
基于py框架实现一个简化的trm?
词向量
本部分特别致谢【自然语言处理】Word2Vec 词向量模型详解 + Python代码实战_word2vec模型-CSDN博客
A1回顾
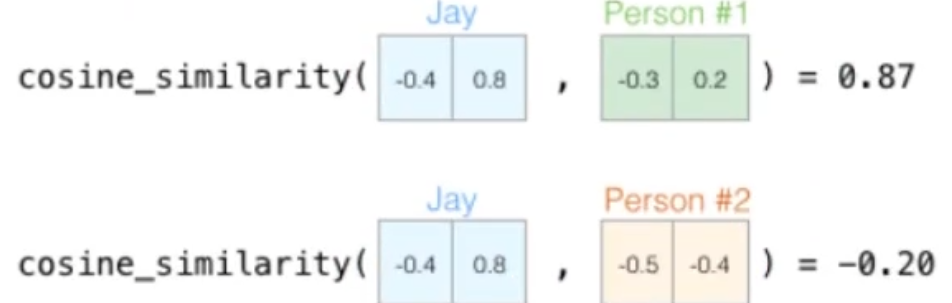
cos∟=0,同向=1,反向180°=-1
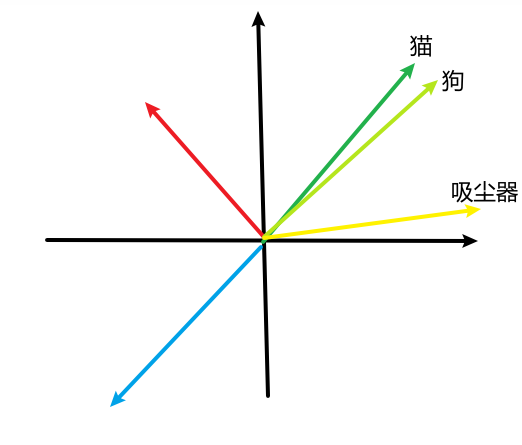
基于word2vec开发的gensim库:由图,词向量捕捉了相似度
You shall know a word by the company it keeps. ——John Rupert Firth (1890-1960)

"分布假说"
A2引入
文本向量化,且向量的维度越高,能提供的信息也就越多,从而计算结果的可靠性就更值得信赖

如何描述词的特征?通常都是在词的层面上来构建特征。Word2Vec就是要把词转化为向量
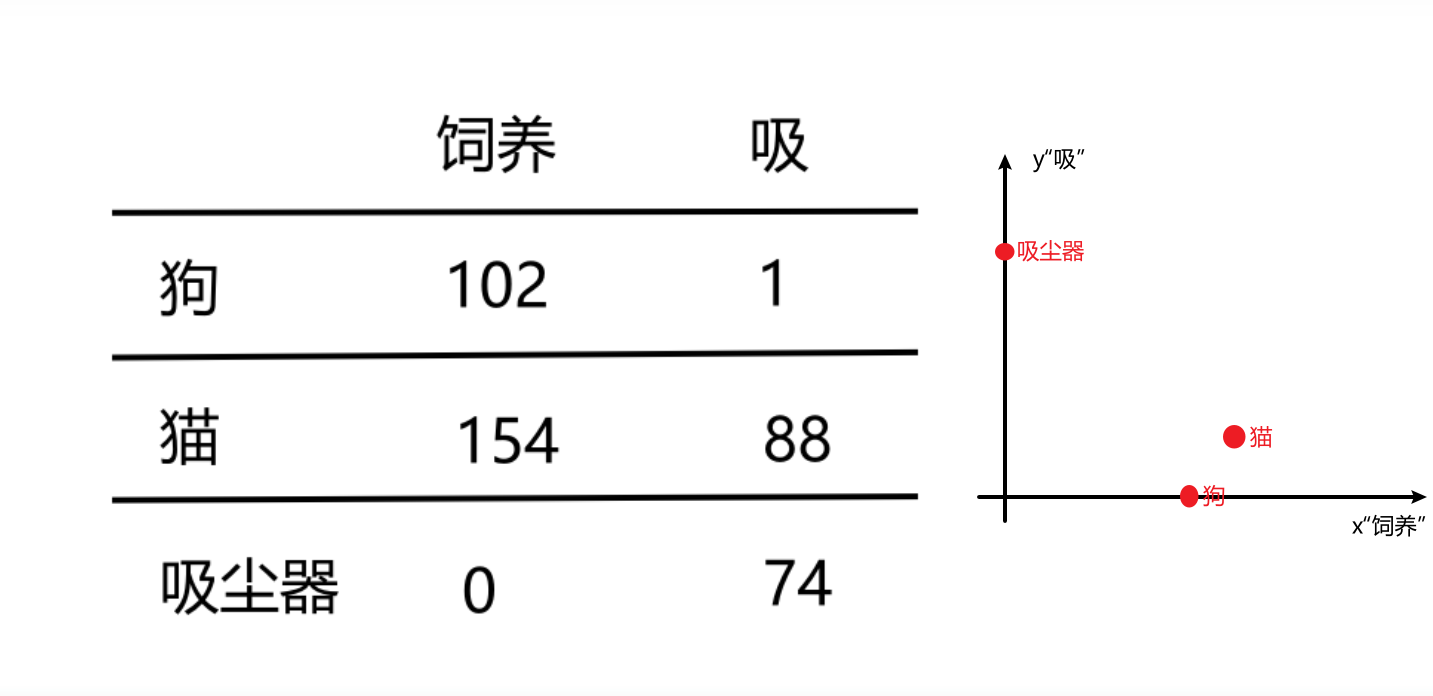
假设我现在有一个训练好的词向量,是一个50维长度的向量,它在某个别的单独位置上(比如位置5、10、15处)的热度最高(+0.8);然后取“man”、“boy”、“water”三个单词来对比,发现“man”和“boy”的热度图中,位置8到10和45到50两个区间上二者相似(+0.6),而“water”一词的热度图仅在个别位置(比如位置13处、33处)和“boy”存在相似。以上例子如何说明了“词的特征存在实际意义”呢?
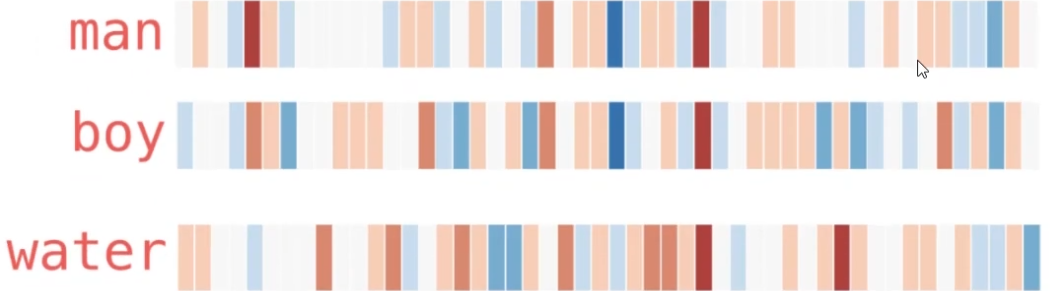
维度特征的语义解释
- 对于“man”和“boy”来说,位置8到10和45到50的相似值(+0.6)可能捕捉到了这两个词在某些语义特征上的相似性,如“性别(男性)”或“人的特征”。这些特征可能与性别、年龄或社会角色相关。
- 而“water”一词在位置13和33与“boy”存在相似,表明这些维度可能捕捉了更广泛的或不同的特征,比如“物理特性”或“生活中常见的实体”。
模型(对比)

网络的输出是所有词可能是下一个词的概率
A3DUNE --举例
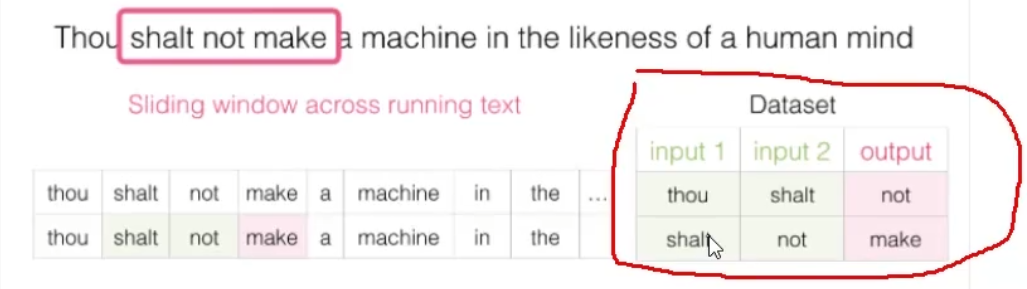
Thou shalt not make a machine in the likeness of a human mind.
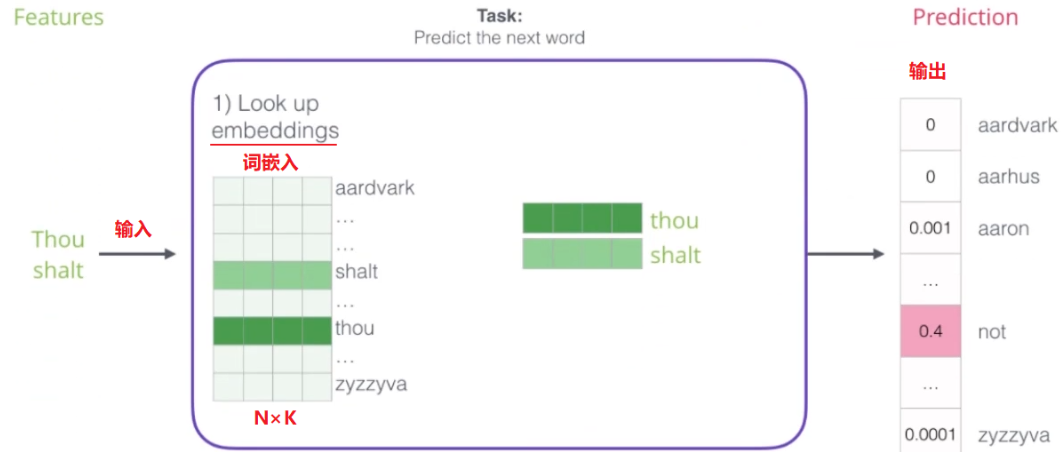
ini化
词典大小 N 为12(即N=12)。词向量的维度 K 可以是300(即K=300),这是超参数,我们可以设置为任意值。
我们会初始化一个 N×K 的词向量矩阵,这里每一行是一个300维的词向量。例如:
词向量矩阵 (N×K):
[ [0.1, -0.2, ...], // "Thou"
[0.5, 0.1, ...], // "shalt"
...,
[0.3, -0.4, ...] ] // "mind"
这每一行是对应于词典中每个词的词向量,初始化时的值是随机的。
独热
对于句子“Thou shalt not make a machine in the likeness of a human mind”,我们会生成一个One-Hot编码矩阵。每个单词会在矩阵中有一个唯一的“1”位置,其余位置是“0”。如果“Thou”在词典中对应的位置是0,则One-Hot编码矩阵的第0行将是:
One-Hot 编码矩阵 (N×N):
[ [1, 0, 0, ..., 0], // "Thou"
[0, 1, 0, ..., 0], // "shalt"
...,
[0, 0, 0, ..., 1] ] // "mind"
前向传播
将One-Hot编码矩阵与词向量矩阵相乘。在这种情况下,由于One-Hot编码矩阵中只有一个“1”,其他为“0”,乘法的结果将提取出词向量矩阵中对应的词向量。
反向传播
在训练过程中,通过反向传播算法,词向量矩阵中的值会不断调整,以最小化损失函数。词向量会被更新,以更好地捕捉句子中词语之间的关系和语义特征。
反向传播是训练神经网络的核心原理,不同的模型都依赖于反向传播来更新网络的权重。架构差异如下:
1. ELMo(Embeddings from Language Models)
ELMo使用双向LSTM(长短期记忆网络)来生成上下文相关的词向量。与传统的词嵌入(如Word2Vec)不同,ELMo能够捕捉上下文信息,因此其词向量在不同上下文中会有所不同。在ELMo中,反向传播算法用于训练LSTM模型。在训练过程中,网络会调整LSTM的参数以最小化预测误差,从而优化上下文词向量的表示。反向传播在这里用于更新LSTM网络的权重,包括隐藏层的参数。
2. Transformer
Transformer模型引入了自注意力机制和多头注意力机制,摆脱了RNN(递归神经网络)的序列处理限制。它通过自注意力机制捕捉长距离的依赖关系,从而改进了语言建模和生成。Transformer模型的训练也依赖于反向传播。反向传播算法用于优化网络中的权重,包括自注意力机制中的权重和前馈网络的权重。Transformer中的每一层(包括多头注意力层和前馈网络层)都有其需要优化的参数,这些参数通过反向传播来调整。
3. GPT(Generative Pre-trained Transformer)
GPT基于Transformer架构,但特别设计为生成模型。它使用自回归的方式生成文本,输入上下文后预测下一个词。GPT的训练过程中,反向传播用于优化Transformer模型的参数,主要集中在自注意力机制和前馈网络上。训练过程中,GPT的目标是最小化生成文本与真实文本之间的差异,通过反向传播调整参数以提高生成效果。
4. BERT(Bidirectional Encoder Representations from Transformers)
BERT是基于Transformer的双向编码器模型,能够在训练过程中考虑上下文的双向信息。这使得BERT在各种NLP任务中表现优异。BERT的训练包括两个阶段:预训练和微调。在预训练阶段,BERT使用掩码语言模型(MLM)和下一个句子预测(NSP)任务来训练模型,反向传播用于优化模型的参数。微调阶段则根据具体任务(如问答、文本分类)进行进一步训练,反向传播在这里也用于优化参数以适应特定任务的要求。
A4训练过程
数据构建
Q:数据应该从哪找呢?
A:一切具有正常逻辑的语句都可以作为训练数据。
计算困境与方案
窗口会依次滑动以覆盖每个词及其上下文,以生成新的上下文-目标对。考虑sftmx的计算公式:
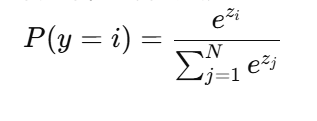
其中,zi 是第 i 个单词的得分(logit),N 是词汇表的大小。
词汇表(Vocabulary)
词汇表是一个自然语言处理模型中所使用的所有单词或词组的集合。对于每个单词,模型会为其分配一个独特的索引。词汇表的大小(也称为词典大小,V)是这个集合中的单词总数。
具体例子
假设我们正在训练一个语言模型来预测英语中的下一个单词。模型的任务是给定前面的单词序列,预测下一个单词是什么。
- 输入 "I love reading books about"……
- 预测下一个单词可能是 "science"、"history"、"fiction" 等
假设我们的词汇表大小为 1,000,000(百万)个单词,这意味着我们的模型可以预测的单词有一百万个。
SoftMax的计算
-
模型输出得分: 模型对每个词汇表中的单词计算一个得分(logit),表示每个单词作为下一个单词的相对可能性。这些得分可能来自于前面的神经网络层。
假设我们有得分向量:
[z_1, z_2, ..., z_1000000],其中 zi 是第 i 个单词的得分。 -
指数运算: SoftMax需要对每个得分取指数,然后归一化。这意味着我们要计算:
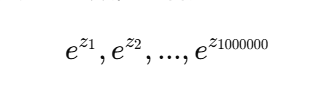
-
归一化: 计算这些指数值的总和,然后每个得分对应的概率是:
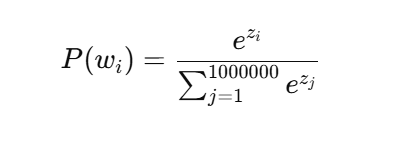
其中 P 是单词 w 出现的概率。
可能的解决方案
这意味着需要计算1,000,000次得分、指数,然后计算1,000,000个概率,(高维度数据)需要大量内存。
这对实时应用(如翻译、语音识别等)是一个巨大的瓶颈,因为我们希望系统能在用户等待时快速响应。
负采样(Negative Sampling)
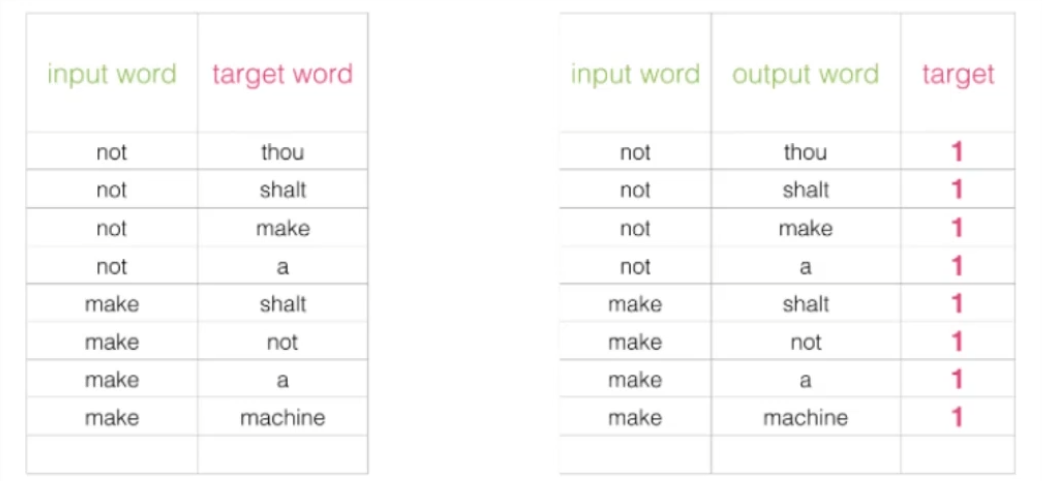
初始解决方案:假设,传统模型中,我们输入 not ,希望输出是 thou,但是由于语料库庞大,最后一层 SoftMax 太过耗时,所以我们可以改为:将 not 和 thou 同时作为输入,做一个二分类问题,类别 1 表示 not 和 thou 是邻居,类别 0 表示它们不是邻居。
出发点非常好,但是由于训练集本来就是用上下文构建出来的,所以训练集构建出来的标签全为 1 ,无法较好的进行训练,如图:
改进方案:加入一些负样本(负采样模型),一般负采样个数为 5 个就好,负采样示意:

即,负采样是指在训练过程中,不仅学习实际存在的正样本对,还通过引入一些负样本对(即不应该出现在一起的对)来帮助模型学习。例如,如果实际存在的排队顺序是ABCDE,那么负样本对可能是“AE”、“BD”等,它们不会在正常的排队顺序中出现。
对于正样本对“AB”,希望模型输出一个高的相似度或概率(表示它们应该在一起)。
对于负样本对“AE”,希望模型输出一个低的相似度或概率(表示它们不应该在一起)。
A5模型(抉择)
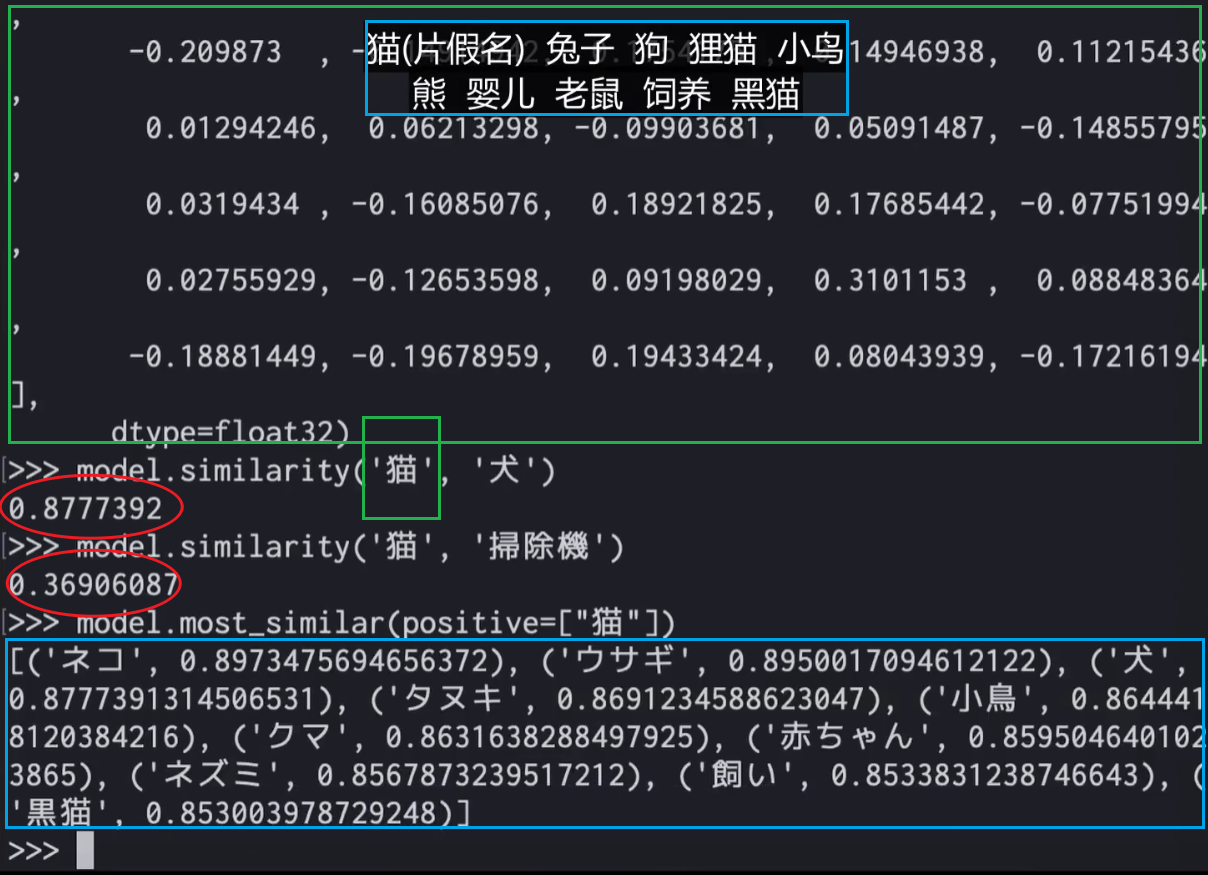
假如目前我们决定使用word2vec或transformer来针对煤矿行业训练一个用于判断某个多义词在不同语境下含义(比如之前提到的“微小震动”)的模型,综合考虑来说更适合用二者中的哪一个?
Word2Vec
优点
- 相对简单,易于实现和训练。
- 训练速度较快,计算资源需求较少。
缺点
- 词向量依赖固定上下文窗口,无法动态地处理复杂、长距离依赖关系(多义词的细粒度)。
Transformer
优点
- BERT和GPT,能够处理更复杂的上下文信息,捕捉长距离依赖关系。
- 有许多预训练的Transformer模型可以微调,以减少训练时间和数据需求。
缺点
- 大量的计算资源和内存,训练过程可能较慢。
- 模型更复杂,调优和实现的难度较高。
代码实战
关于全角转半角的问题,鸣谢word2vec词向量的训练--实战篇(语言模型词向量的生成)_词向量宽度是怎么做到12288-CSDN博客
关于PyTorch的关于自然语言处理的常用包,参考【从零开始学习深度学习】48.Pytorch_NLP实战案例:如何使用预训练的词向量模型求近义词和类比词_nlp近义词任务-CSDN博客

