深度学习模型 网络结构复杂,训练慢,落地难,严重影响了工业化应用,故需要进行模型加速;
本文从 计算优化、系统优化 等层面入手,为大家带来业界在 模型加速 技术上的研究和最新进展。
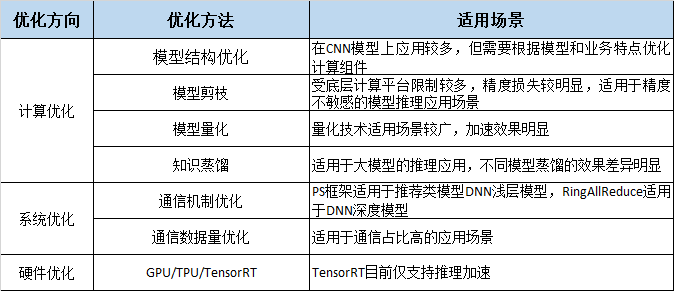
计算优化 就是 减少计算量,是比较常见的加速方法,下面具体介绍。
模型结构优化
深度学习模型深度和宽度越来越大,为了匹配 数据资源、计算资源、任务目标 等,需要进行结构设计;
目前主要是 依靠经验 设计一些 具有 类似功效的 轻型组件 来代替 原模型中的 重型组件,这一点在 CNN 领域尤为突出,CNN 本身就是对 FC 的结构优化,其他优化方式如下
|
模型 |
优化结构 | 优化方式 |
| NIN | MLP-conv模块 | 通过 1x1 卷积核 及 Avg_pooling 代替 fully connected layers 减小参数 |
| VGG | 3x3 卷积核 | 采用连续的 3x3 卷积核 代替 Alexnet 中的大卷积核 |
| GoogleNet | Inception 模块 | 使用多个不同尺寸的卷积核,以一种结构化的方式提取不同尺寸的信息 |
| SqueezeNet | Fire模块 | Squeeze层用 1x1 卷积核实现数据压缩,Expand层用 1x1 和 3x3 卷积核进行特征提取 |
| MobileNets | Depth-wise conv 模块 | 使用 Depth-wise separable convolution 的卷积方式替代传统卷积 |
| ShuffleNets | Group-conv模块、Channel-shuffle模块 | 用 Channel-shuffle 模块优化 组间信息交换 |
具体采用什么方式进行优化,需要根据具体的模型和业务,大多时候需要依赖 人工经验,不断尝试,费时费力,
为了更好更快的 设计和优化网络,神经网络结构搜索 NAS 技术 应运而生,有兴趣的可以了解下。
模型剪枝
在 决策树模型 中 也有剪枝的概念,其实 核心思想 都差不多;
深度学习模型剪枝 分为 结构化剪枝和非结构化剪枝;
结构化剪枝:对参数矩阵进行有规律的裁剪,如 成行 或 成列 裁剪,裁剪后的矩阵仍然是个规则的矩阵,结构化裁剪主流的方法有Channel-level、Vector-level、Group-level、Filter-level级别的裁剪。
非结构化裁剪:将原本稠密的参数矩阵裁剪为稀疏的参数矩阵,一般矩阵的形状不发生变化,只是矩阵内的值变得稀疏,类似于 正则化;因为目前大部分计算平台不支持稀疏矩阵的计算,只有结构化剪枝才能真正减少计算量。
剪枝的难点在于 剪哪里,剪多少,目前主流做法是训练一个大模型,根据参数 权重的大小 进行剪枝,去除不重要的参数,最后对裁剪后的模型 finetune 一下即可,但这种方法收敛较慢,模型也不一定是最优模型;
为了解决这个问题,同时避免每次剪枝后重新训练模型带来的大量计算开销,
Metapruning方法设计了一个权重学习模型来学习不同网络结构对应的权重矩阵,用于评估模型搜索过程中产生的模型的好坏,从而解决了模型评估过程中模型参数训练的问题。
Metapruning算法最大的创新点在于告诉我们模型参数可以直接“生成”,而不需要训练。不过比较遗憾的时,“生成”的模型参数不能直接应用于模型推理,仅供对比评估。
根据经验,非结构化剪枝 对 模型精度 损失较小,但由于 计算平台的限制,加速效果一般;
结构化剪枝 模型加速效果明显,但是 精度算法较大;
模型剪枝形象解释如下图

模型量化
模型量化 是 通过 减少每个参数的 比特数 来降低 参数内存 和 计算量,实现模型加速;
模型量化分为 线性 和 非线性 量化,线性量化如 1/2bit,非线性量化如:
半精度浮点 FP16 和 混合精度 是 常用方法,但需要底层计算平台的支持;
INT8 量化也可以,定点运算 比 浮点运算更快,但 会较大 损失 模型精度;
下图稍微扩展下底层计算方式
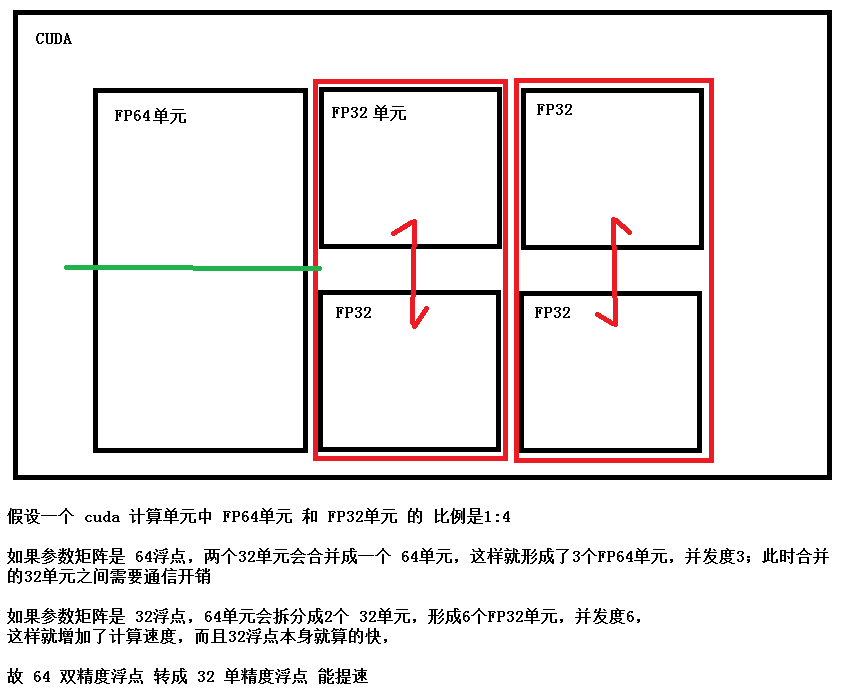
模型量化使用场景较广,加速效果明显,对于 精度敏感 的模型,可通过 精度补偿 操作 来优化 量化模型 的效果。
模型蒸馏
知识蒸馏的思想最早是由Hinton大神在15年提出的一个黑科技,Hinton在一些报告中将该技术称之为Dark Knowledge,技术上一般叫做知识蒸馏(Knowledge Distillation),是模型加速中的一种重要的手段。
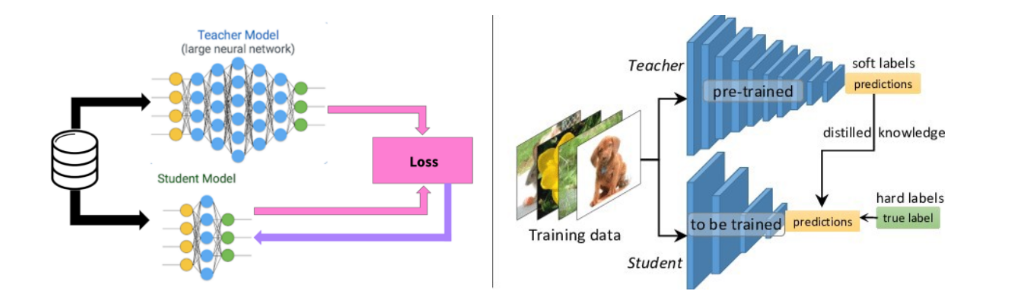
目前大多数 模型蒸馏框架 都 基于 teacher-student 模式,有些方法会 多请几个 teacher,或者 配个 Assistant;
我的理解
一个大模型叫 teacher,一个小模型叫 student,teacher 向 student 传授训练经验,
其实就是 teacher 先趟水,把每个样本的预测一下,判断一下这个样本 像什么(label),好不好学(预测概率),不好学的(概率低),student 就没必要费劲学了,
teacher 给个分(teacher 学到的那个概率),学到那个分就行了,没必须非得学到 100 分(概率1),相当于 减轻了 student 的学习任务(loss);
student 的 label 不是 真实的 label,是 teacher 预测完的 label;
相当于 teacher 已经 划过重点了; 【这个解释绝了】
具体做法
损失函数的构成包含两部分,其一,是真实标签y(hard label)与 student 预测值p之间的损失,其二,是teacher model的输出q(soft label)与 student 预测值p之间的损失。
L = CE(p, y) + αCE(p, q) CE - Cross Entropy
通过这种方式,让小模型的精度趋近于大模型的精度;
下式的qt表示teacher model logit的输出,为了使 P具有传递相似信息的功能,即变成概率,引入softmax函数,并增添了温度T参数。
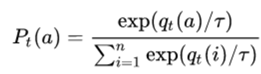
对T的讨论:
- 当T -> inf时, 所有的类别会获得相同的概率,就是一个均匀分布;
- 当T ->0时,则最大值会接近于1,其他值会趋近于0,近似于one hot编码(hard label);
- 当T ->1时,就是softmax公式本身。
小结
模型加速 不仅 加速了训练,更 使得模型在 推理阶段 符合工业需求,可在移动端进行部署。
参考资料:
https://zhuanlan.zhihu.com/p/147204568 深度学习模型,有哪些最新的加速技术? 腾讯技术派
https://www.cnblogs.com/monologuesmw/p/13222983.html 模型加速(一) 概述
https://www.cnblogs.com/monologuesmw/category/1797585.html 随笔分类 - 模型加速 和上面的博客是同一个人的,比较通俗易懂
https://blog.csdn.net/u012108600/article/details/102685883 深度学习模型加速方法
https://zhuanlan.zhihu.com/p/79533156 三张图看懂深度学习模型加速及压缩
https://blog.csdn.net/haima1998/article/details/78250143 Nvidia GPU的浮点计算能力(FP64/FP32/FP16)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号