优先级位数被全部保留。
temp_priority = (uint32_t)nvic_irq_pre_priority << (0x4U - temp_pre);
// 0x0FU >> (0x4U - temp_sub)生成了响应优先级的掩码,
// 和nvic_irq_sub_priority进行与操作时,只有掩码bit为1的部分得以保留。
// 当temp_sub = 4时,生成的掩码是0x0F,响应优先级被全部保留。
// 当temp_sub = 3时,生成的掩码是0x07,响应优先级只有低三位保留,范围 0 ~ 7。
// 当temp_sub = 0时,生成的掩码是0x0,和nvic_irq_sub_priority相与操作后,
// nvic_irq_sub_priority = 0,响应优先级不生效。
// "temp_priority |="操作,将响应优先级放在了低位,和抢占优先级进行组合。
temp_priority |= nvic_irq_sub_priority &(0x0FU >> (0x4U - temp_sub));
// 由于NVIC->IP寄存器只有高4bit用于表示优先级,
// 因此将计算得到的priority左移4位,低位自动补零(低4位无意义),
// 最后将值写入nvic_irq对应的NVIC->IP寄存器。
temp_priority = temp_priority << 0x04U;
NVIC->IP[nvic_irq] = (uint8_t)temp_priority;
}
抢占优先级(pre-emption priority)
高抢占优先级的中断会打断当前的主程序/中断程序运行, 俗称中断嵌套
响应优先级(subpriority)
在抢占优先级相同的情况下, 高响应优先级的中断优先被响应 ( 但是不能嵌套 )
如果有低响应优先级中断正在执行,高响应优先级的中断要等待已被响应的低响应优先级中断执行结束后才能得到响应
优先级处理
优先级数值较小的优先级较高, 优先级0x00 有最高的优先级, 优先级0xF0 有最低的优先级
在进行优先级判断的时候先是比较抢占优先级, 然后比较响应优先级。
当两个中断源的抢占式优先级相同时,这两个中断将没有嵌套关系,
当一个中断到来后,如果正在处理另一个中断,这个后到来的中断就要等到前一个中断处理完之后才能被处理。
如果这两个中断同时到达,则中断控制器根据他们的响应优先级高低来决定先处理哪一个;
如果他们的抢占式优先级和响应优先级都相等,则根据他们在中断表中的排位顺序决定先处理哪一个。
数据来源: https://www.cnblogs.com/shangdawei/archive/2013/04/03/2998810.html
RTX5使用的内核中断
在Cortex-M处理器中,RTX5需要使用SysTick,PendSV,和SVC三个内核中断。

其中PendSV, SVC是必须的,SysTick只是用在基于时间的调度上,因此可以换成任意一种通用定时器。以Cortex-m4内核的处理器为例,进入RTOS2/RTX/Source/GCC/irq_armv7m.S,将SysTick_Handler换成想要使用的通用定时器中断入口(例如TIMER1_IRQHandler);并且进入RTOS2/Source/os_systick.c,在OS_Tick_Setup完成定时器的初始化,实现OS_Tick_GetCount返回计数值等等,把os_systick.c中的函数按照功能需求对接到通用定时器即可。
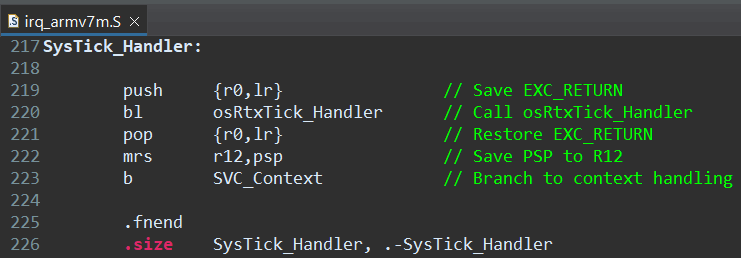
中断优先级配置
如下图,Systick和PendSV都是相同的最低优先级,SVC比最低优先级高一级。

下图展示了RTX5要求的优先级配置,这里将按实际的Cortex-m4情况进行说明。

The RTX kernel uses the priority group value to setup the priority for SysTick and PendSV interrupts. RTX内核使用优先级组的值来设置SysTick和PendSV中断的优先级。
在RTX5系统中,SysTick,PendSV被强制设置成最低优先级(0xFF),因此这两个中断的优先级和优先级组的设置无关。
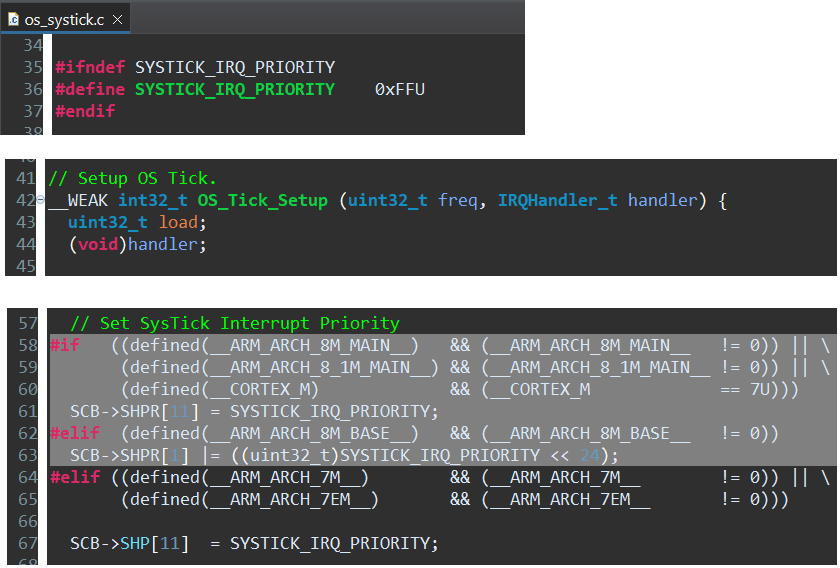
SysTick:
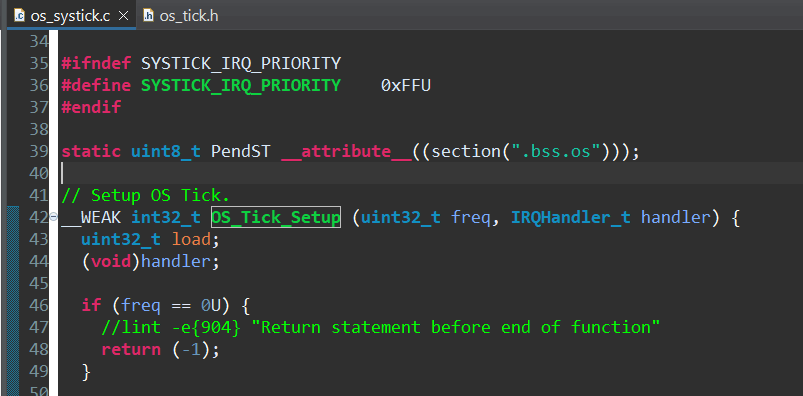
RTOS2/Source/os_systick.c文件,OS_Tick_Setup函数中已经将SysTick配置为最低优先级(最大值表示最低优先级,对于抢占,则表示最低优先级组的最低优先级)。
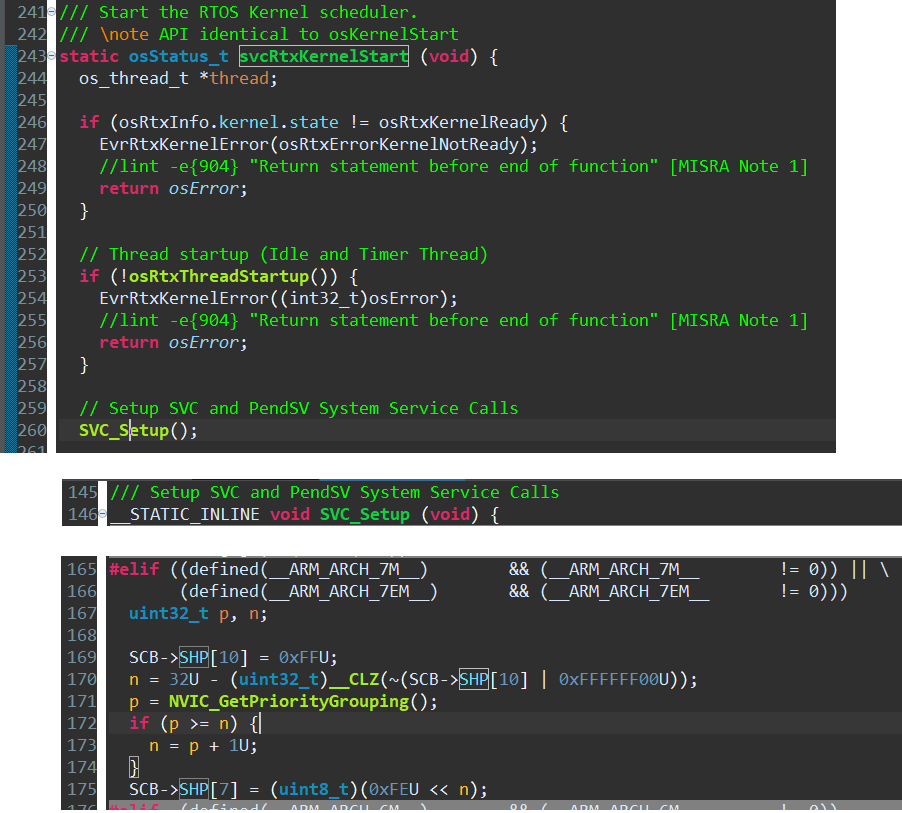
PendSV:
RTOS2/RTX/Source/rtx_kernel.c文件中,svcRtxKernelStart函数调用SVC_Setup(位于RTOS2/RTX/Source/rtx_core_cm.h)
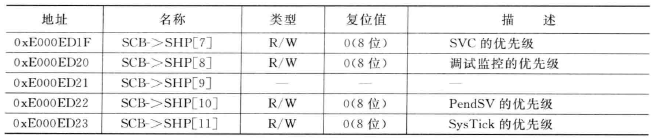
SCB->SHP[10] = 0xFFU;
上面摘取的代码表示将PendSV配置为最低优先级(最大值表示最低优先级,对于抢占,则表示最低优先级组的最低优先级)。
因此,对于SysTick和PendSV的中断优先级配置,在调用svcRtxKernelStart函数之前,我们无需手动进行配置;在调用svcRtxKernelStart函数之后,也不建议再次修改SysTick和PendSV的中断优先级。
SVC:
当优先级配置成4bit全表示抢占优先级时,SVC的优先级才会是lowest+1,即优先级14。
nvic_priority_group_set(NVIC_PRIGROUP_PRE4_SUB0);
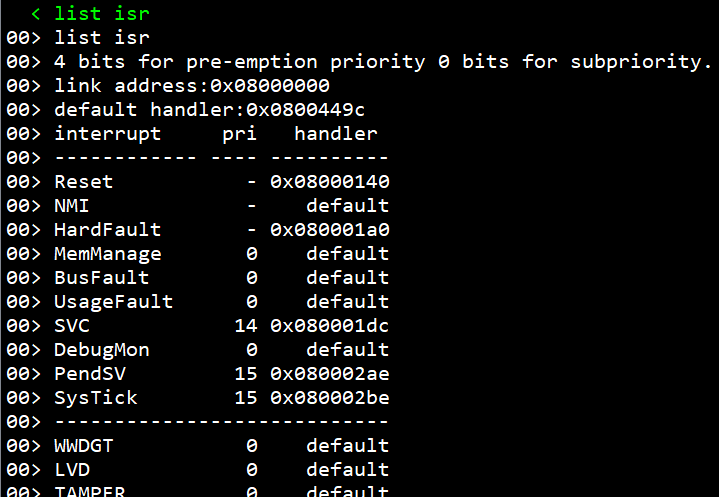
以上代码设置了4bit全表示抢占优先级,没有响应优先级。使用list isr查询当前系统配置的中断优先级(list isr是RTXThread的拓展,不存在于原版RT-Thread系统中),可以看到SVC优先级正确的设置成了14。
当优先级配置成4bit全表示响应优先级是,SVC的优先级就不是lowest+1了,而会变成最高优先级0。
nvic_priority_group_set(NVIC_PRIGROUP_PRE0_SUB4);
使用list isr可以看到,SVC的优先级发生了改变:
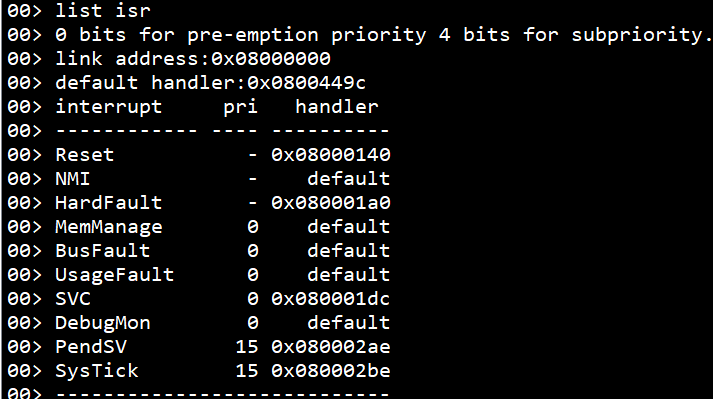
下表列出了不同优先级组下,SVC内核中断优先级的变化情况:
| 优先级组 | SVC的优先级 | 说明 | 其他 |
|---|---|---|---|
| NVIC_PRIGROUP_PRE0_SUB4 | 0 | 最高响应优先级(0级) | - |
| NVIC_PRIGROUP_PRE1_SUB3 | 0 | 0组(最高组,可以打断1组)的最高响应优先级(0级) | SysTick PendSV在1组 |
| NVIC_PRIGROUP_PRE2_SUB2 | 8 | 2组(次高组,可以打断3组)的最高响应优先级(0级) | SysTick PendSV在3组 |
| NVIC_PRIGROUP_PRE3_SUB1 | 12 | 6组(次高组,可以打断7组)的最高响应优先级(0级) | SysTick PendSV在7组 |
| NVIC_PRIGROUP_PRE4_SUB0 | 14 | 次低抢占优先级 | SysTick PendSV优先级最低15,可以被SVC抢占 |
通过以上表,可以总结出来,RTX5内核对SVC中断优先级的配置原则如下:
- 不启用抢占优先级情况下,SVC的响应优先级要高于SysTick和PendSV。
- 启用抢占优先级的情况下,SVC的优先级组要高于SysTick和PendSV的优先级组,保证SVC不会被SysTick和PendSV抢占。
RTX5由以下代码进行对SVC中断优先级进行配置
uint32_t p, n;
SCB->SHP[10] = 0xFFU;
// CLZ返回从最高位向最低为数,遇到第一个1之前的0的个数,如果输入0xFFFFFFFF返回0,如果输入0x0,返回32
// 这个常用来快速筛选出就绪线程中的最高优先级线程,例如rt-thread的32个优先级。
// ~(SCB->SHP[10] | 0xFFFFFF00U)
// (SCB->SHP[10] | 0xFFFFFF00U) = 0xFFFFFFFF,按位取反得0x0
// __CLZ(0) = 32,n = 32 - 32 = 0
n = 32U - (uint32_t)__CLZ(~(SCB->SHP[10] | 0xFFFFFF00U));
// p可以取 7,6,5,4,3,对应4bit响应到4bit抢占之间的优先级组
// 这里p总是大于n
p = NVIC_GetPriorityGrouping();
if (p >= n) {
n = p + 1U;
}
// 在GD32F303这类常见的Cortex-m4芯片中,只有4bit优先级,因此这里的0xFEU,实际上只有0xE有效,高4bit的0xF是无效的,因为最少都会左移 3 + 1 = 4位。(Cortex-m4的实际芯片中很少有完整8bit优先级的)
// 0xE对应二进制就是 0B1110,因为最低位是0,怎么左移都不会变成0xF,保证了有抢占优先级情况下,SCB->SHP[7]一定会比最低优先级(0xF)组高一个优先级。
SCB->SHP[7] = (uint8_t)(0xFEU << n);
SVC不能被PendSV/SysTick抢占的原因
在RTX系统中,用户创建线程,释放互斥锁等操作都是通过SVC软中断实现的,这里以创建线程为例。
当调用osThreadNew创建线程时,实际上调用的是__svcThreadNew函数。
rtx_thread.c
// __svcThreadNew的宏定义
SVC0_3 (ThreadNew, osThreadId_t, osThreadFunc_t, void *, const osThreadAttr_t *)
osThreadId_t osThreadNew (osThreadFunc_t func, void *argument, const osThreadAttr_t *attr) {
osThreadId_t thread_id;
// 无关代码已删减...
thread_id = __svcThreadNew(func, argument, attr);
return thread_id;
}
宏展开就是以下内容了,__svcThreadNew内联汇编,通过svc 0产生一个软中断,等待ARM内核前来处理。
rtx_thread.c
__attribute__((always_inline))
static inline osThreadId_t __svcThreadNew (osThreadFunc_t a1, void * a2, const osThreadAttr_t * a3) {
register uint32_t __r0 __asm("r""0") = (uint32_t)a1;
register uint32_t __r1 __asm("r""1") = (uint32_t)a2;
register uint32_t __r2 __asm("r""2") = (uint32_t)a3;
register uint32_t __rf __asm("r12") = (uint32_t)svcRtxThreadNew;
__asm volatile ("svc 0" : "=r"(__r0) : "r"(__rf),"r"(__r0),"r"(__r1),"r"(__r2) : );
return (osThreadId_t) __r0;
随后arm内核进入SVC_Handler进行处理,在中断模式(特权模式)下执行svcRtxThreadNew函数,通过SVC软中断,用户在线程模式调用osThreadNew,最终会导致处理器进入中断执行实际的函数体,这样就隔离了线程模式(用户态)和特权模式(内核态),虽然在cortex-m这样的不带MMU的单片机上只能通过MPU实现有限的权限管理(例如将内核RAM区设置为线程模式不可写)。
irq_armv7m.S
SVC_Handler:
tst lr,#0x04 // Determine return stack from EXC_RETURN bit 2
ite eq
mrseq r0,msp // Get MSP if return stack is MSP
mrsne r0,psp // Get PSP if return stack is PSP
ldr r1,[r0,#24] // Load saved PC from stack
ldrb r1,[r1,#-2] // Load SVC number
cmp r1,#0 // Check SVC number
bne SVC_User // Branch if not SVC 0
push {r0,lr} // Save SP and EXC_RETURN
ldm r0,{r0-r3,r12} // Load function parameters and address from stack
// 直接看这里,r12存放的是svcRtxThreadNew的函数指针(函数入口地址)
// 关于arm汇编blx:
// bl表示带返回值的跳转指令,自动把当前PC压到LR寄存器,子程序返回时mov pc, lr就可以了
// 由于Cortex-m是三级流水线(取指,译码,执行),执行blx r12时,已经预取指令pop {r12,lr}
// 因此PC是pop {r12,lr}的地址
// X表示 arm/thumb状态切换,cortex-m没有ARM Code因此可以忽略。
blx r12 // Call service function
pop {r12,lr} // Restore SP and EXC_RETURN
str r0,[r12] // Store function return value
因此我们还得回到rtx_thread.c文件,虽然osThreadNew和svcRtxThreadNew函数在同一个文件中,但经过SVC_Handler的代理,执行函数的环境已经变了,此时系统在中断环境,使用MSP栈,因此在RTX5移植时,裸机栈需要留有一定空间。
static osThreadId_t svcRtxThreadNew (osThreadFunc_t func, void *argument, const osThreadAttr_t *attr) {
// 初始化线程控制块,栈,寄存器的过程省略...
if (thread != NULL) {
// 最终会调用这个函数
osRtxThreadDispatch(thread);
}
return thread;
}
在osRtxThreadDispatch函数中,thread创建正常(thread不为null),如果优先级大于当前执行线程优先级,会立即发生线程切换,如果不大于,则加入就绪链表。下图可以看出这两个操作都会对osRtxInfo这个全局变量进行修改,而osRtxThreadBlock,osRtxThreadSwitch,osRtxThreadReadyPut这几个函数对全局变量修改前后也没有关闭/开启中断,利用中断锁对osRtxInfo进行保护。
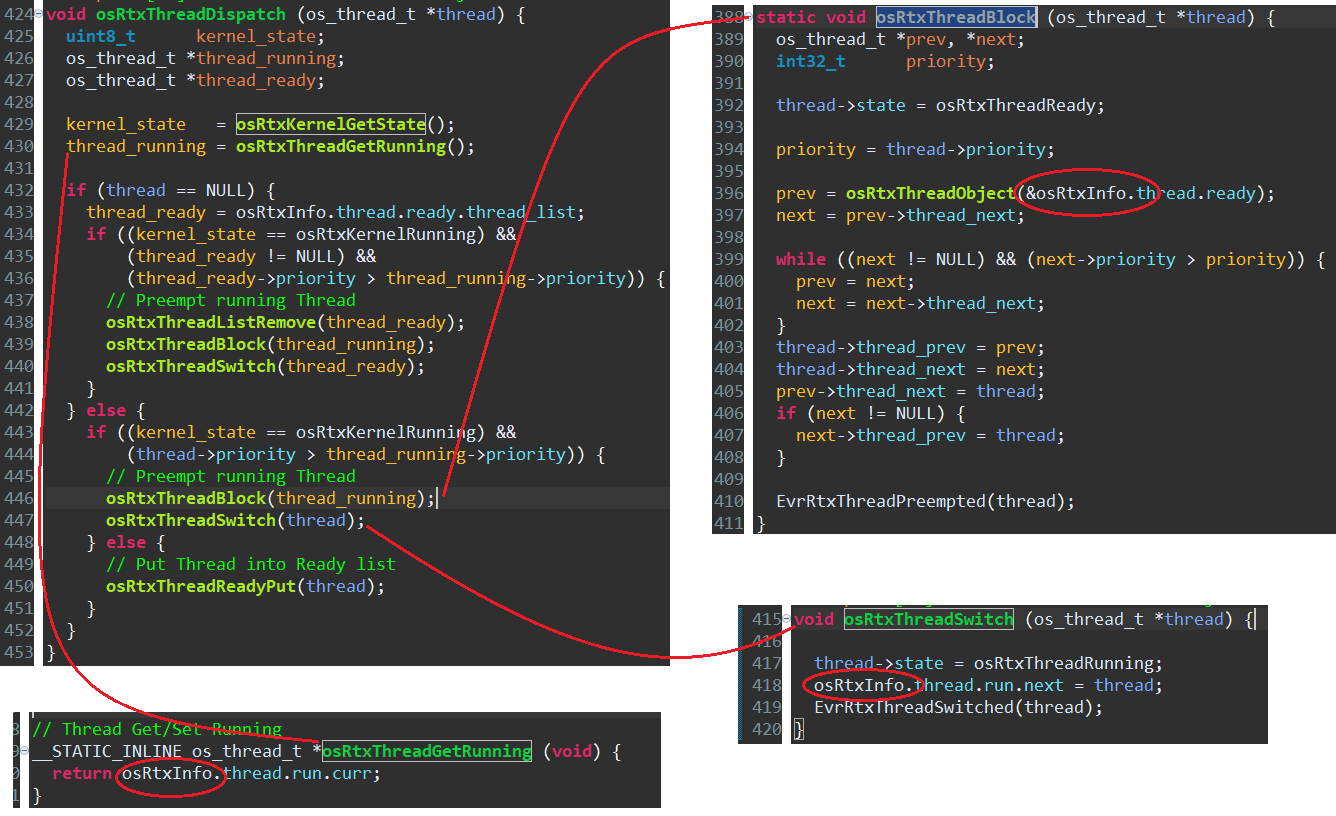
假设此时SysTick中断能抢占SVC中断执行过程,SysTick_Handler会跳转到osRtxTick_Handler函数,而这个函数会接着调用osRtxThreadDispatch。这里就出现了冲突的情况,上一步SVC中断也可能在执行osRtxThreadDispatch,而其中的osRtxThreadBlock这类函数对osRtxInfo全局结构体的链表的操作不具备原子性,若被中途打断,SVC中断程序中修改了一半的数据就会被当前操作覆盖,当中断返回时,SVC中断程序对osRtxInfo写入的写入操作就失效了,若读取osRtxInfo也可能不是当时的值了。
iqr_armv7m.S
SysTick_Handler:
push {r0,lr} // Save EXC_RETURN
bl osRtxTick_Handler // Call osRtxTick_Handler
pop {r0,lr} // Restore EXC_RETURN
mrs r12,psp // Save PSP to R12
b SVC_Context // Branch to context handling
.fnend
.size SysTick_Handler, .-SysTick_Handler
rtx_system.c
void osRtxTick_Handler (void) {
os_thread_t *thread;
OS_Tick_AcknowledgeIRQ();
osRtxInfo.kernel.tick++;
// Process Thread Delays
osRtxThreadDelayTick();
// 基于时间片的调度也会进入该函数
osRtxThreadDispatch(NULL);
// 无关代码省略...
通过以上案例,可以了解到RTX5之所以这样配置内核中断的抢占关系,是因为需要避免调度器自身不会发生抢占,也就不需要类似rt-thread中的中断临界区(中断锁)来保护调度器的一些全局数据结构。
推荐配置
-
对于实时性要求高的应用,例如轴的运行控制,需要快速响应位置传感器(编码器/光栅尺/行程限位)的信号,推荐将NVIC配置成使用4bit都表示抢占优先级的模式(对于GD32宏定义为
NVIC_PRIGROUP_PRE4_SUB0),并且将相应外设的中断信号设置为最高优先级0,同时要评估主栈(MSP)的空间在多次中断嵌套的情况下是否足够,充分发挥Cortex-M和RTX5的优势。 -
对于仪表显示,物联网产品等不要求快速响应的场合,可以设置成4bit都表示响应优先级(对于GD32宏定义为
NVIC_PRIGROUP_PRE0_SUB4),由于同时只会执行某一个中断程序,没有嵌套,这样主栈(MSP)的RAM需求就会降低一些。
参考资料
https://arm-software.github.io/CMSIS_5/RTOS2/html/theory_of_operation.html#Scheduler
https://arm-software.github.io/CMSIS_5/RTOS2/html/cre_rtx_proj.html

