
三月三号 关于 个人版单机gpt / 公司级 大语言模型
个人用途的几种尝试
【个人·壹】ChatAlpha——搭建个人专属 gpt
本模块描述从零开发私有化版本的gpt网站,技术栈为
NextJS + TailwindCSS + chatgpt,NextJS作为 React 的全栈框架,能够快速搭建包含前后端的 React 应用。TailwindCSS则提供了较为便利的样式变量以及移动端的适配,最后通过 NodeJS 的API库chatgpt来调用 OpenAI 进行交互。
简介
ChatAlpha 是基于 ChatGPT 的在线智能对话平台,除包含基础的 AI 对话功能之外,还提供了图片生成、智能工具、角色扮演等多种不同的玩法。整个项目支持了用户注册登录及积分购买与付费功能,且所有的功能的 前端代码 均已开源,开发者可以通过该项目进行学习和二次开发。
实践
-
项目参考自搭建个人专属ChatGPT(零成本且不需要) - 掘金 (juejin.cn),但由于该笔记的作者或网站维护问题,在线demo以各种形式(包括在github里的完整代码源)都无法运行故暂不知其效果。
-
具体初始化该
NextJS项目:npx create-next-app@latest --typescript # or yarn create next-app --typescript目录结构概览:
├── README.md # 项目的README文件 ├── next-env.d.ts # 默认生成的next的ts环境引入文件(不需要关注) ├── next.config.js # next的配置文件 ├── package-lock.json # 项目的package-lock.json ├── package.json # 项目的package.json ├── pages # 项目的主要路径目录 │ ├── _app.tsx # 每个页面的入口文件 │ ├── _document.tsx # 每个页面的文档结构,相当于index.html │ ├── api # 项目的api接口处理(处理服务端接受的请求) │ │ └── hello.ts │ └── index.tsx # 单个页面的入口文件 ├── public # 静态资源目录 │ ├── favicon.ico │ ├── next.svg │ ├── thirteen.svg │ └── vercel.svg ├── styles # 样式文件目录 │ ├── Home.module.css # 使用module css的方式处理scoped样式 │ └── globals.css # 全局的样式必须在 _app.tsx 中引入 └── tsconfig.json # ts的配置文件实际开发中 引入
src作为主要文件目录,其中新增components存放组件、hooks存放自定义的 Hooks、service存放抽象出来的公共服务、store存放状态管理文件、utils存放一些公共的方法。 -
该教程的剩余目录结构如下,后续细节较多,此处不一一列举,建议跳转原文:(原文搭建个人专属ChatGPT(零成本且不需要) - 掘金 (juejin.cn))
【个人·贰】一种 基于Dify的 企业微信 知识库机器人
功能
- 上下文管理:通过Dify API和企业微信的上下文管理功能,机器人能够理解并维护与用户的聊天上下文。这意味着在同一会话中的连续消息可以共享上下文,允许聊天机器人理解和回应更复杂的问题。
- 用户独立会话管理:聊天机器人在企业微信群聊中为每个用户维护单独的会话记录,让机器人能更好地理解和回应每个用户的问题。
- 新旧用户会话处理:对于新用户,每次他们提问时,都会为他们创建一个新的会话。对于老用户,如果他们在私聊或群聊中提问,系统会使用他们之前的会话ID,保证上下文的连续性。
- 群聊@消息回复:在群聊中,机器人能够回复@它的消息,并在回复中@用户,让用户能够清楚地看到机器人的回答。
- 配置灵活:用户可以通过配置文件自由设置是否启用上下文管理,以及选择会话类型(每个消息都是新的会话,还是启用会话管理),以实现更灵活和个性化的机器人行为。
通过以上功能,这个聊天机器人能够提供具有上下文理解能力的智能对话服务,能够处理来自不同用户的私人聊天和群聊,适应不同的聊天场景和需求。
实际操作
-
登录dify官网
-
创建自己的应用
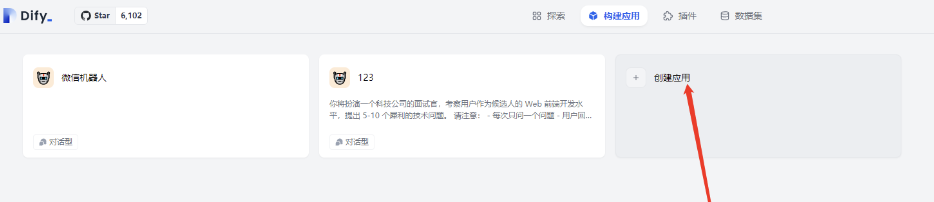
-
选择对话型应用
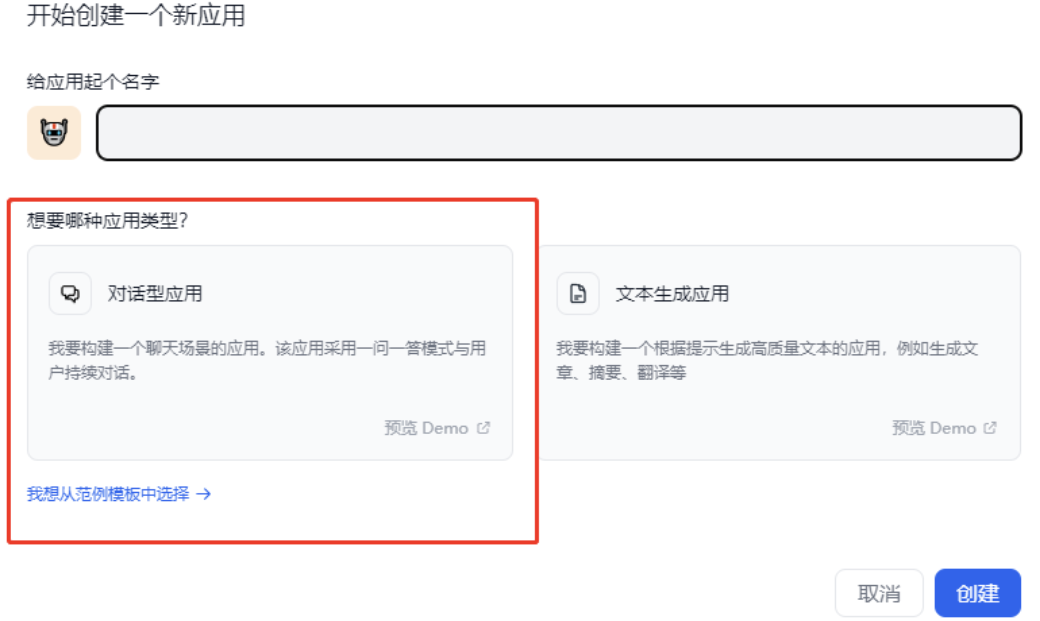
-
点击 构建好应用页面 的 api访问
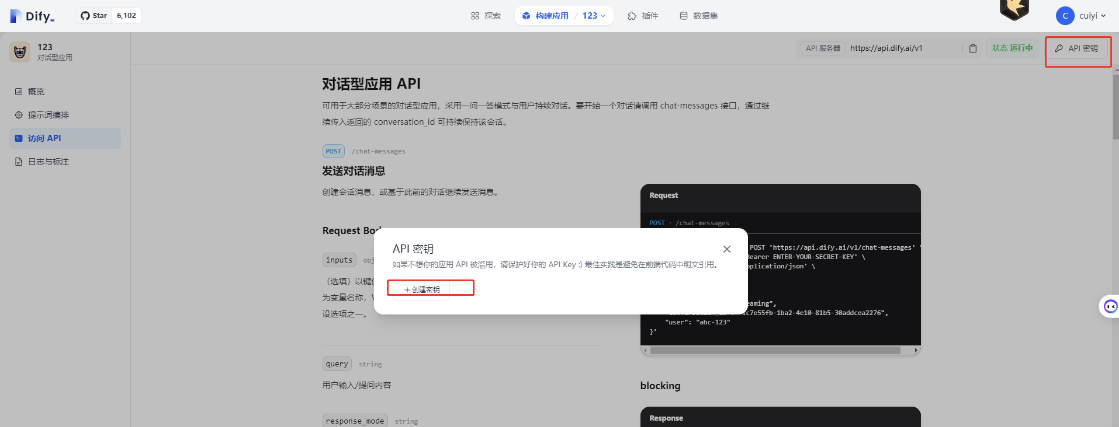
-
生成自己应用key
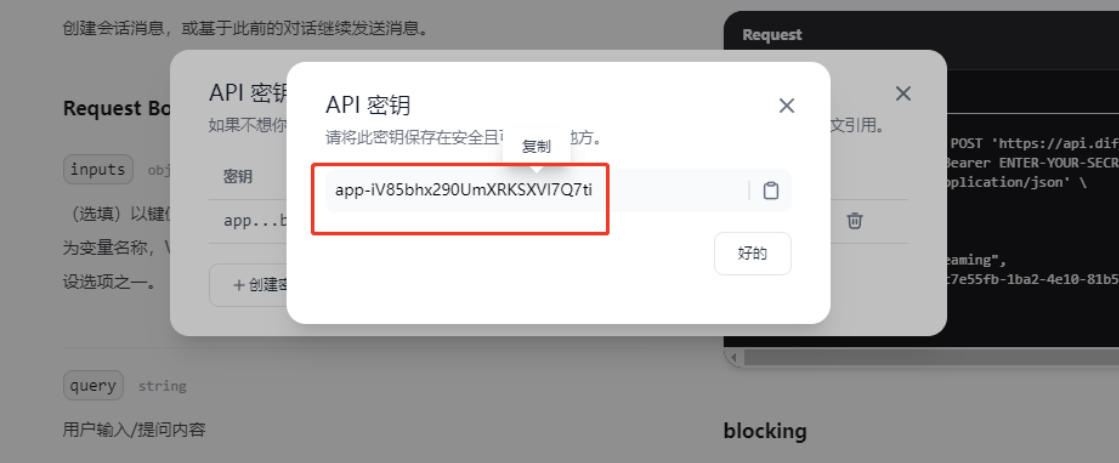
-
在 配置文件 中 写入自己dify的key
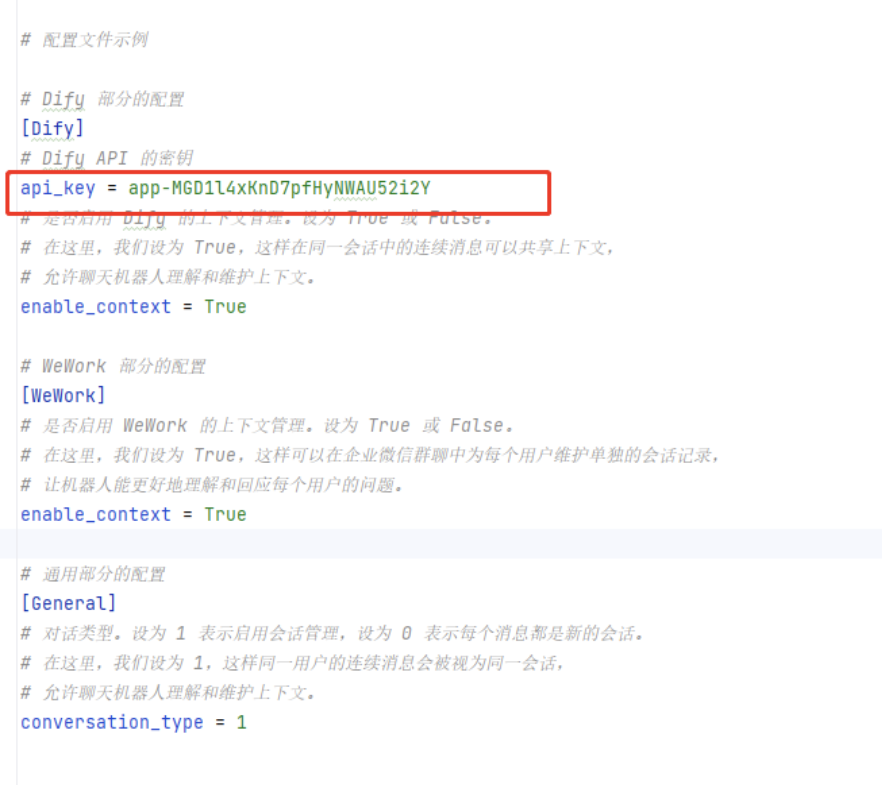
-
运行项目的app软件
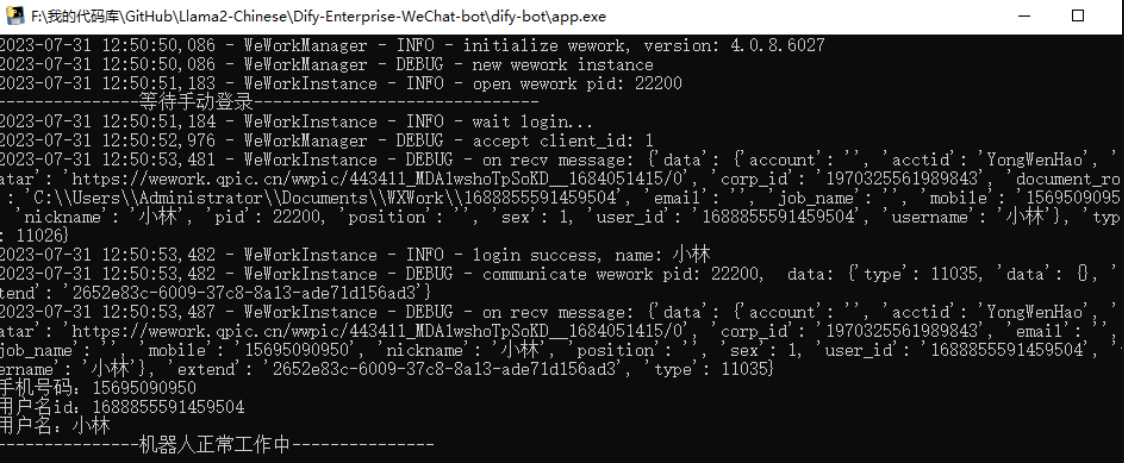
-
效果如图

备注
该文内容较少,原链接https://github.com/luolin-ai/Dify-Enterprise-WeChat-bot?tab=readme-ov-file
【个人·叁】一种 在云服务器上 搭建的 个人版chatgpt 及后端 springboot 集成
【国内服务器上搭建chat GPT】和【后端Spring Boot集成chat GPT】,两个方式都需要所在机器能够访问谷歌
国内服务器搭建GPT
准备
- 一台 可访问公网的 Linux 最低1核2G
- chatgpt的密钥
- 开源的chatgpt的docker镜像
设置网络代理
在/etc/profile增加代理,确保通过密钥方式的chatGPT接口调用能正常访问
export all_proxy=http://127.0.0.1:8889
export http_proxy=http://127.0.0.1:8889
export https_proxy=https://127.0.0.1:8889
export all_proxy=socks5://127.0.0.1:1080
8889和1080需要根据代理配置里的config.json来相应设置
安装docker、镜像
细节见原文
后端Spring Boot集成chat GPT
maven 依赖 引入配置
启动调用接口
细节均参考原文
参考源
以上此篇关于【国内服务器上搭建chat GPT】和【后端Spring Boot集成chat GPT】的教程 来自 在云服务器上搭建个人版chatGPT及后端Spring Boot集成chat GPT教程-腾讯云开发者社区-腾讯云 (tencent.com)
【补充建议】其他
Hugging Face(抱脸)
属性
是一个人工智能(AI)和自然语言处理(NLP)领域的开发者社区和平台。该网站提供了许多有关机器学习和自然语言处理的开源工具、模型和数据集。其中最著名的是其模型存储库,该存储库包含了各种各样的预训练(即 大规模的文本数据集、语言规律、语义理解等)语言模型
平台还提供了一种名为Transformers的开源库,该库包含了许多NLP模型(即 “自然语言处理Natural Language Processing”,nlp模型致力于 处理和理解自然语言,gpt就是一种nlp模型)的实现和预训练权重,方便开发者在自己的项目中使用这些模型
此外,Hugging Face也是一个社交平台,允许开发者分享和讨论他们的模型、代码和实验
备注
鉴于是全英文生态的网站,笔者在浏览和检索的时候都遇到阻碍,体验一般。
LLaMA (羊驼)
属性
是一个较受欢迎(和争议)的开源 大语言模型,出自扎克伯格的Meta。但目前由于LLaMA是英文原生模型,对中文的支持较弱,因此训练中文模型需要额外的训练和对齐。(汉语作为一种世界互联网中的“小众”语言(仅占总体量约5%),大模型构建时往往不会针对汉语进行设计,例如ChatGPT的汉语能力远弱于英文能力,而LLaMA词表中仅包含少量汉字,并且几乎没有在中文上进行训练)
本地化情况
①哈工大-科大讯飞联合实验室的 LoRA训练,但也处于靠后的位置;
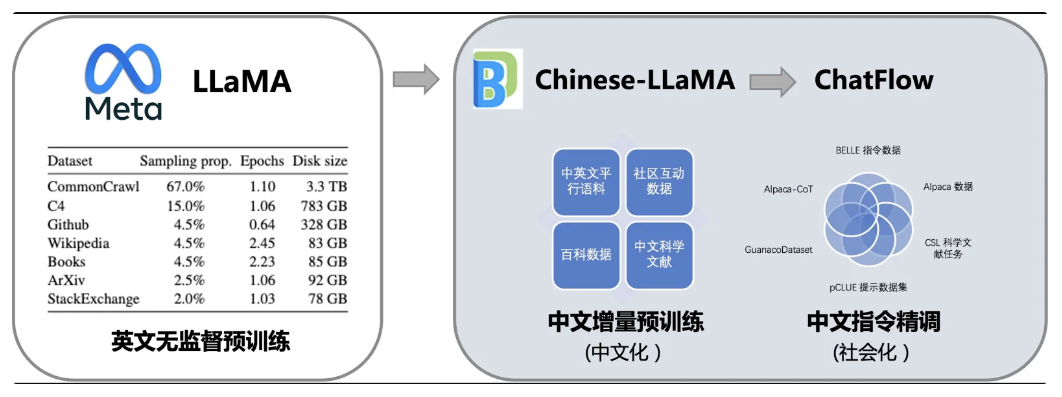
②深圳大学-大数据系统计算技术国家工程实验室的 对话模型 ChatFlow、基础模型Chinese-LLaMA。利用文本翻译数据,将LLaMA在英文上强大语言能力迁移到中文上:
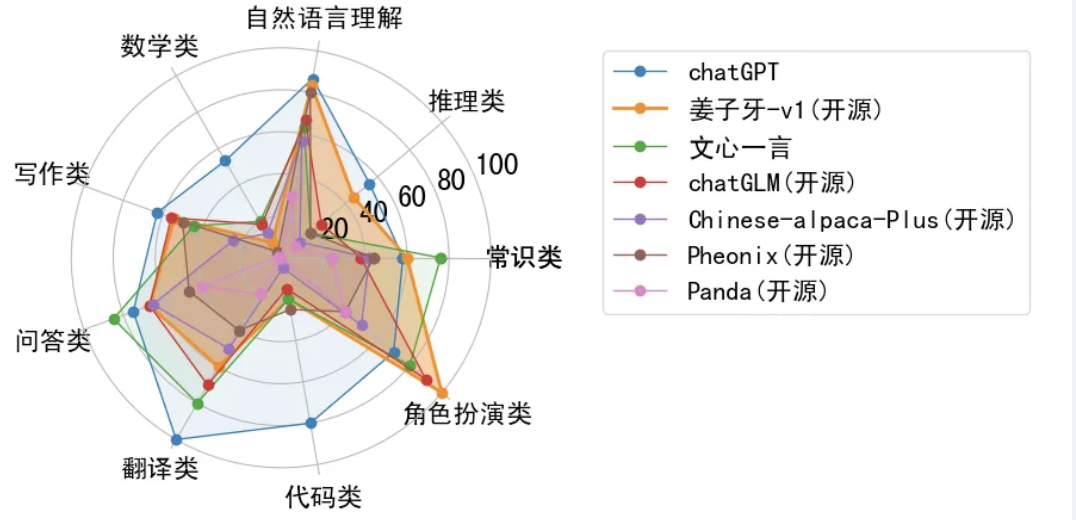
③IDEA研究院 发布的 姜子牙通用大模型(Ziya-LLaMA-13B-v1),基于LLaMA-13B扩充中文词表,进行千亿token量级的预训练,使模型具备中文能力。再经过500万条多任务样本的有监督微调和人类反馈训练获得对话能力。
评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演9大类任务,32个子类,共计185个问题
企业级 大语言模型 选择
现有的 流行 企业级LLM模型
大型语言模型(LLM)是基于大量数据进行预训练的超大型深度学习模型。底层转换器是一组神经网络,这些神经网络由具有自注意力功能的编码器和解码器组成。
| 名称 | 出品公司 | 简单描述 |
|---|---|---|
| BERT | BERT是由谷歌开发的一种预训练语言模型,可以实现文本分类、命名实体识别、问答等自然语言处理任务,基于Transformer. | |
| RoBERTa | RoBERTa是Facebook AI开源的一种预训练语言模型,它是在BERT的基础上进行了一系列改进和优化,如动态掩码、大规模训练等,基于Transformer. | |
| LLaMA | Meta | 开放且高效的大型基础语言模型,共有 7B、13B、33B、65B(650 亿)四种版本,其拥有很多改进版本如:Alpaca+LoRA、Guanaco+QLoRA、Vicuna、Koala。 |
| ChatGLM | 清华大学 | 开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构。 |
考虑维度
- 出品的公司,好公司出品的模型由于有强大的技术作为支持,往往稳定性比较好。
- 基于的原生技术,原生技术越大众化的模型由于有友好的生态,后期越容易解决问题和扩展。
- 模型复杂度,在能满足业务需求的情况下模型简单高效的当然是最好的选择。
- 微训练的硬件要求,考虑到成本问题,在能满足业务需求的情况下可以在消费级GPU上训练的模型当然首选。
- License,模型的版权越开放越好。
训练步骤
- 数据预处理:收集和准备用于训练问答系统的数据集,并将其预处理为模型可接受的格式。通常情况下,数据集需要包含问题和答案,并且需要将其转换为相应的特征向量。
- 模型训练:使用预处理的数据集训练模型。可以使用预训练的BERT模型作为初始模型,也可以从头开始训练模型,具体取决于您的需求和计算资源。
- 模型微调:在模型上进行微调,以适应特定的问答任务。这通常包括在BERT模型的顶部添加额外的层,并对其进行训练,以使其适应特定的任务。
- 模型评估:使用预处理的测试数据集对模型进行评估,以评估其性能和准确性。可以使用多种评估指标,包括精确度、召回率和F1分数等。
- 模型部署:一旦模型训练完成并且性能满足要求,就可以将其部署到生产环境中,并将其用于实际的问答任务。
在 本地 跑一个 大语言模型
优缺点
在本地运行LLM有诸多优点:
- 保护隐私
- 不会产生昂贵的费用
- 无视网络问题
- 可以尝鲜各种开源模型
但是:
- 小白劝退
- 开源模型与商用模型相比,“智商”堪忧
- 个人电脑配置较弱,不可能把模型的全部实力跑出来
开源世界里工具超多,“智商”这种东西,可以通过工具慢慢“调教”
工具
3个本地运行LLM的工具:
- LMStudio
- llamafile
- Ollama
使用方法大同小异,安装也都很简单,从稳定性和便利性来讲,推荐Ollama。
运行Ollama
安装
根据操作系统下载对应的安装包。没有提供GUI界面,所有操作都是需要命令行操作。
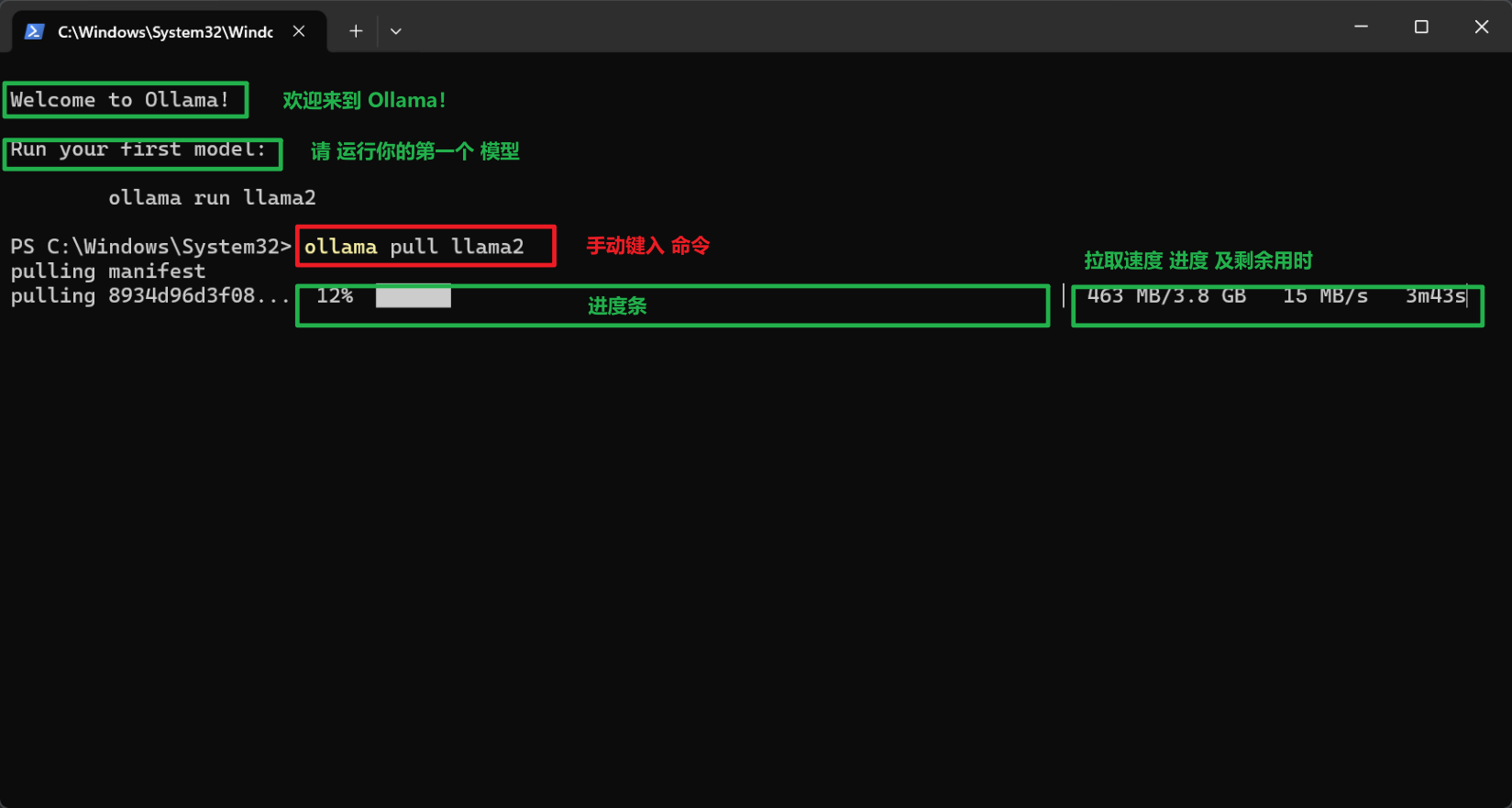
拉取模型
安装完后第一步是要拉取一个模型,
# 安装模型
ollama pull llama2
# 删除模型
ollama rm llama2
此处附上笔者实际操作中的截图:
初学者推荐模型:
- llama2(前述的脸书母公司Meta发布的大语言模型)
- mistral (法国AI公司发布的大语言模型)
- qwen (阿里巴巴发布的大语言模型,通义千问)
- llava (可以进行图片识别的大语言模型)
大厂开源的这些模型,都不是它们最强的模型,因为最强模型都留着商用。这就意味着这些模型刚拿到手里都或多或少有点“智障”,一开始并不能很好的理解你的意图给你很好的回答。这也就造成了后面说的需要“调教”的原因。
参数
ollama pull llama2命令拉取的模型是默认参数(如图),
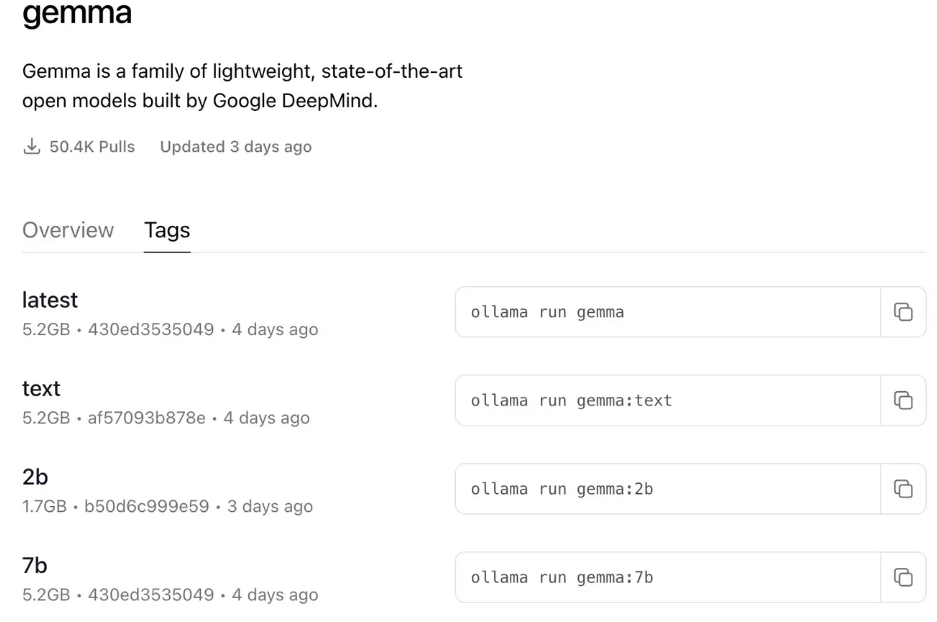
如果你对参数有需求,可以点击模型的Tags标签,自行选择合适的参数。
参数说明:
2b, 7b, 13b
- 模型训练时的参数数量,b代表亿。越大结果越精确,相应的也越占资源,同时生成结果所需的时间也越长。7B至少需要8G内存,13B至少需要16G内存。
instruct, chat, text
- instruct, chat更适合聊天,text更适合内容生成。
q2, q4, q8
- 模型量化值,同样越大越精确,但越占内存,同时生成结果所需的时间也越长。
运行
拉取完模型后,可以使用ollama list命令查看一下所有已安装的模型。接下来就可以运行Ollama了;
Ollama的运行方式有两种,一种是命令行方式,输入ollama serve即可启动服务。另一种是点击App的快捷方式运行,这种方式会在状态栏出现一个ollama的图标。无论哪种方式,启动服务后都会占用11434端口
此时你可以使用任何支持修改API地址的ChatGPT客户端连接Ollama(因为最新版的Ollama已经适配了OpenAI的API)。另外,某些APP如果适配Llama API接口的话,也可以直接配置:
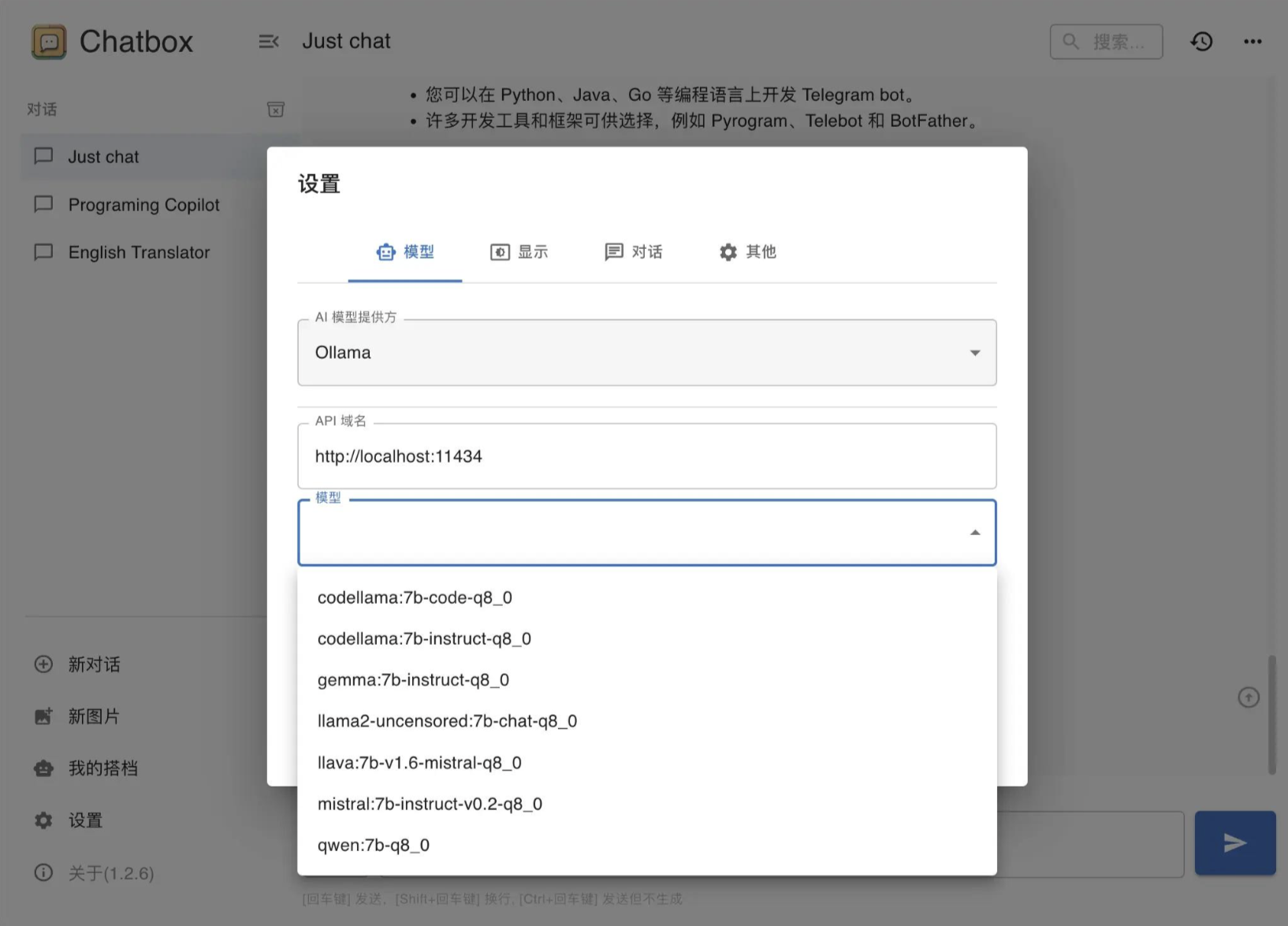
API文档
ollama/docs/api.md at main · ollama/ollama (github.com)
介绍两个
POST /api/generate
POST /api/chat
第一个是内容生成,第二个是与模型聊天。两个API所需的参数不同,具体可以查看文档这里不做赘述。这里主要聊一聊的是这两个接口的区别:
generate接口强调的是生成,因此你需要一次性把提示都给到它,这样才能生成更理想的结果。
chat接口强调的是聊天,也是目前大部分ChatGPT客户端使用的场景,与模型有来有回的聊天,每次聊天都会带上之前的所有上下文。因此可以与模型聊天几个来回后逐步把提示给到它
测试
写一个脚本来测试一下各个模型在内容生成方面表现如何。
首先,安装相应的包:pip install ollama。
然后编写一个python脚本,这个脚本定义了几个简单的角色
import ollama
roles = {
'english_translator': 'Translate `%s` to English.',
'chinese_translator': 'Translate `%s` to Chinese.',
'supervisor': "Explain `%s` like I'm a 5 year old.",
'professional': "Explain `%s` as a professional.",
'generator': "%s",
'content_creator': 'Expand your writing according to the prompts given: `%s`',
}
models = {
'mistral': 'mistral:7b-instruct-v0.2-q8_0',
'qwen': 'qwen:7b-q8_0',
'gemma': 'gemma:7b-instruct-q8_0',
'llama2': 'llama2-uncensored:7b-chat-q8_0',
'llava': 'llava:7b-v1.6-mistral-q8_0',
'codellama': 'codellama:7b-instruct-q8_0',
}
class Assistant:
def __init__(self, model_key, role_key) -> None:
self.role_prompt = roles[role_key]
self.model = models[model_key]
def work(self, user_prompt):
print(user_prompt)
response = ollama.generate(
model=self.model,
# format='json',
options={'temperature': 0.7},
prompt=self.role_prompt % user_prompt,
stream=True
)
for chunk in response:
print(chunk['response'], end='', flush=True)
if __name__ == "__main__":
assistant = Assistant('llama2', 'chinese_translator')
assistant.work("Note: It is important to wear protective gear while handling these ingredients as they are highly corrosive and can cause serious burns if not handled properly.")
项目调研报告
研究报告
矿上 证明

