
Elasticsearch----增删改查
一、集群信息查看
GET /_cluster/health GET _cat/health?v 查看集群健康状况,status="green":表示每个索引的primary shard和replica shard都是active状态的 ="yellow": 表示每个索引的primary shard是active,但是部分replica shard都是不是active状态的 ="red":表示不是所有索引的primary shard是active,部分索引有数据丢失。 GET _cat/indices?v 快速查看集群中索引的情况 PUT /index_test?pretty 新建索引 index_test:测试的索引名 DELETE /index_test 删除index_test索引
二、使用
1、创建索引库(用于集群时候的设置)
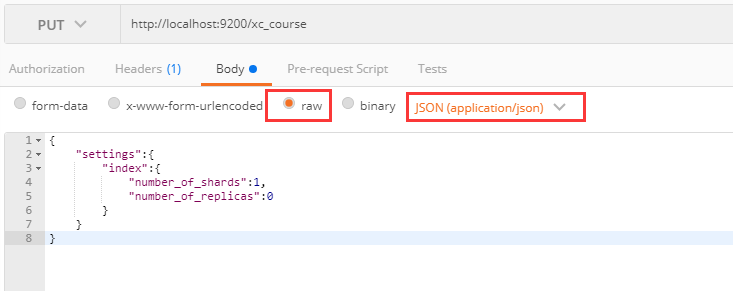
put http://localhost:9200/xc_course //索引库名称
{
"settings":{
"index":{
"number_of_shards":1,
"number_of_replicas":0
}
}
}
- number_of_shards:设置分片的数量,在集群中通常设置多个分片,表示一个索引库将拆分成多片分别存储不同 的结点,提高了ES的处理能力和高可用性,入门程序使用单机环境,这里设置为1。
- number_of_replicas:设置副本的数量,设置副本是为了提高ES的高可靠性,单机环境设置为0.
2、创建映射(创建映射之前需要设置索引库)
我们直接把type写成doc:没有特殊含义
post http://localhost:9200/xc_course/doc/_mapping
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}
获取映射
get http://localhost:9200/xc_course/doc/_mapping
更新映射:不能修改原有字段的type(Mysql是可以修改字段类型的),不会将原有的字段删除,只会添加新的字段。比如下面添加了name,如果原来映射中有name,就不会重复添加了,如果真的需要修改字段的type,只能将索引库删除,重新创建;
post http://localhost:9200/xc_course/doc/_mapping
{
"properties": {
"name": {
"type": "text"
}
}
}
text字段
- 给字段设置分词器,索引和搜索都使用ik_max_word
- get http://localhost:9200/xc_course/doc/_search?q=name:开发,此时搜索的name后面的搜索条件也会被分词
"name": {
"type": "text",
"analyzer":"ik_max_word"
}
- 索引ik_max_word,搜索使用ik_smart,建议使用我们希望文章被拆的越细越好,然后添加到索引库,而搜索的词我们并不希望拆的非常细(更希望精确查找),这样会造成搜索到非常多的无用信息
"name": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
}
- 指定字段是否索引,是否该字段可以被检索到
"pic": {
"type": "text",
"index":false //默认是true
}
- 是否在source之外存储,一般情况我们不需要设置store为true,因为_source中已经有一份原始数据了
"name": {
"type": "text",
"store":false //默认false
}
keyword关键字字段
- keyword字段为关键字字段,通常搜索keyword是按照整体搜索,所以创建keyword字段的索引时是不进行分词的,比如:邮政编码、手机号码、身份证等。keyword字段通常用于过虑、排序、聚合等。
"phone": {
"type": "keyword",
}
date类型
- 插入数据的时候,就可以是两种格式的数据了
"timestamp": {
"type": "date",
"format": "yyyy‐MM‐dd HH:mm:ss||yyyy‐MM‐dd"
}
数值类型
- ES支持 long,integer,short,byte,double,float,half_float,scaled_float
- 1、尽量选择范围小的类型,提高搜索效率
- 2、对于浮点数尽量用比例因子,比如一个价格字段,单位为元,我们将比例因子设置为100这在ES中会按 分 存 储,映射如下:
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
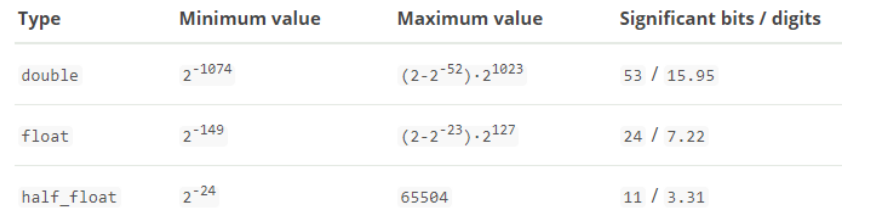
3、创建文档/创建索引(创建文档会直接生成默认配置的索引库和映射)
- 修改文档方式同下:原理,先删除,在update,类似于非关系型数据库中更新,我们也可以只update某一个字段(后面)
- put 或Post http://localhost:9200/xc_course/doc/id值(如果不指定id值ES会自动生成ID)
- 文档相当数据库中的一行数据
创建文档
post http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
{
"name":"Bootstrap开发框架",
"description":"Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。",
"studymodel":"201001"
}
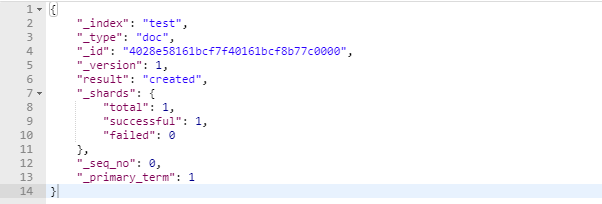
- took:本次操作花费的时间,单位为毫秒。
- timed_out:请求是否超时
- _shards:说明本次操作共搜索了哪些分片(total和successful默认是5,我们之前设置的是1)
- hits:搜索命中的记录
- hits.total : 符合条件的文档总数 hits.hits :匹配度较高的前N个文档
- hits.max_score:文档匹配得分,这里为最高分
- _score:每个文档都有一个匹配度得分,按照降序排列。
- _source:显示了文档的原始内容。
创建文档
- 如果id存在,则不创建(会抛一个错误)
PUT /test/test1/3/_create
{
"name":"newzy"
}
更新文档(全量替换)
PUT http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
{
"name":"newzy"
}
更新文档(局部替换)
post http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000/_update
{
"doc":{
"name":"Bootstrap"
}
}
4、搜索文档
根据id
get http://localhost:9200/xc_course/doc/4028e58161bcf7f40161bcf8b77c0000
搜索全部
get http://localhost:9200/xc_course/doc/_search
根据关键词查询
get http://localhost:9200/xc_course/doc/_search?q=name:开发
- 补充
-
补充:关于q=2是如果检索出来的,es中的,_a11元数据,在建立索引的时候,我们插入一条document,它里面包含了多个field,此时,es会自动将多个field的值,全部用字符串的方式串联起来,变成一个长的字符串,作为_a11 field的值,同时建立索引。后面如果在搜索的时候,没有对某个field指定搜索,就默认搜索_ a11 field,其中是包含了所有field的值的,举个例子,{"name":"jack","address":"xxx"},"jack xxx",作为这一条document的_a11 field的值,同时进行分词后建立对应的倒排索引。
GET /index*/_search?q=-name:xx //表示name字段中不是xx,检索出来 GET /index*/_search?q=+name:xx //和q=name:xx效果一样。表示name字段是xx的,检索出来 GET /index*/_search?q=2 //表示不管是什么field,只有value为2,就检索出来
DSL查询(POST提交)
- 搜索全部,source源过虑设置,指定结果中所包括的字段有哪些。
post http://localhost:9200/xc_course/doc/_search
{
"query":{
"match_all": {}
},
"_source": ["name","studymodel"]
}


@Test public void testSearchAll() throws IOException, ParseException { //搜索请求对象 SearchRequest searchRequest = new SearchRequest("xc_course"); //指定类型 searchRequest.types("doc"); //搜索源构建对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //搜索方式 //matchAllQuery搜索全部 searchSourceBuilder.query(QueryBuilders.matchAllQuery()); //设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{}); //向搜索请求对象中设置搜索源 searchRequest.source(searchSourceBuilder); //执行搜索,向ES发起http请求 SearchResponse searchResponse = client.search(searchRequest); //搜索结果 SearchHits hits = searchResponse.getHits(); //匹配到的总记录数 long totalHits = hits.getTotalHits(); //得到匹配度高的文档 SearchHit[] searchHits = hits.getHits(); for(SearchHit hit:searchHits){ //文档的主键 String id = hit.getId(); //源文档内容 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = (String) sourceAsMap.get("name"); //由于前边设置了源文档字段过虑,这时description是取不到的 String description = (String) sourceAsMap.get("description"); //学习模式 String studymodel = (String) sourceAsMap.get("studymodel"); //价格 Double price = (Double) sourceAsMap.get("price"); //日期 注意 yyyy‐MM‐dd HH:mm:ss里面的"-" SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss"); String str = (String) sourceAsMap.get("timestamp"); Date timestamp = dateFormat.parse(str); System.out.println(timestamp); System.out.println(name); System.out.println(studymodel); System.out.println(description); } }
- 分页查询,from:下标,size,查多少条数据
{
"from" : 1, "size" : 1,
"query": {
"match_all": {}
}
}
//分页查询 @Test public void testSearchPage() throws IOException, ParseException { //搜索请求对象 SearchRequest searchRequest = new SearchRequest("xc_course"); //指定类型 searchRequest.types("doc"); //搜索源构建对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //设置分页参数 //页码 int page = 1; //每页记录数 int size = 1; //计算出记录起始下标 int from = (page-1)*size; searchSourceBuilder.from(from);//起始记录下标,从0开始 searchSourceBuilder.size(size);//每页显示的记录数 //搜索方式 //matchAllQuery搜索全部 searchSourceBuilder.query(QueryBuilders.matchAllQuery()); //设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{}); //向搜索请求对象中设置搜索源 searchRequest.source(searchSourceBuilder); //执行搜索,向ES发起http请求 SearchResponse searchResponse = client.search(searchRequest); //搜索结果 SearchHits hits = searchResponse.getHits(); //匹配到的总记录数,分页前的总数 long totalHits = hits.getTotalHits(); //得到匹配度高的文档 SearchHit[] searchHits = hits.getHits(); //日期格式化对象 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss"); for(SearchHit hit:searchHits){ //文档的主键 String id = hit.getId(); //源文档内容 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = (String) sourceAsMap.get("name"); //由于前边设置了源文档字段过虑,这时description是取不到的 String description = (String) sourceAsMap.get("description"); //学习模式 String studymodel = (String) sourceAsMap.get("studymodel"); //价格 Double price = (Double) sourceAsMap.get("price"); //日期 Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp")); System.out.println(name); System.out.println(studymodel); System.out.println(description); } }
- term query:精确查询,搜索词不会被拆分,直接用整体来查询,一般用于姓名,学好等
post http://localhost:9200/xc_course/doc/_search
{
"query": {
"term" : {
"name": "java"
}
}
}
//TermQuery @Test public void testTermQuery() throws IOException, ParseException { //搜索请求对象 SearchRequest searchRequest = new SearchRequest("xc_course"); //指定类型 searchRequest.types("doc"); //搜索源构建对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //设置分页参数 //页码 int page = 1; //每页记录数 int size = 1; //计算出记录起始下标 int from = (page-1)*size; searchSourceBuilder.from(from);//起始记录下标,从0开始 searchSourceBuilder.size(size);//每页显示的记录数 //搜索方式 //termQuery searchSourceBuilder.query(QueryBuilders.termQuery("name","spring")); //设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{}); //向搜索请求对象中设置搜索源 searchRequest.source(searchSourceBuilder); //执行搜索,向ES发起http请求 SearchResponse searchResponse = client.search(searchRequest); //搜索结果 SearchHits hits = searchResponse.getHits(); //匹配到的总记录数 long totalHits = hits.getTotalHits(); //得到匹配度高的文档 SearchHit[] searchHits = hits.getHits(); //日期格式化对象 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss"); for(SearchHit hit:searchHits){ //文档的主键 String id = hit.getId(); //源文档内容 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = (String) sourceAsMap.get("name"); //由于前边设置了源文档字段过虑,这时description是取不到的 String description = (String) sourceAsMap.get("description"); //学习模式 String studymodel = (String) sourceAsMap.get("studymodel"); //价格 Double price = (Double) sourceAsMap.get("price"); //日期 Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp")); System.out.println(name); System.out.println(studymodel); System.out.println(description); } }
- 根据id精确匹配
post: http://127.0.0.1:9200/xc_course/doc/_search
{
"query": {
"ids" : {
"type" : "doc",
"values" : ["3", "2", "100"]
}
}
}
//根据id查询 @Test public void testTermQueryByIds() throws IOException, ParseException { //搜索请求对象 SearchRequest searchRequest = new SearchRequest("xc_course"); //指定类型 searchRequest.types("doc"); //搜索源构建对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //搜索方式 //根据id查询 //定义id String[] ids = new String[]{"1","2"}; searchSourceBuilder.query(QueryBuilders.termsQuery("_id",ids)); //设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{}); //向搜索请求对象中设置搜索源 searchRequest.source(searchSourceBuilder); //执行搜索,向ES发起http请求 SearchResponse searchResponse = client.search(searchRequest); //搜索结果 SearchHits hits = searchResponse.getHits(); //匹配到的总记录数 long totalHits = hits.getTotalHits(); //得到匹配度高的文档 SearchHit[] searchHits = hits.getHits(); //日期格式化对象 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss"); for(SearchHit hit:searchHits){ //文档的主键 String id = hit.getId(); //源文档内容 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = (String) sourceAsMap.get("name"); //由于前边设置了源文档字段过虑,这时description是取不到的 String description = (String) sourceAsMap.get("description"); //学习模式 String studymodel = (String) sourceAsMap.get("studymodel"); //价格 Double price = (Double) sourceAsMap.get("price"); //日期 Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp")); System.out.println(name); System.out.println(studymodel); System.out.println(description); } }
- match Query:全文检索,它的搜索方式是先将搜索字符串分词,再使用各各词条从索引中搜索。
- operator:查分的词,只要有一个匹配了,就将文章给搜索出来,默认or
-
minimum_should_match: "80%"表示,三个词在文档的匹配占比为80%,即3*0.8=2.4,取整得2,表示至少有两个词在文档中要匹配成功。对于or,默认是0%,对于and,就是100%
{
"query": {
"match" : {
"description" : {
"query" : "java语言牛逼",
"operator" : "or",
"minimum_should_match": "80%"
}
}
}
}
//MatchQuery @Test public void testMatchQuery() throws IOException, ParseException { //搜索请求对象 SearchRequest searchRequest = new SearchRequest("xc_course"); //指定类型 searchRequest.types("doc"); //搜索源构建对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //搜索方式 //MatchQuery searchSourceBuilder.query(QueryBuilders.matchQuery("description","spring开发框架") .minimumShouldMatch("10%")); //设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{}); //向搜索请求对象中设置搜索源 searchRequest.source(searchSourceBuilder); //执行搜索,向ES发起http请求 SearchResponse searchResponse = client.search(searchRequest); //搜索结果 SearchHits hits = searchResponse.getHits(); //匹配到的总记录数 long totalHits = hits.getTotalHits(); //得到匹配度高的文档 SearchHit[] searchHits = hits.getHits(); //日期格式化对象 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss"); for(SearchHit hit:searchHits){ //文档的主键 String id = hit.getId(); //源文档内容 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = (String) sourceAsMap.get("name"); //由于前边设置了源文档字段过虑,这时description是取不到的 String description = (String) sourceAsMap.get("description"); //学习模式 String studymodel = (String) sourceAsMap.get("studymodel"); //价格 Double price = (Double) sourceAsMap.get("price"); //日期 Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp")); System.out.println(name); System.out.println(studymodel); System.out.println(description); } }
- multi Query:可以在多个字段中进行匹配
- fields:单项匹配是在一个field中去匹配,多项匹配是拿关键字去多个Field中匹配。name^10:表示name的权重乘以10;
{
"query": {
"multi_match" : {
"query" : "spring 前台页面",
"minimum_should_match": "10%",
"fields": [ "name^10", "description" ]
}
}
}
//MultiMatchQuery @Test public void testMultiMatchQuery() throws IOException, ParseException { //搜索请求对象 SearchRequest searchRequest = new SearchRequest("xc_course"); //指定类型 searchRequest.types("doc"); //搜索源构建对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //搜索方式 //MultiMatchQuery searchSourceBuilder.query(QueryBuilders.multiMatchQuery("spring css","name","description") .minimumShouldMatch("50%") .field("name",10)); //设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{}); //向搜索请求对象中设置搜索源 searchRequest.source(searchSourceBuilder); //执行搜索,向ES发起http请求 SearchResponse searchResponse = client.search(searchRequest); //搜索结果 SearchHits hits = searchResponse.getHits(); //匹配到的总记录数 long totalHits = hits.getTotalHits(); //得到匹配度高的文档 SearchHit[] searchHits = hits.getHits(); //日期格式化对象 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss"); for(SearchHit hit:searchHits){ //文档的主键 String id = hit.getId(); //源文档内容 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = (String) sourceAsMap.get("name"); //由于前边设置了源文档字段过虑,这时description是取不到的 String description = (String) sourceAsMap.get("description"); //学习模式 String studymodel = (String) sourceAsMap.get("studymodel"); //价格 Double price = (Double) sourceAsMap.get("price"); //日期 Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp")); System.out.println(name); System.out.println(studymodel); System.out.println(description); } }
- 布尔查询
- must:表示必须,条件都需要满足,
should:表示或者,多个查询条件只要有一个满足即可。must_not:表示非,条件都不能满足。
{
"query": {
"bool" : {
"must":[
{
"multi_match" :{
"query" : "spring框架",
"fields": [ "name^10", "description"]
}
},
{
"term":{
"studymodel" : "201001"
}
}
]
}
}
}
//BoolQuery @Test public void testBoolQuery() throws IOException, ParseException { //搜索请求对象 SearchRequest searchRequest = new SearchRequest("xc_course"); //指定类型 searchRequest.types("doc"); //搜索源构建对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //boolQuery搜索方式 //先定义一个MultiMatchQuery MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring css", "name", "description") .minimumShouldMatch("50%") .field("name", 10); //再定义一个termQuery TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("studymodel", "201001"); //定义一个boolQuery BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); boolQueryBuilder.must(multiMatchQueryBuilder); boolQueryBuilder.must(termQueryBuilder); searchSourceBuilder.query(boolQueryBuilder); //设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{}); //向搜索请求对象中设置搜索源 searchRequest.source(searchSourceBuilder); //执行搜索,向ES发起http请求 SearchResponse searchResponse = client.search(searchRequest); //搜索结果 SearchHits hits = searchResponse.getHits(); //匹配到的总记录数 long totalHits = hits.getTotalHits(); //得到匹配度高的文档 SearchHit[] searchHits = hits.getHits(); //日期格式化对象 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss"); for(SearchHit hit:searchHits){ //文档的主键 String id = hit.getId(); //源文档内容 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = (String) sourceAsMap.get("name"); //由于前边设置了源文档字段过虑,这时description是取不到的 String description = (String) sourceAsMap.get("description"); //学习模式 String studymodel = (String) sourceAsMap.get("studymodel"); //价格 Double price = (Double) sourceAsMap.get("price"); //日期 Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp")); System.out.println(name); System.out.println(studymodel); System.out.println(description); } }
- 过滤器
-
过虑器主要判断的是文档是否匹配,不去计算和判断文档的匹配度得分,所以过虑器性能比查询要高,且方便缓存,推荐尽量使用过虑器去实现查询或者过虑器和查询共同使用。对于term和range我们推荐使用过滤器来查询。
{
"query": {
"bool" : {
"must":[
{
"multi_match" : {
"query" : "spring框架",
"fields": [ "name^10", "description" ]
}
}
],
"filter": [
{"term": { "studymodel": "201001"}},
{"range": { "price": { "gte": 60 ,"lte" : 100}}}
]
}
}
}
//filter @Test public void testFilter() throws IOException, ParseException { //搜索请求对象 SearchRequest searchRequest = new SearchRequest("xc_course"); //指定类型 searchRequest.types("doc"); //搜索源构建对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //boolQuery搜索方式 //先定义一个MultiMatchQuery MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring框架", "name", "description") .field("name", 10); //定义一个boolQuery BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); boolQueryBuilder.must(multiMatchQueryBuilder); //定义过虑器 boolQueryBuilder.filter(QueryBuilders.termQuery("studymodel","201001")); boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(60).lte(100)); searchSourceBuilder.query(boolQueryBuilder); //设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{}); //向搜索请求对象中设置搜索源 searchRequest.source(searchSourceBuilder); //执行搜索,向ES发起http请求 SearchResponse searchResponse = client.search(searchRequest); //搜索结果 SearchHits hits = searchResponse.getHits(); //匹配到的总记录数 long totalHits = hits.getTotalHits(); //得到匹配度高的文档 SearchHit[] searchHits = hits.getHits(); //日期格式化对象 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss"); for(SearchHit hit:searchHits){ //文档的主键 String id = hit.getId(); //源文档内容 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = (String) sourceAsMap.get("name"); //由于前边设置了源文档字段过虑,这时description是取不到的 String description = (String) sourceAsMap.get("description"); //学习模式 String studymodel = (String) sourceAsMap.get("studymodel"); //价格 Double price = (Double) sourceAsMap.get("price"); //日期 Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp")); System.out.println(name); System.out.println(studymodel); System.out.println(description); } }
- 排序
{
"query": {
"bool" : {
"filter": [ { "range": { "price": { "gte": 0 ,"lte" : 100}}}]
}
},
"sort" : [
{"studymodel" : "desc" },
{ "price" : "asc" }
]
}
//Sort @Test public void testSort() throws IOException, ParseException { //搜索请求对象 SearchRequest searchRequest = new SearchRequest("xc_course"); //指定类型 searchRequest.types("doc"); //搜索源构建对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //boolQuery搜索方式 //定义一个boolQuery BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); //定义过虑器 boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(0).lte(100)); searchSourceBuilder.query(boolQueryBuilder); //添加排序 searchSourceBuilder.sort("studymodel", SortOrder.DESC); searchSourceBuilder.sort("price", SortOrder.ASC); //设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{}); //向搜索请求对象中设置搜索源 searchRequest.source(searchSourceBuilder); //执行搜索,向ES发起http请求 SearchResponse searchResponse = client.search(searchRequest); //搜索结果 SearchHits hits = searchResponse.getHits(); //匹配到的总记录数 long totalHits = hits.getTotalHits(); //得到匹配度高的文档 SearchHit[] searchHits = hits.getHits(); //日期格式化对象 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss"); for(SearchHit hit:searchHits){ //文档的主键 String id = hit.getId(); //源文档内容 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = (String) sourceAsMap.get("name"); //由于前边设置了源文档字段过虑,这时description是取不到的 String description = (String) sourceAsMap.get("description"); //学习模式 String studymodel = (String) sourceAsMap.get("studymodel"); //价格 Double price = (Double) sourceAsMap.get("price"); //日期 Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp")); System.out.println(name); System.out.println(studymodel); System.out.println(description); } }
- 高亮显示
- 我们可以使用<tag class="eslight"></tag>包裹字段,前端对这个class=“eslight”进行样式的改变,比如 .eslight{color:red}
{
"query": {
"bool" : {
"must":[
{
"multi_match" : {
"query" : "开发框架",
"fields": [ "name^10", "description"],
"type":"best_fields"
}
}
],
"filter": [
{
"range": { "price": { "gte": 0 ,"lte" : 100}}
}
]
}
},
"highlight": {
"pre_tags": ["<tag1>"],
"post_tags": ["</tag2>"],
"fields": { "name": {}, "description":{} }
}
}
//Highlight @Test public void testHighlight() throws IOException, ParseException { //搜索请求对象 SearchRequest searchRequest = new SearchRequest("xc_course"); //指定类型 searchRequest.types("doc"); //搜索源构建对象 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //boolQuery搜索方式 //先定义一个MultiMatchQuery MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("开发框架", "name", "description") .minimumShouldMatch("50%") .field("name", 10); //定义一个boolQuery BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); boolQueryBuilder.must(multiMatchQueryBuilder); //定义过虑器 boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(0).lte(100)); searchSourceBuilder.query(boolQueryBuilder); //设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段 searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{}); //设置高亮 HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.preTags("<tag>"); highlightBuilder.postTags("</tag>"); highlightBuilder.fields().add(new HighlightBuilder.Field("name")); // highlightBuilder.fields().add(new HighlightBuilder.Field("description")); searchSourceBuilder.highlighter(highlightBuilder); //向搜索请求对象中设置搜索源 searchRequest.source(searchSourceBuilder); //执行搜索,向ES发起http请求 SearchResponse searchResponse = client.search(searchRequest); //搜索结果 SearchHits hits = searchResponse.getHits(); //匹配到的总记录数 long totalHits = hits.getTotalHits(); //得到匹配度高的文档 SearchHit[] searchHits = hits.getHits(); //日期格式化对象 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy‐MM‐dd HH:mm:ss"); for(SearchHit hit:searchHits){ //文档的主键 String id = hit.getId(); //源文档内容 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); //源文档的name字段内容 String name = (String) sourceAsMap.get("name"); //取出高亮字段 Map<String, HighlightField> highlightFields = hit.getHighlightFields(); if(highlightFields!=null){ //取出name高亮字段 HighlightField nameHighlightField = highlightFields.get("name"); if(nameHighlightField!=null){ Text[] fragments = nameHighlightField.getFragments(); StringBuffer stringBuffer = new StringBuffer(); for(Text text:fragments){ stringBuffer.append(text); } name = stringBuffer.toString(); } } //由于前边设置了源文档字段过虑,这时description是取不到的 String description = (String) sourceAsMap.get("description"); //学习模式 String studymodel = (String) sourceAsMap.get("studymodel"); //价格 Double price = (Double) sourceAsMap.get("price"); //日期 Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp")); System.out.println(name); System.out.println(studymodel); System.out.println(description); } }
5、IK分词器(实现对中文进行分词)
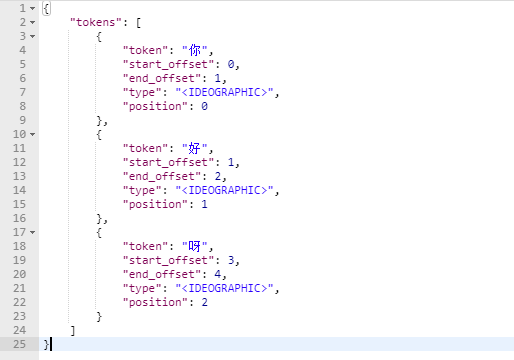
1、测试默认分词器(对中文不友好,测试结果会将中文一个字认为就是一个单词)
post localhost:9200/_analyze
{"text":"你好,呀"}
响应结果
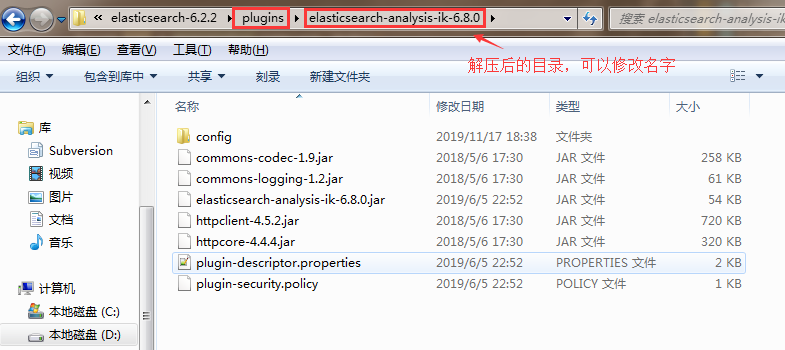
2、IK分词器:https://github.com/medcl/elasticsearch-analysis-ik(版本和ES版本需要一致)
使用:将下载的文件copy到ES中的plugins目录下(可以新建一个文件夹),重启ES,如果报错,可能就是插件的版本和ES不一致
测试
post localhost:9200/_analyze
{"text":"测试分词器,后边是测试内容:spring cloud实战","analyzer":"ik_max_word" }

- 1、ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
- 2、ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
3、IK分词器自定义词库
1、配置ik插件(\elasticsearch-6.2.2\plugins\ik\config\IKAnalyzer.cfg.xml):创建my.dic
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">my.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
2、在IKAnalyzer.cfg.xml配置文件的同一级目录创建my.dic文件(注意保存为utf-8),此时小明同学和笑哈哈就是一个词了,可以查看main.dic
小明同学 笑哈哈
3、重启ES
数据(document)的crud
使用脚本进行partial update
POST /index4/type4/1/_update
{
"script":"ctx._source.num+=1" //表示获取_source中的num数据,并且+1,再更新数据
}
//补充
ctx._source. num==count ?'delete':' none' //删除文档
upsert
POST /index5/type5/2/_update
{
"script": "ctx._source.num+=100", //如果document存在执行这个脚本,如果不存在执行下面的upsert进行初始化。
"upsert":{
"num":2
}
}
使用外置脚本
查看
GET /test/test1/3
删除
DELETE /test/test1/3
搜索
使用DSL语句查询
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}
分页查询
GET megacorp/employee/_search
{
"query": {"match_all": {}},
"from": 0, //从0开始查找
"size": 1 //找1条数据
}
查询的数据只包含某些字段
GET megacorp/employee/_search
{
"_source": ["age"] //默认返回的_source元数据中的值是我们添加(PUT)命令中的request body完整的数据。
}
过滤
GET /megacorp/employee/_search
{
"query" : {
"bool" : {
"filter" : { //筛选
"range" : { //范围
"age" : { "gt" : 30 } //表示年龄大于30
}
},
"must" : {
"match" : {
"last_name" : "smith"
}
}
}
}
}
filter,仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响
query,会去计算每个document相对于搜索条件的相关度,并按照相关度进行排序
GET /megacorp/employee/_search
{
"query": {
"term": { //表示完整的查询,对这个rock climbing不分词,进行完整的查询,但是注意插入数据的时候,建立倒排索引的时候,指定的字段不能分词。否则查询不到
"about": "rock climbing"
}
}
}
全文搜索
参考文档,很详细 https://es.xiaoleilu.com/010_Intro/30_Tutorial_Search.html
重点提出了相关性,传统的数据库对记录查询只有匹配或者不匹配,而elasticsearch中有一个很大的特色就是相关性,即,查询的结果如果出现和搜索关键词有类似的,那么这条记录也会别检索出来。只是权重比较低。
短语搜索
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing" //表示这个一个短语。会较降低相关度
}
}
}
高亮我们的搜索
很多应用喜欢从每个搜索结果中高亮(highlight)匹配到的关键字,这样用户可以知道为什么这些文档和查询相匹配。在Elasticsearch中高亮片段是非常容易的。
让我们在之前的语句上增加highlight参数:
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}
聚合(7.x)
GET /megacorp/employee/_search
{
"size":0, //表示让原始数据不要展示出来
"aggs": {
"testsss": {
"terms": { "field": "interests"} //terms表示合并起来并计算每一组的数量
}
}
}
如果报错Fielddata is disabled on text fields by default. Set fielddata=true on [interests] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field insteadj(解决:先执行下面的这一步(不推荐了,在下一个版本,include_type_name将要删除了),在执行上面的)
或者参考:https://blog.csdn.net/u014646662/article/details/94718834
PUT /megacorp/_mapping/employee?include_type_name=true
{
"properties": {
"interests": { //注意是聚合的字段
"type":"text",
"fielddata": true
}
}
}
//如果出现,表示成功
{
"acknowledged" : true
}
补充mapping知识
GET /megacorp/_mapping/employee?include_type_name=true //查看mapping
自动或手动为index中的type建立的一种数据结构和相关配置,简称为mapping
dynamic mapping,自动为我们建立index,创建type,以及type对应的mapping,mapping中包含了每个field对应的数据类型,以及如何分词等设置。
手动设置mapping
排序
GET megacorp/employee/_search
{
"query": {"match_all": {}}, //查询全部(可以省略)
"sort": [{"age": "desc"}] //按照年龄降序
}
GET /megacorp/employee/_search
{
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
聚合加排序
GET /megacorp/employee/_search
{
"size":0,
"aggs": {
"group_by_interests": {
"terms":{
"field":"interests",
"order":{
"avg_age": "desc" //对avg_age的结果进行排序
}
},
"aggs": {
"avg_age": {
"avg": {"field":"age"}
}
}
}
}
}
需求:根据指定的年龄区间进行分组,每一组在按照兴趣进行分组。最后计算每一组的平均年龄
GET /megacorp/employee/_search
{
"size":0,
"aggs": {
"group_by_price": {
"range": {
"field":"age",
"ranges":[
{"from":0,
"to":32 //不包含32
},
{"from":32, //包含32
"to":40
}
]
},
"aggs": {
"group_by_interests": {
"terms": {"field":"interests"},
"aggs":{
"avg_age":{
"avg":{"field":"age"}
}
}
}
}
}
}
}
单node环境下创建index是什么样子的
单node环境下,创建一个index,有3个primary shard,3个replica shard
集群status-yellow
这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shar是无法分配的
集群可以正常工作,但是一旦出现节点右机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index
{
"settings": {
"number_of_shards": 3, //primary shard的数量确定后不能改变
"number_of_replicas": 1 //表示每一个primary shard 只有一个replicas shard,replicas shard的数量可以增多
}
}
master选举,replica容错,数据恢复
第一步:当一个node节点宕机了(如果这个node是master,那么master在宕机的一瞬间就被另外的一个node选举上了),如果这个节点上有primary shard,那么此时cluster status 为red
第二步:新的master将宕机中的primary shard 的某一个 replicas shard 提升为primary shard ,此时的cluster status 为yellow(少了一个replicas shard);
第三步:启动有故障的node节点(服务器),master会将会将缺失的副本都copy一份到该node上,而该node会使用宕机之前已经有的数据,只是同步一下宕机之后数据的修改部分(包装数据的完整性),cluster status为green。
document ID自动生成和手动生成
手动生成(指定id)
GET /t_index/t_type/1
{
"xx":"xx"
}
不指定id
POST /t_index/t_type/
{
"name":"zy"
}
返回的结果
{
"_index" : "t_index",
"_type" : "t_type",
"_id" : "TEAuvGsB143pQjNJLsoV", //id由20位字符组成,URL安全,base64编码,GUID算法保证分布式系统并行生成时不可能会发生冲突
"_score" : 1.0,
"_source" : {
"name" : "zy"
}
}
ElasricSearch并发冲突问题
解决方案1:悲观锁
悲观锁并发控制方案,就是在各种情况下,只要某一个线程得到了数据,就上锁,上锁之后,就只有一个线程可以操作这一条数据了,当然,不同的场景下,上的额领不同,行级锁,表级顿,读烦,写锁。
解决方案2(es的方案):乐观锁:实现算法是CAS:比较并交换(compare and swap)
https://elasticsearch.cn/book/elasticsearch_definitive_guide_2.x/optimistic-concurrency-control.html
不加锁,引入版本号的概念,当某一个线程对数据进行就修改了在写入后,就会将数据的版本号改变,在改变之前必须先比较自己当前数据的版本号和es中的数据版本号是否一样,如果一样,则写入数据,修改版本号,如果不一样,需要重新获取es中的数据,重复操作;
实操:
创建一条数据,返回结果
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "2",
"_version" : 4,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 2
}
在es6.7之前,put数据如果需要带上版本
PUT /test_index/_doc/2?version=4 //版本号对应上面的版本号
{
"test_field":"test client 1"
}
在es7.x之后
PUT /test_index/_doc/1?if_seq_no=3&if_primary_term=2 //数字和上面查询的结果对应
{
"test_field":"test client 1"
}
put数据的时候如果版本号数据不时es中的对应的数据,就会报错,需要重新获取es中的数据,修改版本号,重新put。
附:es提供了一个feature,就是说,你可以不用它提供的内部_versign版本号来进行并发控制,可以基于你自己维护的一个版本号来进行并发控制。举个列子:加入你的数据在mysql也有一份,然后你的应用系统本身就维护了一版本号,无论是什么自己生成的,还是程序控制的。这个时候,你进行乐观锁并发控制的时候,可能并不是想要用es内部的_version来进行控制,而是用你自己维护的那个version来进行控制。
PUT /index1/type2/1?version=2&version_type=external //更新的时候version版本必须大于es中数据的版本,且必须加上version_type=external(表示版本自己控制)
{
"name":"1"
}
悲观横与乐观锁优缺点
1、悲观锁的优点是:方便,直接加锁,对应用程序来说,透明,不需要做额外的操作;缺点,并发能力很低,同一时间只能有一条线程操作数据。
2、乐观额的优点是:并发能力很高,不给数据加锁,大量线程并发操作;缺点,麻烦,每次更新数据的时候,都要先比对版本号,然后可能需要重新加载数据,再次修改,再写;这个过程,可能要重复好几次。
返回结果解析
{
"took" : 882,
"timed_out" : false,
"_shards" : {
"total" : 29, //搜索打到了多少的分片上
"successful" : 29,
"skipped" : 0, //忽略了多少的shard
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte" //表示查询结果大于等于10000条
},
"max_score" : 1.0, //关联度
"hits" : [] //数据(省略,默认最多显示10条)
}
批量查询 /mget
作用:减少网络开销
GET /_mget //如果 /_mget前面指明了_index,docs中就不需要写"_index"
{
"docs":[ //docs固定,返回多个documents
{
"_index":"index5",
"_type":"type5",
"_id":"1"
},
{
"_index":"index5",
"_type":"type5",
"_id":"2"
}
]
}
GET /index5/type5/_mget
{
"docs":[
{
"_id":"1"
},
{
"_id":"2"
}
]
}
GET /index5/type5/_mget
{
"ids":[1,2] //可以简写
}
批量增删改 bulk
(1)delete:删除一个文档,只要1个json串就可以了
(2)create:相当 PUT/index/type/id/_create,强制创建,存在就报错
(3)index:普通的put操作,可以是创建文档,也可以是全量替换文档
(4)update:执行的partial update操作
POST /_bulk
{"delete":{"_index":"index5","_type":"type5","_id":1}} //注意json字符串必须放在同一行,并且不同操作必须换行,另外如果不是语法错误,某一个操作失败(例如delete)是不影响其他操作的,返回结果会有日志,告诉你错误
{"create":{"_index":"index5","_type":"type5","_id":3}}
{"num":3}
{"update":{"_index":"index5","_type":"type5","_id":2}}
{"doc":{"num":2}}
补充:bulk size最佳大小
bulk.request会加载到内存里,如果太大的话,性能反而会下降,因此需要反复尝试一个最佳的bulk size。一般从1000~5000条数据开始,尝试逐渐增加。另外,如果看大小的话,最好是在5~15MB之间。
说明采用这种特殊的格式(json数据)有什么意义 ?
1、如果采用比较良好的json数组格式 [{"xx":"xx"},"xx":"xx"]
允许任意的换行,整个可读性非常棒,读起来很爽,es拿到那种标准格式的json串以后,要按照下述流程去进行处理
(1)将json数组(json文本)解析为JSONArray对象:这个时候,整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是json文本,一份数据是JSONArray对象
(2)解析json数组里的每个json,对每个请求中的document进行路由
(3)为路由到同一个shard上的多个请求,创建一个请求数组
(4)将这请求数组序列化
(5)将序列化后的请求数组发送到对应的节点上去
缺点:
耗费更多内存,更多的jvm gc开销
我们之前提到过bulk size最佳大小的那个问题,一般建议说在几千条那样,然后大小在10M8左右,所以说,可怕的事情来了。假设说现在100个bulk请求发送到了一个节点上去,然后每个请求是10MB,100个请求,就是1000MB=1GB,然后每个请求的json都copy一份为jsonarray对象,此时内存中的占用就会翻倍,就会占用2GB的内存,甚至还不止。因为弄成jsonarray之后,还可能会多搞一些其他的数据结构,2GB+的内存占用。
占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能急速下降,另外的话,占用内存更多,就会导致ava虚拟机的垃圾回收次数更多,每次要回收的垃圾对像更多,耗费的时间更多,导致es的java虚拟机停止工作线程的时间更短。
2、采用奇特的json格式
{“action”:{“meta”}}\n
{"data"}\n
{“action”:{“meta”}}\n
{"data"}\n
(1)不用其转换为json对象,不会出现内存中的相同数据的拷贝,直接按照换行符切割json
(2)对每两个一组的son,读取meta,进行document路由
(3)直接将对应的json发送到node上去
5、最大的优势在于,不需要将json数组解析为一个JSONArray对象,形成一份大数据的持贝,浪费内存空间
document数据路由原理
我们知道,一个index的数据会被分为多片,每片都在一个shard中,所以说,一个document,只能存在于一个shard中,当客户请创建document的时候,es此时就需要决定说,这个document是放在这个index的哪个shard上。这个过程,就称之为document routing,数据路由。
路由算法:shard=hash(routing)%nunmber_of primary_shards
routing值,默认是id,也可以手动指定,同一个id路由的shard一定是一样的,手动指定routing value是很有用的,可以保证说,某一类document一定被路由到一个shard上去,那么在后续进行应用级别的负载均衡,以及提升批量读取的性能的时候,是很有帮助的。
正是由于路由算法。导致primary shard 是不允许扩增的。
document数据的增删改内部实现原理
(1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
(2)coordinating node,对document进行路由(通过路由算法),将请求转发给对应的node(由primary shard,增删改只能有primary shard处理)
(3)实际的node上的primary shard处理请求,然后将数据同步到replica node
(4)coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
document数据的查询内部实现原理
(1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
(2)coordinating node,对document进行路由(通过路由算法),将请求转发给对应的node(可以是replicas shard),查到结果返回给coordinatind node返回给协调节点
(3)coordinating node 将最好的数据响应给客户端
特殊情况:document如果还在建索引过程中,可能只有primary shard有数据,任何一个replica shard都没有数据,此时可能会导致无法读取到document,但是document完成索引建立之后,primary shard和replica shard就都有了,就可以查询了。
quorum机制
我们在发送任何一个增删改操作的时候,比如说put/index/type/id,都可以带上一个consistency参数,指明我们想要的写一致性是什么?
put/index/type/id?consistency=quorum
one:要求我们这个写操做,只要有一个primary shard量active活跃可用的;就可以执行
all:要求我们这个写操作,必须所有的prinary shardf和rep1ica shard是活跃的,才可以执行这个写操作。
quorum:默认的值,要求所有的shard中,必须是大部分的shard都是活跃的,可用的,才可以执行这个写操作
1、quorum机制,写之前必须确保大多数shard
都可用,int((primary+number_of_replicas)/2)+1,当number_of_replicas>1时才生效
quroum =int((primary + number of replicas)/2)+1
举个例子,3个primary shard,number_of_replicas=1,总共有3+3*1=6个shard,所以,要求6个shard中至少有3个shard是active状态的,才可以执行这个写操作
2、如果节点数少于quorum数量,可能导致quorum不齐全,进而导致无法执行任何写操作
3个prinary,shard,replica=1,要求套少3个shard是active,3个shard按照之前学习的shard&replica机制,必须在不同的节点上,如果说只有1台机器的话,是不是有可能出现,3个shard都没法分配齐全,此时就可能会出现写操作无法执行的情况。
1个primary hard,replica=3,quorum=((1+3)/2)+1=3,要求其中必须有3个shard是要处于active状态的。如果这个时候只有2台机器的话,会出现什么情况呢?
一个node节点不允许primary shard和replicas shard或replicas shard和replicas shard在一台机器上的,所以说,此时的两台机器,只能分配两个shard,一台机器放primary shard,另一台机器放replicas shard,这样如果按照quorum机制的话,永远数据也写入不了。
ES提供了一种特殊的处理场景:防止如果假如就只有一台node,为了可以正常的使用,解决:当unmber_of_replicas>1时才生效。举例子,只有一个primary shard和一个replicas shard(最低配置),公式:((1+1)/2)+1=2,要求必须有2个shard是活跃的,但是可能就1个node,此时就1个shard是活跃的,如果你不特殊处理的话,导致单点集群就无法工作。
3、quorum不齐全时,wait,默认1分钟,timeout,100,30s
等待期间,期望活跃的shard量可以增加,最后实在不行,就会timeout
我们在写操作的时候,可以加—个timeout参数,比如说put/index/type/id?timeout=30,这个就是说自己去设定quorunm不齐全的时候,es的timeout时长,可以缩短,也可以增加(30单位为毫秒,30s加上s表示秒)
search timeout机制
默认情况下,没有所谓的timeout,比如说,如果你的搜索的特别慢,每个sharda要花好几分钟才能查询出来所有的数据,那么你的控索请求也会等待好几分钟之后才会返回。这就非常不利于用户体验。
timeout机制,指定每个shard,就只能在timeout时间范围内,将搜索到的部分数据(也可能全部搜索到了),直接理解返回给client程序,而不是等到所有的微据全都搜索出来以后再返回。所以需要指定timeout
multi_index和multi_type搜索模式解析
GET /index5,index4,index3/_search GET /index*/_search GET /_all/_search 等于GET /*/_search
_search搜索:
client发送一个搜素请求,会把清求打到所有的primary shard上去执行,因为每个shard都包含部分数据,所以每个shard上可能会包含搜索请求的结果。但是如果primary shard有replica shard,那么请求也可以打到replica shard上去,就不会打到primary shard上去了。
deep paging性能问题
假如我们需要第1000页的数据,每页10条,coordinating节点就会将请求发送到相关的shard上(全局的数据第1000页),每一个shard都会检索出10000-10010条数据返回给coordinating节点。然后coordinating 节点,在将所有的数据根据_score排序。在取出第一千页的数据,正好10条。
检索的过深的时候,就需要在coordinate node上保存大量的数据,还要进行大量数据的排序,排序之后,再取出对应的那一页,所以这个过程,即耗费网络带宽,耗费内存,还耗费cpu,所以deep paging的性能问题,我们应该尽量避免出现这种deep paging操作。
倒排索引的解析
首先在建立倒排索引之前需要normalization,是关键字正常化,也就是说对拆分出的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关联的文档的概率。
比如
document:likes dogs
分词后有 likes, dogs
如果你搜索 like dog,同样也会被分词为like,dog,但是这是找不到document的(没有一个单词符合document)。所以使用normalization,会将likes-->变成like。dogs-->dog
再次搜索like dog / likes dog / like dogs 等。分词后都会被normalization转换正常。like dog就可以搜索到了。
分词器
1、什么是分词器
切分词语,nornalization(提升recall召回率)给你一段句子,然后将这段句子拆分成一个一个的单个的单词,同时对每个单词进行normalization(时态转换,单复数转换)
recall,召回率:搜索的的候,增加能够搜索到的结果的数量
分词器的组成
character filter:在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(<span>hello<span>-->hel1o),&-->and(I&you-->I and you)
tokenizer:分词,hello you and me-->hello,you,and,me
token filter:对拆分的单词进行时态转换,单复数转换等等,a/the/an-->可能干掉,
一个分词器,很重要,将一段文本进行处理,最后处理好的结果才会拿去建立倒排索引
2、内置分词器的介绍
Set the shape to semi-transparent by calling set_trans(5) //将要拆分的语句
standard analyzer : set,the,shape,to,semi,transparent,by,calling,set_trans,5 //默认的分词器
simple analyzer : set,the,shape,to,semi,transparent,by,calling,set,trans
whitespace analyzer : Set,the,shape,to,semi-transparent,by,calling,set_trans(5)
language analyzer : set,shape,semi,transpar,call,set_tran,5
测试倒配索引的分词器
GET /_analyze
{
"analyzer":"standard",
"text":"i like joke" //测试这段文字是如果被分词的
}

