paper 地址:http://personal.ie.cuhk.edu.hk/~ccloy/files/eccv_2014_deepresolution.pdf
图像超分辨率重建
把一张 低分辨率图像(low resolution) 通过一定的算法 转换成 高分辨率图像(high resolution);
在 深度学习 之前,有很多 传统方法 可以解决该问题,如 插值,但是效果一般;
SRCNN 是第一个 把 深度卷机网络 用于该任务的 深度学习模型,故被称为 图像超分辨率重建的 鼻祖;
可喜的的是 作者 有我们的国人 何凯明大神;
SRCNN 网络结构
作者认为,既然能够通过一定的算法提高图像分辨率,那么 低分辨 与高分辨 之间 一定有 “共通的特性”;
就是这么简单的假设,作者设计了 SRCNN;这里我想说的是,模型到底是什么不重要,重要的是 作者为什么 能设计这样的模型;
该模型的网络结构非常简单,只有 3 层卷积,如下图
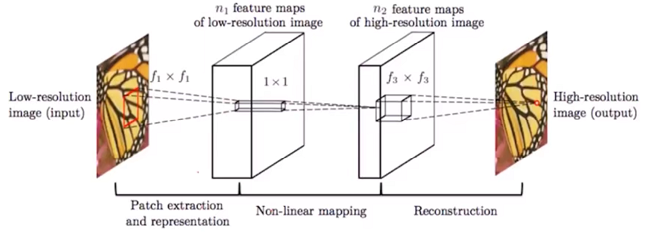
第一层:对 低分辨率图像进行 特征提取,原文 9 x 9 x 64卷积核
第二层:对特征进行非线性映射,原文 1 x 1 x 32卷积核
第三层:对 映射后的特征进行重建,生成高分辨率图像,原文 5 x 5 x 1卷积核
// 生成 单通道图像,故c=1,与 输入保持一致
训练与测试
训练过程:在 高分辨率图像 上随机截取 patch,先进行降采样(目的是降低分辨率),再进行升采样(模型需要,输入尺寸固定),以此作为模型输入,label 是 截取的 patch,loss 为 逐像素 mes;
测试过程:先通过 插值等方式 降低分辨率,然后喂给模型
超分辨率的 质量评价
1. PSNR 峰值 信噪比
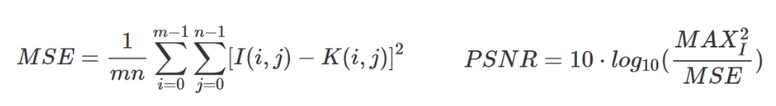
本质还是 逐像素差,差值越小,PSNR越大,质量越高
2. SSIM
3. MOS(意见平均分)主管
4. 感知损失
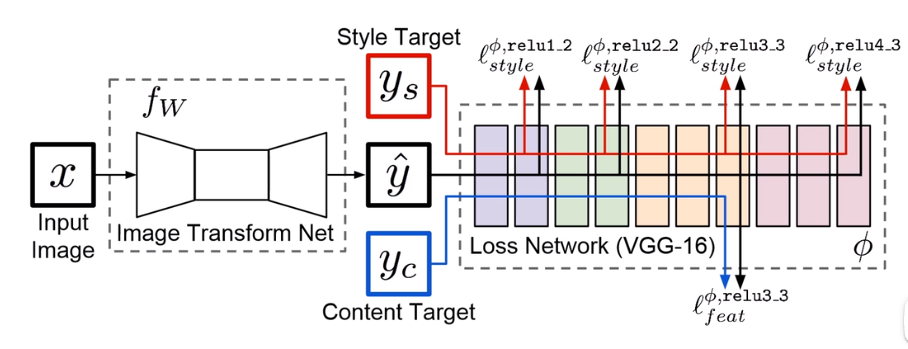
要看懂这张图,先学习 图像风格迁移,本文默认你已学过;
此处无需 风格损失,即无需 上面红色那一路;只用到了 内容损失;
这里 input x 也不需要,y’ 是重建后的 图像,yc 是 原高清图像,经过 后面的 cnn网络 提取特征,计算 特征之间的 mes,大致 如此,细节可自由发挥
总结
既然是 鼻祖,肯定不完美,有很多改进版,以后再说
参考资料:
https://zhuanlan.zhihu.com/p/49846783
https://zhuanlan.zhihu.com/p/27160373
https://www.bilibili.com/video/BV1pE411H7vd?spm_id_from=333.337.search-card.all.click&vd_source=f0fc90583fffcc40abb645ed9d20da32


 浙公网安备 33010602011771号
浙公网安备 33010602011771号