
Elasticsearch----下载安装
1、下载安装
elasticsearch 启动时候回占用大量内存(2G左右),启动成功后,内存会慢慢释放掉一些
windows
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
进入elasticsearch的bin目录,双击elasticsearch.bat启动服务,默认端口是9200
如果启动不了:config/elasticsearch.yml 中添加 xpack.ml.enabled: false
linux:可以直接使用docker部署
阅读文档:
https://es.xiaoleilu.com/index.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.2/modules-scripting-painless.html
配置
1、elasticsearch.yml,注意设置elasticsearch.yml是UTF-8的字符编码)
#ES可以配置集群,这个就是集群的名称(一个集群通用这个名字) cluster.name: xuecheng #设置当前的服务在集群中的节点名称(不能重复) node.name: xc_node_1 #设置绑定主机的ip地址,设置为0.0.0.0表示绑定任何ip,允许外网访问,生产环境建议设置为具体 的ip network.host: 0.0.0.0 #服务端口(使用http访问) http.port: 9200 #ES集群内部之间相互访问的接口 transport.tcp.port: 9300 #指定该节点是否有资格被选举成为master结点,默认是true,如果原来的master宕机会重新选举新 的master node.master: true #指定该节点是否存储索引数据,默认为true。 node.data: true #配置集群 discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301"] #设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些。 discovery.zen.ping_timeout: 3s #主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这 里要设置为2。 discovery.zen.minimum_master_nodes: 1 #是否允许成为协调节点 node.ingest: true #设置为true可以锁住ES使用的内存,避免内存与swap分区交换数据。 bootstrap.memory_lock: false #单机允许的最大存储结点数,通常单机启动一个结点建议设置为1,开发环境如果单机启动多个节点可设置大于1. node.max_local_storage_nodes: 2 path.data: D:\ElasticSearch\elasticsearch-6.2.1-1\data path.logs: D:\ElasticSearch\elasticsearch-6.2.1-1\logs #开启cors跨域访问支持 http.cors.enabled: true #(允许所有域名)以上,使用正则 http.cors.allow-origin: /.*/
更多时间
discovery.zen.ping_timeout discovery.zen.fd.ping_timeout discovery.zen.join_timeout discovery.zen.publish_timeout discovery.zen.commit_timeout
2、jvm.options
设置最小及最大的JVM堆内存大小:在jvm.options中设置 -Xms和-Xmx: 1) 两个值设置为相等 2) 将 Xmx 设置为不超过物理内存的一半。 默认是1g
3、log4j2.properties
生产环境,注意最好配置error
4、在linux上根据系统资源情况,可将每个进程最多允许打开的文件数设置大些。
elasticsearch ‐ nofile 65536
启动报错
其他错误参考:https://blog.csdn.net/qq_34409255/article/details/84974280
当在配置文件配置了 network.host: 0.0.0.0,报错:JVM is using the client VM [Java HotSpot(TM) Client VM] but should be using a server VM for the best performance
解决修改java运行环境 D:\java\jdk1.8.0_201\jre\lib\i386\jvm.cfg
概念
了解参考:https://www.cnblogs.com/jajian/p/9801154.html
对Elastcisearch描述
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
ElasticSearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elastic Search 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。底层基于Lucene。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
面向文档的,使用json作为文档序列化格式。
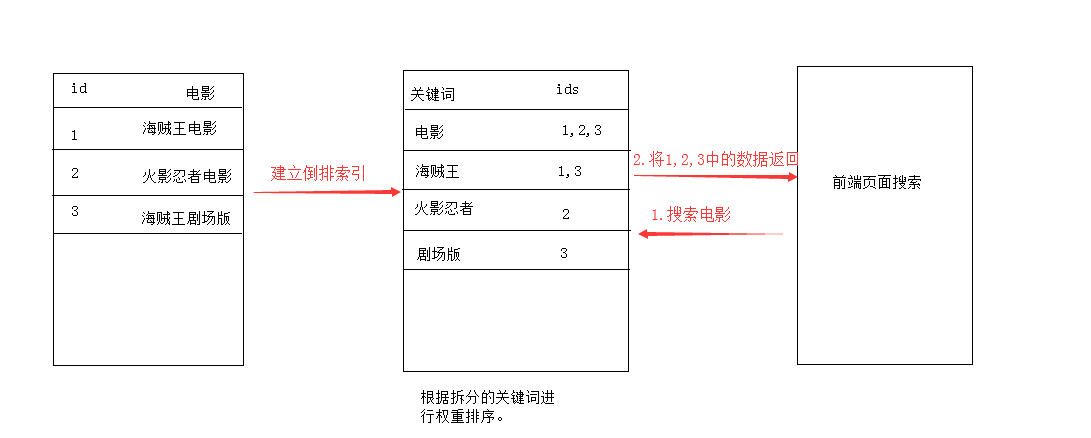
全文检索、倒排索引(示意图)
倒排索引就是讲数据中的词拆分构建一个大表,将关键字拆出来,后面带上这个文章的documentid号,通过关键词可以找到对应的文章
全文检索就比较好理解的,就是当我们输入“全瓦解”,会被拆分成”全”,“瓦解”2个此,用2个词去倒排索引里面去检索数据,检索到的数据返回。整个过程就叫做全文检索
lucene
lucene.就是一个jar包,里面包含(封装好的各种建立倒排索引,以及进行搜索的代码,包含各种算法、我们用java开发的时候,引人lucene jar,然后基于lucene的api开发即可,用lucene,我们就可以去将已有的数据建立索引,lucene会在本地磁盘上面,给我们组织索引的数据结构。另外的话,我们也可以用lucene提供的一些功能和api来针对磁盘上的索引数据,进行搜索。
Elasticsearch
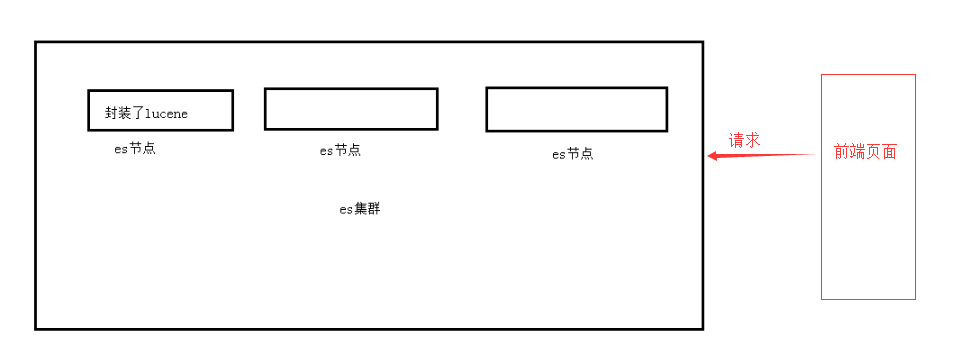
1.自动维护数据的分布到多个节点索引的建立,还有搜索请术分布到多个节点的执行
2.自动维护数据的冗余副本,包证说,一些机器宕机了,不会丢失任何的数据
3.封装了更多的高级功能,以给我们提供更多高级的支持,让我们快速的开发应用,开发更加复杂的应用,复杂的搜索功能,聚合分析的功能,基于地理位置的搜素(距离我当前位置1公里以内的烤内店)
shard和replica
shard:单机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分不到多态服务器上去执行,提高吞吐量和性能。,每一个share都是一个Lucene index
replica:任何服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提供检索操作的吞吐量和性能。primary share(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数重,默认1个,默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
index(索引)和type(类型)和document(文档)
ES中document相当数据库中的一行。
ES中的type相当数据库中的表
ES中的index(名词)相当数据库中的数据库,index(动词):往ES中存入数据
使用
windows启动
启动命令(进入bin目录)
elasticsearch.bat
如果出现
ElasticsearchException[X-Pack is not supported and Machine Learning is not available for [windows-x86]; you can use the other X-Pack features (unsupported) by setting xpack.ml.enabled: false in elasticsearch.yml错误
解决:在elasticsearch.yml配置文件最后添加,重新启动
xpack.ml.enabled: false
访问浏览器
http://127.0.0.1:9200/
出现,表示启动成功
{
"name" : "xxxx-PC", //表示node(节点名称):在哪一台服务器上启动
"cluster_name" : "elasticsearch", //集群名称,如果需要修改,在conf/elasticsearch.yml中修改
"cluster_uuid" : "SSOU_2kJSW6xsHZFwfLrhg",
"version" : {
"number" : "7.2.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
使用kibana
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。
启动(bin目录下)
kabana.bat
打开浏览器
http://localhost:5601
使用开发工具(dev tools)操作下面的命令

 浙公网安备 33010602011771号
浙公网安备 33010602011771号