
软考设计师上午题
数据的表示:源码-反码-补码
原码:十进制转化为二进制,正数不变,负数符号位为1.
反码:原码基础上,符号位不变,其他位取反.
补码:反码加1
移码:符号位取反
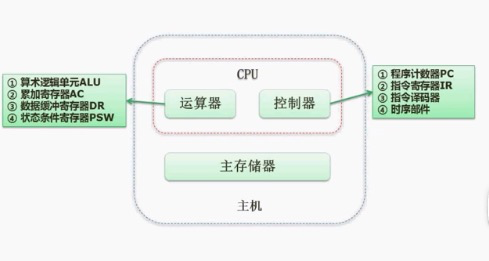
CPU结构:
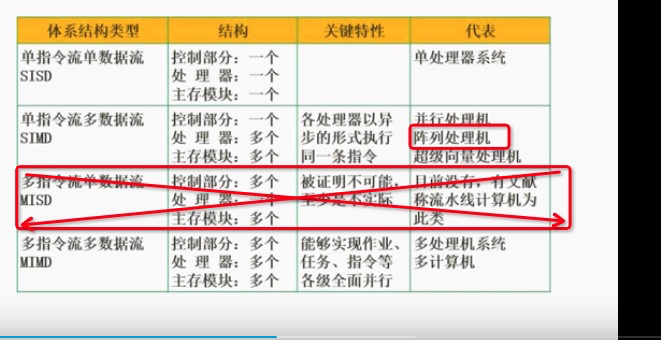
指令数据流:
CISI与RISC

流水线计算:


答:203ns = 5+99*2
流水线吞吐率 = 指令条数/流水线执行时间
上例中:吞吐率 = 100/203
流水线最大吞吐率 = 1/流水线周期
上例中:最大吞吐率 = 1/2
流水线的加速比 = 不使用流水线的执行时间/使用流水线的执行时间
上例中:流水线加速比 = 500/203
层次化存储结构
cache是在存储体系中,寄存器是最快的,cache是其次。
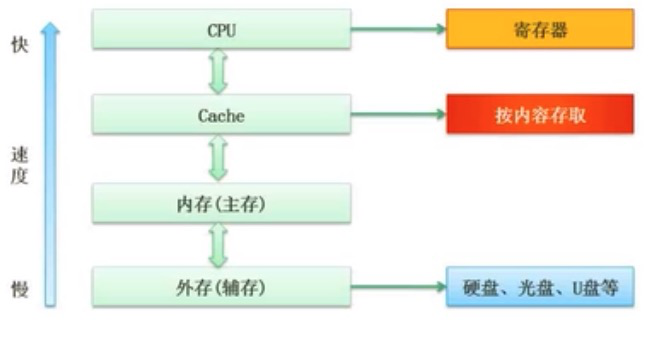
cache概念

存储器
随机存储器RAM
只读存储器ROM
ROM存储器只能读,数据一旦写入则不可更改,掉电后数据不丢失。
RAM存储器可以随时读和写,掉电后数据会自动消失。

磁盘
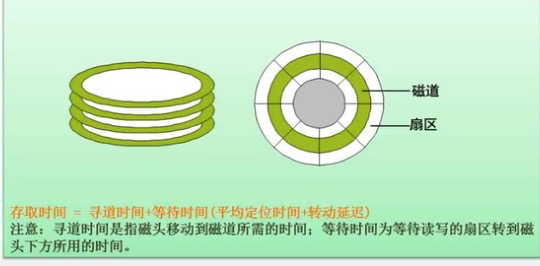
计算:
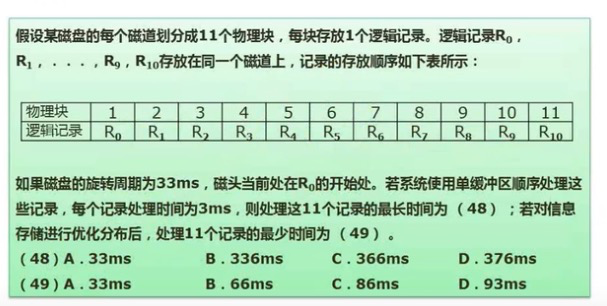
注意:这里单个物理块的时间为磁盘旋转周期+处理时间。
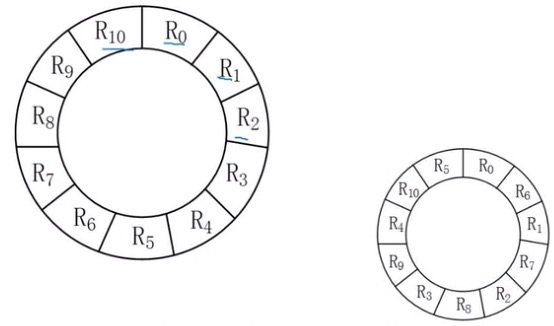
当处理R0时,磁盘旋转时间+处理时间 花了6ms,此时磁头出于R2的位置,所以时间为 6 + (10*30) + 6*10 = 366
最少时间为第二个圈圈的时间为6*11 = 66.所以选C,B。
可靠度计算
串并联混合可靠度计算
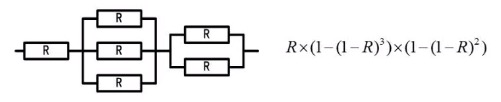
自己画图,写写公式。
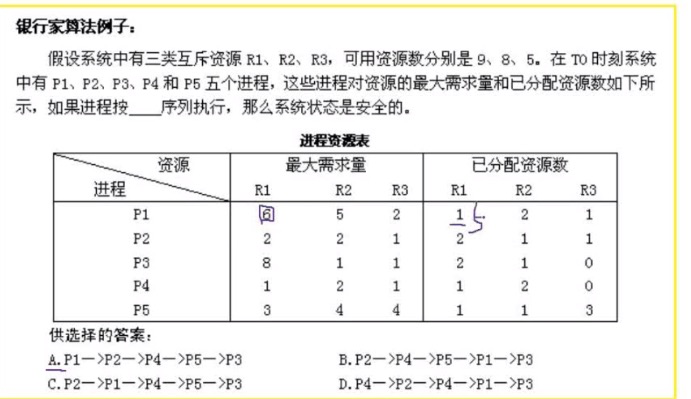
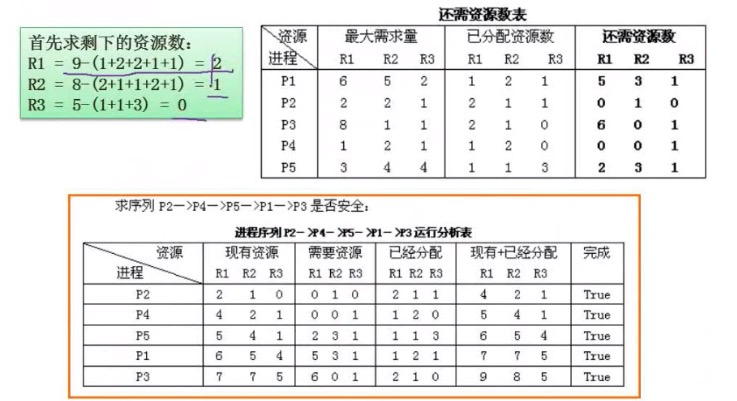
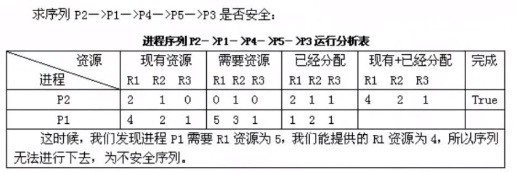
PV操作
要会画图
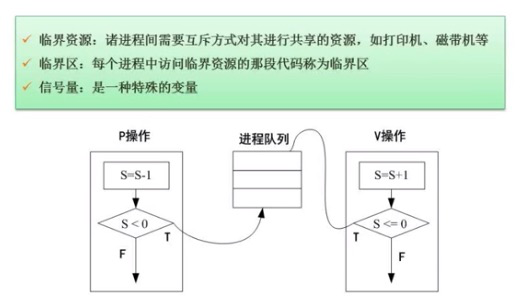
例题:
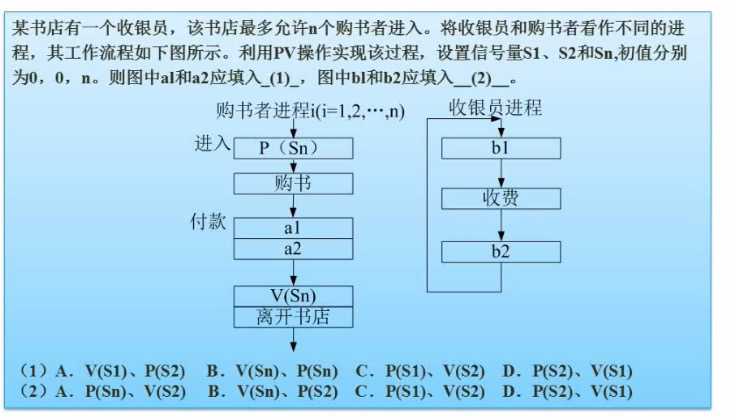
他们是一对的,选AC。
PV操作与前驱图
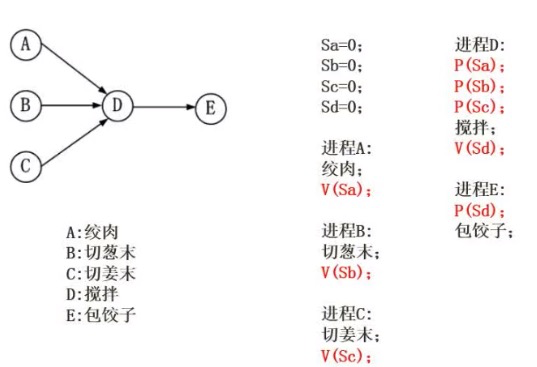
箭头开始位置有V操作,箭头结束位置有P操作。
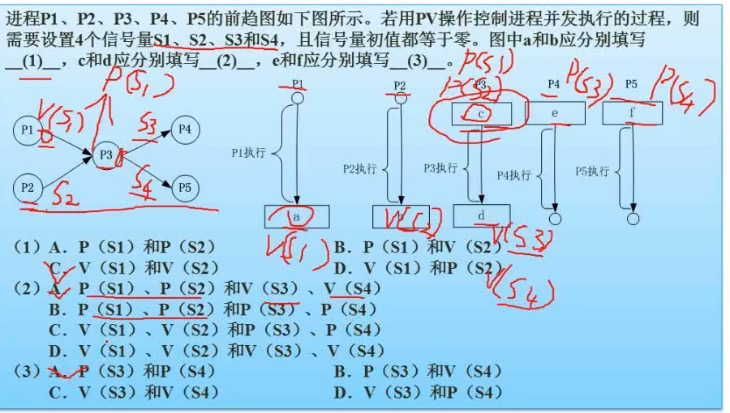
CAA
死锁
本质是资源问题,所有的进程都在等待其他进程释放资源,但是其他进程也在等待资源,此时就会有死锁。
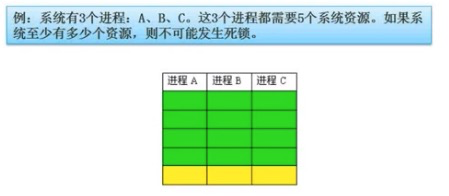
最少资源 = 资源数*(进程数-1)+1
页式存储
里面会有一个页面表示物理地址和逻辑地址的映射,这里的物理地址又称为页帧号。

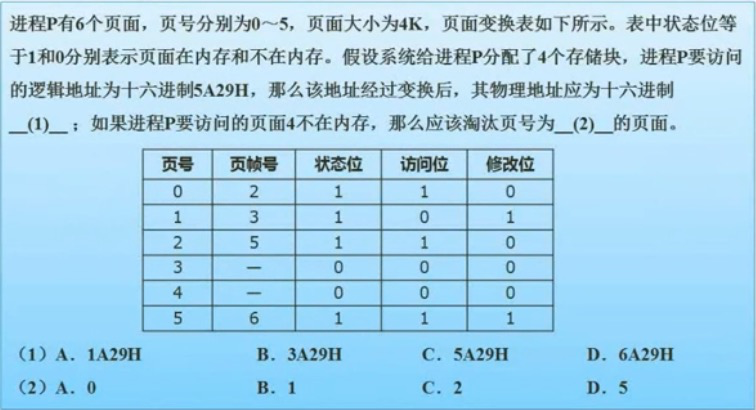
5A29H, 5表示逻辑的也好,那么在上图的映射中物理地址(页帧号)为6,选择D。
要访问进程P,那么数据是需要在内存中并且没有被访问的,此时只有1符合条件,选择B。
段式存储
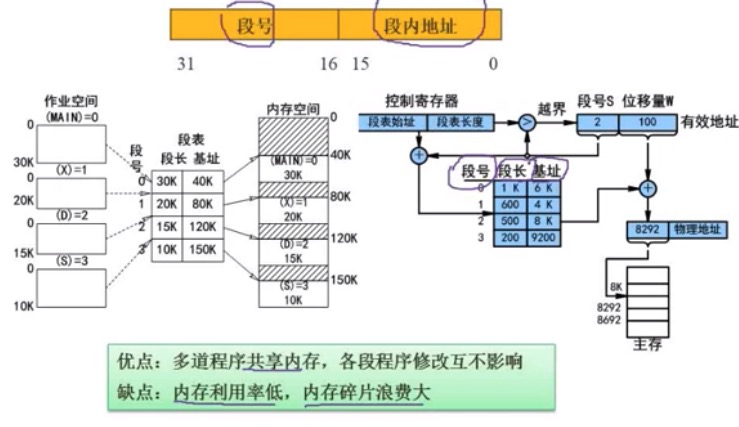

例:
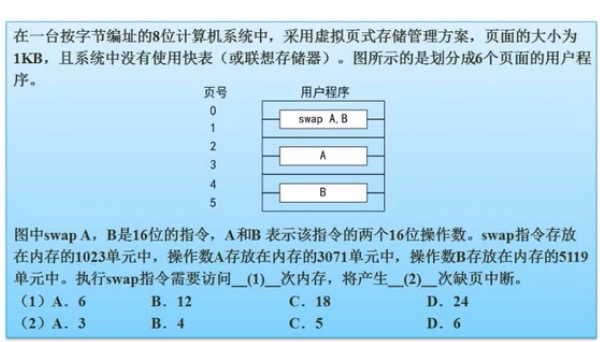
如图所示有指令、A、B各占用2个页,所以有6个块,每个块会访问2次内存,2*6 = 12 ,选择B。
指令块不会产生两次缺页中断,只会产生一次 。所以总共有5次,选择C。
例:
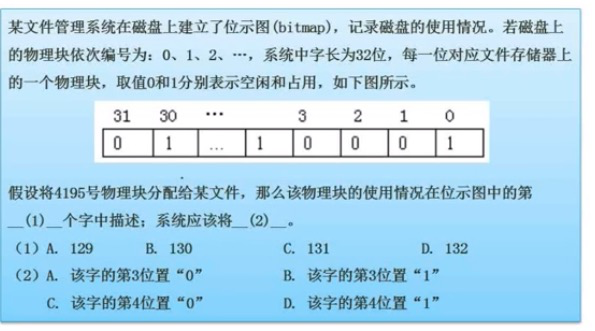
物理块是从第0号开始,所以(4195+1)/ 31 = 131 余 4,所以选择D。
余4的话,从第0号开始,那么应该将第3号置位1.
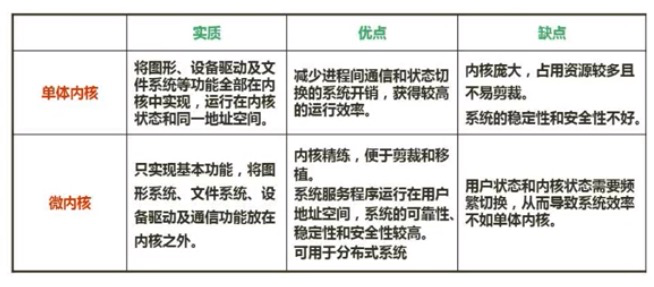
微内核操作系统
数据库三级模式两级映射
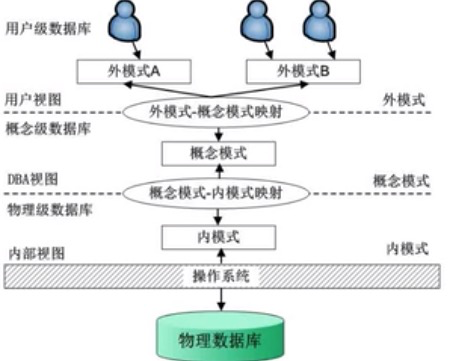
观察上图,由上到下依次为 用户、外模式、映射1(外模式/模式映射)、概念模式、映射2(模式/内模式映射)、内模式。
外模式是模式的一部分,是部分用户看到的数据库的样子。
内模式处于最底层,是对数据在数据库底层的存储的描述。
外模式/模式映像保证了当模式改变时,外模式不用变 (逻辑独立性)
模式/内模式映像保证了当内模式改变时,模式不用变 (物理独立性)
数据库设计过程
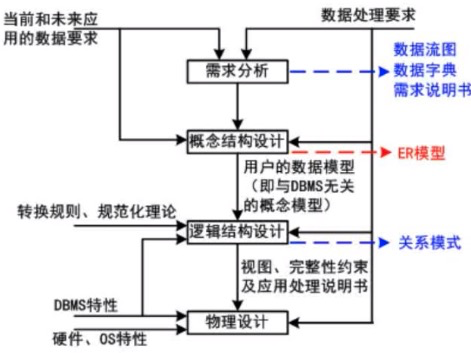
E-R模型
多对多中:一个实体转化为一个关系模式,联系单独也是一个关系模式。
1对多 或者 多对多中:个实体转化为一个关系模式,联系可以放入其中一个实体中。
关系代数

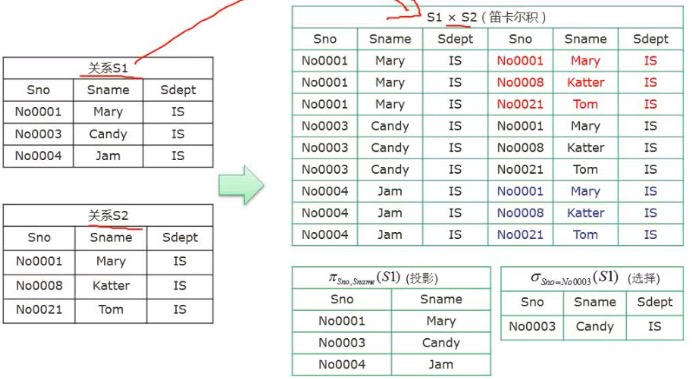
连接操作会把两个数据集都有的字段相等的数据连接起来
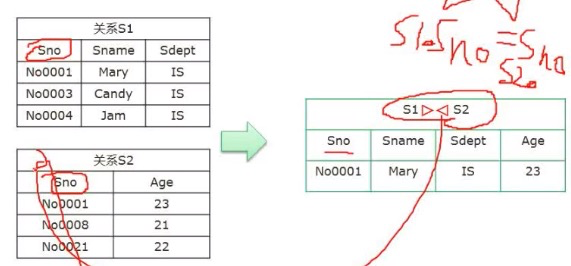
键
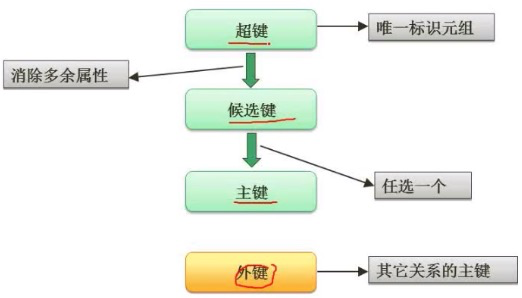
候选键可以有多个,主键只能有一个,有几个字段都可以作为主键,但是只能有一个字段作为主键。
求候选键


如图,A1入度为0,且可以遍历所有节点,所以候选键为A1。
例:

注意ABD->E只可以图上这么画,不能单独分开来画,分开来表示A只能到E,B只能到E,D只能到E,这是不对的。
如图:ABDC的组合键才是候选码。

选择B。
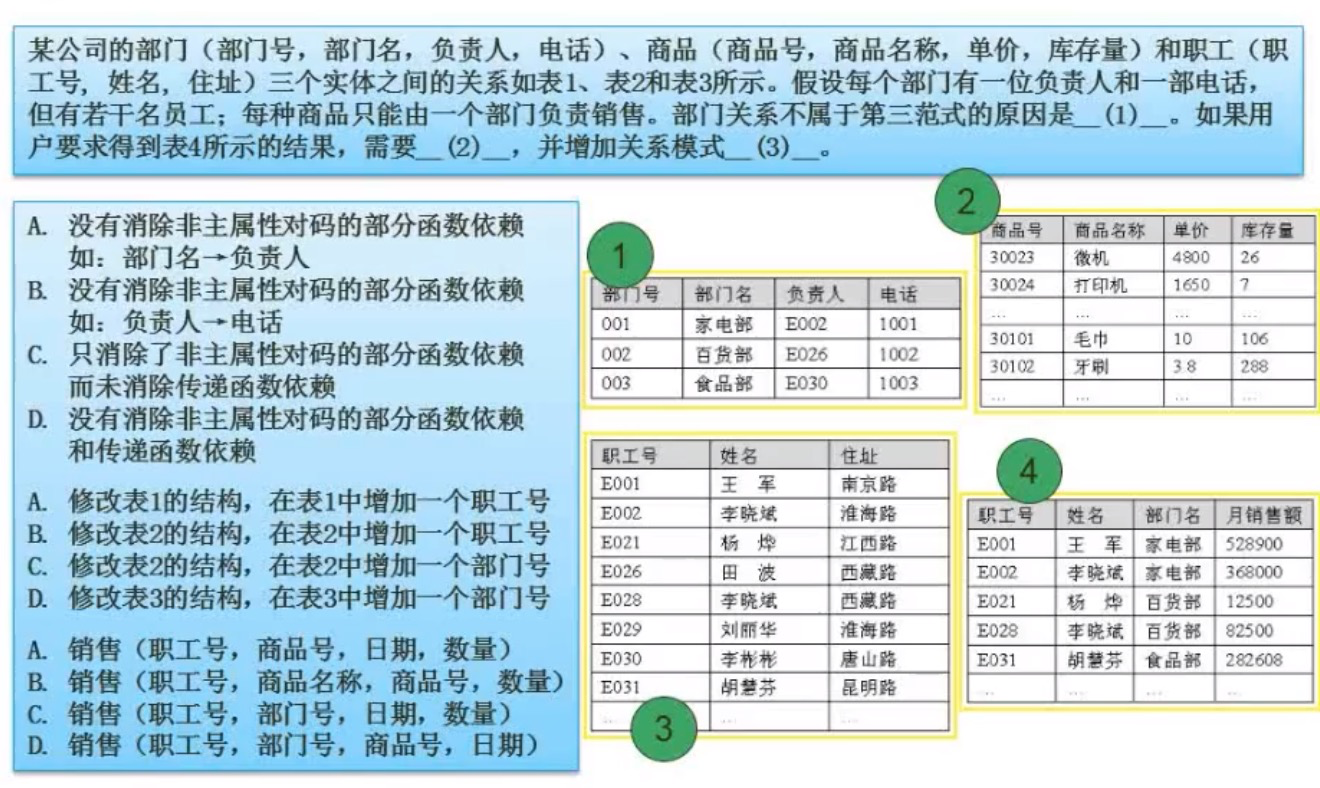
例:一空:有可能不属于第二范式,也可能不属于第三范式,选C。
二空:销售是部门销售,但是部门有多个人,所以还是得针对个人,选D。
三空:C,D中职工号和部门号是有冗余了,他们取一个就够了,排除。B中商品名称和商品号也冗余了,排除。把A带入符合条件,选A。


是无损分解。
判断是否无损分解可以用表格法:
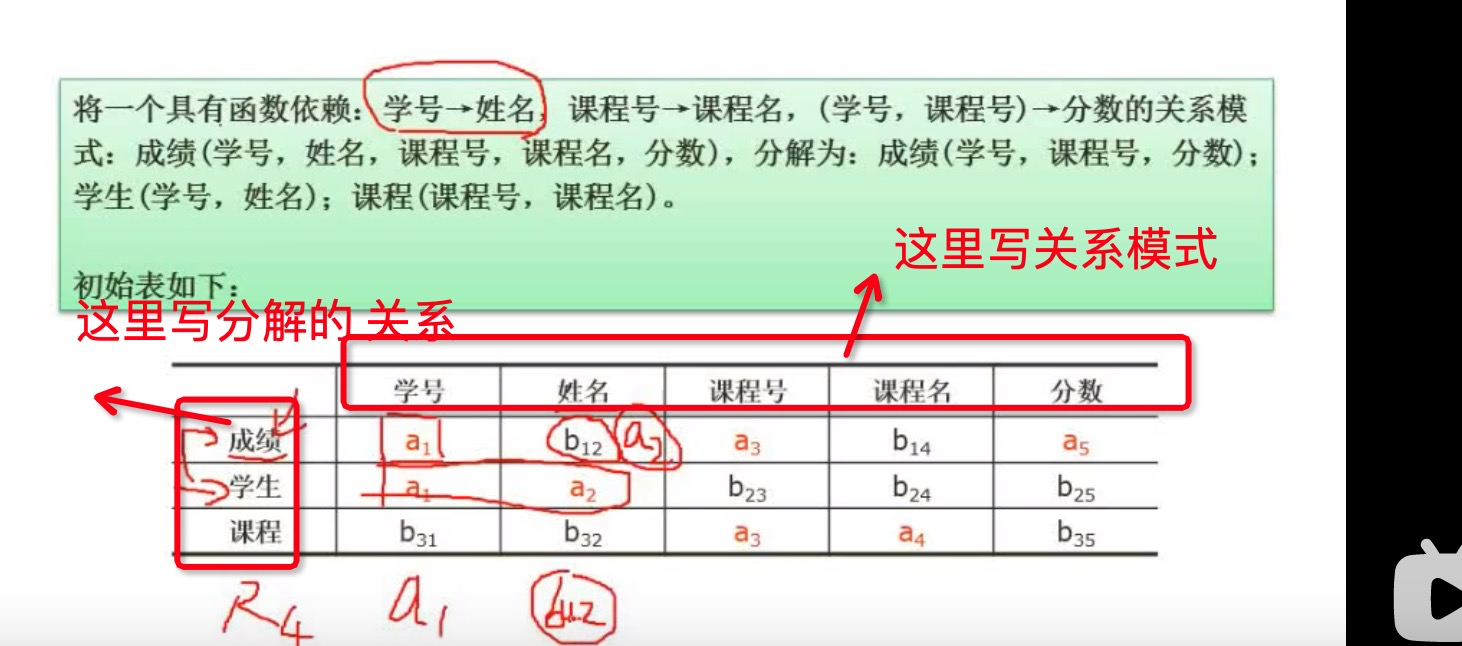
①如图所示列出行头和列头
②看分解出的关系式是否包含上面最初的未分解关系模式里面的属性,如果有就做上记号,如图
③对做上记号的关系式,再根据分解出来的关系式,推出其他的属性是否也可以做出记号,如下图:
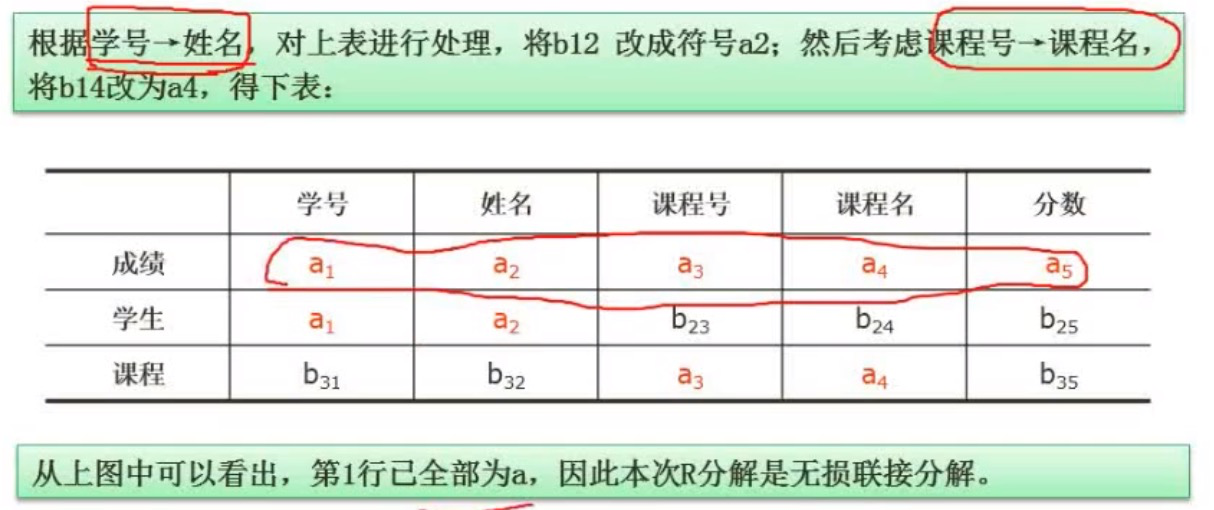
如果有一行全部标记为a,那么就可以当做无损分解。
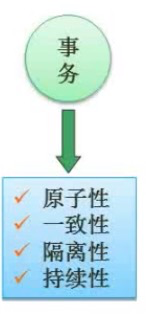
数据库备份
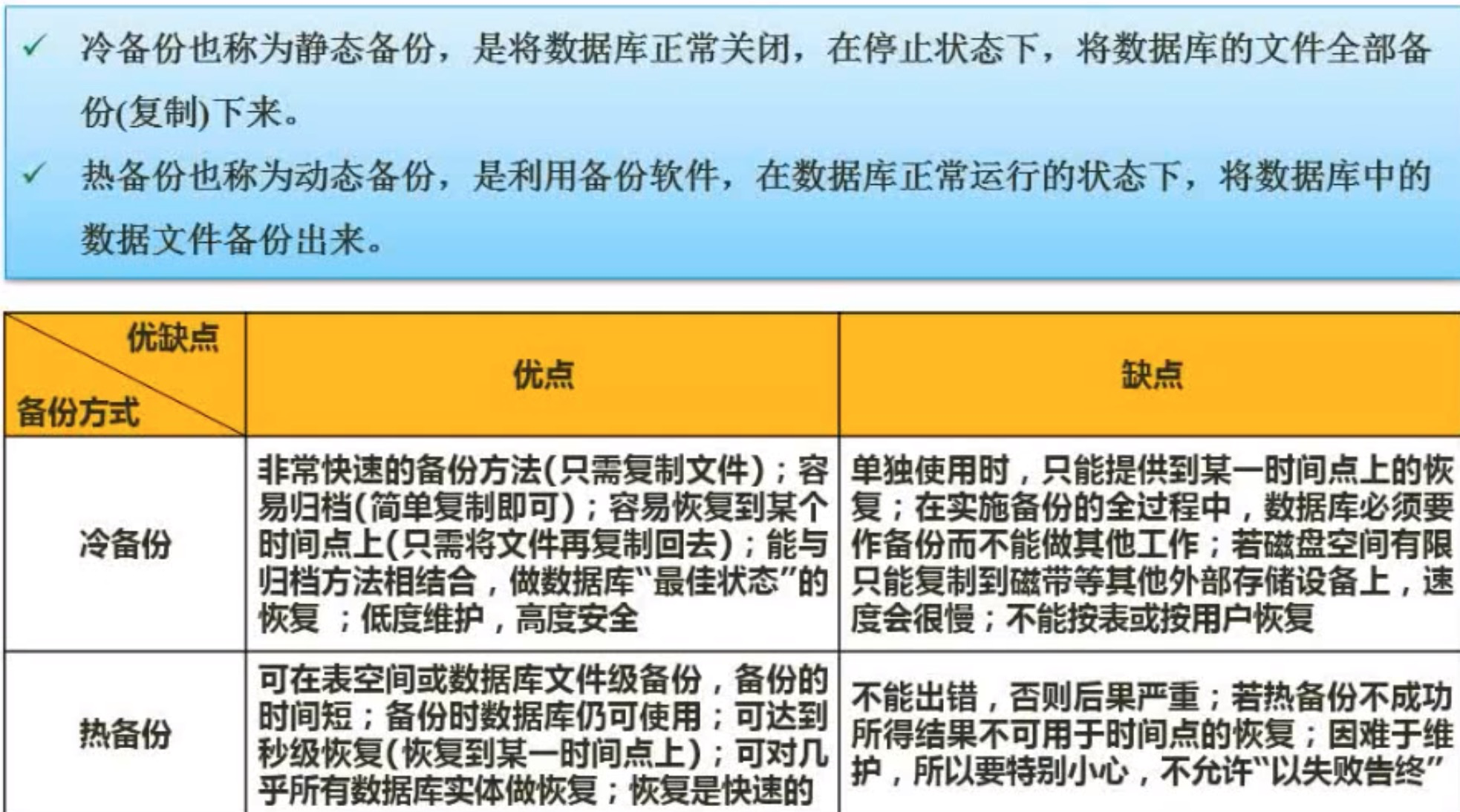


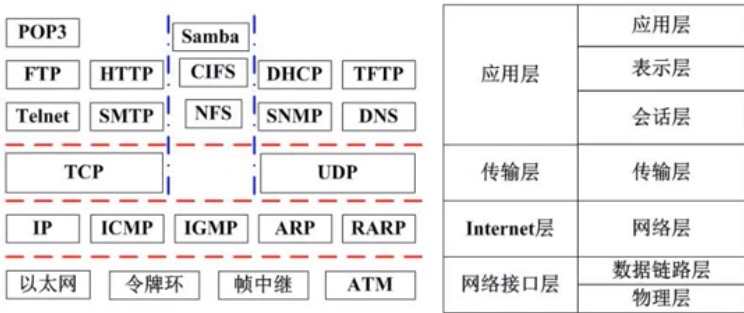
七层模型
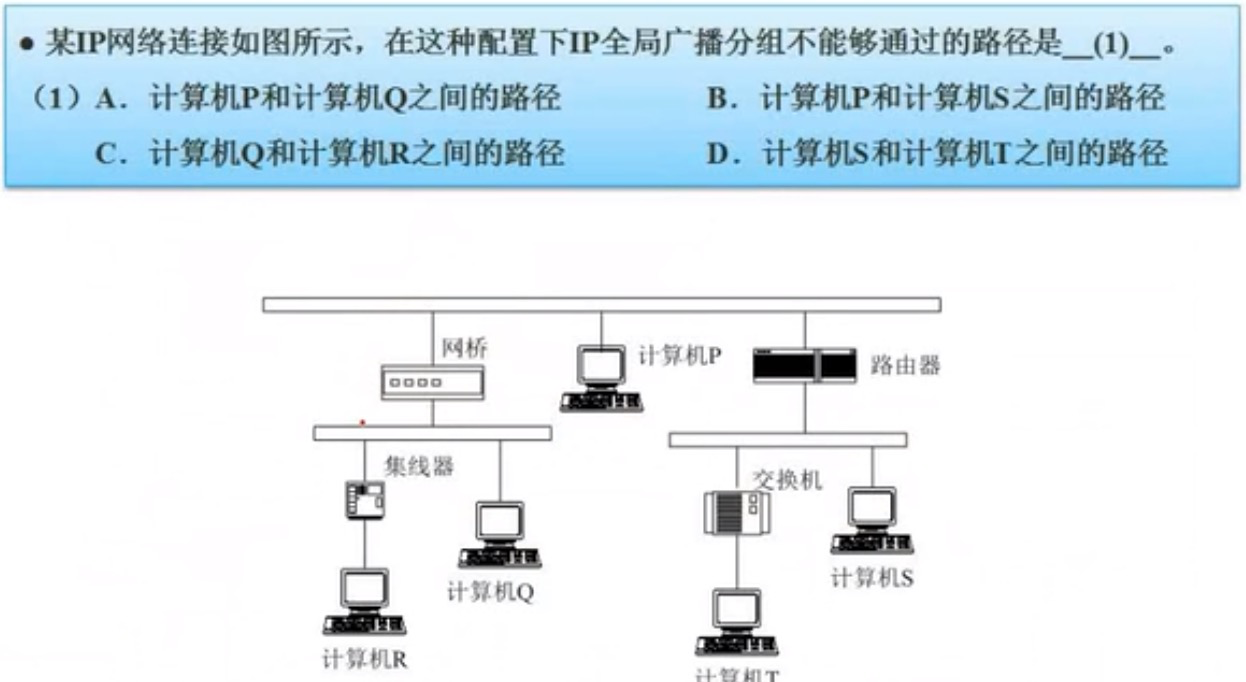
本题主要看是否能在一个局域网(两个就计算机不能跨网,第三层设备,交换机):
A选项中PQ通过网桥,网桥属于第二层数据链路层,是可以的。
B选项PS通过路由器,路由器属于第三层网络层,不能连接。
C选项QR通过集线器链接,属于第一层物理层,是可以的。
D选项ST通过交换机,交换机属于第二层数据链路层,是可以的。
DNS协议
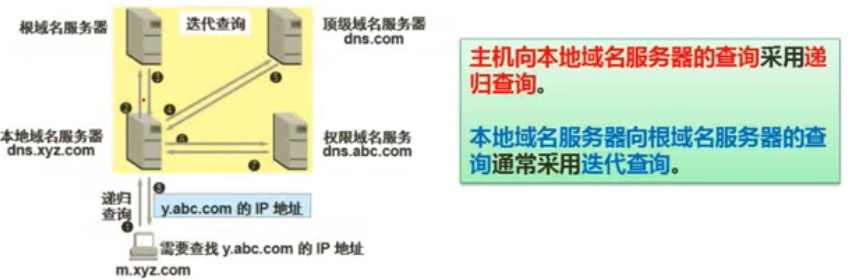
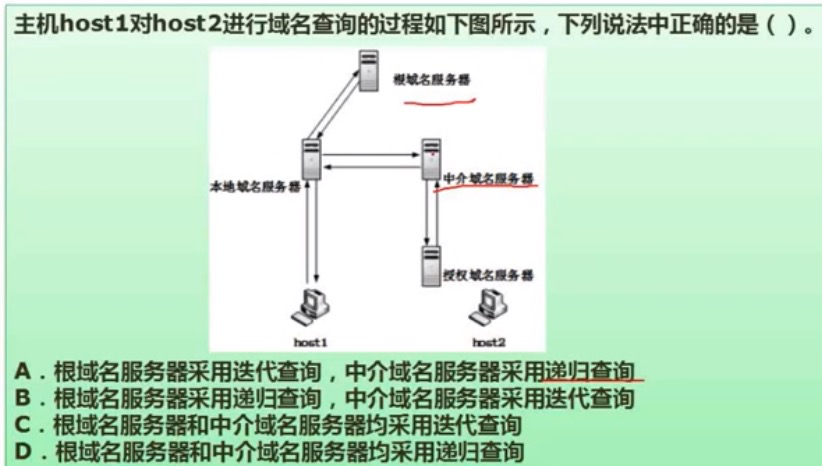
递归服务器会刨根纠底,选A。
计算机网络拓扑结构(优缺点要了解)
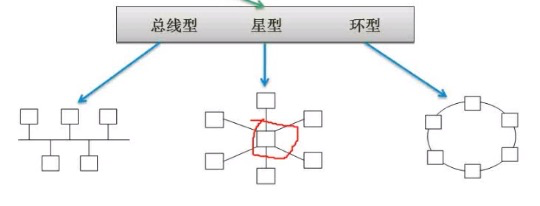
ipv6


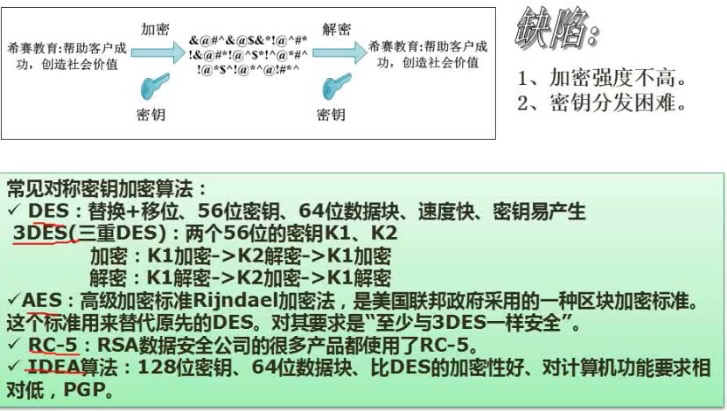
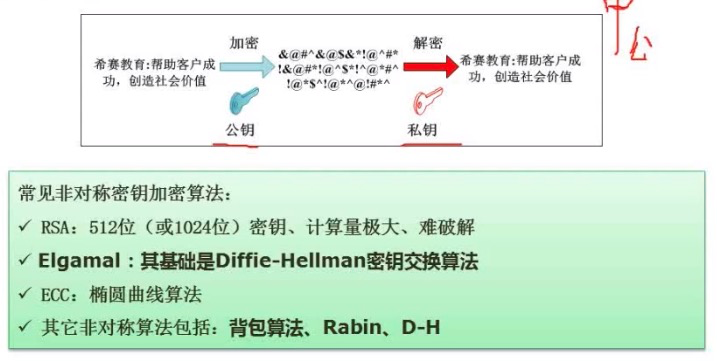
对称加密与非对称加密
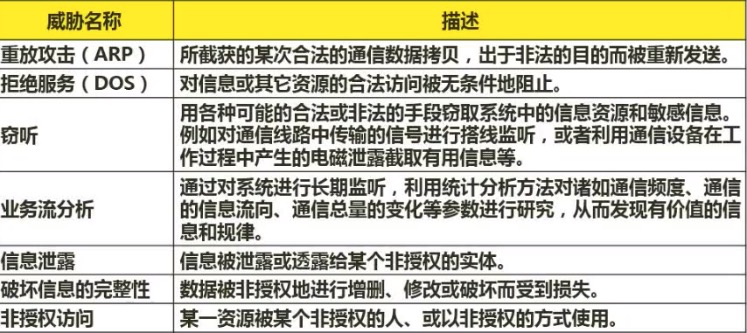
网络攻击

数组

存储地址为 2*5+3 = 13
根据上三角或者下三角 来求变化为一维数组的位置(代入法解题即可)

只有A 代入正确。
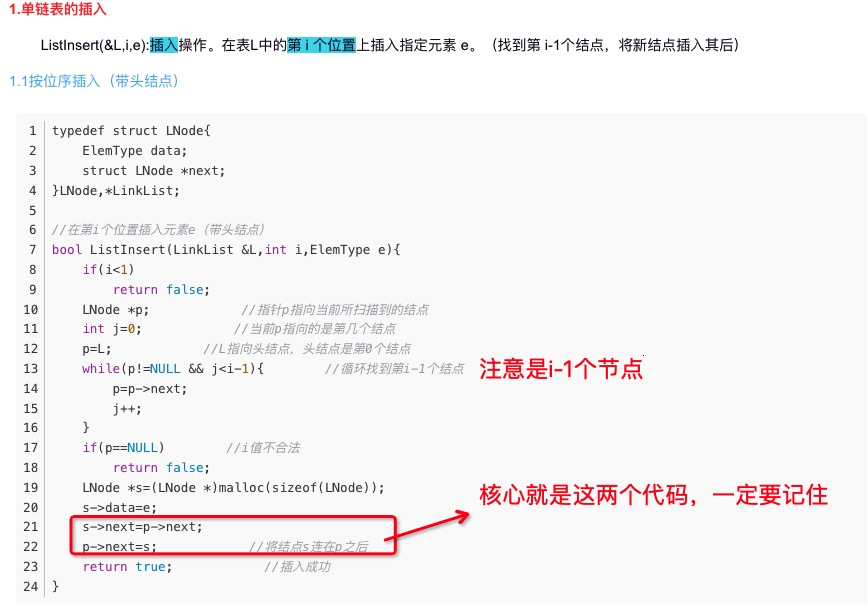
链表的操作
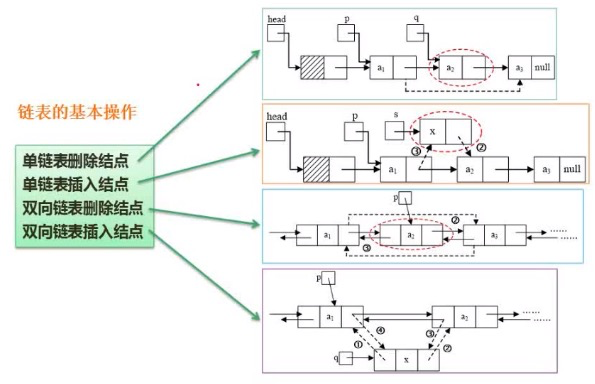
双向链表还没有怎么考到一般考到的是单链表。

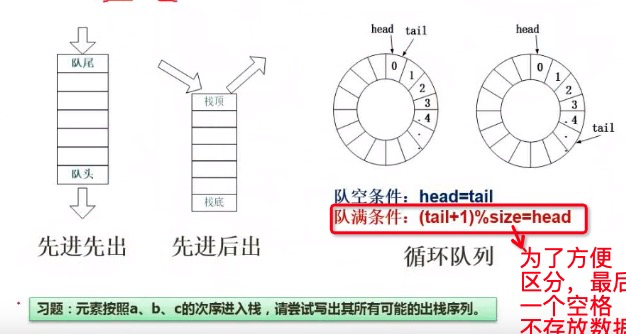
上述习题中,可能出现的顺序有:abc,acb,bca,cba
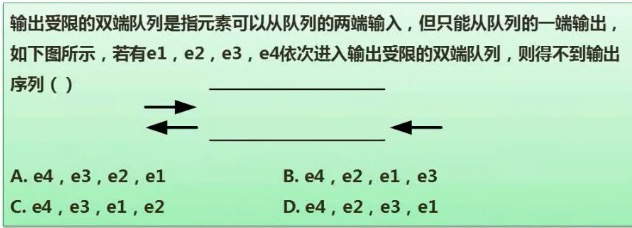
选D,代入法解决,自己想一想,可以弄清楚的。
广义表:

例1:长度为3,深度为2。
例2:head(head(tail(LS1)))
二叉树
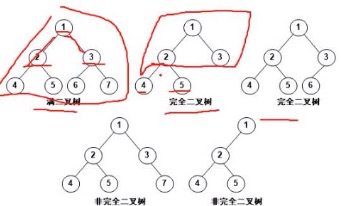
满二叉树:节点都是满的二叉树
完全二叉树:从左万有的节点没有空缺的二叉树

遍历
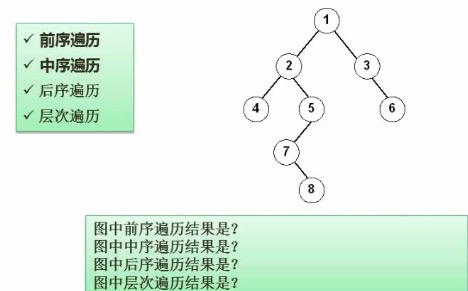
前序:1,2,4,5,7,8,3,6
中序:4,2,7,8,5,1,3,6
后续:4,8,7,5,2,6,3,1
例:
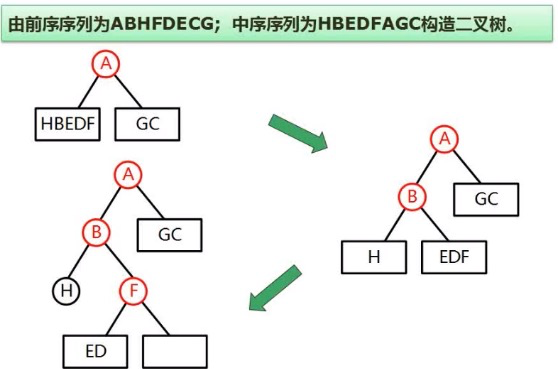
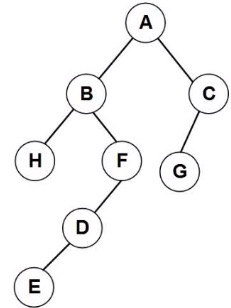
排序二叉树
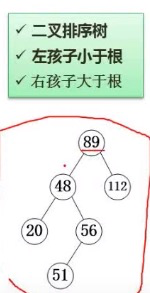
最优二叉树(哈夫曼树)

路径长度:跟结点到当前节点的距离。
带权长度:路径长度*节点值。
树的带权路径长度:所有点点的带权长度累加起来。
自己要多练右边的哈夫曼树的求法,要掌握。
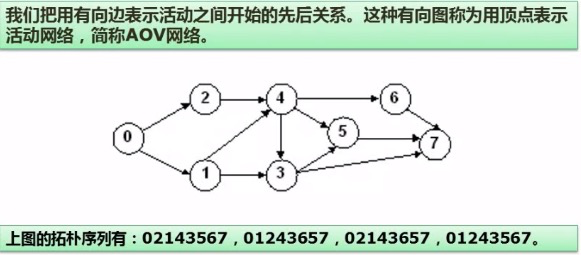
图的遍历
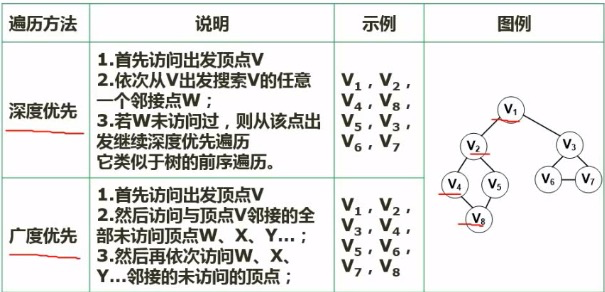
拓扑排序
图的最小生成树
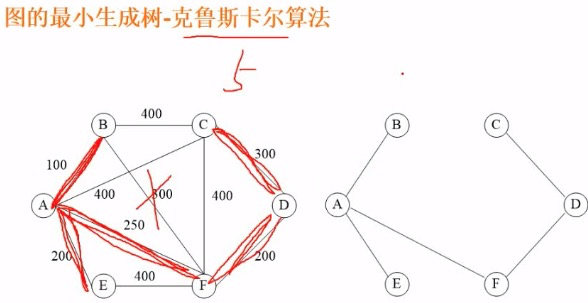
解决图的最小生成树最重要的思路就是找最小权的边,边数=顶点数-1,且不要形成闭环,形成闭环的边要舍弃掉。
时间复杂度

顺序查找时间复杂度

二分查找(注意时间复杂度为O(log2 n))
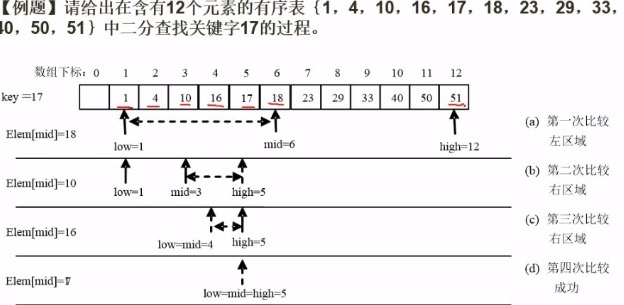
排序
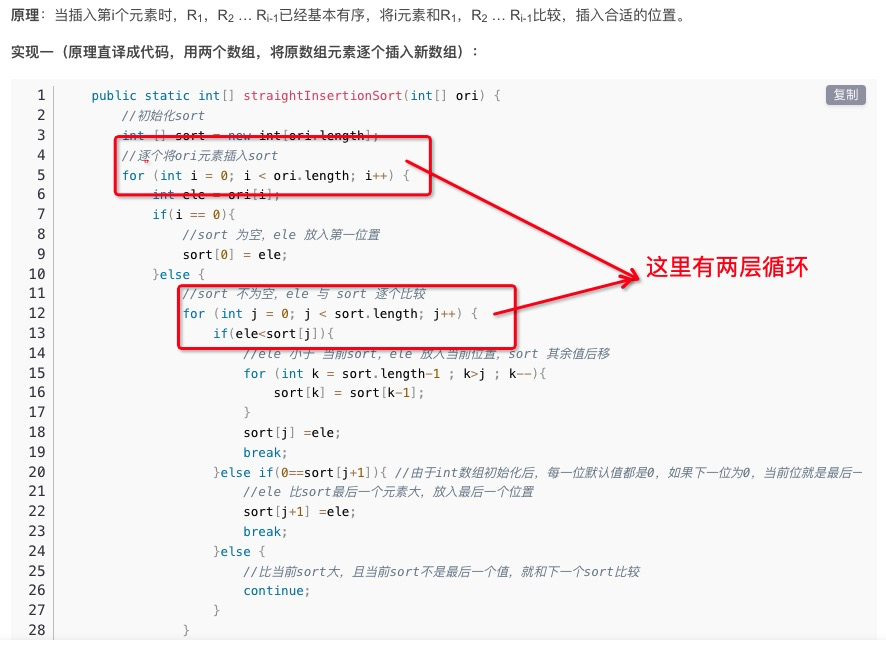
直接插入排序
算法:两个数据集一个已经排好序,一个没有排序,将没有排序的一个一个插入已经排序的正确位置,需要两层循环,那么时间复杂度为O(n2)。
代码如下:
希尔排序(代码实现有点不会)
看如下链接:https://blog.csdn.net/qq_41890240/article/details/122936669
https://blog.csdn.net/NIUBILISI/article/details/89603593
排序有点难,我们先放着吧 到时候需要些代码加深记忆。
编译流程
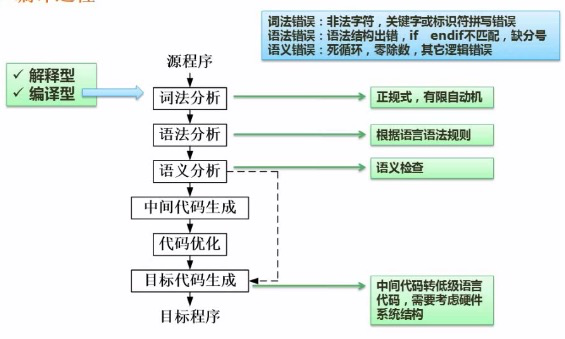
有限自动机

一空:

二空:
解题思路就是把选项带入一空中符合和不符合的情况,然后进行排除。
A选项,一空中的D项都符合,范围太大了 ,所以排除。
B选项,不符合一空的C选项,排除。
C选项符合条件。
保护期限
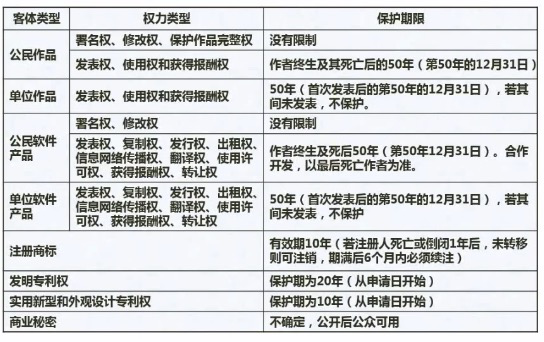
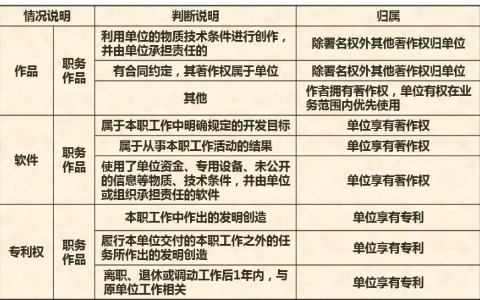



主要是单位的问题 


结构化开发模型:
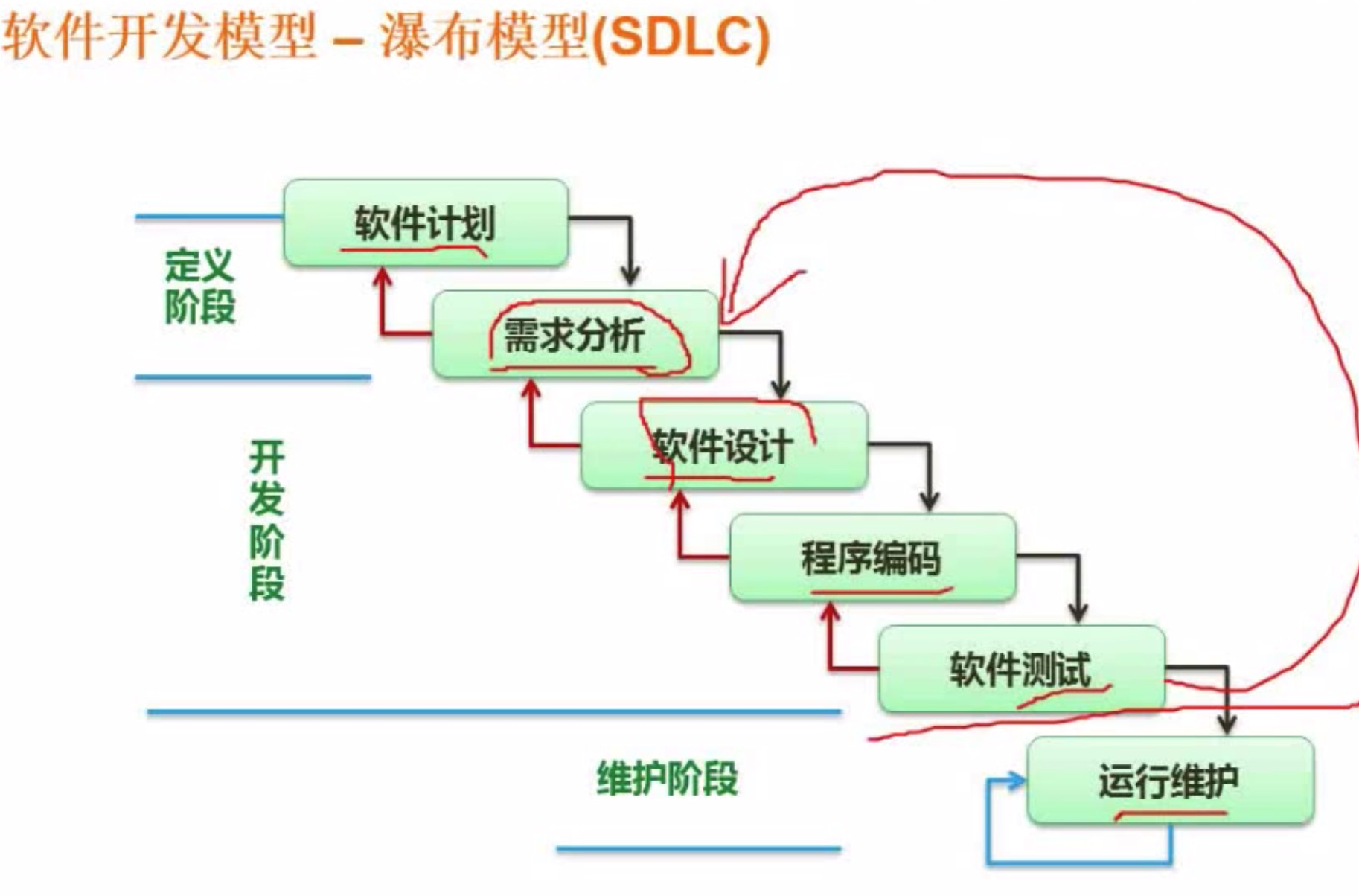
瀑布模型适用于需求明确或者二次开发的情况,需求不明确的项目,不用用瀑布模型。
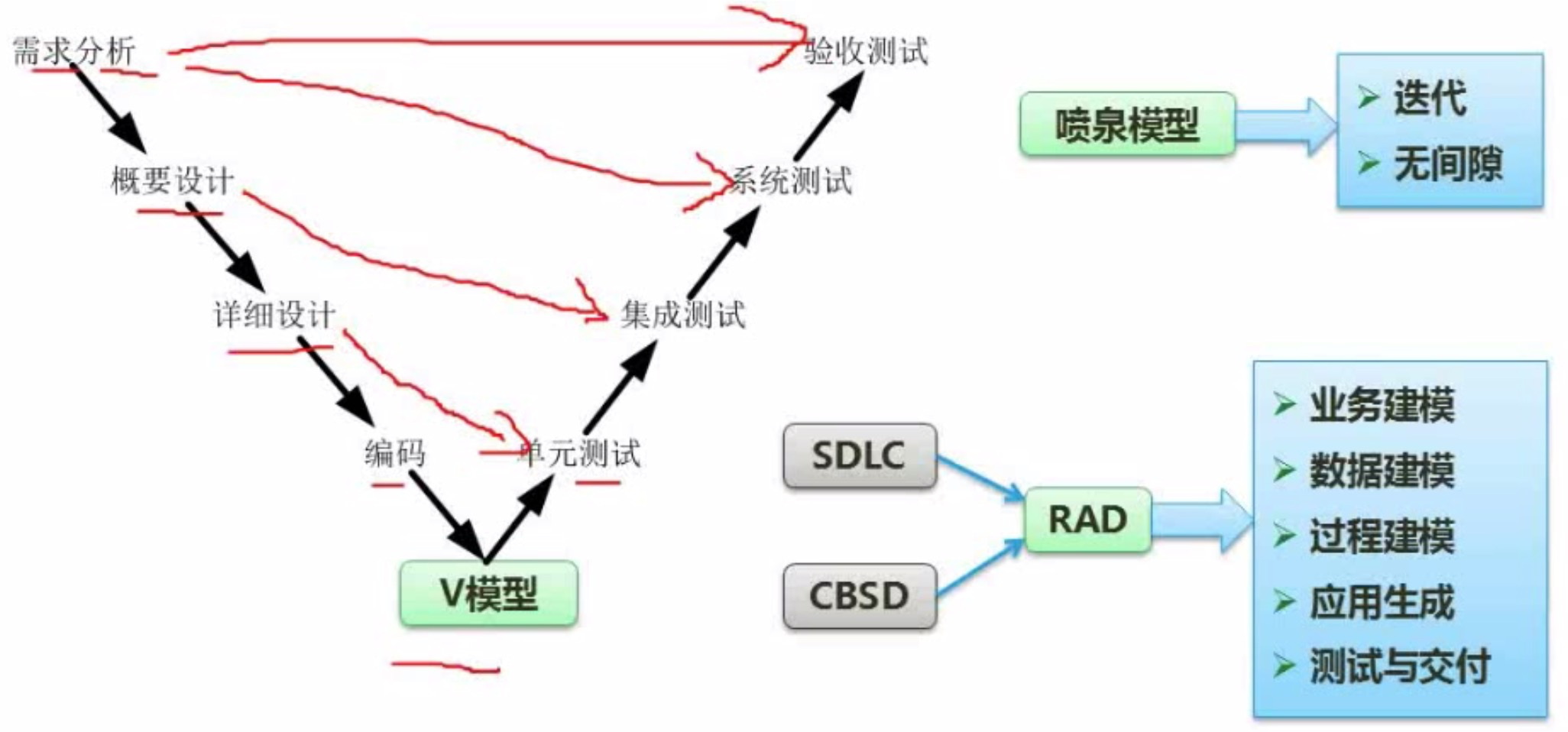
螺旋模型包括原型,以及包括风险分析。
项目管理
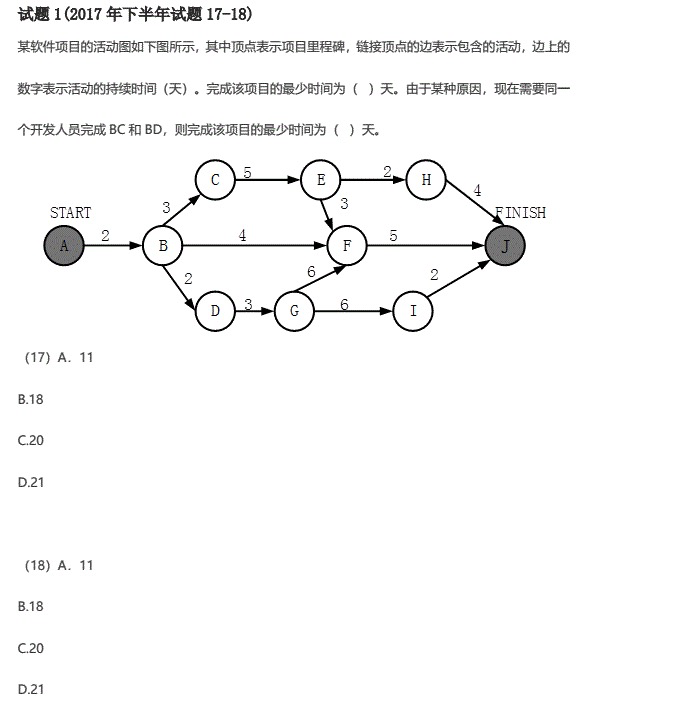


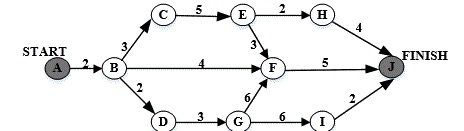

注意:这里BC是8天,因为有两个路经过这里,要最长的减去它,为18-18=0天。
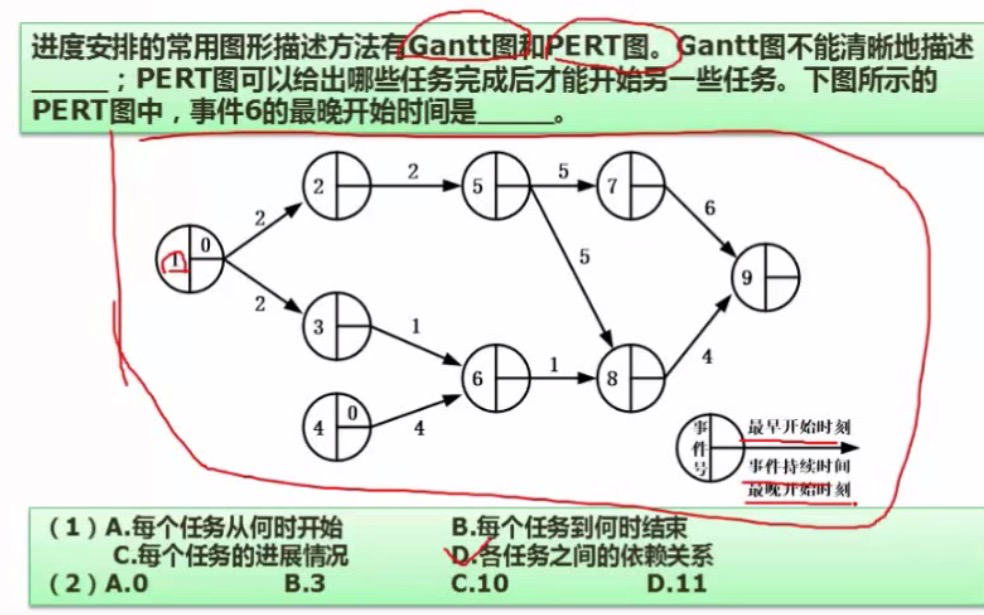
选择D,C。这道题目挺好的,要记住。
面向对象

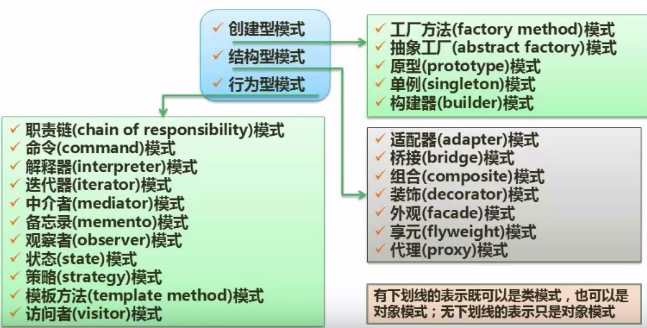
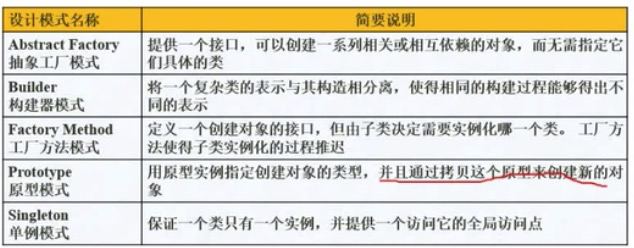
设计模式



数据流图
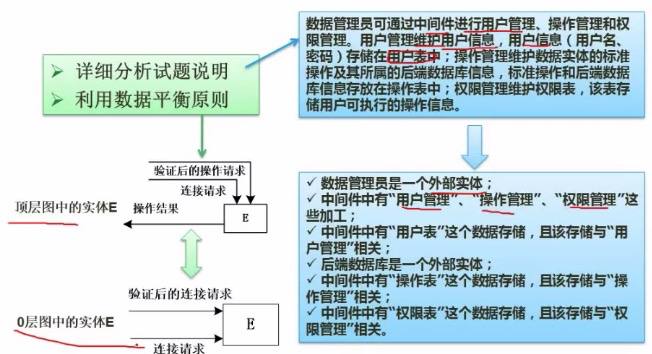
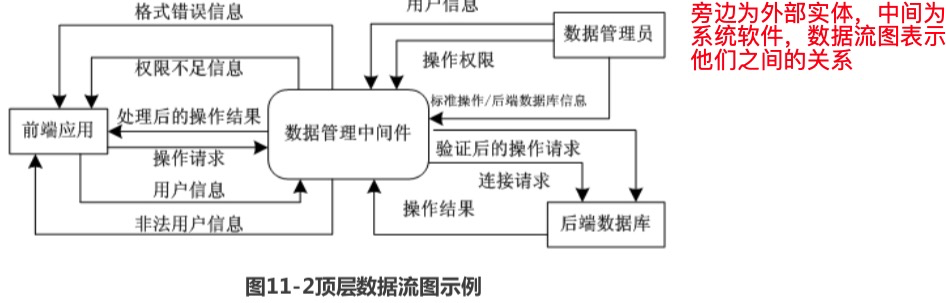
顶层数据流图
顶层数据流图是把软件看成一个大的加工,确定与外部实体之间的输入与输出数据流,这种图能很好的体现出系统与外部实体之间的交互关系。
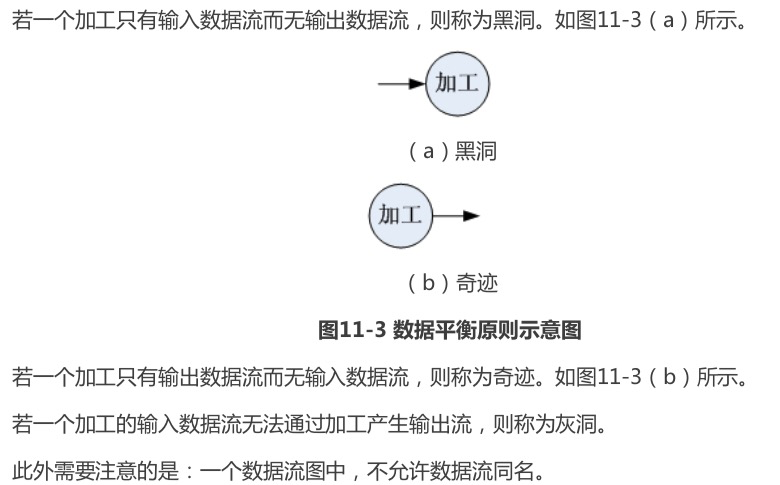
数据平衡原则:
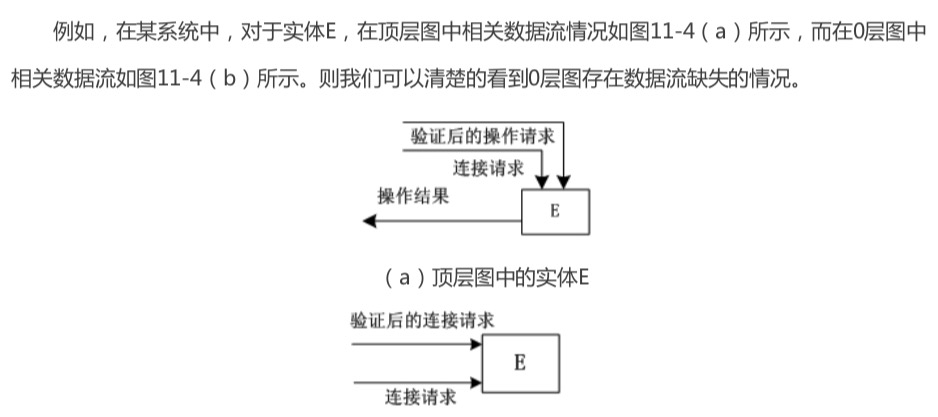
分层数据流图的数据平衡原则
上层图不需要描述下层图中所描述的详细信息,而下层图的输入与输出应与上层图保持一致,也就是父图和子图之间的数据流必须保持一致。
每张数据流图的数据平衡原则
加工的输入数据流和输出数据流要平衡,即保证加工的输出数据流都有其对应的输入数据流与 输出数据流。以下属于打破了数据平衡原则,会产生错误的情况
软件开发模型
1.瀑布模型。小型,需求明确,二次开发
优点:容易理解,管理成本低,以文档作为驱动,强迫开发人员采用规范的方法,严格规定了各阶段必须提交的文档;要求每一阶段结束后,都要进行严格的评审。与它最相适应的开发方法是结构化方法。缺点:不适应软件开发工作中用户需求的改动,对风险的控制能力较弱。
V模型。该模型强调开发过程中测试贯穿始终。V模型在瀑布模型的基础上,强调测试过程与开发过程的对应性和并行性,同样要求需求明确,而且很少有需求变更的情况发生。
2.增量模型。迭代,强调每一个增量都要发布一个可操作的产品。
3.演化模型包括:原型模型,螺旋模型
a.原型模型。迭代,需求不明确,目的是快速,低成本。
原型模型通过向用户提供原型获取用户的反馈,使开发出的软件能够真正反映用户的需求。同时,原型模型采用逐步求精的方法完善原型,使得原型能够“快速”开发,避免了像瀑布模型一样在冗长的开发过程中难以对用户的反馈作出快速的响应。相对瀑布模型而言,原型模型更符合人们开发软件的习惯,是目前较流行的一种实用软件生存期模型。原型模型适应于软件开发过程中用户需求还会变更的场合。原型模型又细分为探索型原型、实验型原型和演化型模型三种。
b.螺旋模型。综合了瀑布模型和原型模型中的演化模型的优点,还增加了风险分析,特别适用于庞大而复杂的、高风险的管理信息系统的开发。
4.喷泉模型。一种以用户需求为动力,以对象为驱动的模型,主要用于描述面向对象的软件开发过程。该模型的各个阶段没有明显的界限,开发人员可以同步进行开发。其优点是可以提高软件项目开发效率,节省开发时间,适应于面向对象的软件开发过程。
填空题:
(1)快速原型模型的关键在于快速地建造出软件模型。
(2)螺旋模型强调风险分析,特别适合于大型复杂的软件项目开发。
(3)瀑布模型是基于软件生命周期的模型,是传统软件工程的基础模型。
(4)在增量模型中,把软件产品作为一系列的增量构件来设计、实现、集成和测试。
(5)喷泉模型是以对象为驱动的模型,主要用于描述面向对象的软件开发过程。
数据流图可以看下我们之前找的资料
考点:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】