
Function
介绍、定义
组织好的(提前写好内置)、可重复使用的、用以实现特定功能的 代码段 。
str1 = "iloveu"
str2 = "goodluck"
str3 = "seeya"
count = 0
for i in str1:
count += 1
print(f"字符串{str1}的长度是{count}")
# 将for写三次分别对应str1、2、3重复的代码过多,非常低效,所以引入函数
def my_length(data):
count = 0
for i in data:
count += 1
print(f"字符串{data}的长度是{count}")
my_length(str1)
my_length(str2)
my_length(str3)
函数实现了把 重复性的劳动 封装 了起来。
基础定义语法 def 函数名 (传入参): + 函数体 + return 返回值 ;
调用函数才能使其工作:函数名() , 先执行了调用所在行再执行函数体
参数
接受外部提供的数据
def add(x,y) ; result=x+y ; print(f"{x}+{y}的结果是{result})
xy为形参,以后代码可以写入 add(5,6) 称为实参来调用
传入参数可以没有,也可以任意n个
返回值
定义
完成功能后会将运算结果返回给调用者;且运行时一旦遇到return会立即结束def函数
none
无返回值的函数实际上是返回了none这个字面量,即 返回了空、返回了无意义的内容;
在
if判断中,none等同于False;
def check_age(age):
if age > 18:
return "success"
else:
return None
result = check_age(16)
if result == None: # 或写成“if not result”
print("未成年不可进入")
在定义环节暂时不需要变量有具体值的场景时,可以
name=None来代替;
说明文档
内容应在函数体之前
"""
check_age可以用于判断年龄是否成年(整体功能解释)
:param age: 表示输入的年龄值
:return: 返回值时判断的结果
"""
嵌套
函数之内调用了另一个函数,如图:

其执行结果:
--1--
--2--
--3--
变量作用域
-
局部变量
定义在函数体内的,只在函数体内生效,当函数完成后销毁局部变量;
-
全局变量
内外都能生效的变量;
num = 200 def test_a(): print(f"test_a:{num}") def test_b(): # 若想声明为全局,在此行写“ global num” num = 500 # 局部变量,外部该是多少就是多少 print(f"test_b:{num}") test_a() test_b() print(num) """ 显示结果运行如下: test_a:200 test_b:500 200 """
综合
ATM模拟;
- 定义全局变量money(记录余额)和name(记录姓名);
- 四组函数 查询函数、存款函数、取款函数、主菜单函数;
- 要求:①程序启动先输入姓名,②每次查询完成会返回主菜单,③存取款后会显示余额,④选择退出或输错会完全退出程序否则一直运行
# 定义全局的money和name
money = 5000000
name = None
# 此处要求输入姓名
name = input("请输入您的姓名")
# 查询函数
def q(show_header):
if show_header:
print("----查询余额----")
print(f"{name},您的余额剩余:{money}")
# 存款函数
def s(num):
global money
money += num
print("----存款操作----")
print(f"{name},您好,存款{num}成功")
# 调用q函数以实现查询余额的功能
q(False)
# 取款函数
def get_moeny(num):
global money
money -= num
print("----取款操作----")
print(f"{name},您好,取款{num}成功")
# 调用q函数以实现查询余额的功能
q(False)
# 主菜单函数
def menu():
print("----主菜单----")
print(f"{name},请选择业务:")
print("查余额\t\t[输入1]")
print("存款\t\t\t[输入2]")
print("取款\t\t\t[输入3]")
print("退出业务\t\t[输入4]")
return input("请输入您的选择:")
# 实现无限循环来确保不退出
while True:
keyboard_input = menu()
if keyboard_input == "1":
q(True)
continue # 通过continue继续下一次循环,并且实现一进来就是主菜单
elif keyboard_input == "2":
num = int(input("您需要存入的金额:"))
s(num)
continue
elif keyboard_input == "3":
num = int(input("您需要取出的金额:"))
get_moeny(num)
continue
else:
print("退出程序")
break
Container
列表list及其遍历
场景:我想记录5个、50个、500个学生姓名,此前学习的分别定义五个变量不高级且低效;
出于 批量存储及使用多份数据 的目的,数据容器可以容纳 任意类型数据 的 元素 ;
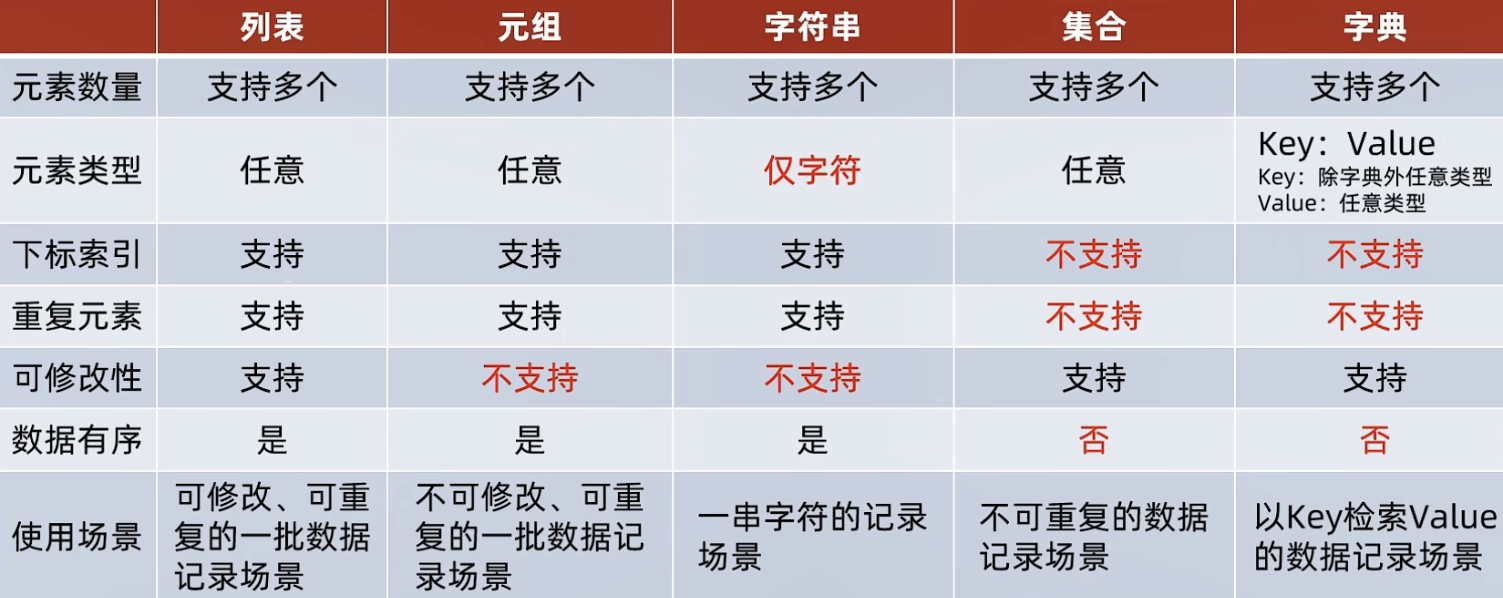
根据是否支持重复、修改、有序分为五类
定义
[ ] 为标识, 变量名称 = [元素1,元素2,元素3,...]
空列表可以写成 变量名称 = [ ] 或 变量名称 = list ( )
- 可以一次存储多个、且 可以是不同的数据类型 、支持嵌套
[ [1,2.3] , [4,5,6] ]
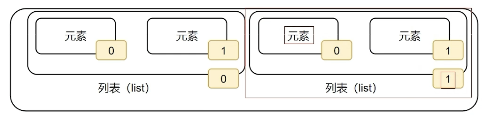
下标索引
从而在列表中取出特定元素 print( name_list [0] ) 、 print( name_list [-1] ) 、 print( name_list [1] [0] )
常用操作
将函数定义为class(类)的成员则叫做 方法 ,和函数一样有传入参、返回值,只是使用格式不同
-
插入
在指定位置传入指定的元素
mylist.insert( 1,EXAMPLE03 ) -
查询
查找指定元素在列表中的下标,找不到则ValueError
index = mylist.index("example01")验证 :
print(f"example01在列表中的下标索引值是{index}") -
追加
mylist,append( [4,5,,6] ), 只能插入到尾部也可以追加一批元素,通过 “将其他容器内容取出再依次追加” 实现
mylist.extend(myLIST2) -
删除
①删指定下标的某单个:
del mylist[2]或mylist.pop(2)(同时可以接收被pop删除的元素:element = mylist.pop(2))②删除某元素在列表中的第一个匹配项:
mylist.remove(2)实现的是“从前到后搜索2这个元素并删除第一个出现的2”,比如[ 1 2 3 2 5 ]会变成[ 1 3 2 5 ] -
清空
mylist.clear() -
修改
本质是赋值语句:
mylist [0] = "EXAMPLE02" -
统计个数
①有几个某元素:
print( mylist.count(1) )②总共个数:
count = len(mylist)
遍历
有 从容器内依次取出元素 的需求,亦称作 迭代
如何遍历?——while(/for)
如何在循环中取出列表元素?——下标索引
循环条件如何控制?——定义一个下标值小于列表的元素数量
index = 0 # 初始下标为0
while index < len(mylist):
# 通过index变量取出对应下标的元素
element = mylist[index]
print(f"列表的元素:{element}")
# 至关重要:将循环变量(index)每一次循环都+1
index += 1
元组tuple
格式
列表可以修改,想要信息不被篡改,即可以理解为 “元组是只读的list”
元组内只有单个元素时记得打一个逗号
特点
和list一样支持嵌套、下标索引取出等
操作
| index | 查找某个,存在则返回对应下标,反之报错 | |
| count | 统计某数据出现次数 | |
| len | 统计元素个数 |
index = t6.index("程序员")
num = t7,count ("程序员")
num = len(t8)
字符串str
字符的容器,修改、移除、追加均无法完成
-
查找
找“and”的位置:
value = mystr.index("and")
例如,如果
mystr的值是 “I like apples and oranges”,那么mystr.index("and")将返回 12,因为子字符串 “and” 第一次出现在索引位置 12 处
- 替换(把所有字符串aaa替换成bbb):
new_mystr = mystr.replace("aaa","bbb")
替换是得到新字符串而不是修改老字符串
-
分割:
划分成多个字符串并存入对象中
mystr = "Hello, my name is John" result = mystr.split() print(result)
将字符串 mystr 分割成多个 子字符串 ,使用空格作为分隔符。然后赋值给 result ;
输出结果就是把原始字符串 按空格分割 的各个 子字符串 组成的列表 ['Hello,', 'my', 'name', 'is', 'John']。
- 规整:
去除前后空格:字符串.strip()
去除前后指定字符串:字符串.strip(字符串) 【此种传参若不给定则用默认值】

注意到“12”和“21”都被去除掉了,故其原理是不考虑顺序的,一旦出现就会被去除。
-
统计出现次数:
count = mystr.count("APPLE") -
统计字符串长度:
num = len(mystr)
容器的切片
-
内容连续、有序、可下标索引的一类容器,可包括list、tuple、str...
-
从一段序列截取出一段子序列
sequence[start:stop:step]start:起始索引,表示切片开始的位置(包含该位置的元素),默认为 0。stop:终止索引,表示切片结束的位置(不包含该位置的元素),默认为序列的长度。step:步长,表示每次取元素的间隔,默认为 1
mystr = "Hello, World!" # 获取从索引 7 开始到结尾的子字符串 print(mystr[7:]) # 输出: "World!" # 获取从索引 0 到索引 5 之间的子字符串 print(mystr[0:5]) # 输出: "Hello" # 使用负数索引获取从倒数第 6 个元素到倒数第 2 个元素之间的子序列 print(mystr[-6:-1]) # 输出: "World" # 使用步长为 2 获取所有偶数索引位置上的字符 print(mystr[::2]) # 输出: "Hlo ol!" # 反转整个序列 print(mystr[::-1]) # 输出: "!dlroW ,olleH"需要注意的是,切片操作返回的是一个新的序列,原始序列保持不变。
集合set
定义格式
需求场景:去重处理(自带去重且内容无序)
myset = {elem1, elem2, ...}
或者定义空集
myset = set()
特点
elem1、elem2 等是集合中的元素,可以是整数、浮点数、字符串、元组等
# 使用花括号定义集合
fruits = {"apple", "banana", "orange"}
# 使用set()函数定义集合
numbers = set([1, 1, 1, 2, 3, 4, 5])
# 使用set()函数将其他可迭代对象转换为集合
characters = set("Hello")
# 打印出集合的内容
print(fruits) # 输出: {'banana', 'orange', 'apple'}
print(numbers) # 输出: {1, 2, 3, 4, 5}
print(characters) # 输出: {'H', 'o', 'e', 'l'}
示例中首先使用花括号定义了一个字符串集合
fruits,其中包含 “apple”、“banana” 和 “orange” 三个元素;使用
set()函数将列表[1, 2, 3, 4, 5]转换为整数集合numbers;使用
set()函数将字符串 “Hello” 转换为字符集合characters。打印这些集合的内容;可以看到集合是无序的,并且不包含重复的元素。【故不支持下标索引, 但支持修改,见下】
常见操作
-
添加元素(Addition):
- 使用
add()方法向集合中添加单个元素。 - 使用
update()方法向集合中添加多个元素。
fruits = {"apple", "banana"} fruits.add("orange") print(fruits) # 输出: {'banana', 'orange', 'apple'} fruits.update(["grape", "watermelon"]) print(fruits) # 输出: {'banana', 'orange', 'grape', 'apple', 'watermelon'} - 使用
-
删除元素(Removal):
- 使用
remove()方法删除指定元素,如果元素不存在则会引发错误。 - 使用
discard()方法删除指定元素,如果元素不存在不会引发错误。 - 使用
pop()方法删除并返回集合中的一个元素。
fruits = {"apple", "banana", "orange"} fruits.remove("banana") print(fruits) # 输出: {'orange', 'apple'} fruits.discard("watermelon") print(fruits) # 输出: {'orange', 'apple'} removed_element = fruits.pop() print(removed_element) # 输出: 'orange' print(fruits) # 输出: {'apple'} - 使用
-
集合运算(Set operations):
- 并集(Union): 使用
union()或|运算符。 - 交集(Intersection): 使用
intersection()或&运算符。 - 差集(Difference): 使用
difference()或-运算符。 - 对称差集(Symmetric Difference): 使用
symmetric_difference()或^运算符。
set1 = {1, 2, 3, 4, 5} set2 = {4, 5, 6, 7, 8} union_set = set1.union(set2) print(union_set) # 输出: {1, 2, 3, 4, 5, 6, 7, 8} intersection_set = set1.intersection(set2) print(intersection_set) # 输出: {4, 5} difference_set = set1.difference(set2) print(difference_set) # 输出: {1, 2, 3} symmetric_difference_set = set1.symmetric_difference(set2) print(symmetric_difference_set) # 输出: {1, 2, 3, 6, 7, 8} - 并集(Union): 使用
-
子集与超集的判断(Subset and Superset checking):
- 使用
issubset()方法检查一个集合是否是另一个集合的子集。 - 使用
issuperset()方法检查一个集合是否是另一个集合的超集。
set1 = {1, 2, 3, 4, 5} set2 = {1, 2, 3} is_subset = set2.issubset(set1) print(is_subset) # 输出: True is_superset = set1.issuperset(set2) print(is_superset) # 输出: True集合不支持下标索引所以不能用while遍历
- 使用
字典、映射dict
用于存储键-值对。字典提供了一种非常快速和高效的方式来根据键来查找和访问对应的值
key不可以重复,后来者所带的value会覆盖前者;
字典也没有下标索引;
除了key内不可嵌套字典,其他都可以嵌套;
示例,说明如何使用字典的嵌套来表示学生的多个属性:
students = {
"john": {
"age": 20,
"major": "Computer Science",
"grades": [75, 80, 90]
},
"alice": {
"age": 21,
"major": "Mathematics",
"grades": [85, 90, 95]
},
"bob": {
"age": 19,
"major": "Physics",
"grades": [70, 75, 80]
}
}
students 字典包含三个键-值对,每个键都是学生的姓名。每个学生对应一个嵌套的字典,该字典存储了学生的信息,包括年龄(age)、专业(major)和成绩(grades)。
新增元素:
fruits = {"apple": 3, "banana": 5, "orange": 2}
# 使用索引操作符新增元素
fruits["grape"] = 4
# 使用update()方法新增元素
fruits.update({"watermelon": 1})
print(fruits)
# 输出: {'apple': 3, 'banana': 5, 'orange': 2, 'grape': 4, 'watermelon': 1}
创建一个含有苹果、香蕉和橙子的字典。然后,我们使用索引操作符 [],将 "grape" 和其对应的值 4 添加到字典中。接着,使用 update() 方法,传入一个包含 "watermelon" 和其对应值 1 的字典,将其添加到原有字典中。
更新元素:
fruits = {"apple": 5, "banana": 7, "orange": 3}
# 使用索引操作符更新元素
fruits["apple"] = 8
# 使用update()方法更新元素
fruits.update({"banana": 10})
print(fruits)
# 输出: {'apple': 8, 'banana': 10, 'orange': 3}
新增(更新)时,如果原有键已存在,会将其更新为新的值;如果原有键不存在,则会新增该键和对应的值。
删除元素:
fruits = {"apple": 3, "banana": 5, "orange": 2}
# 使用del语句删除元素
del fruits["banana"]
# 使用pop()方法删除元素
removed_value = fruits.pop("apple")
print(fruits) # 输出: {'orange': 2}
print(removed_value) # 输出: 3
清空字典:
fruits = {"apple": 3, "banana": 5, "orange": 2}
# 使用clear()方法清空字典
fruits.clear()
print(fruits) # 输出: {}
要获取字典中的所有键,可以使用字典对象的 keys() 方法。该方法会获得字典中的所有键。
fruits = {"apple": 3, "banana": 5, "orange": 2}
# 获取所有的键并转换为列表
keys_list = list(fruits.keys())
print(keys_list)
# 输出: ['apple', 'banana', 'orange']
# 使用循环获取所有的键
for key in fruits.keys():
print(key)
# 输出:
# apple
# banana
# orange
通用操作

遍历:五类都支持for遍历,集合和字典不支持while
len、max、min: (容器) 是通用的
容器类型具有通用的排序功能,可以使用内置的 sorted() 函数进行排序。下面是一个例子:
fruits = ["apple", "banana", "orange", "grape"]
sorted_fruits = sorted(fruits)
print(sorted_fruits)
# 输出: ['apple', 'banana', 'grape', 'orange']
使用 sorted() 函数对该列表进行排序,并将结果保存在 sorted_fruits 变量中。
输出结果为 ['apple', 'banana', 'grape', 'orange'],表示水果列表按字母顺序进行了排序。
sorted() 函数返回一个新的已排序的列表,不会修改原始列表。如果希望在原地对列表进行排序(即修改原始列表),可以使用列表的 sort() 方法。
可以使用比较运算符(如 <、>、<=、>=、==、!=)对字符串进行大小比较。这些比较运算符按照字符的字典顺序进行比较,即比较每个字符的 Unicode 值。下面是一个字符串大小比较的例子:
str1 = "apple"
str2 = "banana"
if str1 < str2:
print("str1 is less than str2")
elif str1 > str2:
print("str1 is greater than str2")
else:
print("str1 is equal to str2")
两个字符串 str1 和 str2,分别表示 “apple” 和 “banana”。使用 < 和 > 比较运算符进行大小比较。根据字典顺序,“apple” 在 “banana” 之前,因此 str1 < str2 返回 True,将打印 “str1 is less than str2”。

