
MySQL----实操篇
表内容操作:
1、增
insert into 表 (列名,列名...) values (值,值,值...) insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...) insert into 表 (列名,列名...) select (列名,列名...) from 表 INSERT INTO 表 VALUES (DEFAULT,"xsss",DEFAULT) //如果不填写字段,values后面的所有的字段都需要填写,不需要写的,可以填default SELECT LAST_INSERT_ID(); //返回主键
2、删
删除数据一般不使用下面的sql语句,我们使用假性删除,给每一行数据加上一个是否删除字段,删除的时候把这个字段变成0,查询的时候判断条件为1
delete from 表 #删除表中的所有的数据 delete from 表 where id=1 and name='alex' DELETE FROM tbuser WHERE id IN (12,13) DELETE FROM tbuser WHERE id BETWEEN 16 AND 20
3、改
UPDATE 表 set name = 'alex' where id>1 UPDATE employee SET dept = dept+1 WHERE id = 1; //对数据库中的dept字段自增1
4、查
select * from 表 select * from 表 where id > 1 select nid,name,gender as gg from 表 where id > 1 SELECT COUNT(*) FROM t_user WHERE username="yy"; //返回查询的数目 SELECT * FROM logininfo LIMIT 4,10; //第5行数据开始一个10条数据 limit 4,-1(最后一行),如果数据不够10条,直接返回实际的数目
4.1子查询
SELECT
*,
(SELECT
ordername
FROM
u_order
WHERE t_user.`order_id` = u_order.`id`) AS ordername //根据t_user.order_id 来关联查询的
FROM
t_user ;
5、其他
a、条件
select * from 表 where id > 1 and name != 'alex' and num = 12;
select * from 表 where id between 5 and 16;
select * from 表 where id in (11,22,33)
select * from 表 where id not in (11,22,33)
select * from 表 where id in (select nid from 表)
b、通配符
select * from 表 where name like 'ale%' - ale开头的所有(多个字符串)
select * from 表 where name like 'ale_' - ale开头的所有(一个字符)
c、限制
select * from 表 limit 5; - 前5行
select * from 表 limit 0,5 - 钱5行(从第0行开始),和limit 5 一样
select * from 表 limit 4,5; - 从第4行开始的5行
select * from 表 limit 5 offset 4 - 从第4行开始的5行
d、排序
select * from 表 order by 列 asc - 根据 “列” 从小到大排列
select * from 表 order by 列 desc - 根据 “列” 从大到小排列
select * from 表 order by 列1 desc,列2 asc - 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序
ORDER BY colum asc IF(ISNULL(colum),0,1) //null被强制放在最前,不为null的按声明顺序[asc|desc]进行排序
ORDER BY colum asc IF(ISNULL(colum),1,0) //null被强制放在最后,不为null的按声明顺序[asc|desc]进行排序
e、分组
select num from 表 group by num
select num,nid from 表 group by num,nid
select num,nid from 表 where nid > 10 group by num,nid order nid desc
select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid
select num from 表 group by num having max(id) > 10
特别的:group by 必须在where之后,order by之前
f、连表
无对应关系则不显示
select A.num, A.name, B.name
from A,B
Where A.nid = B.nid
无对应关系则不显示
select A.num, A.name, B.name
from A inner join B
on A.nid = B.nid
A表所有显示,如果B中无对应关系,则值为null
select A.num, A.name, B.name
from A left join B
on A.nid = B.nid
B表所有显示,如果B中无对应关系,则值为null
select A.num, A.name, B.name
from A right join B
on A.nid = B.nid
g、组合
组合,自动处理重合
select nickname
from A
union
select name
from B
组合,不处理重合
select nickname
from A
union all
select name
from B
示例
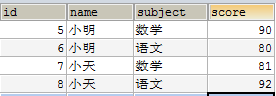
计算每一个同学的总成绩从大到小排名(显示字段有name,总成绩)
不加DESC,默认从小到大排序(ASC)
SELECT NAME,SUM(score) AS t FROM u GROUP BY NAME ORDER BY t DESC
计算每一个同学的最高成绩(显示字段有name,总成绩)
SELECT NAME,MAX(score) AS t FROM u GROUP BY NAME
示例
需求,A表关联了B表,如果给A表插入数据
就按照正常的逻辑插入数据,但是如果插入的id在B表中找不到,就会报错
INSERT INTO employee(NAME,dept) VALUE("小明",1); //1是B表的id
示例
关联表的问题,如果from表的时候取了别名,后面只能使用 别名.id
SELECT * FROM realauth AS r LEFT JOIN logininfo ON r.`applier_id` = logininfo.`id`
示例
一张表关联多张表
SELECT r.id,ap.id AS ap_id,ap.username,au.id AS au_id,au.username FROM realauth AS r LEFT JOIN logininfo AS ap ON r.`applier_id` = ap.`id` LEFT JOIN logininfo AS au ON r.`auditor_id` = au.`id`
示例
查出字段不为空和为空的数据
SELECT * FROM userfile WHERE fileType_id IS NOT NULL; SELECT * FROM userfile WHERE fileType_id IS NULL;
示例
<select id="getClientSchedules" resultMap="CourseScheduleMap">
SELECT cs.id as scheduleId,ci.courseName,tch.userName teacherName,sv.venueName,sc.campusName,
cs.weekTimes,cs.beginTimes,cs.endTimes,cs.rebuildLim,cs.genderLim,cs.totalLim,cs.lastLim,
cs.totalCount,cs.maleScale,cs.maleCount,cs.femaleScale,cs.femaleCount,stime.`shortName` beginTimesShortName,etime.`shortName` endTimesShortName
FROM (select * from course_schedule where status = 1 and schoolId = #{schoolId}
<if test="courseId != null">
and courseId = #{courseId}
</if>
<if test="teacherId != null">
and teacherId = #{teacherId}
</if>
<if test="beginTimes != null">
and beginTimes = #{beginTimes}
</if>
<if test="endTimes != null">
and endTimes = #{endTimes}
</if>
<if test="weekTimes != null">
and weekTimes = #{weekTimes}
</if>
<if test="rebuildLim != null and rebuildLim==2">
and (rebuildLim = 0 or rebuildLim = 2)
</if>
<if test="rebuildLim != null and rebuildLim==1">
and (rebuildLim =0 or rebuildLim = 1)
</if>
) cs
LEFT JOIN user_info tch ON cs.teacherId= tch.id
LEFT JOIN course_info ci ON cs.courseId=ci.id
LEFT JOIN school_venue sv ON cs.venueId = sv.id
LEFT JOIN school_campus sc ON sv.campusId = sc.id
LEFT JOIN school_year sy ON cs.yearId = sy.id
LEFT JOIN school_times_info stime ON stime.`times` = cs.`beginTimes` and stime.status=1 and cs.schoolId= stime.schoolId
LEFT JOIN school_times_info etime ON etime.`times` = cs.`endTimes` and etime.status=1 and cs.schoolId= etime.schoolId
LEFT JOIN course_schedule_depart dep ON cs.id= dep.scheduleId
LEFT JOIN course_schedule_major maj ON cs.id= maj.scheduleId
LEFT JOIN (select * from user_info where id = #{stuId}) stu ON cs.schoolId= stu.schoolId
LEFT JOIN school_class scl ON stu.classId= scl.id and scl.status=1
LEFT JOIN course_class_selection ccs ON ccs.classId = stu.classId
where sy.isThisYear=1 and (dep.departId is null or dep.departId=stu.departmentId)
and (maj.majorId is null or maj.majorId=stu.majorId)
and (ccs.id is null or (cs.weekTimes=ccs.weekTimes and cs.beginTimes>=ccs.beginTimes and ccs.endTimes>=cs.endTimes))
and ((stu.userSex=0 and genderLim!=1) or (stu.userSex=1 and genderLim!=2))
</select>
获取数据库中时间的后几天
语法结构
DATE_SUB(date,INTERVAL expr type)
DATE_ADD(date,INTERVAL expr type)
select * from table where date_sub('2019-04-03',INTERVAL 1 year);
SELECT DATE_ADD(weekBegin,INTERVAL 1 DAY) FROM school_week WHERE WEEK>=1 AND WEEK<=4 AND yearId=22 SELECT DATE_SUB(weekBegin,INTERVAL -1 DAY) FROM school_week WHERE WEEK>=1 AND WEEK<=4 AND yearId=22
比较时间(更多参考:https://www.cnblogs.com/Darkqueen/p/9264087.html)
https://blog.csdn.net/qq_23375733/article/details/88533006
select
*
from attend_record
where status = 1 and schoolId=#{schoolId} and stuId = #{stuId} and unix_timestamp(#{signInTime})> unix_timestamp(signInTime)
查询重复数据
1.having只能用在group by之后,对分组后的结果进行筛选(即使用having的前提条件是分组)。
select Email from Person group by Email having count(Email) > 1
查询id最大的一条数据
select * from table where id=(select MAX(id) from table where xx) SELECT * FROM 表名 ORDER BY id DESC LIMIT 0,1
分数排名
题目:letcode算法(https://leetcode-cn.com/problems/rank-scores/)
下面这个应该只能支持mysql8.x
SELECT Score, dense_rank() over(order by Score desc) as 'Rank' FROM Scores
方式2
select a.score as Score, count(DISTINCT b.score) AS Rank # 统计b表符合条件的不重复的分数的数量作为排名 FROM scores a join scores b where b.score >= a.score # 条件是这个分数不小于我,因为a、b表数据相同,所以排名值最小是1 group by a.id # a表中每个数据都进行排名 order by a.score DESC # 最后按分数(跟排名一样)降序排列
获取薪水表中第二高的薪水
题目:letcode算法(https://leetcode-cn.com/problems/second-highest-salary/comments/)
思路1:从大到小排序,取第二
#方式1 select distinct salary from Employee order by salary desc limit 1,1 #优化[如果不存在结果,返回null] select (select distinct salary from Employee order by salary desc limit 1,1) as SecondHighestSalary
思路2:不是最大数的最大数
SELECT max(Salary) SecondHighestSalary FROM Employee where Salary != (select max(Salary) from Employee );
换座位
题目:https://leetcode-cn.com/problems/exchange-seats/
思路:直接调换id,然后再进行排序【直接对查询出来的ID进行加减操作,变换ID的顺序】
SELECT (CASE
WHEN MOD(id,2) = 1 AND id = (SELECT COUNT(*) FROM seat) THEN id
WHEN MOD(id,2) = 1 THEN id+1
ElSE id-1
END) AS id, student
FROM seat
ORDER BY id;
查询一张表中状态0的数量和状态1的数量
select DJZT,count(1) as num from XM_ZLWT_JCJLMX group by DJZT;
树形结构表的查询
使用sql语句,构建树
缺点,无法构建不确定层级的树
<mapper namespace="com.aepcmis.ht.jc.mapper.BkdyMapper">
<resultMap id="BaseResultMap" type="com.aepcmis.common.entity.Tree">
<id column="BKDY_PKID" jdbcType="VARCHAR" property="id"/>
<result column="BKDY_PPKID" jdbcType="VARCHAR" property="pid"/>
<result column="BKMC" jdbcType="VARCHAR" property="text"/>
<collection property="children" ofType="com.aepcmis.common.entity.Tree">
<id column="BKDY_PKID2" jdbcType="VARCHAR" property="id"/>
<result column="BKDY_PPKID2" jdbcType="VARCHAR" property="pid"/>
<result column="BKMC2" jdbcType="VARCHAR" property="text"/>
</collection>
</resultMap>
<select id="queryTree" resultMap="BaseResultMap">
SELECT
b1.BKDY_PKID,
b1.BKDY_PPKID,
b1.BKMC,
b2.BKDY_PKID as BKDY_PKID2,
b2.BKDY_PPKID as BKDY_PPKID2,
b2.BKMC as BKMC2
FROM
HT_JC_BKDY b1 left join HT_JC_BKDY b2 on b1.BKDY_PKID = b2.BKDY_PPKID
WHERE B1.BKDY_PPKID is null
</select>
</mapper>
将list查询出来递归构建树
public List<TreeNode> transDepartment(List<Qydy> rootList){
List<TreeNode> nodeList = new ArrayList<>();
for (Qydy qydy : rootList) {
TreeNode treeNode = new TreeNode();
treeNode.setId(qydy.getQYDY_PKID());
treeNode.setText(qydy.getQYMC());
treeNode.setAttributes(qydy);
//表明是一级父类
if (1==qydy.getCJ()){
// treeNode.setState("open");
nodeList.add(treeNode);
}
treeNode.setChildren(setChild(treeNode.getId(),rootList));
}
return nodeList;
}
public List<TreeNode> setChild(String id, List<Qydy> list ){
List<TreeNode> childList = new ArrayList<>();
for (Qydy qydy : list) {
TreeNode treeNode = new TreeNode();
if (id!=null && id.equals(qydy.getQYDY_PPKID())){
treeNode.setId(qydy.getQYDY_PKID());
treeNode.setText(qydy.getQYMC());
treeNode.setParentId(id);
treeNode.setState("close");
treeNode.setAttributes(qydy);
childList.add(treeNode);
}
}
for (TreeNode department : childList) {
List<TreeNode> treeNodes = setChild(department.getId(), list);
if (treeNodes.size()>=1){
department.setState("close");
}
department.setChildren(treeNodes);
}
return childList;
}
删除树
@Override
public void DelByPid(List<String> objects) {
//1 创建list集合,用于封装所有删除菜单id值
List<String> idList = new ArrayList<>();
//2 向idList集合设置删除菜单id
for (String id:objects){
//把当前id封装到list里面
idList.add(id);
this.selectPermissionChildById(id,idList);
}
qydyMapper.deleteBatchIds(idList);
}
private void selectPermissionChildById(String id, List<String> idList) {
//查询菜单里面子菜单id
QueryWrapper<Qydy> wrapper = new QueryWrapper<>();
wrapper.eq("QYDY_PPKID",id);
wrapper.select("QYDY_PKID");
List<Qydy> childIdList = qydyMapper.selectList(wrapper);
//把childIdList里面菜单id值获取出来,封装idList里面,做递归查询
childIdList.stream().forEach(item -> {
//封装idList里面
idList.add(item.getQYDY_PKID());
//递归查询
this.selectPermissionChildById(item.getQYDY_PKID(),idList);
});
}
统计各班级男女生人数
select banji,count(1) 班级人数,sum(case when xingbie='1' then 1 else 0 end ) 男生人数,sum(case when xingbie='2' then 1 else 0 end ) 女生人数 from biyelunwen_xuesheng group by banji

