
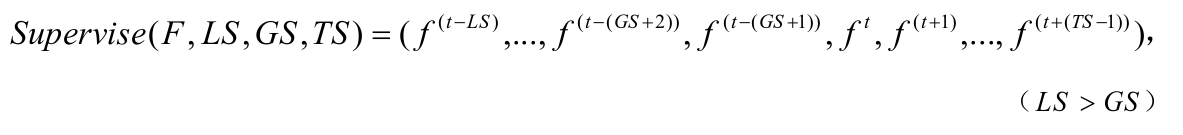
杂谈
-
基于transformer,目前都在研究什么:爆破块度分析、井下人员or安全帽等穿戴or异物 姿态检测/算法 【图像&视频识别】、“设备”知识图谱 的构建、时间序列(比如压力)预测、······
-
trm到底好在哪里?【所谓自注意力机制】
想象模型处理信息序列的过程,是你去认识一长排陌生人,传统RNN方法 你需要单个逐次去招呼、结识和记忆,当这队人很长时 后期的你会忘记最初几人的信息 即 “梯度消失”,同时这个过程过于缓慢,因为不是 “并行处理”。
现在,trm赋予你一副眼镜or anything that allows you to gain the ability to "filter other people's characteristics”,使你仅去获取各人自身的特征 和 各人与其他人的关系,你这时可以一次性查看所有人(input)、优先与你最想了解的对象 “交谈”(fetch),且忽略对话时的 “噪音”。
所以——我们想把这个思路试着引入到以往朴素传统的CBR方法中
-
介绍国内外的时候 分段简单展开一下前人手段+成果【传统?】【AI?】;列举完实验数据之后【和谁?】对比模型→强调你的误差更小;
-
搭建论文之外的平台?例如矿压分析预警 Python设计——可视化 来压、云图等等
-
在论述某个模型在某领域的已证实的应用价值时,可以举不限于能源行业的例子(金融?医疗?···)以丰富参考文献。
-
“支护”——支:支架,被动去抵抗围岩变形,支不住就会冒顶;护:掩护,构件,护不住就会塌方;支护:既要又要,锚杆、锚喷、锚注
发问
建库后筛选确定参数
创新性--把trm引入CBR
二者的结合主要可以出现在CBR的检索和重用两个阶段。具体来说,Transformer可以帮助增强CBR中某些步骤的处理能力,尤其是数据理解和相似度计算方面。
检索(Case Retrieval),
自注意力机制更好地捕捉历史案例和当前问题之间的潜在相似性。特别是对于文本型数据(如文档、对话历史等)。【参与组件】编码器部分可以对当前输入问题和历史案例中的文本进行编码,生成高维度的特征表示。
得益于self attention,trm理解和捕捉历史案例(如支护类型、锚杆长度等)的复杂特征。不同的煤矿作业场景具有不同的背景信息,Transformer能够关注到重要的细节(如地质条件、巷道类型、支护设计等),并找到当前问题与历史案例之间的潜在相似性。
重新利用(Case Reuse),
根据检索到的案例来解决当前问题。Transformer可以用于案例的改编和推理,特别是当问题的解决方案需要高灵活性的组合或创新时。【参与组件】解码器负责将编码的案例信息转化为具体的解决步骤或建议。
【扩展】存储和更新阶段(Case Storage and Update),trm自动生成标签或总结,辅助管理案例库的更新和维护。
即:trm依然保留了大模型的通用性,而在应用上展现出了对煤矿领域的适应性。
为什么做这个题目?
目的和意义
为什么要用这种方法?
检索阶段:trm通过生成的向量表示来计算当前问题与历史案例之间的相似度。这个方法相比于传统的CBR基于关键词或简单相似度度量的模型,能够捕捉更多的语义关系,提高检索的准确性和鲁棒性。
自注意力机制是Transformer的核心,它通过计算输入序列中每一元素与其他所有元素的关系,生成每个元素的上下文向量表示。具体来说:
- 每个输入元素(如一个词或一个特征)会生成三个向量:Query(查询向量)、Key(键向量)Value(值向量)。
- 查询向量和键向量之间的相似度决定了该元素在生成输出时对其他元素的关注程度。通过这种方式,模型能够在处理某个输入时自动选择哪些其他部分的信息最为相关。
- 最终的输出向量是通过加权平均其他元素的值向量得到的,这些权重是基于查询和键的相似度计算得出的。
trm的好处:㈠ 捕捉到词汇或特征之间的长距离依赖关系。这意味着即使两个案例或问题中的关键词没有完全相同,它们的潜在语义关系仍然可以被捕捉到。㈡ 地质条件、巷道形态这种复杂的依赖关系,Transformer能够通过向量表示精确地捕捉。
CBR的坏处:㈠ 关键词或特征值的简化处理会丢失文本或数据中的深层次语义和上下文。㈡ 结构化数据(如表格数据csv or Excel),常使用欧氏距离
重用阶段:传统方法通常需要手动设定规则或采用简单的组合方法,我们更具灵活性和创新性
跟别人不同的点是什么?
为什么别人没用/你的这种方法?
发言提纲
各位老师好,我是来自系统理论专业23-4班的xxx,我的论文题目是《》,指导老师xxx。下面我将从以下4方面向各位评审老师做出介绍。一、背景和意义,选择这个题目主要两方面原因。一方面发现xx在xx上存在一定问题。······
挑战
在CBR中,除了文本数据,还可能涉及到结构化数据(如数值、时间序列数据等)。这时,可能需要将Transformer与其他模型(如图神经网络或传统的基于距离的度量方法)结合使用。
开题报告
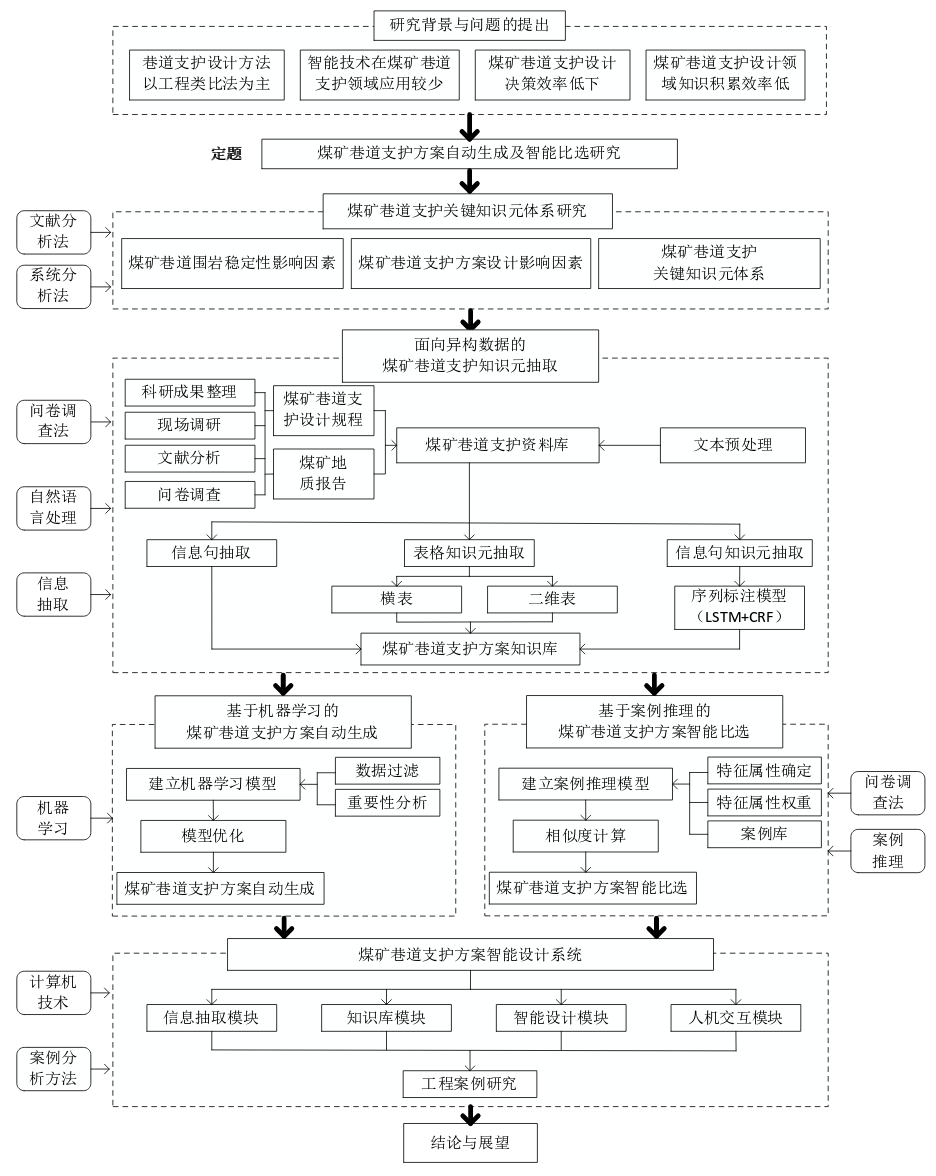
基于地质注意力增强和案例推理方法的巷道支护优化设计研究
K1、立论依据
1.1、课题来源、选题依据和立论背景
围绕 安全 和 高效 两个煤矿行业的永恒主题展开:
当今采矿业,特别是在设计煤巷支护系统,目前主要依赖工程类比或基于经验的方法。虽广泛应用,但有时无法确保所选方案的最佳效果,一说因支护力度不够而需二次加固,其次或因支护过度而导致资源的不必要浪费;另外,随着浅部煤层的开采减少、大部分转向深部开采——开采难度和强度的增大,设计有效的巷道支护系统至关重要。
关于转为深部开采:
每年正以 10 米左右的速率向深部发展,付凌晖,刘爱华 总编.中国统计年鉴[Z].中国统计出版社,2022.
带来了什么:地质条件变差,支护难度加大,这超出了以往的经验范畴
利用机器学习和数据分析技术,分析和预测巷道支护的效果,以提高矿区支护设计的效率;以本方向(巷道支护)发生的煤矿事故为例:
- 2021年11月10日,贵州六盘水猴子田煤矿顶板事故,造成4人死亡,直接经济损失744.4万元。发生原因:110702回风联络斜巷处于地质构造带,巷道超高不易支护,作业人员空顶维修作业导致顶板失稳、冒落。
- 2024年11月1日,陕西永寿县碾子沟煤矿,进行超前支架顶梁调架千斤顶连接作业时1人死亡。发生原因:副帮超前支架突然倾斜,地质调查和力学分析不详,致使支护结构不能适应复杂多变的地下环境。
- 2022年8月4日,山西沁源凤凰台煤业3#煤层31采区3102胶带顺槽掘进工作面发生较大顶板事故,造成5人遇难,直接经济损失1982.28万元。发生原因:支护措施滞后、不足以承受顶板压力。
☞这些事故反映了巷道支护的实施和监测方面的隐患。事故频发及其带来的高额经济损失和人员伤亡表明,传统的巷道支护策略和技术在某些情况下未能有效预防顶板事故——即,基于现有支护技术的地质评估方法在应对复杂地质条件和高风险环境时的局限性。本文通过引入大数据分析、机器学习,尤其是借鉴了Transformer大语言模型构建一套Geo-Attentive Case-Based Reasoning(地质注意力机制的案例基模型,下文简称GeoAttCBR)来提供更精准的地质风险评估和实时的支护效果监测。
1.2、研究目的、理论意义和应用价值
☞围岩稳定性分类是巷道支护设计的重要参考依据,稳定性决定支护方式和支护参数。其中,支护方式是支护设计的结果。
☞大语言模型系统地分析和学习历史事故数据、地质数据以及巷道支护的实时数据,以期提高对复杂地质条件的响应能力、实现巷道支护设计的优化,减少人为的决策失误。研究的成果预期会测试、应用于矿业的安全管理实践中,通过改进支护技术和实施新的监控系统,显著提高矿工的安全和矿山的运营效率。首先是救人性命,其次是减少经济损失。
国家从顶层设计层面对“十四五”期间我国煤矿智能化建设发展进行部署,国家发改委等八部委联合印发了《关于加快煤矿智能化发展的指导意见》,意见提出:到 2035 年,各类煤矿基本实现智能化,构建多产业链、多系统集成的系统,建成智能感知、智能决策、自动执行的煤矿智能化体系
中国煤炭工业协会煤矿支护专业委员会. 中国煤炭工业协会煤矿支护专业委员会2020年度工作报告[R].2020.
意义还有以下:
-
使用传统类比法 或 经验分析法时 受到 人为因素的影响,但我们CBR依赖于历史案例和数据驱动的推理过程
-
比如 巷道返修 的频率,节约了 巷道维护 费用
-
尽管聚焦于煤矿,但具有广泛的潜力,可为其他工程领域提供理论和技术支持,具有较强的推广价值
K2、 数据收集/文献综述【n】
2.1国内外现状、发展动态
支护方式研究现状
- 逐渐从被动支护形式向主动支护形式发展,在澳、美、英等这些锚杆支护技术较为先进的国家,锚杆支护在实际应用中占据着极高比例(* 苏自约, 闫莫明, 徐祯祥. 岩土锚固技术与工程应用[D]. 北京: 人民交通出版社, 2004. )
- 目前煤矿巷道支护参数设计大多数以BP神经网络等传统机器学习方法为主
大方向
现今井下智能化建设在AI方向的发展迅速,广泛应用在优化能源使用及分配¹ 、实时收集数据² ³ 、制定或模拟救援方案路径⁴ 、钻探爆破和运输加工的过程控制⁵ 以及智能路由通信网络管理⁷ ⁸ 等一系列领域,
- [Wang Yan;Hu Hejuan;Sun Xiaoyan;Zhang Yong;Gong Dunwei.Unified operation optimization model of integrated coal mine energy systems and its solutions based on autonomous intelligence[J].Applied Energy,2022.]
- [Tongqiang Xia;Diao Li;Xiaolin Li;Xin Yan;J.G. Wang.A novel in-depth intelligent evaluation approach for the gas drainage effect from point monitoring to surface to volume[J].Applied Energy,2024(PB).]
- [程德强;寇旗旗;江鹤;徐飞翔;宋天舒;王晓艺;钱建生;.全矿井智能视频分析关键技术综述[J].工矿自动化,2023(11):4-24.]
- [张力文;Hu Haifeng;.基于Arduino的新型智能矿用搜救机器人设计[J].仪表技术,2022(03):23-26.]
- [赵振宇;张开加;董宇;.鑫岩煤矿井下煤矸分选与充填开采一体化系统设计[J].煤炭工程,2022(01):19-25.]
- [史光亮;王瑞君;孔祥宇;.多网融合下的煤矿应急广播通信系统设计与应用[J].煤炭技术,2023(11):251-254.]
- [赵晓明;.基于5G网络的庞庞塔煤矿智能矿山建设[J].江西煤炭科技,2022(01):207-209.]
本方向
巷道支护方面 有哪些应用了大模型的 既往研究?:【后期补全简述】
陈万辉等学者 展示了一个多层次、跨学科的研究方法,结合了数据科学、机器学习和传统工程技术。即在其研究中引入案例推理(CBR)和深度学习技术到巷道支护方案设计领域,开发了一个巷道支护方案智能设计系统,该系统通过实时分析和处理地质数据及支护历史案例,实现了支护方案的智能优化,且在内蒙古某矿进行的对比预测指标表明,该系统能有效提出与实际地质条件相匹配的支护方案,显著提高了支护设计的精确性和操作效率。
王佳明 引入信息抽取、机器学习和案例推理技术,对煤矿巷道支护方案自动生成和智能比选进行研究,实现煤矿巷道支护方案的智能设计,即:···
王向前 针对煤矿回采巷道支护参数设计的问题,采用案例推理(CBR)的方法构建了煤矿回采巷道支护智能决策模型,探讨了煤矿回采巷道支护案例的表示、案例检索及案例的修正等问题
采用遗传算法和人工神经网络建立了围岩稳定性分类预测模型。通过算例验证了该模型能在考虑多影响因素下准确地代表围岩稳定性影响因素与围岩类型之间的非线性关系,并预测出软岩巷道的围岩分类,从而为软岩巷道稳定性分类及控制技术提供参考依据。
[1]陈万辉, et al."煤矿巷道支护方案智能设计研究."工矿自动化 50.08(2024):76-83+90.doi:10.13272/j.issn.1671-251x.2024060044.
[2]王佳明.煤矿巷道支护方案自动生成及智能比选研究. 2023. 中国矿业大学, MA thesis.
[3]王向前,and 孟祥瑞. "基于CBR的煤矿回采巷道支护智能决策系统研究与实现". 第十届全国煤炭工业生产一线青年技术创新文集. Ed.安徽理工大学;, 2016, 132-140.[4]张士科, et al."基于遗传算法和人工神经网络的巷道支护研究."煤炭与化工 39.01(2016):1-4.doi:10.19286/j.cnki.cci.2016.01.001.
2.2文献查阅范围/手段;参考资料
本文主要借助山东科技大学图书馆、超星数字图书馆等各级图书馆、相关书籍、资料、光盘检索以及互联网等渠道,查阅有关机械产业、矿山行业和人工智能领域的期刊、杂志和书籍,并通过中国期刊论文库、博硕论文库、EI(工程索引)数据库及现场调研等获取目前国内外相关领域的研究报告和文献。
广泛收集国内外矿区公开发布的巷道描述及其支护参数,包括支护类型、材料、尺寸、地质条件、巷道尺寸、支护效果等;对收集来的数据进行清洗和预处理,确保形成数据库的质量和一致性
其中,考虑到榆林地区、鄂尔多斯等地区煤炭资源丰富,煤层赋存稳定较易开采,形成了以神华集团为代表的现代化开采企业,以大规模高强度开采为特点,煤炭产量持续快速增长,故着重选取该地煤矿数据样本。然而,这些地区煤层埋深情况复杂、部分工作面采掘推进速度较快,矿区形成巨大开采空间。采动应力场使得工作面矿压显现特征明显,频繁发生顶板切落、支架冲击载荷等灾害。
K3、研究内容、技术路线、创新点
我们想干什么?——样本数据进行分析和学习,建立一个多元输入多元输出的非线性映射模型,实现方案自动生成
| port | types | parameters |
|---|---|---|
| 开采参数 | 埋深、采法(1炮采2普采3综采4综放)、柱宽、年限 | |
| 顶板参数 | 直接顶/老顶 厚、抗压、弹性模量、泊松比 | |
| 煤层参数 | 煤厚、倾角、内摩擦角 | |
| input | 底板参数 | 同上 |
| 断面参数 | 形状、面积、宽/高 | |
| 地下水 | 涌水量(正常) | |
| 地应力 | 垂直/水平 | |
| ==== | ======== | ============ |
| 支护方式 | 即支护方式 | |
| output | 锚杆参数 | 类型、直径、长度、间距、排距 |
| 锚索参数 | 同上 |
3.1研究内容/解决的关键技术
煤矿巷道支护方案设计不仅与地质参数相关,也与埋藏深度、断面尺寸、层间距、地下水等密切相关,这是一个庞大的系统工程,变量间的关系很难用一个公式表达清楚。然后,机器学习方法单纯从抽取存储的知识库数据出发,通过自组织学习能力深挖知识元之间的潜在规律和特征,同时还可将开采情况、断面情况、工程地质条件以及地应力条件等作为算法的输入参数进行考虑,为方案自动生成研究提供了新的路径。
通过对这些文本信息进行处理和分析,能够实现领域知识的自动识别和抽取。随着这些技术的高速发展以及对矿山建设行业的交叉渗透,代替人工挖掘数据价值,在保障安全的前提下实现效益的最大化
深度学习(是机器学习的一个子集,即 所有深度学习都是机器学习,但不是所有机器学习都是深度学习)
门控RNN模型按顺序处理每一个标记(token)并维护一个状态向量,其中包含所有已输入数据的表示。如要处理第n个标记,模型将表示句中到第n−1个标记为止的状态向量与最新的第n个标记的信息结合在一起创建一个新的状态向量,以此表示句中到第n个标记为止的状态。从理论上讲,如果状态向量不断继续编码每个标记的上下文信息,则来自一个标记的信息可以在序列中不断传播下去。但在实践中,这一机制是有缺陷的:[梯度消失问题]使得长句末尾的模型状态会缺少前面标记的精确信息。此外,每个标记的计算都依赖于先前标记的计算结果,这也使得其很难在现代深度学习硬件上进行并行处理,这导致了RNN模型训练效率低下。
-
它的状态向量理论上包含了输入序列的所有重要信息,使得模型可以基于这个累积的信息生成输出。LSTM的这种设计使得它必须在处理完整个输入序列后,才能得到一个全面的状态向量,用于后续的翻译过程。
-
[ ]
3.2技术路线/可行性分析【重点】
可行性!
解码器介入的CBR相似度计算!
目标是将历史案例(例如煤矿作业规程、地质报告等)映射到一个向量空间,然后计算当前问题和历史案例之间的相似度。
将案例数据转换为适合Transformer输入的格式(例如,文本数据转化为token)。训练一个标准的Transformer编码器,主要任务是让编码器学习如何将输入数据映射到合适的向量空间。使用向量空间中的相似度度量方法(如余弦相似度、欧几里得距离等)来比较案例之间的相似度。
- 实现简单,训练过程相对直接。
- 更容易理解和调试,适合需要快速验证的课题。
- 可以很好地解决基于案例相似度的检索问题。
- 控制模型的复杂度,降低过拟合的风险,尤其是在数据量有限的情况下。
撰写方面的可解释性!
透明,容易进行调试和分析尤其是在说明模型的推理过程、结果解释时
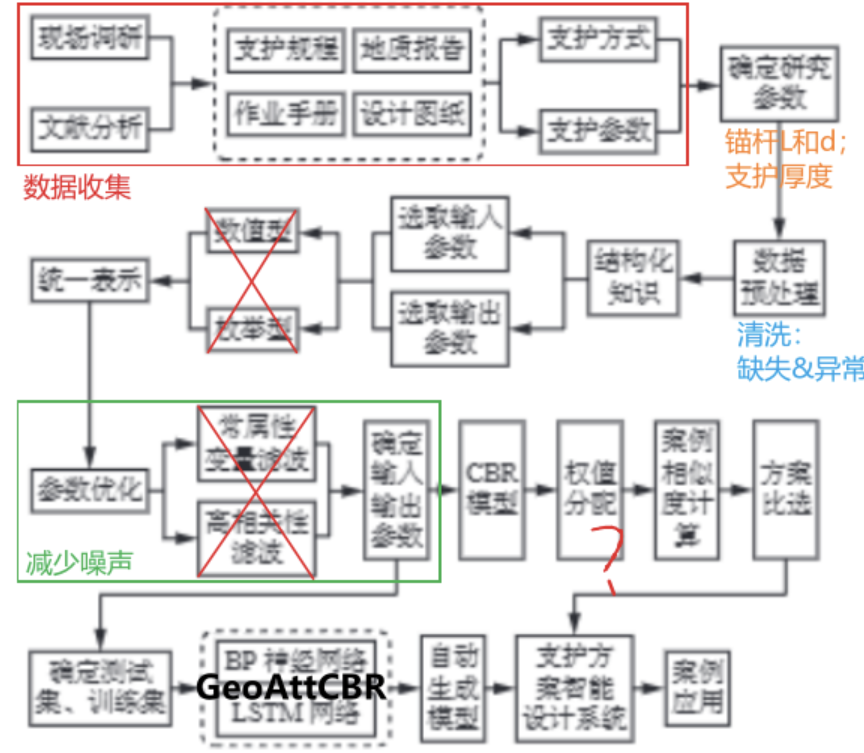
初期构想的技术路线
如下:
首先通过期刊杂志、书籍教材、论文文献、现场调研、科研汇报、研究报告等途径,得到《支护规程》、《地质报告》、《作业手册》、《设计图纸》等材料,收集其中案例的支护方式及其参数(统一为CSV、Excel等格式,并且做到格式规范化和标签化)。接下来确定研究的对象参数,对确定出来的数据进行预处理(清洗、去噪、填补、剔除)。然后选取出输入参数、输出参数,通过某种方式得到向量状态下的“统一表示”,使其机器可理解的数据。再使用“常属性变量滤波”、“高相关性滤波”等方法,对此时状态下的数据进行一定的优化。接下来建立含有transformer解码器参与的CBR模型,分配权值,并且对案例计算相似度,比选不同的方案。确定好测试集和训练集,在GeoAttention-CBR架构(暂定名称,意为“基于地质注意力的案例推理模型”)下验证、推广等,因为数据集较小,考虑使用交叉验证(cross-validation)来评估模型性能。注意,在技术路线的全过程中,注意全局的各个环节都要收集反馈,并基于这些反馈来调整最终模型的结构和优化方法。
?机器理解的是什么样子的数据?
比如现在csv/Excel里的形式:
| 煤厚 | 工作面埋深 | 锚杆长度 | 支护厚度 | 支护类型 |
|---|---|---|---|---|
| 5 | 300 | 10 | 20 | 锚杆 |
| 6 | 250 | 12 | 22 | 锚杆 |
| 7 | 350 | 15 | 25 | 钢拱 |
各值发生转换(例如煤厚除以5;锚杆定义为“1”)得到一维向量[1,0.6,10,20,1],这个特征向量就是机器能理解的形式。
另一种构想路线如下:
-
数据怎么来?现场测量、工程报告或设计图纸等等应收尽收
-
结构化格式,CSV或Excel表格,其中每列代表一个变量(如锚杆长度L、直径d和支护厚度H),每行代表一个观测实例
-
数据清洗:缺失值——删除?填充?;异常值——箱型图识别
-
什么叫“结构化知识”、“统一表示”:就是将所有数据源合并到一个单一的数据库或数据框架中【围岩库】,确保每个参数都遵循相同的命名约定和数据类型
-
减噪阶段的二次优化意义何在?
- 再次提升数据质量,减少无关特征和冗余特征,移除无用的常量特征和高度相关的特征,可以减少模型训练和预测时所需的计算资源,加快模型的训练和预测速度;同时,降低过拟合的风险,尤其是在数据量不是特别大时,减少特征数量可以帮助模型泛化到新的数据上。
- 提到的常属性变量滤波(Constant Attribute Filtering)、高相关性滤波(High Correlation Filtering)什么意思?
- 前者CAF涉及识别并移除那些在整个数据集中具有相同值的属性或变量。这些常属性变量对于建模来说没有信息价值,因为它们不提供任何有助于区分数据记录的有效信息。也就是说,移除这些变量可以减少数据的维度,提高计算效率,同时避免模型训练时的过拟合问题。
- 后者HCF用于检测并处理高度相关的变量。当两个或多个变量之间的相关性很高时,意味着它们携带相似的信息,并可能导致多重共线性问题。
- 减噪处理 这一步还可以用什么技术?除了这里提到的CAF、HCF
- 随机森林(本身对超参数的设置没那么敏感)、递归特征消除RFE(支持向量机SVM)、Lasso回归(正则化惩罚)或者两两集成(计算量太大!)
-
本文确定要研究的参数是谁?怎么确定?
-
假设数据集包含以下:
其中锚杆长度L和直径d、支护厚度H与支护失败率P有较高的相关性则这三者就是要研究的参数
-
-
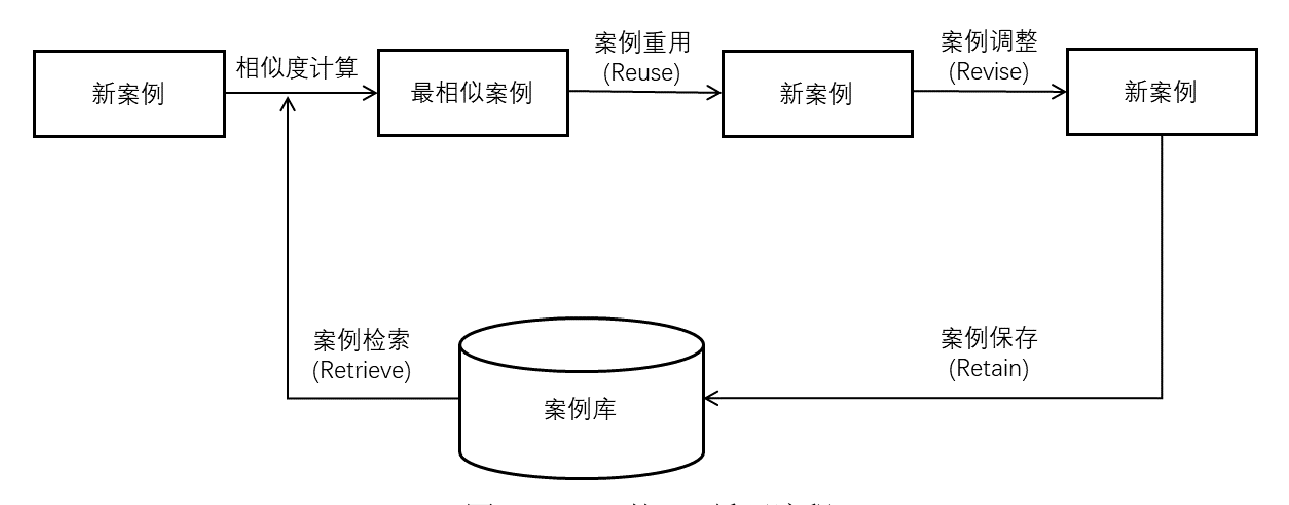
CBR(“基于案例的推理”模型,Case-BasedReasoning)是怎么回事?
- input是那些【将被用来识别和检索相似案例的特征】,比如L、d、H等等,共同构成了案例的描述,使得CBR系统能够根据给定的新场景或问题找到历史数据库中最相似的案例。
- output是CBR模型【解决问题后提供的结果】,通常是基于历史案例的解决策略。在巷道支护的场景中,本文预期的输出参数包括:
- 推荐的支护方案:基于找到的相似案例推荐的支护技术和方法。
- 预期的稳定性或风险评估:对所推荐支护方案在当前地质和工况条件下的预期性能的评估。
- 成本估算:基于历史数据估算实施推荐支护方案的大致成本。
-
“分配权值”
-
顾名思义,如果某个参数(如支护厚度H)对支护效果的影响比其他参数(如锚杆的L、d)更为显著,那么支护厚度在相似度计算中应该拥有更高的权重。
-
CBR流程中,,权值在什么步骤出现?
-
分权在CBR中是必需的吗?
如果所有特征都同等重要,或者数据非常均匀,且没有明显的个别特征对结果影响更显著就不必需;反之,多数实际应用中,特征差异性大就必需
-
一个加权的CBR例子:
设现有以下两矿井,其支护: 矿井A 地质条件:软岩,多裂隙 巷道尺寸:高 3 米,宽 4 米 支护类型:锚杆支护 锚杆长度:1.5 米 锚杆直径:25 毫米 支护厚度:200 毫米 支护间距:1 米 矿井B 地质条件:硬岩,少裂隙 巷道尺寸:高 3 米,宽 4 米 支护类型:锚杆支护 锚杆长度:2 米 锚杆直径:30 毫米 支护厚度:250 毫米 支护间距:0.8 米需要对以上特征进行编码和标准化处理,以便进行数值计算;为不同的特征分配不同的权重,反映它们对支护效果的影响程度。假设权重分配如下:
地质条件(软岩=0, 硬岩=1):权重 0.3
锚杆长度:权重 0.2
锚杆直径:权重 0.1
支护厚度:权重 0.2
支护间距:权重 0.2
加权欧氏距离公式计算此处两个案例之间的相似度,公式,
w是权重weight,x是两例中特征i的各自值:
$$
Distance
=√[∑(⋅(−)2)]
$$
-
-
[ ]
具体到本例中,
地质条件差异:0.3×(0−1) 2=0.3
锚杆长度差异:0.2×(1.5−2) 2=0.02
锚杆直径差异:0.1×(25−30) 2=2.5
支护厚度差异:0.2×(200−250) 2=200
支护间距差异:0.2×(1−0.8) 2=0.008
总相似度距离为:TotalDistance=√(0.3+0.02+2.5+200+0.008) ≈ 14.15
本例的实际意义:较低的距离值表示较高的相似度。在这个例子中,计算得出的距离较大,表明两个案例在支护特性上有较大的差异,特别是在支护厚度和锚杆直径上。基于这种计算,如果矿井A的支护方案已知有效,而矿井B的条件相似但具有一些关键差异,则可以考虑调整矿井B的支护设计以适应其特定的地质和结构条件。
3.3论文的创新点【重点】
-
将transformer的嵌入层自注意力机制的 线性变换思路,引入CBR的传统相似度计算里,提高相似度计算的准确性和模型的解释性。
-
辅助现场技术人员 根据相似巷道的支护方案 对目标巷道的初步设计方案 进行优化和比选。
-
about--知识元抽取:
-
首先,通过科研成果整理、现场调研、文献分析和问卷调查等方式获取了xxx份煤矿巷道支护资料,对煤巷支护资料的文本特征进行解析,
-
针对知识元存储方式的不同,构建了面向异构数据的煤巷支护知识元抽取体系
-
然后详细介绍了信息句抽取的方法
先是信息句触发词集和信息句正则规则的制定,在此基础上通过规则匹配的方式抽取到符合条件的信息句,为下文的信息句知识元抽取提供预料支撑
-
在知识元抽取方面,先是描述了表格知识元的抽取方法,根据知识元所存储的表格特征,将表格分为两种类型:
横表和二维表,采用标题规则和Python的docx库设计不同的抽取方法,有效抽取了两类表格中的知识元
-
然后构建序列标注模型对信息句中的知识元进行抽取。
-
考虑到抽取对象是煤巷领域,构建领域知识词典,并应用于中文分词任务和触发词拓展
-
构建了基于LSTM+CRF算法的序列标注模型;在模型训练阶段,使用BIOES编码方式进行标注,标注完成后对模型进行训练,从而实现了对信息句中的25个知识元字段的信息抽取,并对不同知识元字段的抽取结果进行详细分析
-
最终实现了对信息句、表格和信息句知识元的抽取,为接下来的方案自动生成和智能比选提供数据支撑。
解码器介入的CBR相似度计算!
目标是将历史案例(例如煤矿作业规程、地质报告等)映射到一个向量空间,然后计算当前问题和历史案例之间的相似度。
将案例数据转换为适合Transformer输入的格式(例如,文本数据转化为token)。训练一个标准的Transformer编码器,主要任务是让编码器学习如何将输入数据映射到合适的向量空间。使用向量空间中的相似度度量方法(如余弦相似度、欧几里得距离等)来比较案例之间的相似度。
- 实现简单,训练过程相对直接。
- 更容易理解和调试,适合需要快速验证的课题。
- 可以很好地解决基于案例相似度的检索问题。
- 控制模型的复杂度,降低过拟合的风险,尤其是在数据量有限的情况下。
K4、研究基础
4.1实验手段、研究和实验条件
性能瓶颈
由于煤矿作业涉及到大量的参数(如地质数据、作业条件等),在使用Transformer进行案例检索和推理时,高维数据可能会引发性能瓶颈。通过【“常属性变量滤波”、“高相关性滤波”】去除冗余特征和高相关性特征,可以有效减少模型的输入维度,提高Transformer模型的处理效率。
【Constant Attribute Filtering】如果某些参数(如某种支护类型或作业方式)在所有历史案例中始终相同,那么这些参数可能不需要被考虑。比如,大部分历史案例都使用了相同的锚杆长度,而这个长度与作业场景并无太大差异
【High Correlation Filtering】例如,某些地质条件、支护类型和材料强度之间可能存在高度的相关性。如果支护的具体类型与材料强度之间高度相关,并且这两个变量在模型中传递的是类似的信息,那么可以通过去除其中一个变量来减少计算负担
建数据库
支护资料获取
-
科研成果
- 一线公司、矿井:提取典型
-
现场调研
-
实际案例《作业规程》《地质报告》《作业手册》
支护规程:通常包括八大章节,分别为第一章概况、第二章地面位置及地质情况、第三章巷道布置及支护说明、第四章施工工艺、第五章生产系统、第六章劳动组织与主要技术经济指标、第七章安全技术措施、第八章灾害应急措施及避灾路线;
煤矿地质报告 一般:没有统一的格式,各矿区通常存有较大的差异,但
对围岩和煤层的相关力学参数的表达方式大体相同
-
-
书籍、论文分析
- 查阅:全面性
-
问卷调查
- 面向生产人员发放:以确保普遍性
通过以上方法,本文共收集了612份关于煤矿巷道支护的资料,这些资料来自于内蒙古、山西、山东、安徽、贵州等地。经初步筛查发现,
从支护类型上看,
从存储格式上看,
(DOCX、 PDF和DOC的格式存储。为保证对煤矿巷道支护资料的高效处理,本文全部采用结构化管理形式,一方面,利用python将所有DOC格式转为DOCX格式存储,另一方面,再利用python将所有PDF资料转化为WORD文档,并以DOCX 格式存储。
围岩分类现状
根据岩石的坚硬程度和岩体完整程度给出岩体基本质量级别,然后根据地下水情况、软弱结构面情况以及初始应力等对基本质量值进行修正,最终获得岩体级别的校正结果。(申艳军, 徐光黎. 国标岩体分级标准BQ的图解法表示[J]. 岩石力学与工程学报, 2012,31(S2):3659-3665.)
$$
S=
\frac{γH}{Rc}
$$

S、、分别代表围岩稳定性指数、围岩自重、单轴抗压强度
更适用于无明显构造应力且完整的岩体,而对于有明显构造应力或节理发育很明显的岩体则不适用。
本 稳定性指数分类法 将围岩稳定性分成三个等级:当围岩稳定性指数在0.25以下时为稳定,在0.25~0.40的范围内时为中等稳定,高于0.40且低于0.65时则为不稳定。
目前应用最广泛的煤矿巷道围岩稳定性分级方法,它以模糊数学理论为基础,通过建立隶属函数,并根据其计算出每个评价对象对整个评价值
的权重,然后再将所有被评估对象的权重加权求和得出最终结果
王哲哲等(2019)、张涛等(2020)、尹会永(2020)采用该方法研究煤矿巷道围岩稳定性分级,取得了较好的应用效果, 并通过仿真或现场实验进行了检验。
-
随机森林是一种用作预测和分类的机器学习模型,该算法以数据驱动方式解决小样本容量问题,能够较好地反映出不同类别间的差异性,因此被广泛应用于各个领域。
赵汝星(2014)搜集了部分矿井35条巷道数据,选取围岩强度、埋深、节理裂隙发育程度、巷道跨度、直接顶与煤层厚度之比和松动圈厚度六个指标构建随机森林模型进行回采巷道稳定性分类,同时与决策树、BP神经网络等模型对比,发现该模型在回采巷道围岩稳定性分类方面具有更好的效果。邵良杉等(2018)构建了基于改进随机森林算法的回采巷道围岩稳定性分类模型,同时对影响煤矿巷道围岩稳定性的因素进行了重要性排序
-
支持向量机是一种机器学习分类算法,目前应用已经非常成熟。石永奎等(2015)分别建立支持向量机模型、决策树模型和朴素贝叶斯模型对煤矿围岩稳定性进行分类预测,通过粗糙集理论分析验证了七类影响因素,并从三个方面对模型效果进行评价,研究结果表明SVM分类方法在围岩稳定性分类中具有更好的表现。
-
最早由董方庭教授提出。当围岩强度小于围岩应力时,围岩四周将形成松动破裂区,即松动圈,其分布范围的大小综合反映了原岩应力、岩体性质及地下水等多种因素的影响,成为巷道围岩稳定性判定的综合性分类指标。
-
特殊情形下,仅使用单一方法难以实现准确分类。为此,许多学者提出了多种方法有效结
合的综合分类法。杨仁树等(2015)[ 26]综合运用模糊聚类法和层次分析法,实现了对煤矿巷道围岩稳定性的合理分类。王应帅(2015)[ 27]将工程岩体分级理论和专家评分法有效结合,对围岩稳定性进行分类,效果显著。
皮尔逊系数计算相关性
SPSS软件 得到统计图(颜色越深关系越高,即正相关or负相关)
模型调优
CBR循环流程如何与trm结合?
在训练集上训练模型,并在验证集上测试模型的性能,使用交叉验证(包括分类准确率、回归预测的误差等)来评估模型的稳定性和可靠性。
4.2经费,来源、开支预算
(工程设备、材料须填写名称、规格、数量)
K5、工作计划
| 序号 | 阶段及内容 | 工作量估计(h) | 起讫日期 | 阶段成果/形式 |
|---|---|---|---|---|
| ① | 材料收集 | |||
| ② | 建立数据库 | “统一表示” | ||
| ③ | 确定研究对象参数 | |||
| ④ | 数据预处理 | |||
| ⑤ | 二次优化减噪 | |||
| ⑥ | CBR建模 | 分配权值、相似度s | ||
| ⑦ | 测试集、训练集的验证及推广 | |||
| 合计 |
附件:评分表、评审小组和意见(略)
开题报告(优先)
注
以下内容编辑时间较早,不及前文更新及时,故参考意义有限,下文 仅节选以示学习了部分文献的数据处理手法 等
论文架构(再议)
0.1摘要
0.2目录
0.3附表清单\插图清单
1绪论
1.1研究背景、意义
1.2国内外研究现状
1.3论文研究内容、论文组织结构
2.XX(数据/预/处理)方法
介绍[预处理的必要性]:由于传感器的灵敏度会受到空间环境温度、湿度等因素的影响...这些异常数据会阻碍模型提取时间序列数据的特征, 影响机器学习模型的“学习”能力...
"实验数据来自XX省某煤矿的工作面XX年X月X日至..的监测数据.."
a0xx数据的分布特征
介绍数据产生的地理环境、条件,简要交代数据形成的原理,可附【工作面测站布置图】【数据能否分类?分别作图?】···
a1异常值的修正:
3σ原则
...井下传感器可能会工作异常,导致传感器记录数据出现重大误差。同时,为了保证传感器的正常工作,煤矿工作人员会定期对传感器进行调校...
给数据示例!处理过程
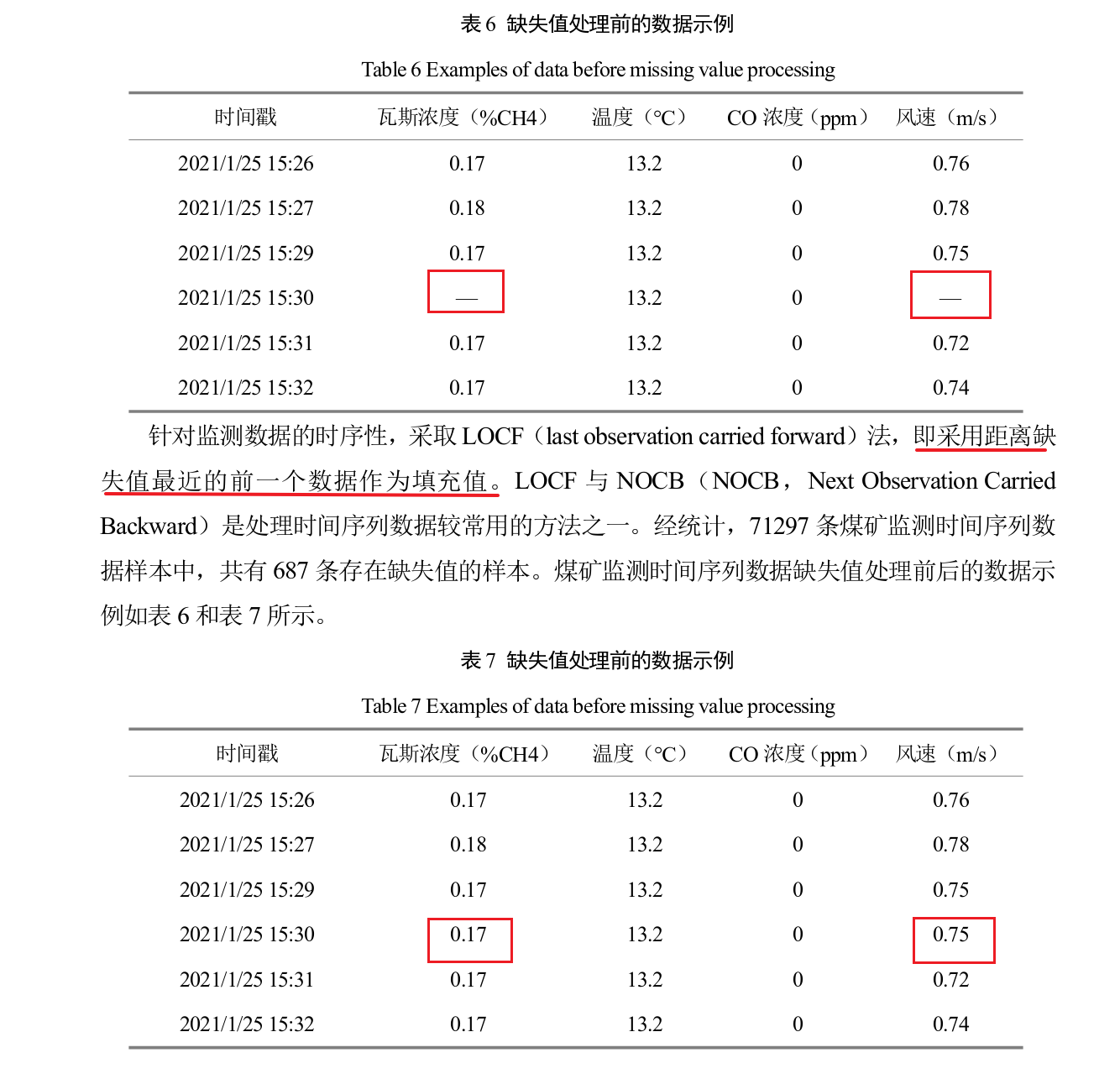
a2缺失值的处理:
1直接delete//2基于统计学的填充(前两者都忽略时间性)//3基于机器学习的K最近邻\RNN\最大期望\矩阵分解 等
...传感器采集出错的现象,导致数据缺失。时间序列数据的缺失会使得缺失值前后的数据时间关联性变弱,数据误差变大,影响模型的训练效果...
给数据示例!处理过程
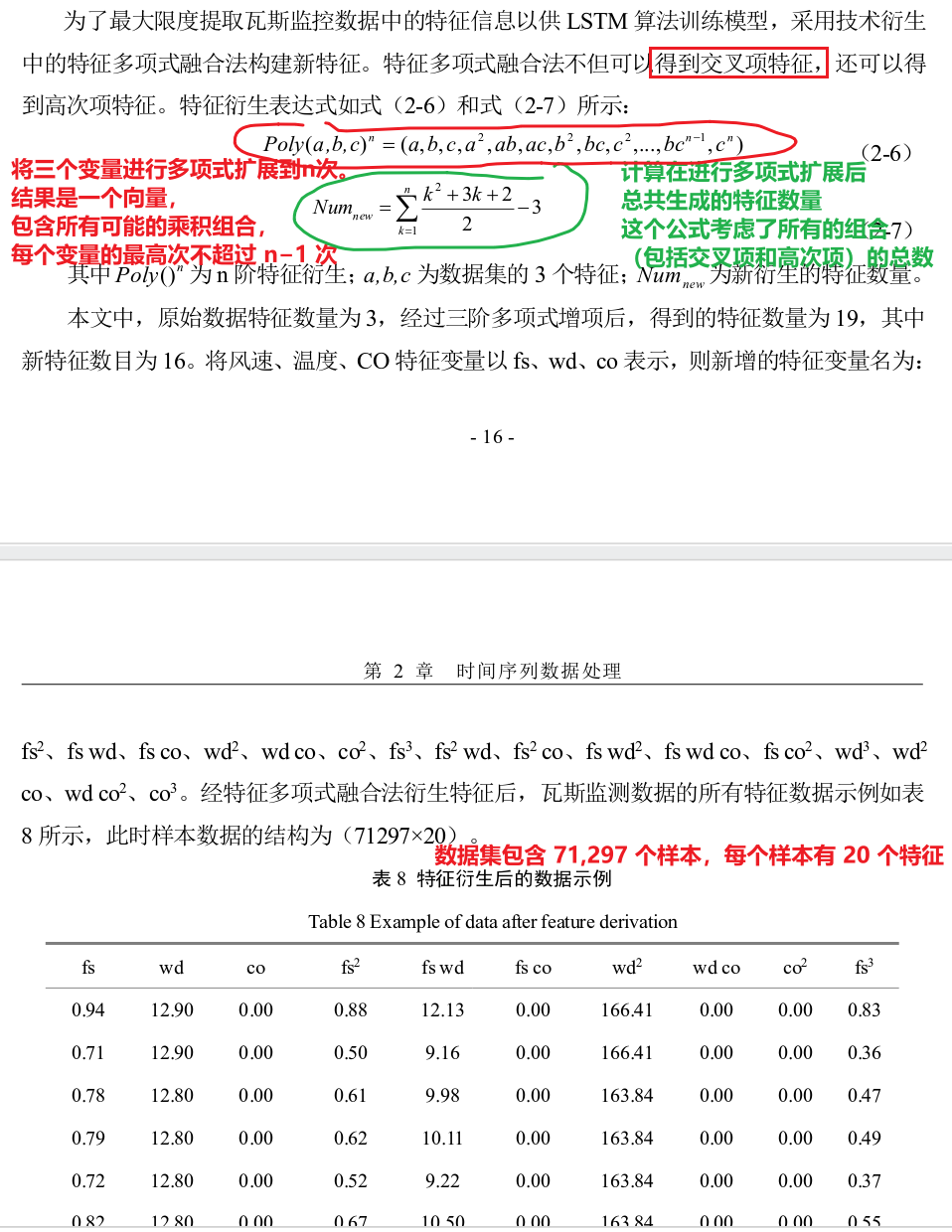
b特征工程
为什么要搞特征工程?数据挖掘中的数据和特征中包含的信息决定了机器学习获取知识和技能的上限,而各种模型和算法的应用是为了能够更大限度地提高学习性能,从而使得学习能力逼近上限。因此对原始数据中的特征处理是非常必要的。通过获取更多的、更好的特征,可以减少模型寻找最优参数的工作量和时间。
检测数据特征衍生:
例子:计算每小时的平均瓦斯浓度、最大值和最小值等来衍生新特征。此外引入滞后特征,例如,将前1小时、前2小时和前3小时的瓦斯浓度作为新的特征,以帮助模型捕捉浓度变化的趋势和模式
时间序列的有监督化:
例子:假设我们有一段时间的瓦斯浓度监测数据,目标是预测未来1小时的瓦斯浓度。选择过去6小时的数据作为输入特征(t-6, t-5,..., t-1的瓦斯浓度),而当前时刻的瓦斯浓度(t)作为输出标签
特征无量纲化:
例子:在训练模型时,瓦斯浓度原始数据范围很大(例如0到1000 ppm),而其他特征(如温度或湿度)的范围则很小(例如0到100),导致模型训练时难以收敛。所以对瓦斯浓度和其他特征进行Z-score标准化或Min-Max归一化,使所有特征在同一范围内,提高训练效果稳定性
以“瓦斯时间序列数据的特征分析”为例:
工程一:衍生

工程二:有监督化
- F (Forecasting Period) - 预测期:想要进行预测的未来时间点。
- LS (Lag Step) - 滞后期步长:从当前时刻往回看多少时间步长来作为输入特征的基础。
- GS (Gap Step) - 空档期步长:向前或向后设置的一个时间间隔,用于定义开始预测的起点。
- TS (Time Step) - 时间步长:预测未来多少个时间步长的数据。
在公式 Supervise(F, LS, GS, TS) 中:输入为一系列的历史特征 f(t-LS), f(t-(GS+2)) 至 f(t-(GS+1)),和未来的目标数据 f(t), f(t+1) 至 f(t+(TS-1))。
这里,t 是当前时间点。
历史数据从 t-LS 开始,意味着从当前时间往回看 LS 个时间单位。
空档期从 t-(GS+2) 到 t-(GS+1),这是在当前时间点前后(下例中是后)的一个时间间隔,用于处理时间序列中的信息间隔问题,确保不会用到未来数据预测未来。
预测目标是从当前时间 t 到 t+(TS-1) 的数据,即从现在开始的未来 TS 个时间步的数据。

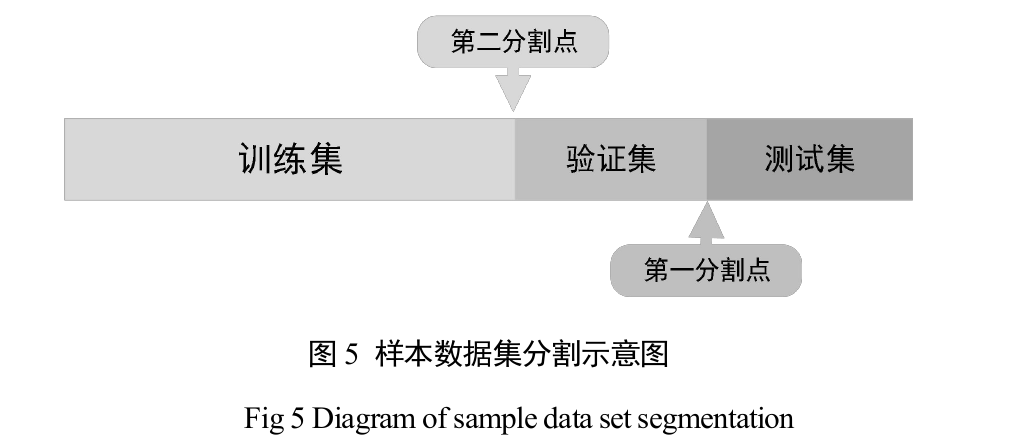
c数据集划分:
时间序列数据是按时间顺序排列的,因此在划分数据集时,不能随机分割(比如将数据随意打乱
2.? 本章小结
3.基于___模型的xx预测/xx分析/xx模拟?
3.1介绍模/网原理
3.2参数确定
3.3预测/分析/模拟 自己模型
3.3.1描述
3.3.2算法实现
3.3.3实验验证
3.4本章小结
4.总结与展望
4.1总结
总结研究成果,突出本模型在矿区安全管理中的应用价值。
4.2展望
如扩展数据集、改进模型或探索新的算法?
参考文献
附录
致谢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号