
F1C100S rt-smart 内核移植(一)
嵌入式系统的一般流程
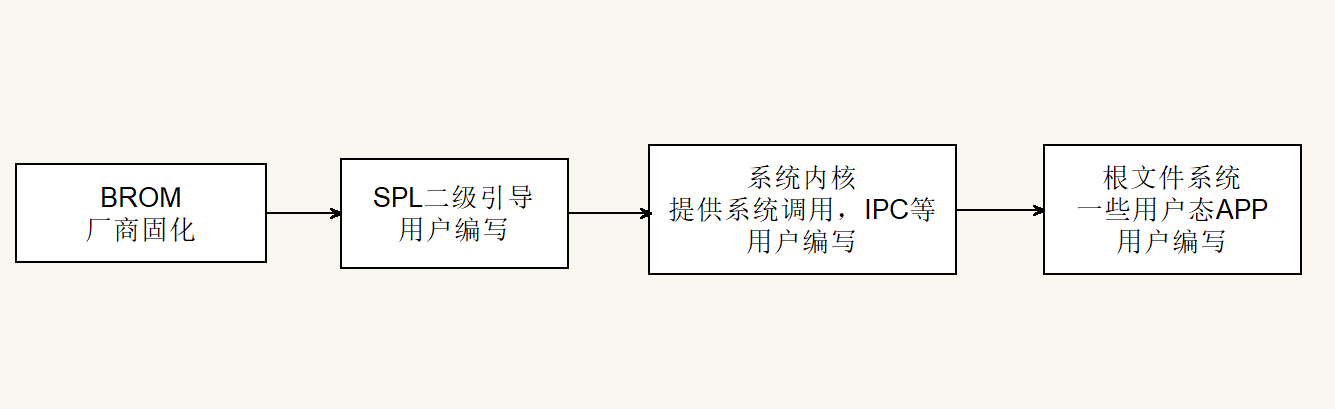
- BROM是厂商固化在芯片内部的,是上电后最早运行的代码,主要做最小系统初始化,然后根据情况(通常是GPIO配置) ,从不同的启动介质加载二级引导程序到处理器内部SRAM。
- SPL程序是用户编写,其最主要的功能是初始化DDR,并将操作系统内核加载到DDR,最终跳转执行。SPL程序可以是存储器裸数据读取,也可以是文件系统方式读取内核,取决于处理器内部SRAM的大小,例如S3C2410内部SRAM仅4KB,就只能做存储器裸数据搬运;TI AM335X系列可用SRAM有107KB,那么就通常支持下FAT文件系统。
- 系统内核运行在DDR中,工作在内核态,向上层应用提供系统调用syscall, ipc通信,文件io等功能,也是整个嵌入式系统的基础。
- 最后就是用户的根文件系统,里面包含所有用户态的程序,做系统移植时这部分可用先忽略,若需要测试用户态程序,推荐使用romfs做测试。
SPL的准备工作
在SPL程序的链接脚本中可用看到,放在最终生成文件最前面的是start.o的代码段spl/src/start.o (.text*),据此可用找到start.S便是SPL程序最开始执行的代码。
SECTIONS
{
. = 0x00000000;
.text :
{
PROVIDE(__image_start = .);
PROVIDE(__text_start = .);
PROVIDE(__spl_start = .);
spl/src/start.o (.text*)
*(.text) /* .text sections (code) */
*(.text*) /* .text* sections (code) */
PROVIDE(__spl_end = .);
*(.init.text)
*(.exit.text)
*(.glue*)
*(.note.gnu.build-id)
PROVIDE(__text_end = .);
}
/* 其余内容省略... */
}
在SPL程序中start.S中主要做了以下操作:
// 进入SVC模式,此时中断控制器INTC并未初始化,需要先屏蔽中断响应FIQ和IRQ
// 不屏蔽也是可以的,大部分处理器上电后中断控制器默认关闭的,见下图一。
/* Enter svc mode and mask interrupts */
mrs r0, cpsr
bic r0, r0, #0x1f
orr r0, r0, #0xd3
msr cpsr, r0
// 由于当前页表(Translation Table)还未配置到cp15-C2寄存器
// 需要将MMU关闭,此时CPU发出的就是物理地址,直达硬件和内存
// 为了加速一些循环操作,例如将内核复制到DDR中的memcpy,可以开启ICACHE
mrc p15, 0, r0, c1, c0, 0
// M bit = 0, MMU disable:
bic r0, #0x1
// I bit = 1, enable icache
orr r0, #0x1000
mcr p15, 0, r0, c1, c0, 0
// 将中断向量表设置为低端地址
// 在ARM9中,中断向量表只能设置为高端地址0xFFFF0000或低端地址0x00000000
// 由于BROM占用了高端地址0xFFFF0000,因此0xFFFF0000是不可写的,
// 只能将用户中断向量表设置到低端地址0x00000000,见下图二,图三
// cortex-a就没有这个限制,将cp15-C1 bit13置1,再将中断表地址写入cp15-C12寄存器,
// 就可以任意指定中断向量表地址了。
/* Set vector to the low address */
mrc p15, 0, r0, c1, c0, 0
bic r0, #(1<<13)
mcr p15, 0, r0, c1, c0, 0
// 复制SPL程序的向量表到SRAM 0x0地址,
// 不复制也可以,因为大部分芯片BROM已经帮忙完成这项工作了,只要上一步设置好向量表位置即可。
/* Copy vector to the correct address */
adr r0, _vector
mrc p15, 0, r2, c1, c0, 0
ands r2, r2, #(1 << 13)
ldreq r1, =0x00000000
ldrne r1, =0xffff0000
// 关于这里为何要拷贝2次,复制64字节内容,我也不知道具体原因
// 我测试只复制中断向量表的32字节,偶尔会出现一些问题
ldmia r0!, {r2-r8, r10}
stmia r1!, {r2-r8, r10}
ldmia r0!, {r2-r8, r10}
stmia r1!, {r2-r8, r10}
// 这里主要工作是初始化系统时钟,和DDR
// 然后复制操作系统内核,到此SPL程序的任务就完成了
/* Initial system clock, ddr add uart */
bl sys_clock_init
bl sys_dram_init
bl sys_uart_init
bl sys_copyself
// 死循环,一般也不会到这里
b .



关于图四,第一条是指令是b reset,通常在BROM加载完SPL程序到SRAM后,最后会将PC指向SRAM的首地址ldr pc, 0x0,(这里的0x0代表SRAM首地址),也是SPL程序的第一条指令位置。
如果第一条指令是b reset,那么是基于PC寄存器的相对寻址,可以在±32MB程序空间内跳转,和代码的链接位置无关,即使链接脚本的起始地址填错,也是可以运行的(注意:只要汇编代码中有绝对地址跳转ldr pc, xxx或访问全局变量ldr r0, xxx,此时还是会出错的)。
如果第一条指令是ldr pc, reset,那么就是绝对地址跳转了,可以在4GB地址空间任意跳转,
考虑这样一种情况:程序加载地址是0x0,但链接地址被写成0x80000000,那么BROM加载完SPL程序并执行它的第一条指令,就会强制跳转到0x80000000这个没有程序的地址空间,导致启动失败。
当然这只是一种为了说明问题而提出的异常情况,实际中只要保证加载地址和链接地址一致,使用b指令和ldr指令没有区别,因为向量表其他位置还是使用的是ldr指令,一般而言SPL程序极少超过32MB(处理器内部SRAM也没这么大),向量表其他位置也可以使用b指令跳转。
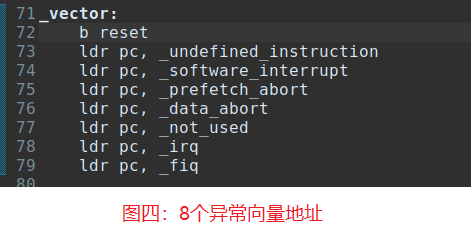
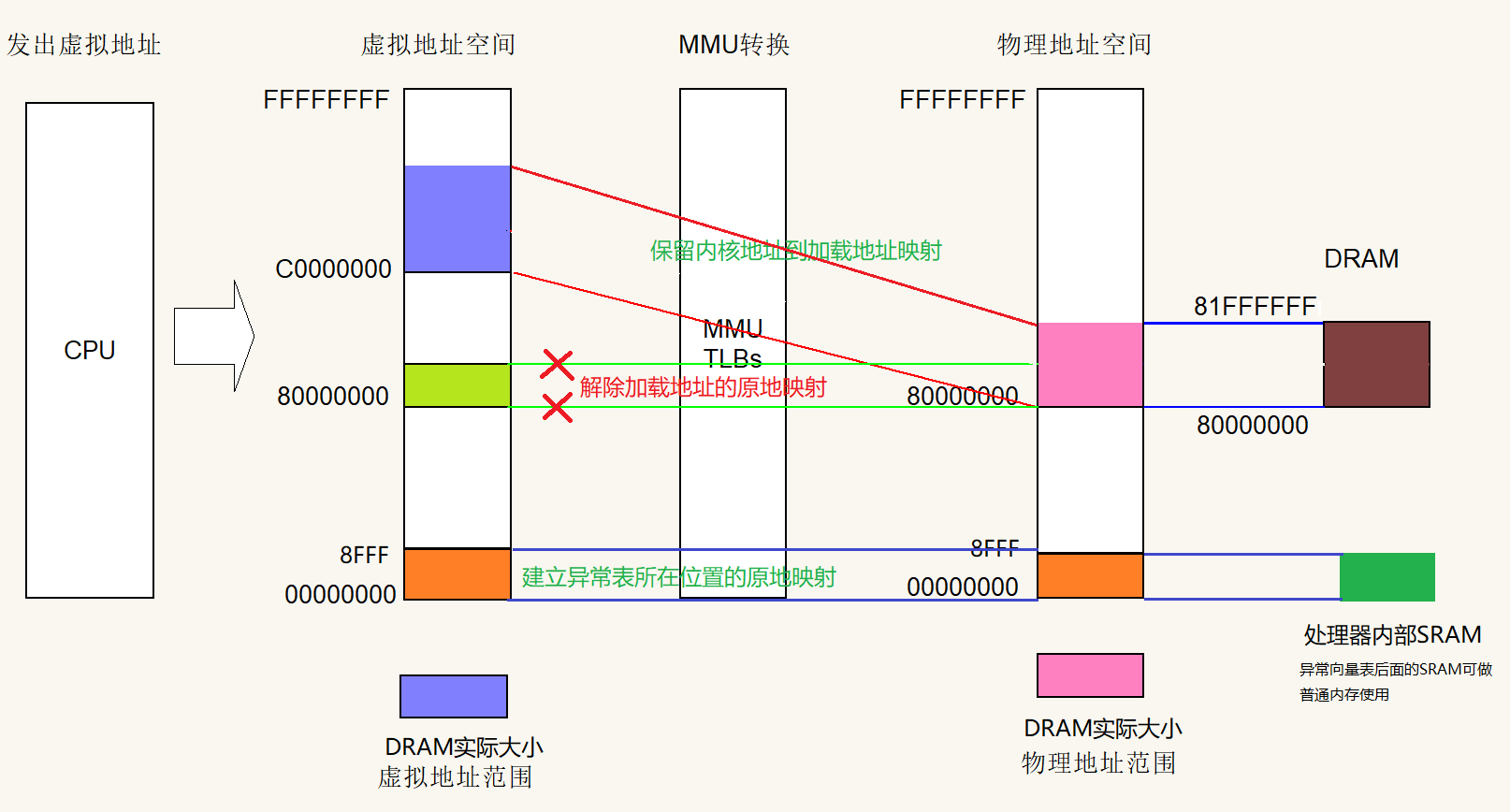
当内核加载到DRAM中,启动完成后,处理器内部SRAM中的SPL程序也就没有价值了,因此可以将处理器内部SRAM作为内存使用,但注意不能破坏前8个异常向量的位置,也就是前32字节保留。
操作系统工作后,可以在SRAM地址空间配置MMU,在SRAM地址范围建立一个原地映射,虚拟地址==物理地址,使用cache和writebuffer,当作一片高速RAM使用。
内核的开始
第一阶段目标
从start_gcc.S的reset程序开始,到rt-smart第一个c函数rtthread_startup为止
这里以:http://117.143.63.254:9012/www/rt-smart/ 网站下载的rt-smart-20210706.zip为蓝本进行移植和剪裁,工具链使用arm-linux-musleabi_for_x86_64-pc-linux-gnu_stable.tar.bz2
其中以下目录被替换成github:https://github.com/RT-Thread/rt-thread/tree/rt-smart rt-smart分支下的最新代码:
/rt-smart/kernel/components/lwp/
/rt-smart/kernel/src/
/rt-smart/kernel/include/
其它的文件则保持不变。
在rt-smart系统源码中,关于不同架构处理器相关代码在根目录的libcpu目录下
由于这里只需要适配F1C100S这一款CPU,所以可以将libcpu目录全部删除,删除后的目录结构如下图所示:
在bsp目录新建allwinner_tina文件夹,代表我们移植的F1C100S处理器。
下面将对allwinner_tina目录下重点需要关注的文件进行说明:
link_smart.lds
可以参考\rt-smart\kernel\bsp\imx6ull-artpi-smart\link_smart.lds和\rt-smart\kernel\bsp\raspberry-pi\raspi4-32\link.lds进行移植,由于内核地址空间是从0xc0000000开始,所以连接脚本的起始地址也要是内核地址空间起始地址。
SECTIONS
{
. = 0xc0000000;
这里推荐将启动相关的汇编文件生成的代码放在前面,这样在调试时确定断点地址比较容易找。
/* Startup code */
KEEP(*(.vectors))
build/libcpu/start_gcc.o(.text)
build/libcpu/mmu_gcc.o(.text)
build/libcpu/cp15_gcc.o(.text)
build/libcpu/context_gcc.o(.text)
*(.text)
*(.text.*)
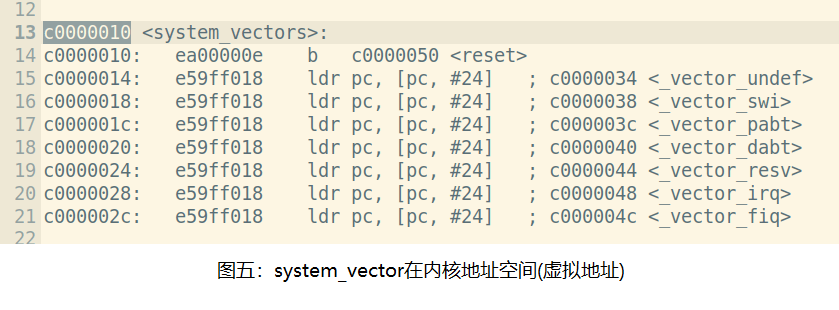
通过objdump反汇编,可以看到start_gcc的相关代码就在最终生成可执行文件的前面:
rtthread.elf: file format elf32-littlearm
Disassembly of section .text:
c0000000 <__image_start>:
c0000000: ea000002 b c0000010 <system_vectors>
c0000004: aa55aa55 bge c156a960 <__bss_end+0x151e788>
.......
c0000010 <system_vectors>:
c0000010: ea00000e b c0000050 <reset>
c0000014: e59ff018 ldr pc, [pc, #24] ; c0000034 <_vector_undef>
c0000018: e59ff018 ldr pc, [pc, #24] ; c0000038 <_vector_swi>
......
c0000030 <_vector_reset>:
c0000030: c0000050 andgt r0, r0, r0, asr r0
......
// 程序开始执行的位置
c0000050 <reset>:
c0000050: e10f0000 mrs r0, CPSR
c0000054: e3c0001f bic r0, r0, #31
c0000058: e38000d3 orr r0, r0, #211 ; 0xd3
c000005c: e12ff000 msr CPSR_fsxc, r0
.....
rtconfig.h
这里配置rt-smart的内核选项,挑一些重点的重点的讲解:
// 内核对象名字长度,内核对象名称在结构体里以数组形式固定分配,
// 填大小时最好考虑结构体对齐,建议取值为4的整数倍
#define RT_NAME_MAX 16
// 使用rt-smart特性
#define RT_USING_SMART
#define RT_CONFIG_MMU
#define RT_ALIGN_SIZE 4
// 支持的优先级设置为32个就能满足一般需求,rt-smart中数字小的优先级高
// 0:最高优先级,31最低优先级,且31被idle线程占用。
#define RT_THREAD_PRIORITY_32
#define RT_THREAD_PRIORITY_MAX 32
// 系统心跳的时间,单位ms
#define RT_TICK_PER_SECOND 1000
#define RT_USING_CACHE
#define RT_USING_USERSPACE
// 配置内核空间的起始地址,这里指的是虚拟地址
// DRR = 0x80000000, kernel = 0xc0000000
#define KERNEL_VADDR_START 0xc0000000
// 关于PV_OFFSET,由于rt-smart启动早期,根据虚拟地址计算实际的物理地址使用的是加法,
// 所以PV_OFFSET这个固定偏移量就是:物理地址-虚拟地址,这样代码中使用加法根据虚拟地址算物理地址时,
// 会造成上溢,只保留低32位,相当于绕了4GB地址空间一圈又回到了物理地址上。
//(当然也可以使用减法计算,只不过改动点就比较多了)
// pv offset = paddr - vaddr = 0x80000000 - 0xc0000000 = 0xc0000000
#define PV_OFFSET 0xc0000000

// 关于rtthread的设备驱动,最小内核移植只需要一个串口输出启动信息,其它的都可注释掉
/* Device Drivers */
#define RT_USING_DEVICE_IPC
#define RT_PIPE_BUFSZ 512
#define RT_USING_SYSTEM_WORKQUEUE
#define RT_SYSTEM_WORKQUEUE_STACKSIZE 2048
#define RT_SYSTEM_WORKQUEUE_PRIORITY 23
#define RT_USING_SERIAL
#define RT_SERIAL_RB_BUFSZ 512
//#define RT_USING_I2C
//#define RT_USING_PIN
//#define RT_USING_RTC
//#define RT_USING_SDIO
//#define RT_SDIO_STACK_SIZE 512
//#define RT_SDIO_THREAD_PRIORITY 15
//#define RT_MMCSD_STACK_SIZE 1024
//#define RT_MMCSD_THREAD_PREORITY 22
//#define RT_MMCSD_MAX_PARTITION 16
//#define RT_USING_SPI
// 网络接口相关的上层代码也可以先移除
/* Network interface device */
//#define RT_USING_NETDEV
//#define NETDEV_USING_IFCONFIG
//#define NETDEV_USING_PING
//#define NETDEV_USING_NETSTAT
//#define NETDEV_USING_AUTO_DEFAULT
//#define NETDEV_USING_IPV6
//#define NETDEV_IPV4 1
//#define NETDEV_IPV6 1
rtconfig.py
这里配置编译选项和参数,需要根据自己的CPU平台进行配置,例如arm内核型号,是否使用硬浮点以及一些编译选项。

SConstruct
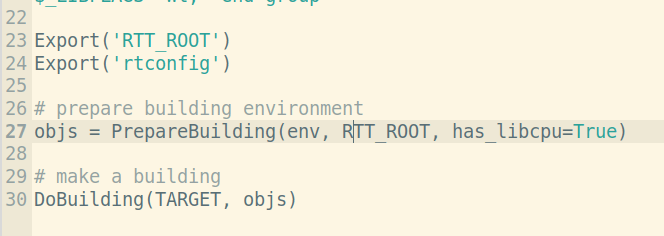
由于我们不使用rt-smart根目录下libcpu文件夹的处理器相关代码,而是把它放到了bsp/allwinner_tina/libcpu目录下,因此这里准备编译函数(PrepareBuilding)的第三个参数需要改成has_libcpu=True,编译脚本中PrepareBuilding的函数实现位于/rt-smart/kernel/tools/building.py,有需要的可以前去查阅。
libcpu/start_gcc.S
这里是rt-smart内核的入口,其中最重要的工作是对MMU的页表进行初始化。
这里的第一条汇编语句必须是b system_vectors基于PC的寻址跳转,因为内核的连接地址在0xC0000000,而生成的内核可执行文件被SPL程序加载到0x80000000的内存首地址,SPL程序加载完成内核可执行文件后,会将PC设置为0x80000000,如果第一条语句使用ldr pc, system_vectors,那么PC寄存器就等于0xC00000XX,CPU跳转到0xC00000XX处执行,但是0xC00000XX这个地址上是没有程序的(也可能超出物理内存范围),CPU会立即进入取指令异常。从下图五-内核可执行文件反汇编中可以看到system_vectors值是0xC0000010。
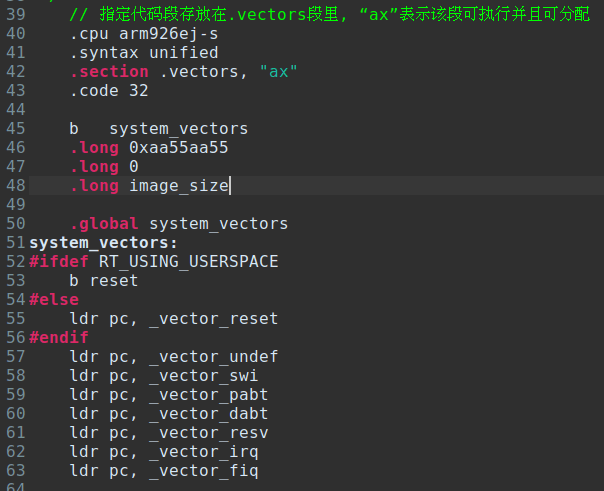
这些数据是给SPL程序识别合法的可执行文件和文件大小的,作用与文件头相同。
.long 0xaa55aa55
.long 0
.long image_size
这里RT_USING_USERSPACE表示使用rt-smart微内核,实际上这个宏应该常存在,可能现在rt-smart还处于早期阶段,没有完全从rtthread标准版分离出来。这里的跳转依然要使用相对跳转b reset,原因和上面一样。
#ifdef RT_USING_USERSPACE
b reset
#else
ldr pc, _vector_reset
#endif
data段除了给处理器各个异常模式分配栈空间,还需要分配一个临时页表的空间,给内核启动早期,建立虚拟地址和物理地址之间的映射关系使用。这里使用的是最简单的一级页表(First-level fetch),也就是段映射(section table),每个段描述符(section descriptor)占用4个字节(uint32_t),用以代表1MB虚拟地址和物理地址的映射关系,因此4GB地址空间需要4096*4=16KB的页表空间。
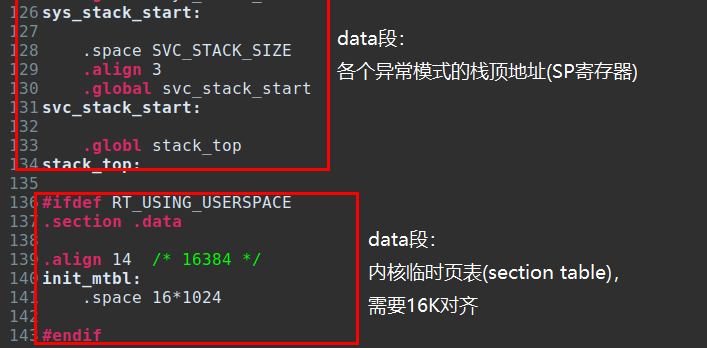
由于CP15-C2页表基地址寄存器只有[bit31-bit14]有效,[bit13-bit0]是被保留的(意思是用户不可用,也许ARM内核用了),因此页表地址需要16KB对齐。还有一点非常重要:页表基地址必须是物理地址。

这里是常见的初始化操作,切换到SVC模式屏蔽FIQ和IRQ中断,失效ICACHE和DCACHE,失效页表缓存(TLB)。
关闭MMU:大部分SPL程序编写者一般都不会开启MMU,即使开启了也只是建立原地映射VA == MVA == PA。由于CP15-C1寄存器控制了cache,writebuffer,处理器大小端模式等,这里最好再重新配置一次并关闭MMU。
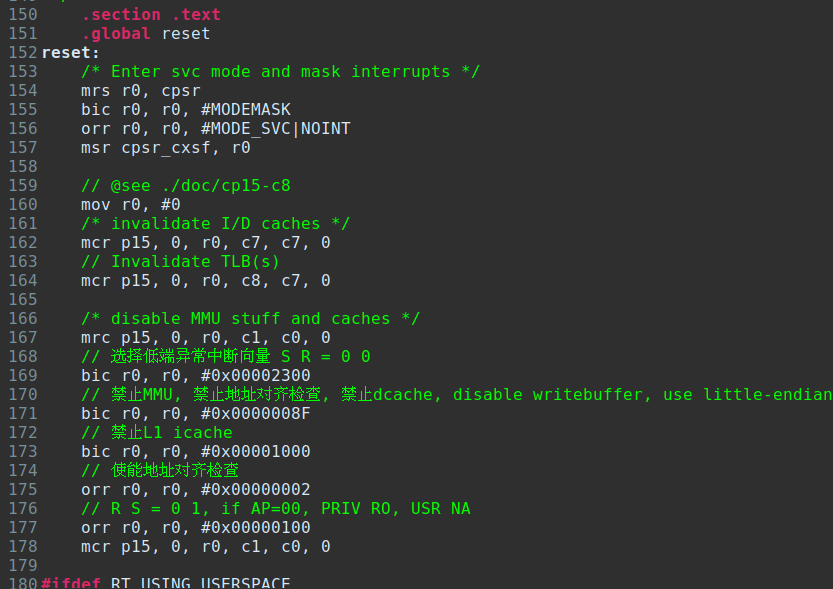
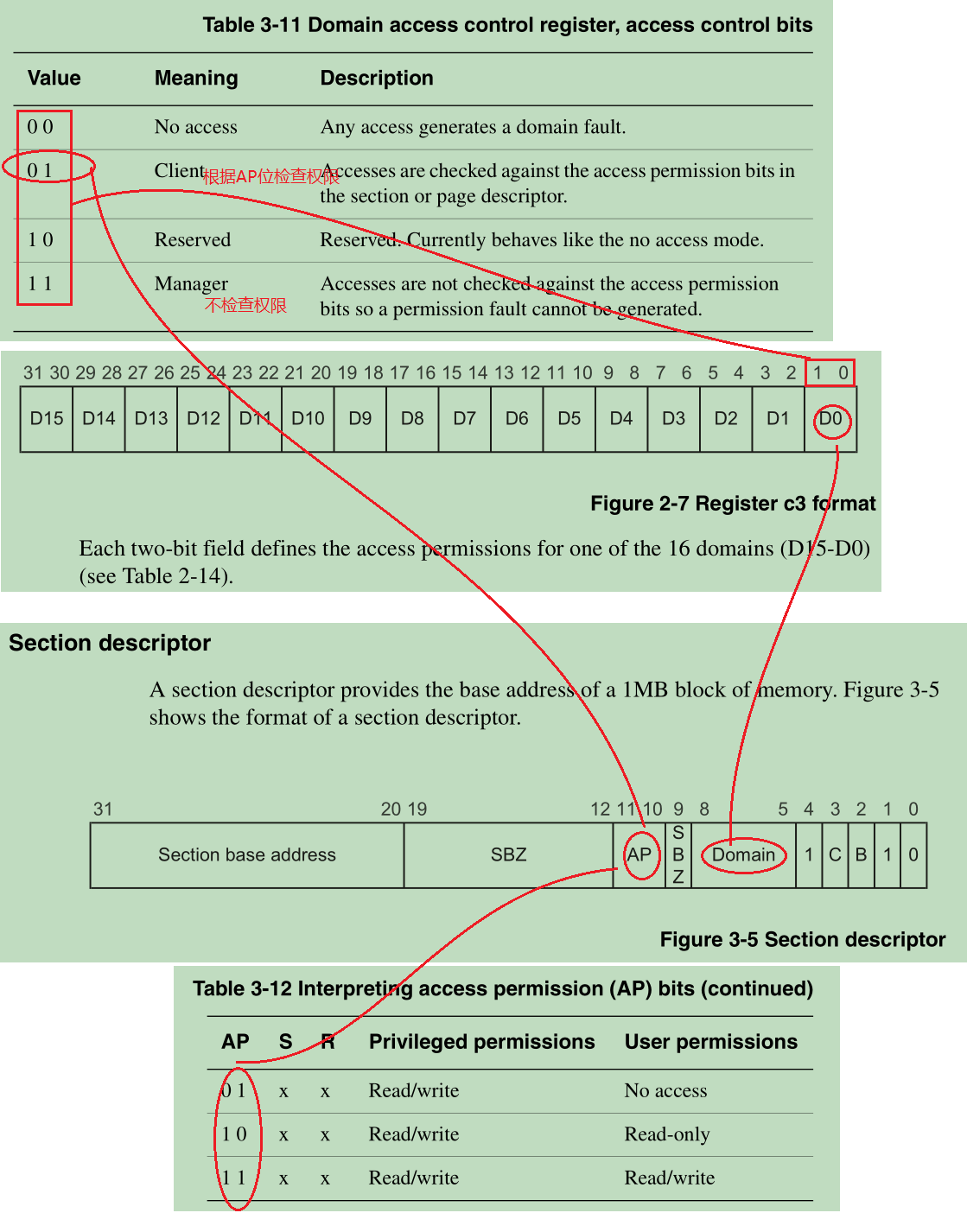
CP15-C1 [bit9~bit8] R位和S位决定了,页表的段描述符(section descriptor)的A位P位未配置(A=0,P=0)时的默认地址读写权限。AP和RS位的组合可以形成6种特权模式和用户模式对于特定地址段的读写权限配置。上面的汇编代码中,我配置R=0,S=1,那么默认的权限就是:特权模式只读,用户模式无权限。事实上我们在配置页表的段描述符(section descriptor)时,通常都需要配置AP的值,除非特意想让该段内存使用默认权限。


下面代码是建立一级页表前的准备工作:
#ifdef RT_USING_USERSPACE
//`PV_OFFSET`是内核`连接地址`和内核`加载地址`之间的偏移量,在上文rtconfig.h章节已详细介绍,这里将PV_OFFSET存入R5寄存器备用
ldr r5, =PV_OFFSET
// 这里生成了1024 * 1024 = 1M的掩码
mov r7, #0x100000
sub r7, #1 // r7:0x0FFFFF
// mvn表示按位取反后进行寄存器传送,这样r8就是一个1M地址空间的掩码
// 任何值和r8进行按位与操作都会丢失低20位,向下对齐到1M的整数倍
mvn r8, r7 /* r8: 0xfff00000 */
// r9: 0xc0000000,内核的起始地址
ldr r9, =KERNEL_VADDR_START
// 一个典型的程序结构如下:|.text|.rodata|.data|.stack|.bss|
// .data和.stack段可以合并,那么.bss段结束的地方就是内核的结束地址(此时还没有.heap段)
ldr r6, =__bss_end
// 内核的结束地址r6 + (对齐大小 - 1)r7
// 只要内核的结束地址r6 >= 1,加上r7后就 >= 对齐大小,完成了向上补齐的操作
// 下面在按位与上掩码,清除低端无效位,就完了整数对齐操作
add r6, r7
// 程序结束地址(r6)就向上对齐到了1M的整数倍
and r6, r8 /* r6 end vaddr align up to 1M */
// 展开形式:sub r6, r6, r9
// 所以内核的大小r6 = 内核的结束地址r6 - 内核的起始地址r9
sub r6, r9 /* r6 is size */
经过上面的一些计算,即使当前内核大小目前只有190KB,我们也认为内核大小占了1MB空间,因为接下来的页表配置是使用的一级页表(First-level fetch)其每个页表项(Section descriptor)所代表的是1MB的地址空间,下面将寄存器中计算所得参数列出:
| 寄存器 | 数据 | 备注 |
|---|---|---|
| r5 | PV_OFFSET | 虚拟地址+PV_OFFSET=物理地址 |
| r6 | 内核大小 | 向上对齐到1M整数倍 |
下面就准备开始建立内核临时页表,并在使能MMU后切换到虚拟地址空间执行。
/*
.space SVC_STACK_SIZE
.align 3
.global svc_stack_start
svc_stack_start:
.globl stack_top
stack_top:
*/
// 根据start_gcc.S在.data段的定义,stack_top也就是svc模式栈顶地址
// 这里stack_top是虚拟地址,此时MMU还未打开,加上r5(PV_OFFSET)转换成物理地址
// 设置sp的目的是为了下面进行c函数调用做准备
ldr sp, =stack_top
add sp, r5 /* use paddr */
// init_mtbl同样需要转换成物理地址
ldr r0, =init_mtbl
add r0, r5
mov r1, r6
mov r2, r5
// 跳转到C函数,设置页表项
bl init_mm_setup
根据ATPCS(ATM-Thumb指令调用标准),r0~r4存放函数调用的参数,顺序是从左到右,那么 mtbl = r0,size = r1 = r6,pv_off = r2 = r5。
这里和rt-smart提供的内核空间映射代码不同:对于内核地址和程序加载地址以外的其他地址空间,rt-smart官方版在表项中写入的是0x00也就是Fault类型,访问这些地址会产生异常;而我这里将这些虚拟地址与物理地址建立原地映射VA==PA,方便在启用MMU后还能初始化一些外设,拷贝中断向量表等。
#ifdef RT_USING_USERSPACE
void init_mm_setup(unsigned int *mtbl, unsigned int size, unsigned int pv_off) {
unsigned int va;
// 初始化了内存映射表,从 0 地址开始,以 1M 的粒度扫描整个 4G 地址空间,建立三关系:
for (va = 0; va < 0x1000; va++) {
unsigned int vaddr = (va << 20);
if ((vaddr >= KERNEL_VADDR_START) && (vaddr - KERNEL_VADDR_START < size)) {
// 虚拟地址处于内核地址空间,建立从内核地址空间到内核程序加载地址的映射
mtbl[va] = ((va << 20) + pv_off) | NORMAL_MEM;
} else if (vaddr >= (KERNEL_VADDR_START + pv_off) && (vaddr - (KERNEL_VADDR_START + pv_off) < size)) {
// vaddr >= 0x80000000 && vaddr < 0x80100000
// 虚拟地址在处于内核加载地址,建立原地址映射
mtbl[va] = (va << 20) | NORMAL_MEM;
} else {
// 其他地址配置成no cache, no writebuffer,并且原地址映射
// 便于开启MMU后关闭看门狗, INTC中断控制器等外设
// 注意需要保证外设寄存器地址不在内核地址空间
mtbl[va] = (va << 20) | DEVICE_MEM;
}
}
}
#endif
经过上面的一通操作,得到了如下的地址转换关系,虚拟地址和物理地址空白的区域我建立了原地映射。
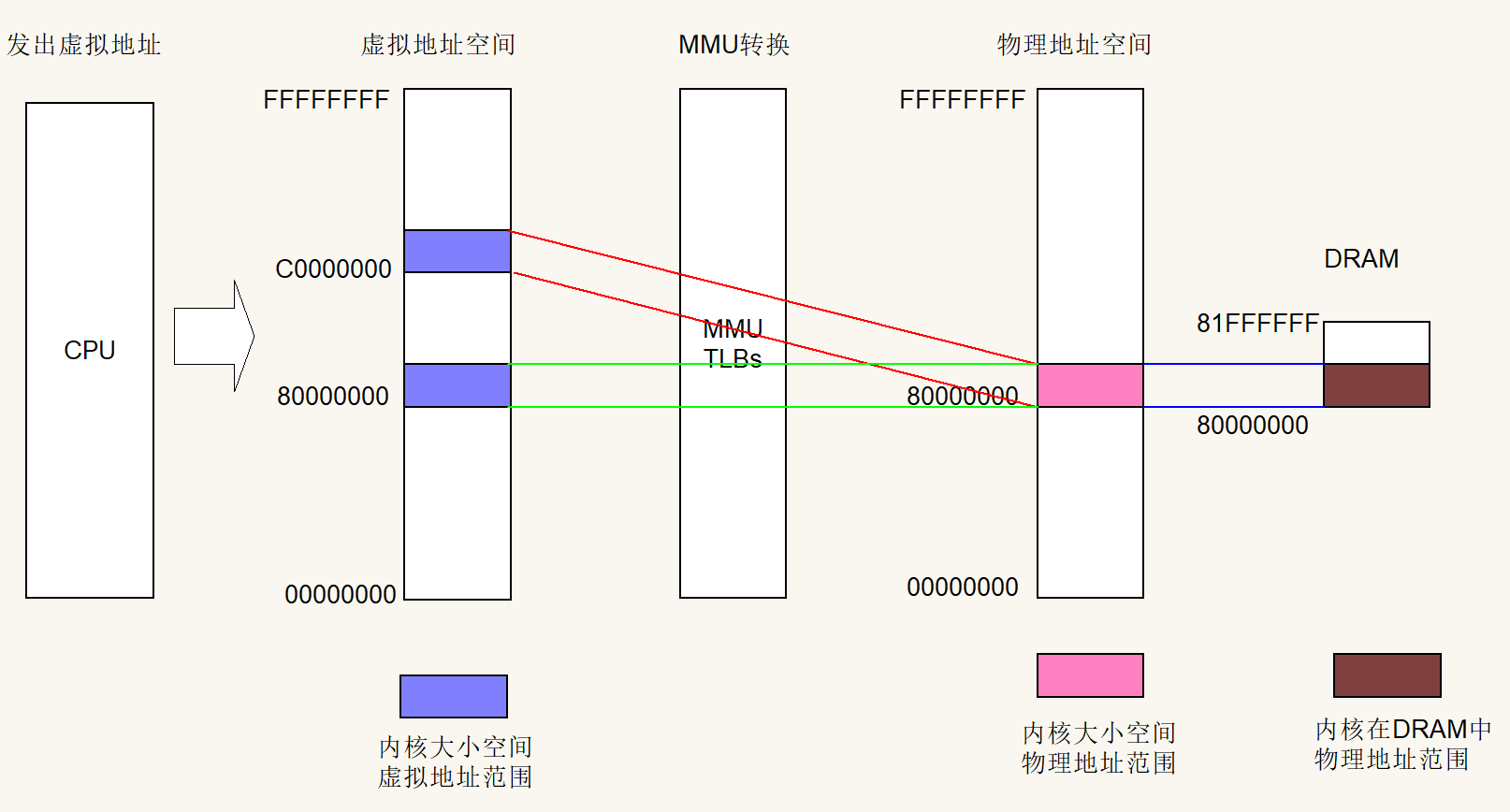
接下来就是使能MMU了,由于后面会将程序加载地址空间的原地映射解除,见上图绿色线区域,这里需要先将lr寄存器设置为虚拟地址的标签值,这里的enable_mmu使用的是b强制跳转指令,因此不会自动将下一条指令地址放入lr寄存器。那么enable_mmu子程序调用完成后,pc值就是内核地址空间(虚拟地址)。
// 这里先将返回地址切换到虚拟地址空间, enable_mmu后pc指向虚拟地址空间
ldr lr, =after_enable_mmu
ldr r0, =init_mtbl
add r0, r5
b enable_mmu
after_enable_mmu:
/* init stack */
bl stack_setup
子程序使能MMU,关于DOMAIN_CHECK,其值配置为0x55555555,CP15-C3寄存器定义了16个区域,每个区域有2bit,可以放不同的权限控制符,例如01进行权限检查,11不进行权限检查;需要配合一级页表的段描述符或二级页表的页描述符的AP位进行控制所映射地址空间的权限,其对应关系见下图。
.align 2
.global enable_mmu
enable_mmu:
mov r1, #0
mcr p15, 0, r1, c8, c7, 0 /* Invalidates all TLBs */
mcr p15, 0, r1, c7, c7, 0 /* invalidate icache & dcache */
// disable FCSE
mcr p15, 0, r1, c13, c0, 0
ldr r1, =DOMAIN_CHECK
/* 该内存区域的访问必须配合该内存区域的段描述符中AP位进行权检查 */
mcr p15, 0, r1, c3, c0, 0
// C2寄存器用来保存页表的基地址,即一级映射描述符表的基地址
// 页表基地址必须是物理地址,必须在16KB边界(16KB对齐)
mcr p15, 0, r0, c2, c0, 0
// 对于cp15-c1寄存器的操作可以全部合并到一起,分开是为了看的更清楚
/* mmu enable */
mrc p15, 0, r0, c1, c0, 0
orr r0, r0, #0x1
mcr p15, 0, r0, c1, c0, 0
/* enable icache */
mrc p15, 0, r0, c1, c0, 0
orr r0, r0, #(1<<12)
mcr p15, 0, r0, c1, c0, 0
/* enable dcache */
mrc p15, 0, r0, c1, c0, 0
orr r0, r0, #(1<<2)
mcr p15, 0, r0, c1, c0, 0
/* enable write buffer */
mrc p15, 0, r0, c1, c0, 0
orr r0, r0, #(1<<3)
mcr p15, 0, r0, c1, c0, 0
/* invalidate icache & dcache */
mov r1, #0
mcr p15, 0, r1, c8, c7, 0 /* Invalidates all TLBs */
mcr p15, 0, r1, c7, c7, 0 /* invalidate icache & dcache */
// 返回地址是内核地址空间
bx lr
enable_mmu后就是设置内核各个模式的的异常栈了(实际上就是各个异常模式SP寄存器的赋值),由于前面已经建立了加载地址到内核地址的映射,这里的栈顶地址是使用的内核地址空间(虚拟地址)。
stack_setup:
/* Setup Stack for each mode, 'sp' use virtual address */
mrs r0, cpsr
bic r0, r0, #MODEMASK
orr r1, r0, #MODE_UND|NOINT
msr cpsr_cxsf, r1
ldr sp, =und_stack_start
orr r1, r0, #MODE_ABT|NOINT
msr cpsr_cxsf, r1
ldr sp, =abt_stack_start
orr r1, r0, #MODE_IRQ|NOINT
msr cpsr_cxsf, r1
ldr sp, =irq_stack_start
orr r1, r0, #MODE_FIQ|NOINT
msr cpsr_cxsf, r1
ldr sp, =fiq_stack_start
orr r1, r0, #MODE_SYS|NOINT
msr cpsr_cxsf,r1
ldr sp, =sys_stack_start
orr r1, r0, #MODE_SVC|NOINT
msr cpsr_cxsf, r1
ldr sp, =svc_stack_start
bx lr
由于我在配置页表时,对加载地址和内核地址以外的区域建立了原地映射,因此我这里可以很方便的把一些外设初始化,其中最重要的是拷贝异常向量表,其它的初始化包括:关闭看门狗,关闭中断控制器,关闭GPIO等等;这些操作完成后,还需要对内核程序的.bss段进行清零操作。我们的内核临时页表是手动指定到.data段的,因此不受影响。
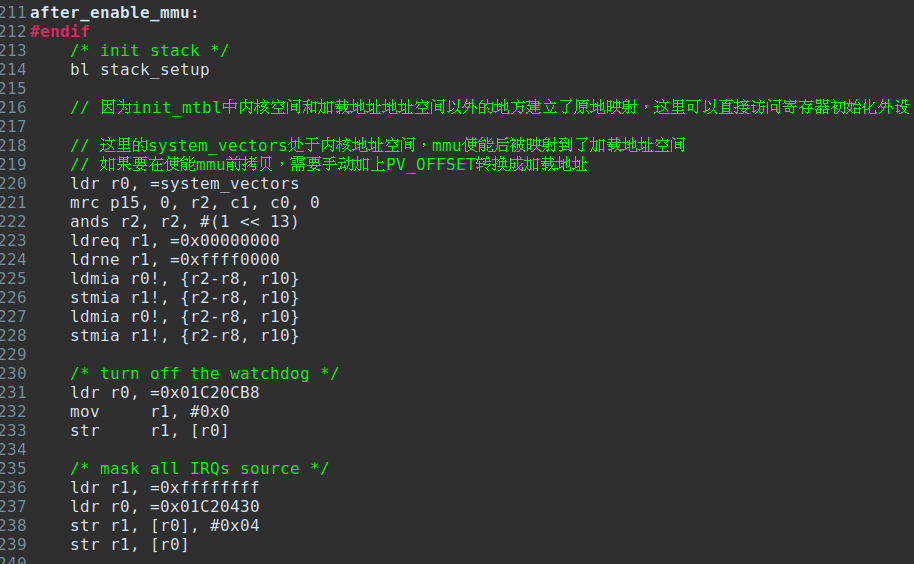
下面就是取消加载地址原地映射的操作了,只保留内核地址到加载地址的映射;因为加载地址(0x80000000)是留给用户态程序的,内核程序只占0xC0000000开始的地址空间。这里是通过重新分配内存(编译时固定分配)作为页表,配置页表并切换过去的方式实现的。
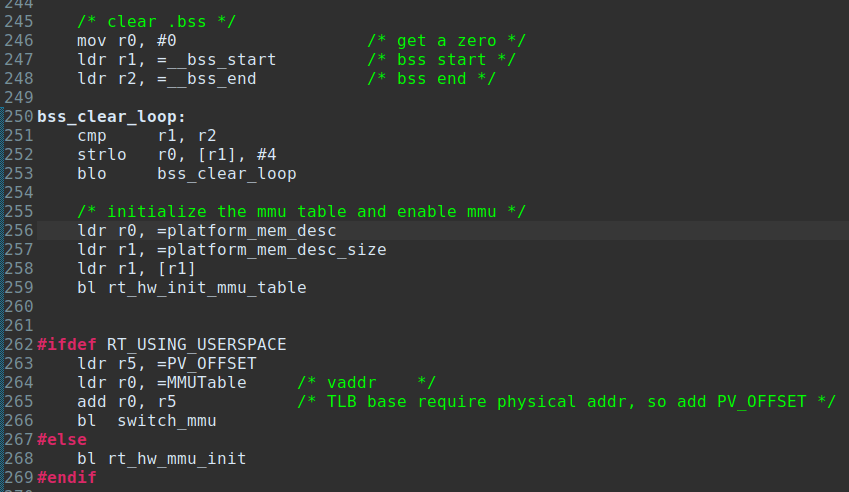
上图中的platform_mem_desc是虚拟地址和物理地址映射描述符,struct mem_desc是rt-smart自己定义的,因此和平台无关。
struct mem_desc
{
// 虚拟地址起始地址
rt_uint32_t vaddr_start;
// 虚拟地址结束地址,例如32MB的内存是vaddr_start + 1FFFFFF
rt_uint32_t vaddr_end;
// 物理地址起始地址
rt_uint32_t paddr_start;
// 页表项属性
rt_uint32_t attr;
};
这里在ARM9平台必须建立两段地址映射:
第一:内核虚拟地址0xC0000000到物理内存起始地址0x80000000的映射,映射的大小为物理内存的实际大小,这一点和cortex-a内核一致。
第二:必须建立中断向量表地址的原地映射,因为ARM9不像cortex-a的CPU可以将异常向量表随便设置(可指定到0xC0000000开始虚拟地址空间,实际还是存在于物理内存),只能在物理地址0x0地址和0xFFFF0000地址二选一,而F1C100S这款芯片0xFFFF0000被BOOTROM占用,是只读的无法修改,那么留给用户的只有0x0地址了。由于我们在前面将异常向量表拷贝到了处理器内部SRAM,所以建立0x0虚拟地址到内部SRAM0x0物理地址的原地映射。若不拷贝异常向量表到芯片内部SRAM,也可以将0x0虚拟地址映射到0xC0000000开始内核地址空间。如果缺少中断向量表地址的映射关系,系统时钟产生中断时,由于未指定虚拟地址0x0到物理地址的映射关系,CPU用虚拟地址跳转到FIQ异常地址时就会立刻陷入取指令异常。
异常向量表地址映射的Cache和WriteBuffer配置可以当普通内存对待:使用Cache,使用WriteBuffer。
#define F1C100S_DDR_SIZE 0x02000000
#define F1C100S_DDR_BASE 0x80000000
#define F1C100S_DDR_ADDR_MAX 0x01FFFFFF
#define F1C100S_SRAM_SIZE 0x9000
#define F1C100S_SRAM_BASE 0x0
#define F1C100S_SRAM_ADDR_MAX 0x8FFF
struct mem_desc platform_mem_desc[] = {
/* F1C100S DDR1 32M, 0 ~ (32M-1)*/
{KERNEL_VADDR_START, KERNEL_VADDR_START + F1C100S_DDR_ADDR_MAX, F1C100S_DDR_BASE, NORMAL_MEM},
// 异常向量表放在SRAM, 必须建立原地址映射, 用户态内存在0x100000后面
{F1C100S_SRAM_BASE, F1C100S_SRAM_BASE + F1C100S_SRAM_ADDR_MAX, F1C100S_SRAM_BASE, NORMAL_MEM}
};
#define RW_CB (AP_PRV_RW_USR_RW|DOMAIN0|CB|DESC_SEC) /* Read/Write, cache, write back */
/* normal memory mapping type */
#define NORMAL_MEM RW_CB
经过上面的配置,r0寄存器就是rt-smart定义的页表项描述符结构体数组地址,r1就是结构体数组的长度,这里r1 = 2,调用c函数rt_hw_init_mmu_table进行页表初始化。MMUTable就是内核正常运行时使用的页表了。由于我们配置内核临时页表时,内核地址到加载地址的页表项使用了Cache和WriteBuffer,这里修改内核地址空间的数据后,因为接下来会调用switch_mmu切换页表,我们想要对内存的更改立即生效,需要rt_hw_cpu_dcache_clean将Cache的数据强制刷新到主存。
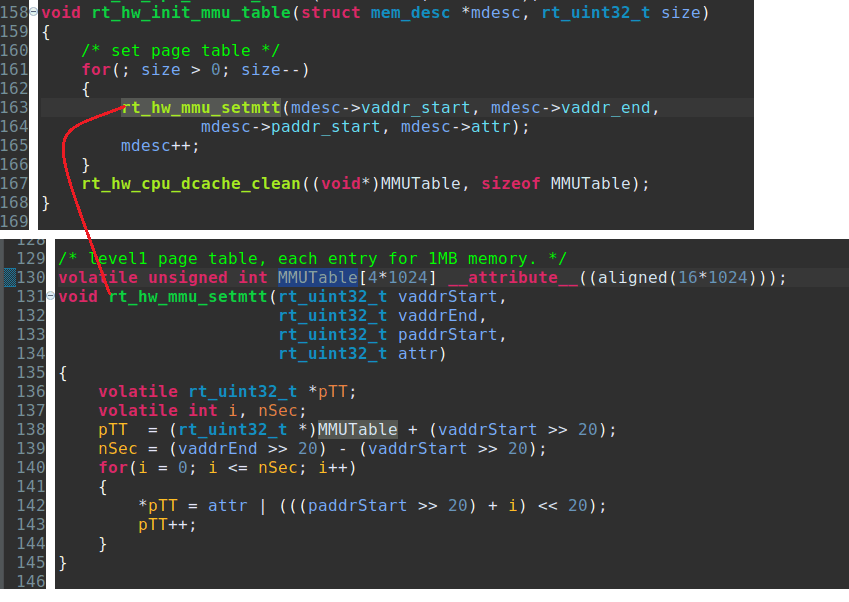
*pTT = attr | (((paddrStart >> 20) + i) << 20);就是配置下图所示的一级页表的表项描述符(Section descriptor)

最后,调用汇编子程序switch_mmu就实现了页表的切换工作。关于失效DCache数据项的操作,我参考了linux2.6内核对ARM9处理器切换页表的汇编代码,使用mrc p15, 0, r15, c7, c14, 3仅回写并清除被标记为脏页Dirty的数据项,而rt-smart原版代码是失效整个DCache。理论上性能差别不是很大,因为此时内核还未运行,DCache中并没有多少需要经常访问的影响性能的数据。
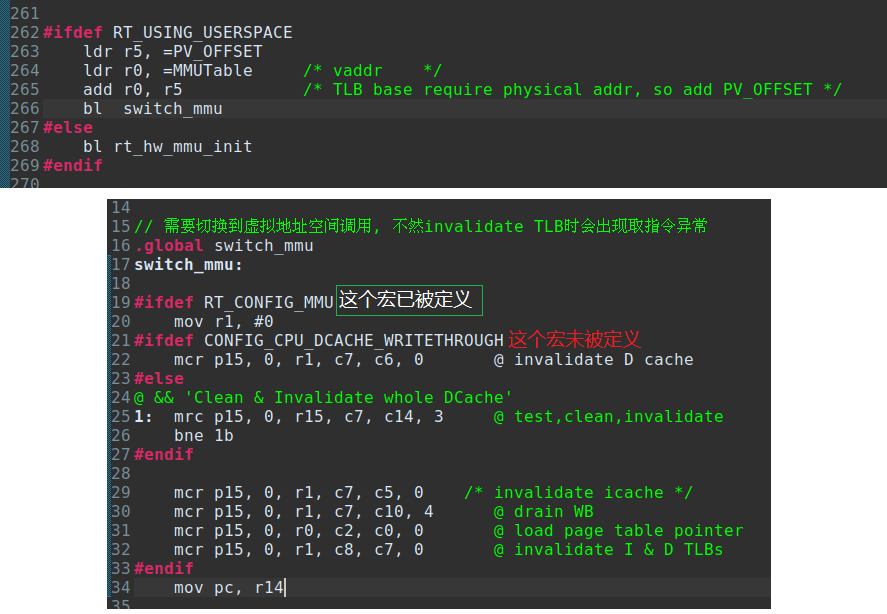
linux2.6内核在ARM9平台切换页表的汇编代码如下,供参考:
文件路径:\linux-2.6.32.27-master\arch\arm\mm\proc-arm926.S
/*
* cpu_arm926_switch_mm(pgd)
*
* Set the translation base pointer to be as described by pgd.
*
* pgd: new page tables
*/
.align 5
ENTRY(cpu_arm926_switch_mm)
#ifdef CONFIG_MMU
mov ip, #0
#ifdef CONFIG_CPU_DCACHE_WRITETHROUGH
mcr p15, 0, ip, c7, c6, 0 @ invalidate D cache
#else
@ && 'Clean & Invalidate whole DCache'
1: mrc p15, 0, r15, c7, c14, 3 @ test,clean,invalidate
bne 1b
#endif
mcr p15, 0, ip, c7, c5, 0 @ invalidate I cache
mcr p15, 0, ip, c7, c10, 4 @ drain WB
mcr p15, 0, r0, c2, c0, 0 @ load page table pointer
mcr p15, 0, ip, c8, c7, 0 @ invalidate I & D TLBs
#endif
mov pc, lr
switch_mmu后新的TLB转换表如下图,移除了加载地址原地映射;扩大了内核地址到加载地址映射范围为整个内存大小;新增了SRAM区域异常向量表映射。
随后调用C++的全局对象构造函数,实际上rt-smart内核代码没有C++的部分,会直接跳转到ctor_end标签处,由于F1C100S的中断控制器(INTC)已经关了,这里把FIQ和IRQ打开msr cpsr_c, #MODE_SVC也是安全的,最终调用rtthread_startup,这就是内核的入口,剩下的基本上都是C语言的世界了。
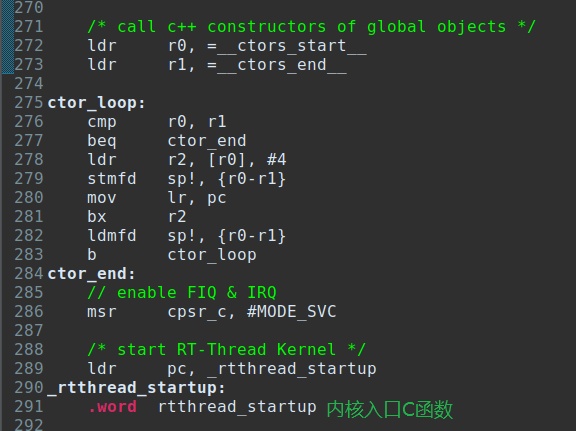
至此,我们第一阶段的目标:从第一行汇编开始到rt-smart入口C函数就已经完成了,能正常运行到rtthread_startup处,移植工作就已完成一半。

