爬取微博热搜top50
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称:爬取微博热搜top50
2.主题式网络爬虫的内容与数据特征分析:排名 关键词 点击量
3.主题式网络爬虫设计方案概述:
先分析页面 对比源代码找出规律,然后对网页进行爬取,再对爬取的数据进行分析和可视化。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征分析: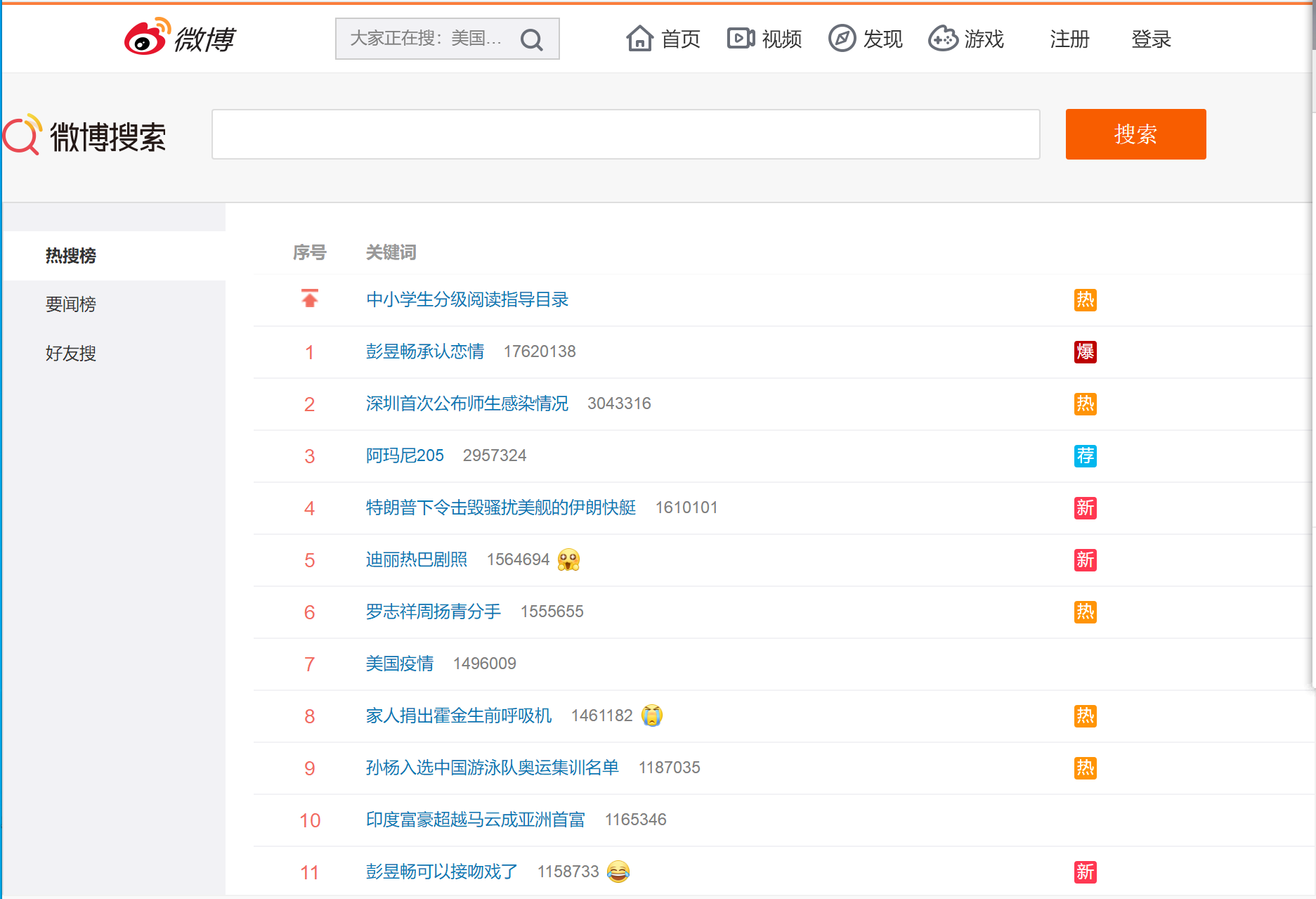
2.Htmls页面解析:
右击查看网页源代码
3.节点(标签)查找方法与遍历方法:
(1)热搜的名字都在<td class="td-02">的子节点<a>里
(2)热搜的排名都在<td class=td-01 ranktop>里(置顶热搜没有排名)
(3)热搜的访问量都在<td class="td-02">的子节点<span>里

三、网络爬虫程序设计
1.爬取数据
###导入模块 import requests from lxml import etree ###网址 url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6" ###模拟浏览器 header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}###伪装爬虫 ###主函数 def main(): ###获取html页面 html=etree.HTML(requests.get(url,headers=header).text) rank=html.xpath('//td[@class="td-01 ranktop"]/text()') affair=html.xpath('//td[@class="td-02"]/a/text()') view = html.xpath('//td[@class="td-02"]/span/text()') top=affair[0] affair=affair[1:] print('{0:<10}\t{1:<40}'.format("top",top)) for i in range(0, len(affair)): print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288))) main()
爬取结果:
将top5存入Excel表格中
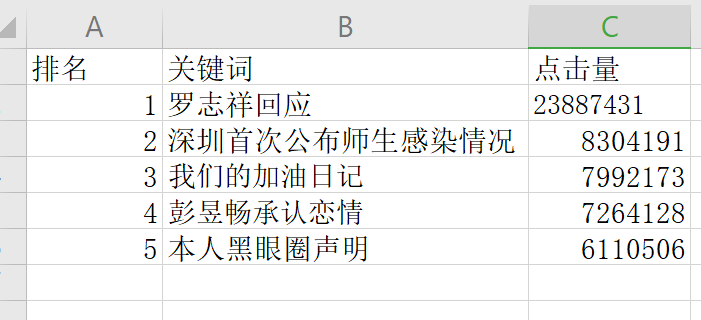
2.对数据进行清洗和处理:
import pandas as pd
df = pd.read_excel('weibotop5.xlsx')
df.head()``
结果如下:

3.数据分析与可视化
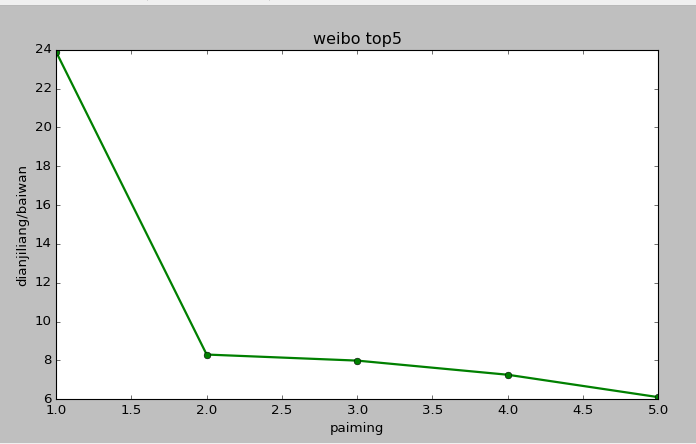
import matplotlib.pyplot as plt plt.figure(figsize=(6,4)) plt.plot([1,2,3,4,5],[23.887431,8.304191,7.992173,7.264128,6.110506],'go-',linewidth=2) plt.rcParams['font.sans-serif']=['SimHei'] plt.legend() plt.xlabel('paiming') plt.ylabel('dianjiliang/baiwan') plt.title('weibo top5') plt.show()
结果如下:
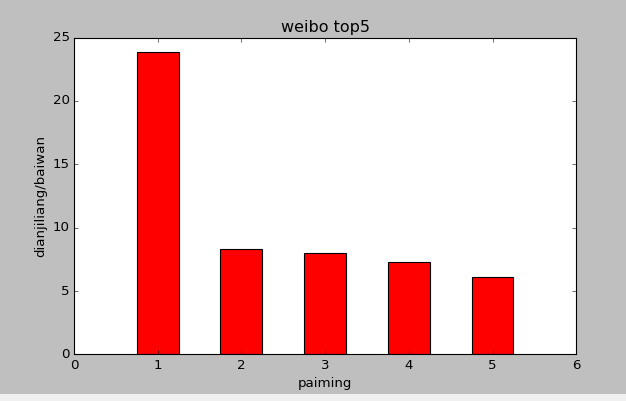
import matplotlib.pyplot as plt plt.figure(figsize=(6,4)) x=[1,2,3,4,5] y=[23.887431,8.304191,7.992173,7.264128,6.110506] plt.bar(x,y,width=0.5,align='center',color='r') plt.xlabel('paiming') plt.ylabel('dianjiliang/baiwan') plt.title('weibo top5') plt.show()
结果如下:
四、结论
1.经过对主题分析和可视化可以得知热搜的排行与差异
2.本次作业让我学习了学习了几个新的库
