所谓自注意力机制就是通过某种运算来直接 计算得到句子 在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐含向量表示。
自注意力机制的缺陷就是:模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置, 因此作者提出了通过多头注意力机制来解决这一问题。
实验证明,多头注意力机制 效果优于 单头注意力,计算框架如下图

V K Q 是固定的单个值,linear 层有3个,Scaled Dot-Product Attention 有3个,即 3个头; 【Scaled Dot-Product Attention 后面会讲】
类似于堆积了 3个 单头注意力;
之后 concat ,或者 sum,最后 linear;
其实多头注意力 就是把 单头注意力 执行了多次,然后把结果进行合并
代码
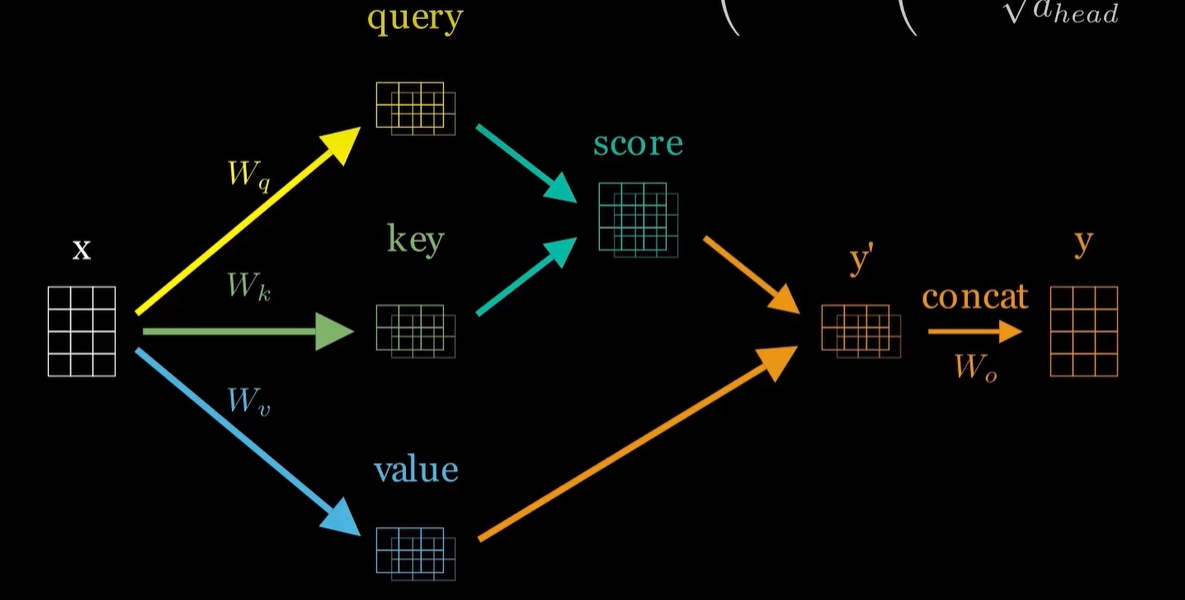
在具体代码中,使用如下流程图,思路更清晰明了



import math import torch import torch.nn as nn class LayerNorm(nn.Module): def __init__(self, hidden_size, eps=1e-12): """Construct a layernorm module in the TF style (epsilon inside the square root). """ super(LayerNorm, self).__init__() self.weight = nn.Parameter(torch.ones(hidden_size)) self.bias = nn.Parameter(torch.zeros(hidden_size)) self.variance_epsilon = eps def forward(self, x): u = x.mean(-1, keepdim=True) s = (x - u).pow(2).mean(-1, keepdim=True) x = (x - u) / torch.sqrt(s + self.variance_epsilon) return self.weight * x + self.bias class SelfAttention(nn.Module): def __init__(self, num_attention_heads, input_size, hidden_size, hidden_dropout_prob): super(SelfAttention, self).__init__() if hidden_size % num_attention_heads != 0: raise ValueError( "The hidden size (%d) is not a multiple of the number of attention " "heads (%d)" % (hidden_size, num_attention_heads)) self.num_attention_heads = num_attention_heads self.attention_head_size = int(hidden_size / num_attention_heads) # 每头大小 self.all_head_size = hidden_size self.query = nn.Linear(input_size, self.all_head_size) self.key = nn.Linear(input_size, self.all_head_size) self.value = nn.Linear(input_size, self.all_head_size) self.attn_dropout = nn.Dropout(0.8) # 做完self-attention 做一个前馈全连接 LayerNorm 输出 self.dense = nn.Linear(hidden_size, hidden_size) self.LayerNorm = LayerNorm(hidden_size, eps=1e-12) self.out_dropout = nn.Dropout(hidden_dropout_prob) def transpose_for_scores(self, x): # x 最后一维即 input_size(例如10),把这维转换成 heads_num * head_size(例如 2*5) new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size) x = x.view(*new_x_shape) # [b h w] --> [b h heads headsize] return x.permute(0, 2, 1, 3) # [b heads h headsize] heads 类似通道数 def forward(self, input_tensor): mixed_query_layer = self.query(input_tensor) # [b h hiddensize] mixed_key_layer = self.key(input_tensor) mixed_value_layer = self.value(input_tensor) query_layer = self.transpose_for_scores(mixed_query_layer) # [b heads h headsize] key_layer = self.transpose_for_scores(mixed_key_layer) value_layer = self.transpose_for_scores(mixed_value_layer) # qk = [b heads h headsize] * [b heads headsize h] = [b heads h h] # 消掉了最后一维 attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2)) # score 标准化,只是除了一个定值,不必纠结 attention_scores = attention_scores / math.sqrt(self.attention_head_size) # Apply the attention mask is (precomputed for all layers in BertModel forward() function) # [batch_size heads seq_len seq_len] scores # [batch_size 1 1 seq_len] # attention_scores = attention_scores + attention_mask # Normalize the attention scores to probabilities. attention_probs = nn.Softmax(dim=-1)(attention_scores) # [b heads h h] # This is actually dropping out entire tokens to attend to, which might # seem a bit unusual, but is taken from the original Transformer paper. # Fixme attention_probs = self.attn_dropout(attention_probs) # 对一些激活值dropout # softmax * v = [b head h h] * [b heads h headsize] = [b heads h headsize] context_layer = torch.matmul(attention_probs, value_layer) context_layer = context_layer.permute(0, 2, 1, 3).contiguous() # [b h heads headsize] new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,) context_layer = context_layer.view(*new_context_layer_shape) # [b h inputsize] # 归纳:注意力机制到底干了啥? # 其实他就是把初始的编码转换成新的编码,而且新旧编码长度是相同的,而注意力机制相当于给旧编码进行了加权 ### 下面不属于 注意力机制了 hidden_states = self.dense(context_layer) hidden_states = self.out_dropout(hidden_states) hidden_states = self.LayerNorm(hidden_states + input_tensor) return hidden_states
再来一张图帮助理解

Z0是单个head生成的新编码, 将8个Z横着拼起来,8x3=24,生成(2,24)的矩阵,乘以Wo(24, 4),得到 新编码Z(2, 4)
小结
1.注意力机制的 输入和输出 shape 是原则上是相同的,这样方便理解和计算,【即使不同,乘个矩阵就相同了】
2.把单头分解成多头,相当于一个大领导负责一个大项目,分解成多个小组长分别负责一个子项目,之后再做项目合并

优势:
多头注意力融合了来自于相同的注意力池化产生的不同知识,这些知识的不同 来源于相同的查询、键和值的 不同的子空间表示;
可并行处理;
参考资料:
https://zhuanlan.zhihu.com/p/484524337 (多头)自注意力机制
https://zhuanlan.zhihu.com/p/365386753 Multi-headed Self-attention(多头自注意力)机制介绍
https://blog.csdn.net/beilizhang/article/details/115282604 代码
https://zhuanlan.zhihu.com/p/486137878 基于pytorch实现(多头)自注意力代码
https://blog.csdn.net/HappyCtest/article/details/109847449 Pytorch 自带 多头注意力


 浙公网安备 33010602011771号
浙公网安备 33010602011771号