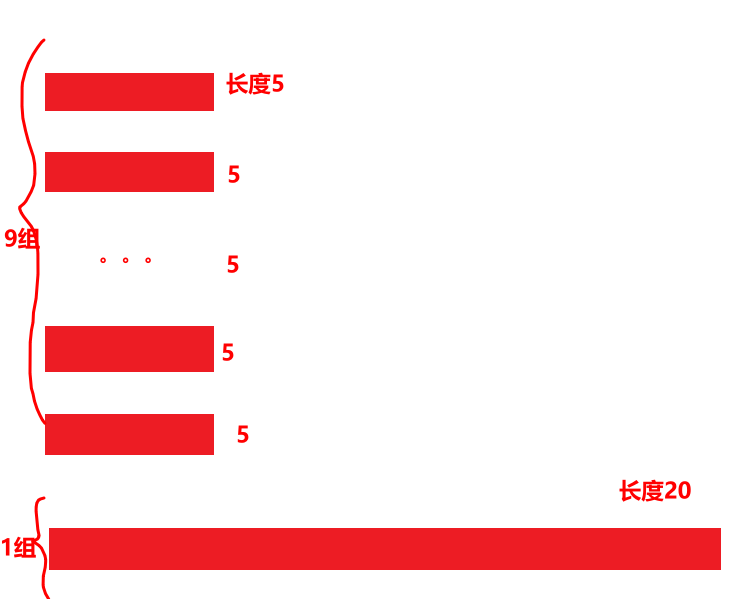
transformer 从零
trm在做什么事情?
类比“翻译”,输入、黑盒处理、输出。

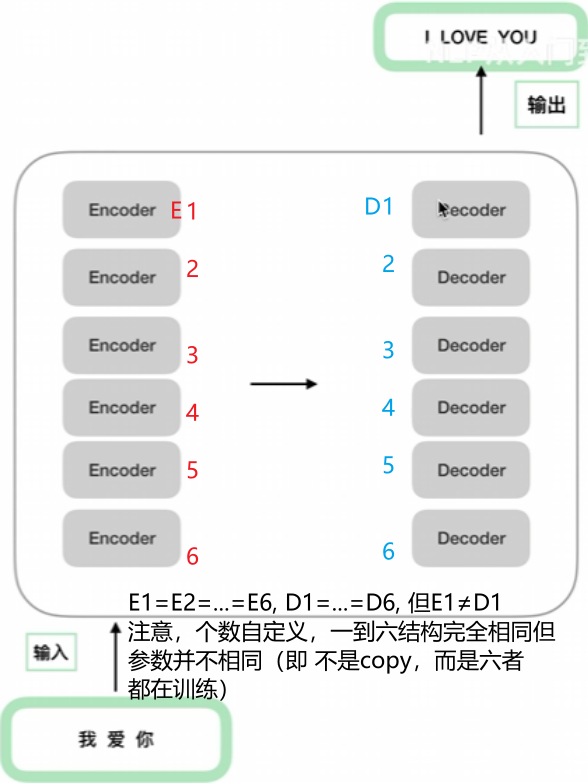
对其细化,黑盒中编码作为解码的输入,二者的结果作为终局输出的输入。继续细化成下图:
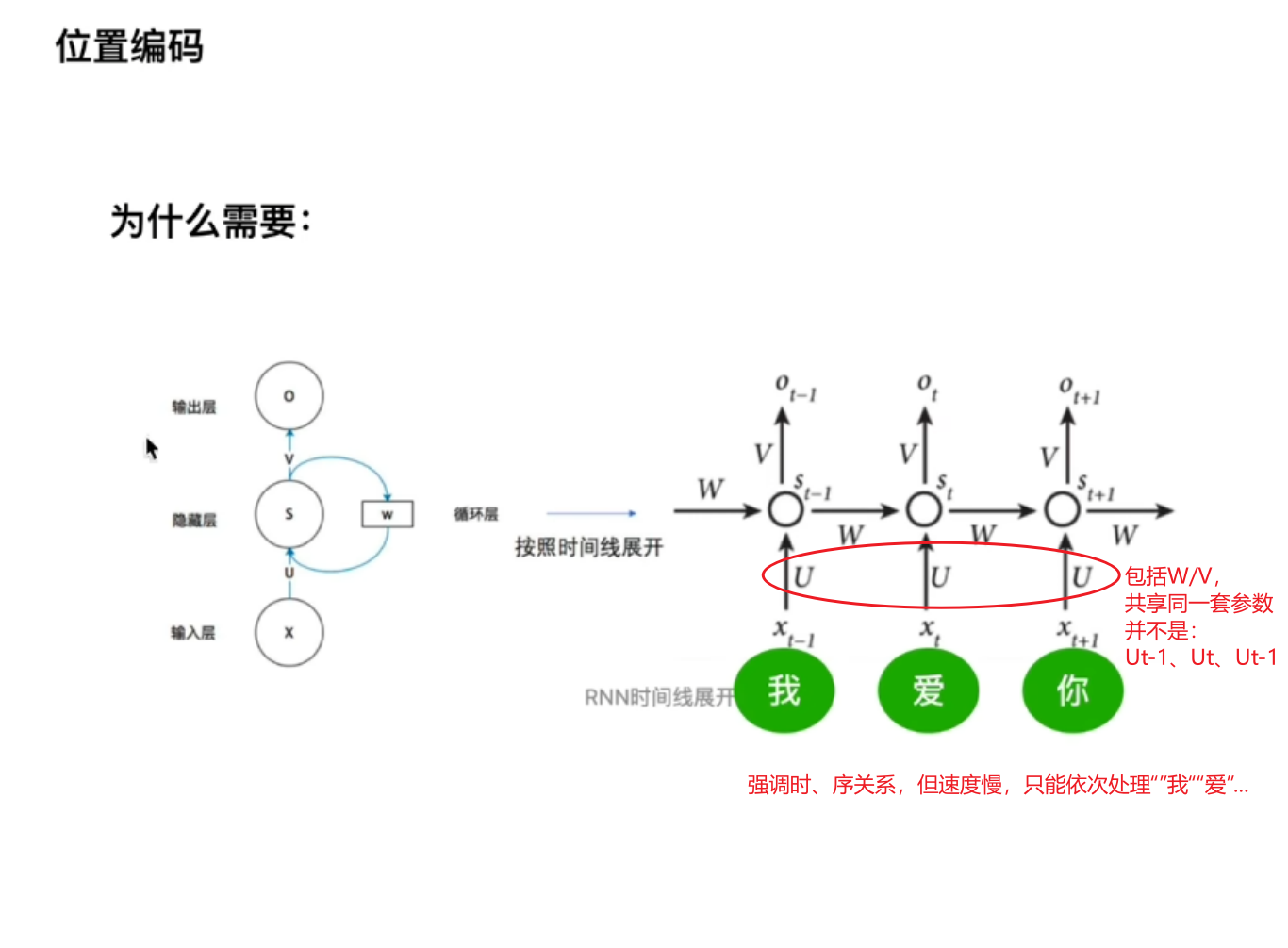
位置编码
下图为rnn下的时间线展开,
借由三角函数性质公式:
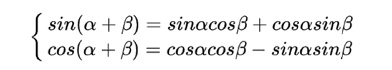
得到:
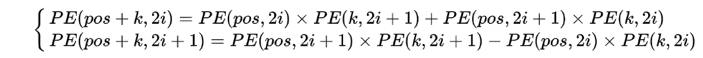
即,若当pos=“我”,k=“爱”时,pos+k的“你”位置的向量被前二者线性组合,也就是说,位置向量中蕴含了相对位置的信息。
多头注意力
基本的注意力机制
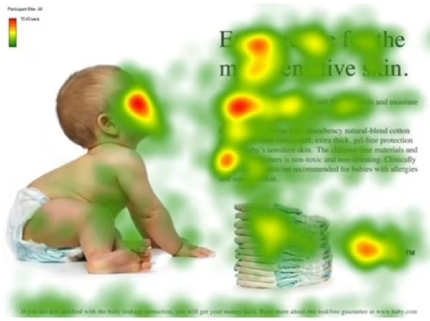
给出上图(颜色深浅表示不同注意力分配),另外现在给出一句话“婴儿在干嘛”,人类会更关注左侧而非右侧文字
trm中如何实现

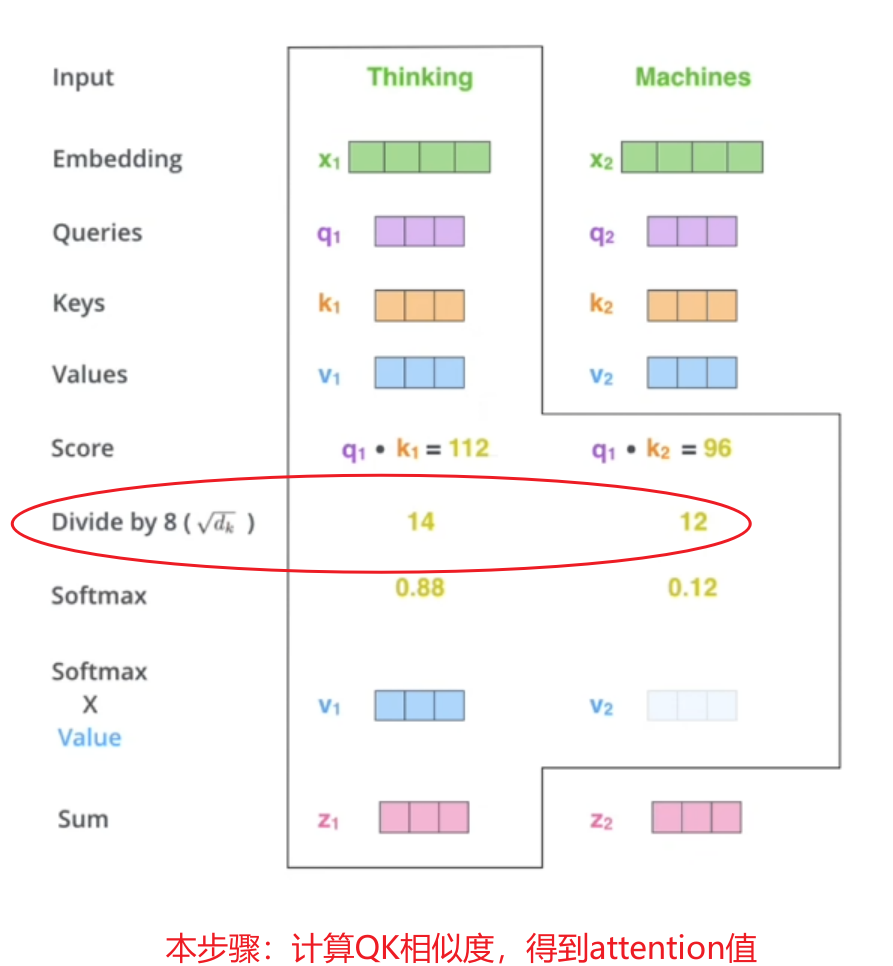
结合本式,以上图(婴儿)为例,当问出“婴儿在干嘛”后,应该更关注哪些区域。简化信息,提炼“婴儿”一词作为输入,并划分四个区域作为key。
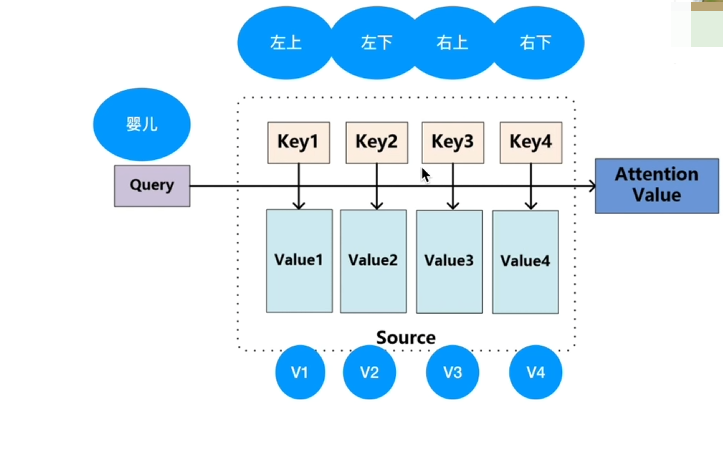
【点乘】是向量在向量上的投影长度,为标量,可反映“相似度”,越相似则值越大;此处判断query(婴儿)点乘key1(左上/...)谁更大,若四者计算结果V1~V4呈现“0.7,0.1,0.1,0.1”则判定为“左上”
在trm中,仅有单词向量,如何获取QKV?
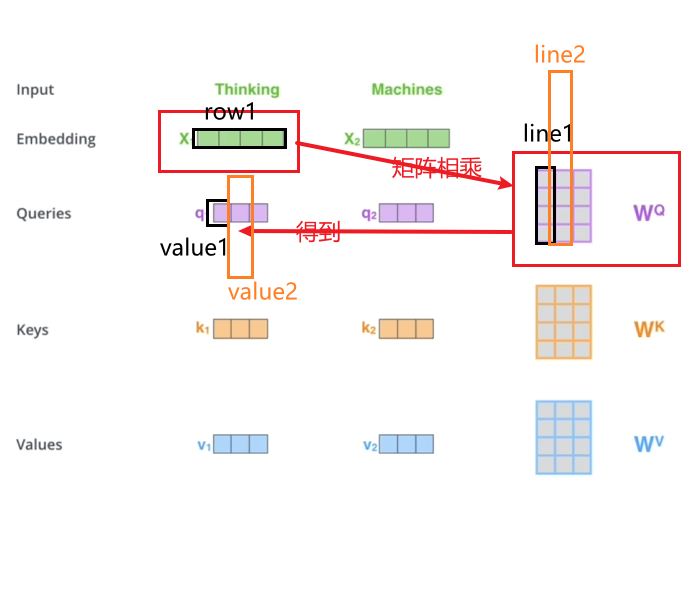
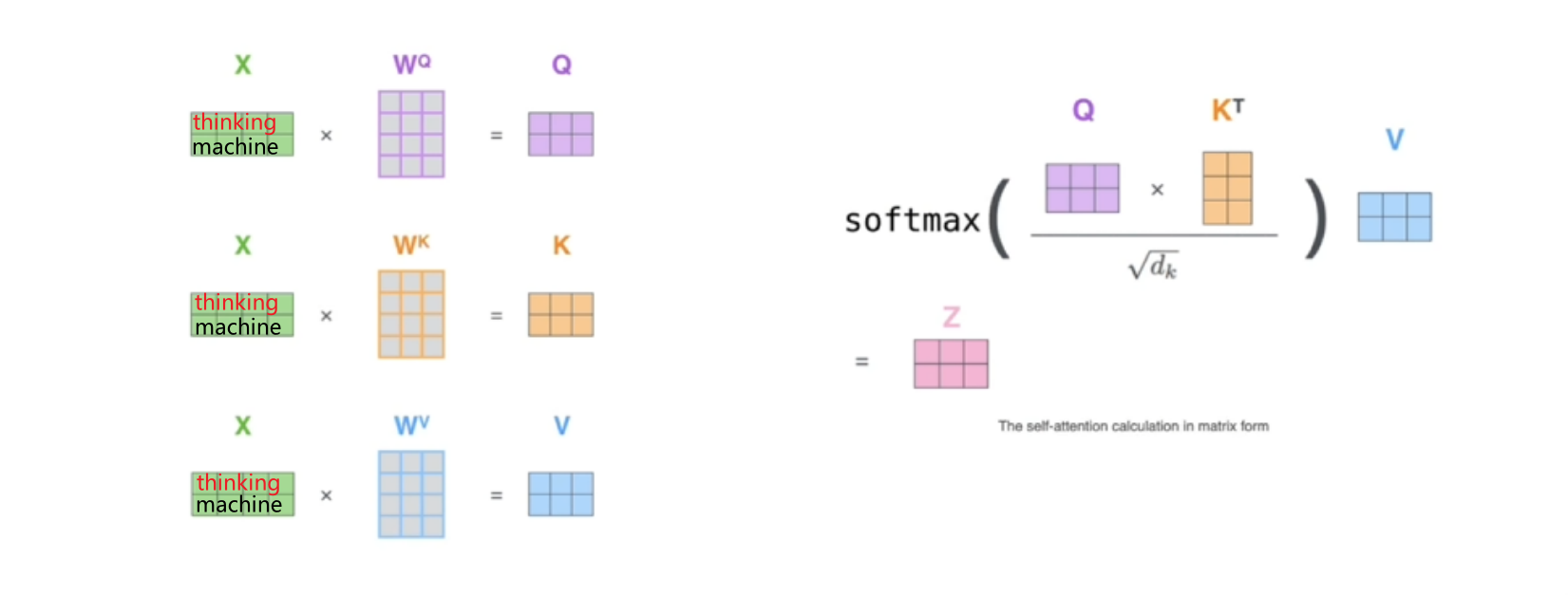
实际代码使用矩阵以方便并行(同时输进“thinking”和“machine”更快):
并且考虑使用两套(多套)参数,如图:
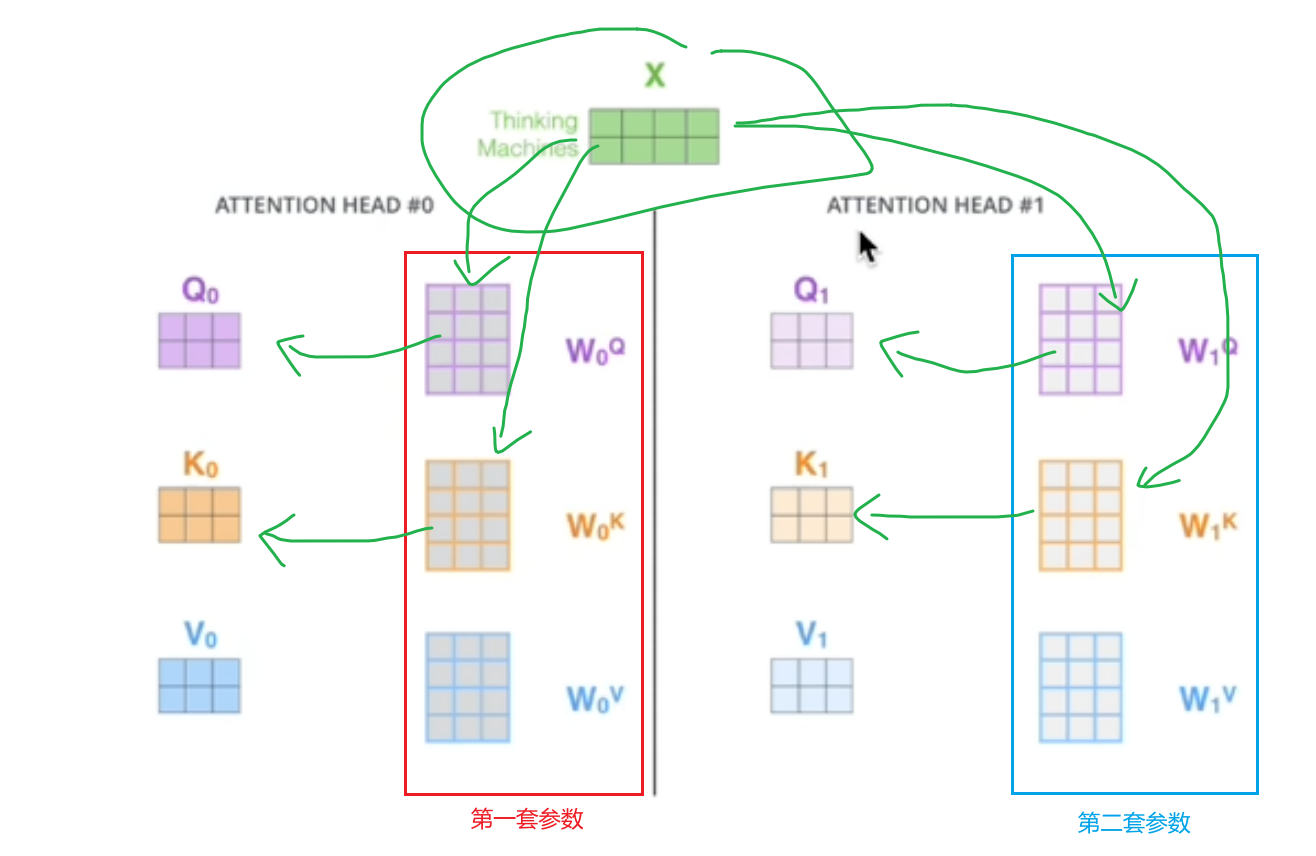
操作理由:打到不同“空间”,保证trm注意、捕捉到更多的信息。最后,各组流经不同“空间”各出一个z值,z0到z7八个(“头”)结果值一起输出,再取矩阵即为多头注意力的输出。
残差和layerNorm
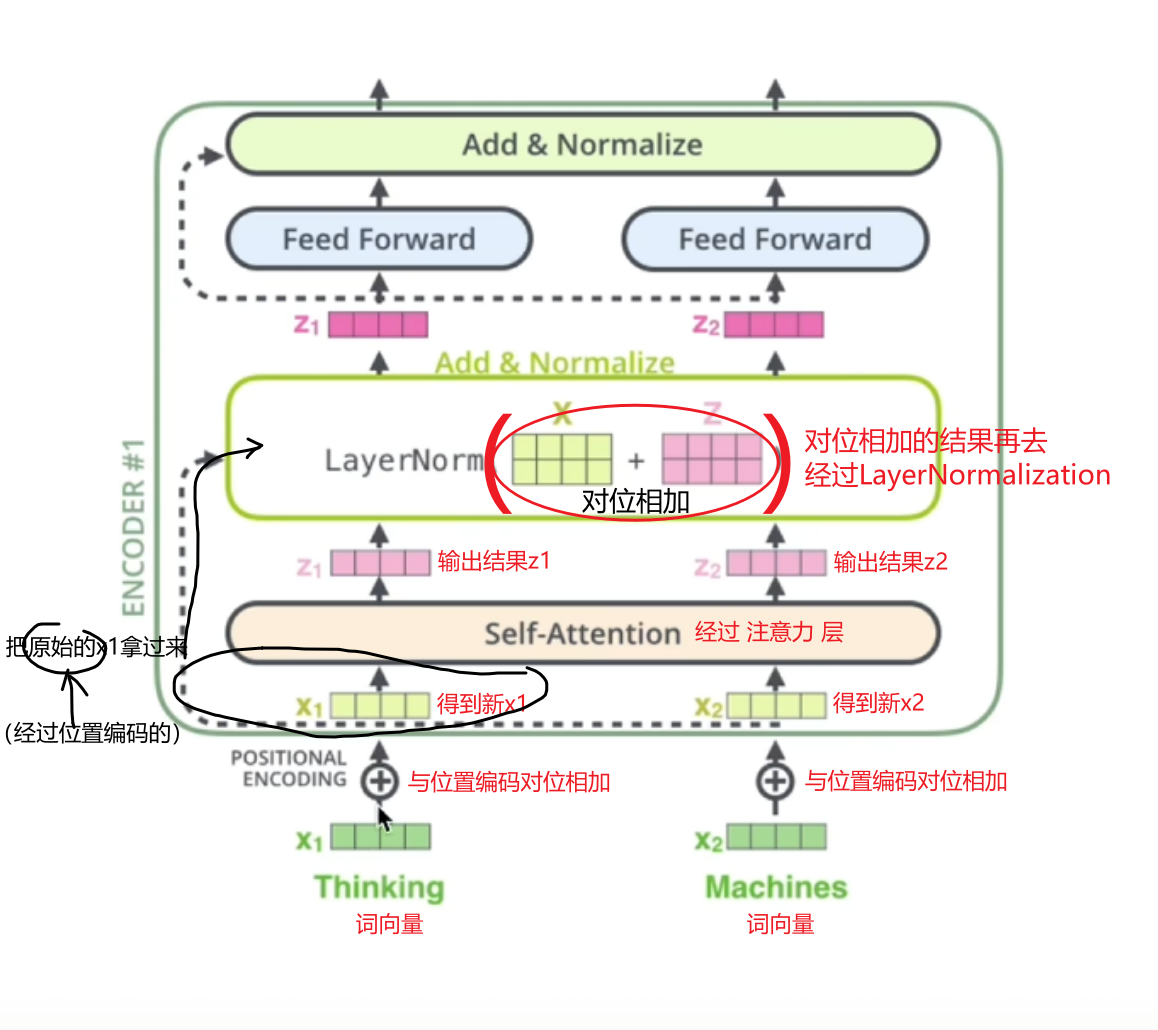
什么是残差?
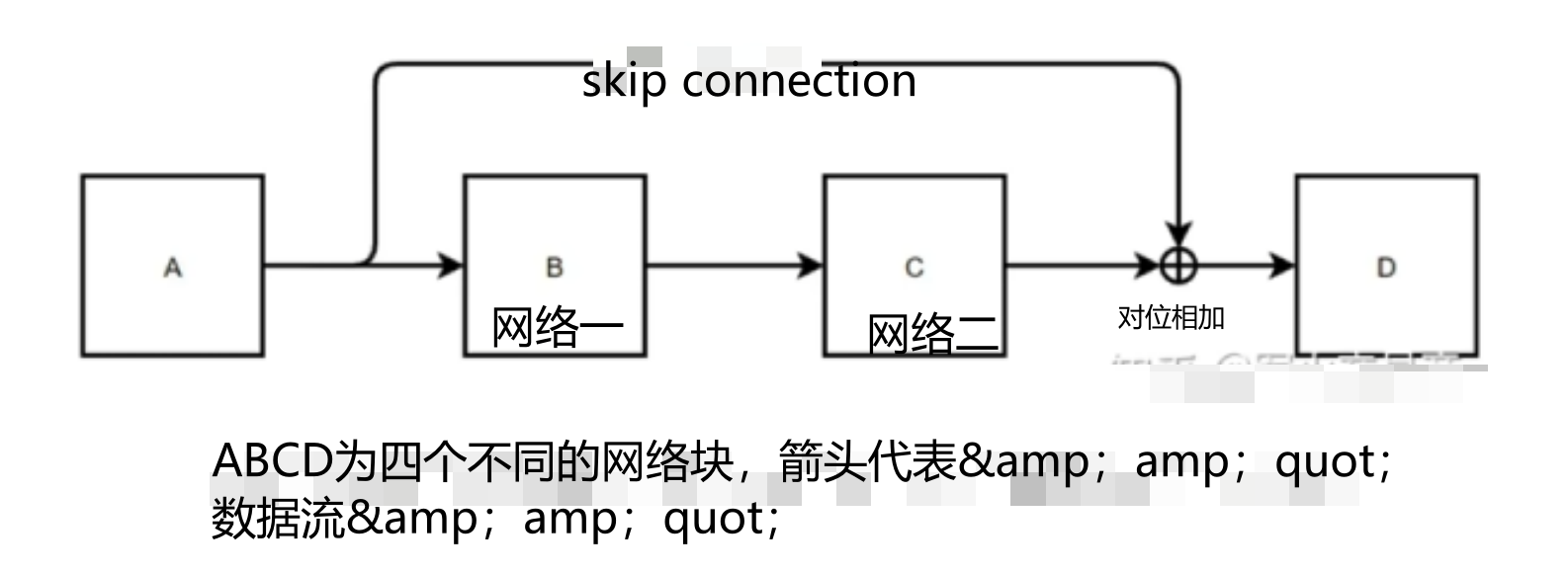
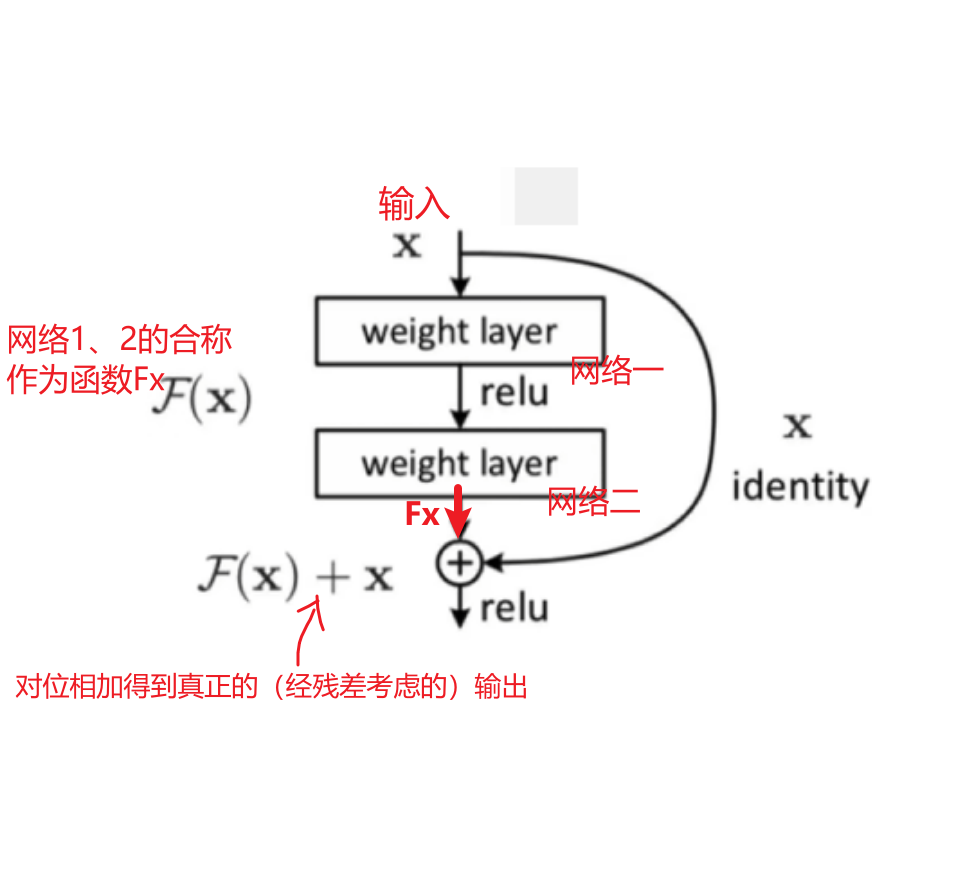
为什么不用传统的BN?
BN在NLP任务中(大多)表现效果差,BN对样本总是仅对其某一维度上做分析(只比较体重/只比较身高...);
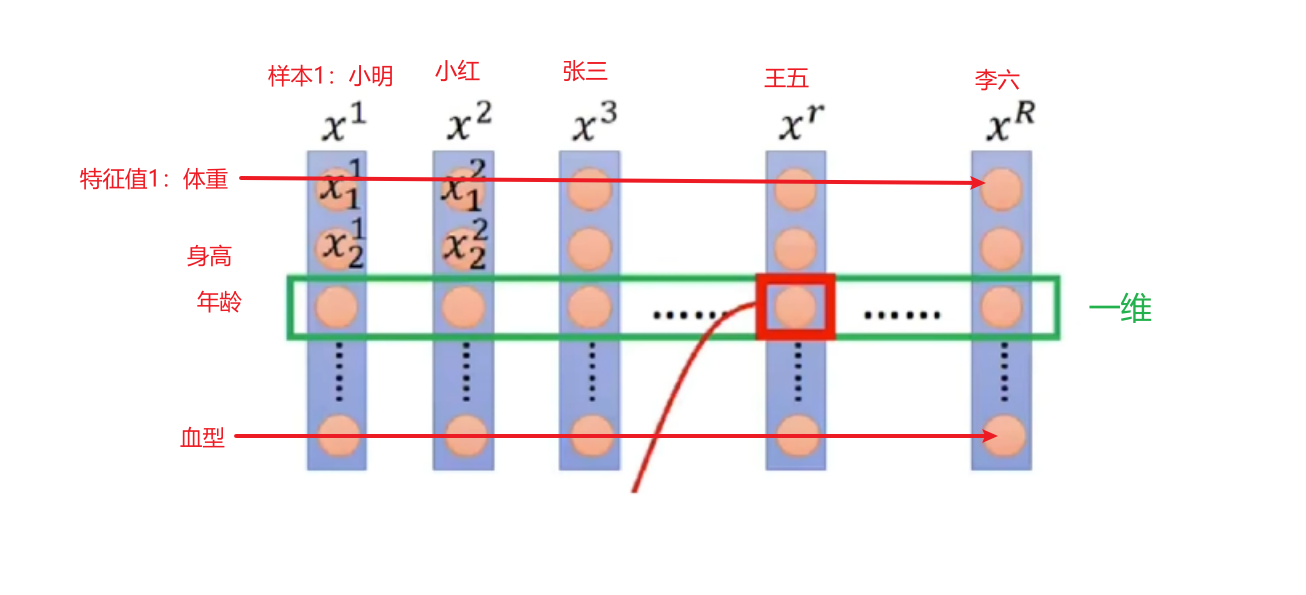
优点是BN解决了内部协变量偏移(存疑)、缓解了梯度饱和问题且加快其收敛;
缺点batch_size较小的时候效果差,比如全班100人,batch为10人,BN则会以本10人的均值、方差来模拟全100人的均值、方差;其次就是BN在RNN中的问题: