
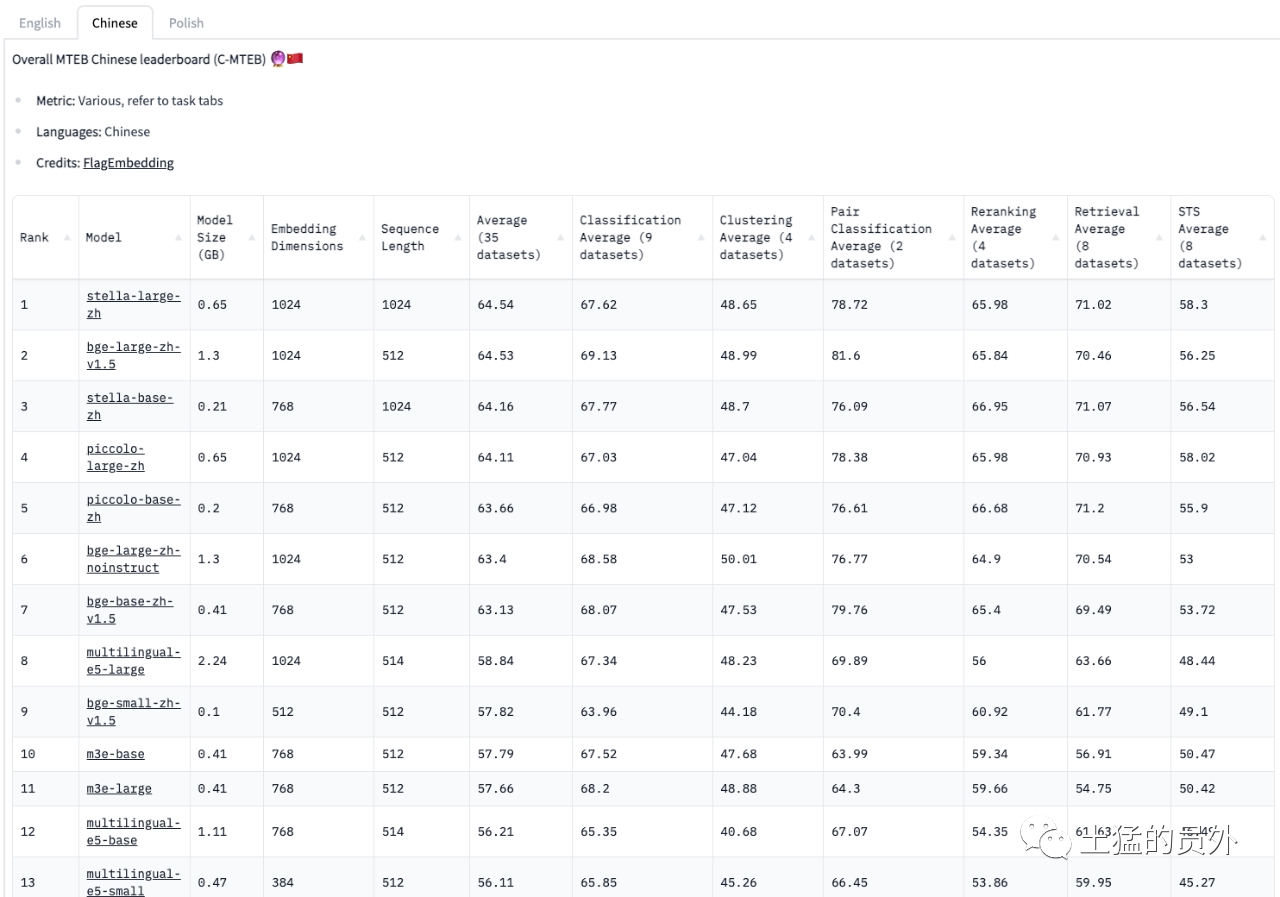
利用 MTEB 基准
要全面评估编码器的功能,最好的参考是大规模文本嵌入基准(MTEB)。这个基准可以让我们根据向量的维度、检索的平均性能和模型的大小来对比不同的编码器。不过,我们也不能完全相信这个基准的结果,因为它并不是万能的,而且模型的训练数据的细节可能没有公开。
MTEB 不仅给我们展示了 OpenAI、Cohere 和 Voyager 等流行嵌入的性能,还告诉我们一些开源模型也有相近的性能水平。但是,我们要注意,这些结果只是一个大概的概览,可能不能准确反映这些嵌入在我们的领域和上下文中的表现。所以,在最终选择之前,我们必须对我们的数据集进行深入的评估,强调定制评估方法的重要性。
huggingface 维护了一套 embedding 评测指标:https://hf-mirror.com/spaces/mteb/leaderboard
text2vec-base-chinese
说明
关联模型
text2vec-large-chinese
text2vec-base-chinese-paraphrase:https://huggingface.co/shibing624/text2vec-base-chinese-paraphrase
下载:https://huggingface.co/shibing624/text2vec-base-chinese
资料
M3E
说明
下载
资料
https://mp.weixin.qq.com/s/3o-Kcox-gVkMyX_bxKE20w M3E:新的中文Embedding模型
M3E(Moka Massive Mixed Embedding):新的中文Embedding模型,使用千万级(2200w+)中文句对数据集进行训练,
支持异质文本,在文本分类和文本检索的任务上效果超过openai-ada-002模型。
BGE-BAAI General Embedding
说明
关联模型
bge-large-zh
下载:https://huggingface.co/BAAI/bge-large-zh
资料


 浙公网安备 33010602011771号
浙公网安备 33010602011771号