
mtcnn 的 ohem 思想很简单,就是把每个 batch 样本的 loss 排序,选取前 一定比例 的 loss 作为 该 batch 的 loss;
我们可以这么理解,只选大 loss,小 loss 被弃用,相当于 小 loss 为 0,0 进行反向传播时自然不用再算了;
本文重点在解读 ohem 代码

def cls_ohem(cls_prob, label): num_keep_radio = 0.7 # cls_prob shape is [384, 2] # label shape is [384], valus are one of [1 0 -1 -2] ### mtcnn 中分类问题只用 pos 和 neg 样本,part 和 landmark 样本不参与计算; ### 而 送入网络时样本并没有区分开,每个样本输出都有 cls_prob; ### ohem 要做的是把 pos 和 neg 对应的样本的 cls_prob 找出来,其他的不需要; ones = tf.ones_like(label) zeros = tf.zeros_like(label) sample_num = cls_prob.get_shape()[0] cls_prob_size = tf.size(cls_prob) cls_prob_reshape = tf.reshape(cls_prob, [cls_prob_size, -1]) ### 相当于竖着展开了 ### 展开以后,0 2 4 6... 位置上的是 非人脸的 prob,1 3 5 7... 位置上的是 人脸的 prob ### 把人脸和非人脸的 prob 取出来 raw = tf.range(sample_num) * 2 # 0 2 4 6... 这些位置上是非人脸的 prob,加上 1 个位置就是人脸的 prob # 把 label 中人脸的 label 变成 1, 其他变成 0 label_filter_one = tf.where(tf.less(label, 0), zeros, label) cls_prob_pos_index = label_filter_one + raw cls_prob_face_noface = tf.squeeze(tf.gather(cls_prob_reshape, cls_prob_pos_index), axis=1) ### shape [384] loss = -tf.log(cls_prob_face_noface + 1e-10) ### 加上 1e-10 是为了防止 cls_prob_neg_pos 很小,log 后为 无穷 ### 把 pos 和 neg 的 prob 取出来 # 把 pos 和 neg 的label 变成 1, 其他变成 0,然后点乘 label_filter_two = tf.where(tf.less(label, 0), zeros, ones) label_filter_two = tf.cast(label_filter_two, tf.float32) loss = loss * label_filter_two ### pos and neg sample number pos_neg_count = tf.reduce_sum(label_filter_two) pos_neg_hard = tf.to_int32(pos_neg_count * num_keep_radio) loss, _ = tf.nn.top_k(loss, k=pos_neg_hard) with tf.Session() as sess: # print(sess.run(cls_prob_pos_index)) # print(sess.run(label_filter_two)) # print(sess.run(loss)) print(111, sess.run(cls_prob_face_noface)) print(222, sess.run(label_filter_two)) return tf.reduce_mean(loss) cls_prob = tf.random_uniform([10, 2],0, 1, seed = 100) # label = np.array([1,0,0,0,0,0,0,0,0,0]) label = np.array([1,0,0,0,-1,0,-2,0,0,0]) # Loss:1.4161593 print(label.shape) loss = cls_ohem(cls_prob, label) with tf.Session() as sess: print(sess.run(loss))
注意,不要在 取 log 之前进行浮点数之间的乘法,对精度影响很大, 【为此我折腾了一上午】
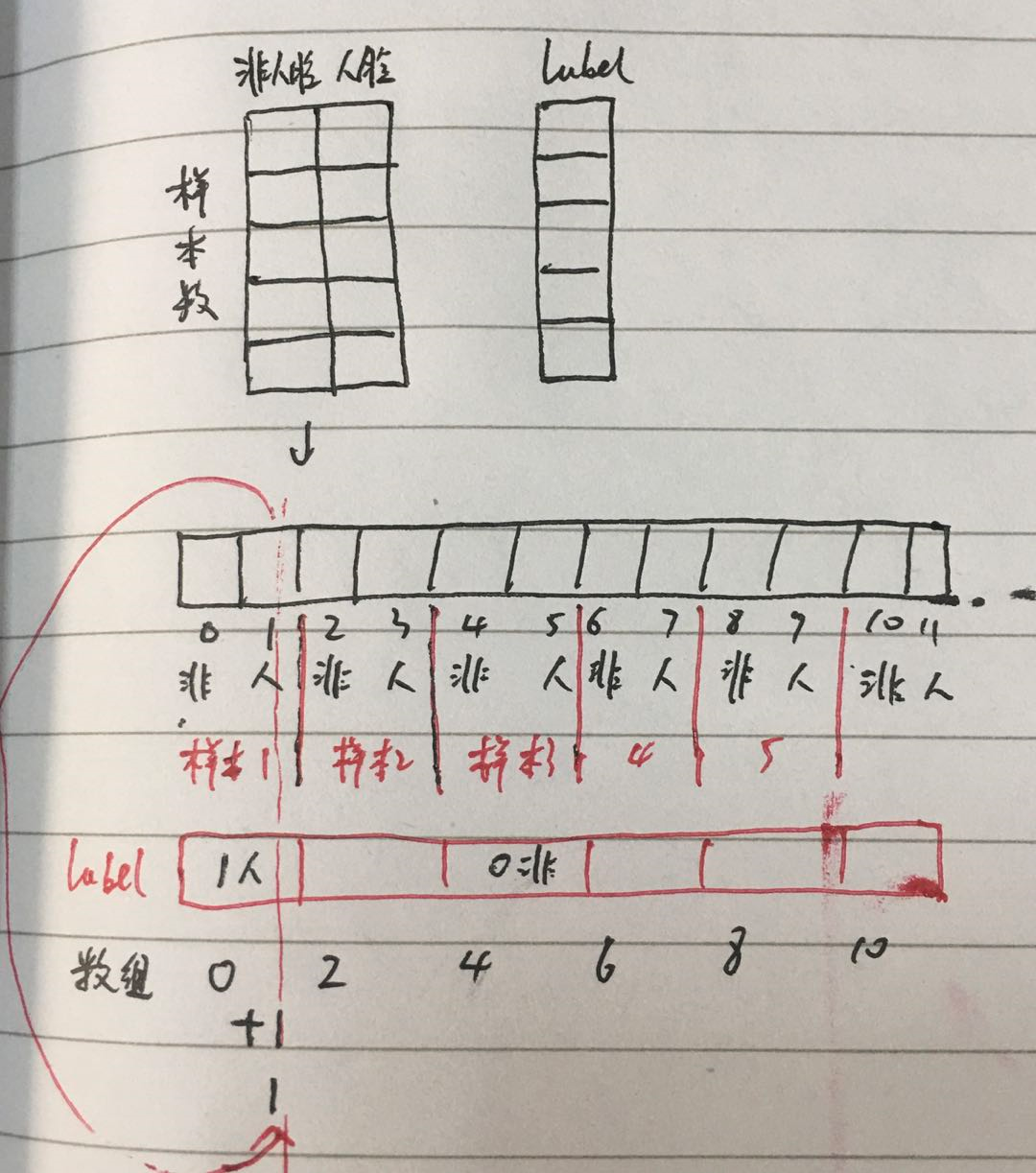
其中最难理解的就是下面几句
### 把人脸和非人脸的 prob 取出来 raw = tf.range(sample_num) * 2 # 0 2 4 6... 这些位置上是非人脸的 prob,加上 1 个位置就是人脸的 prob # 把 label 中人脸的 label 变成 1, 其他变成 0 label_filter_one = tf.where(tf.less(label, 0), zeros, label) cls_prob_pos_index = label_filter_one + raw cls_prob_face_noface = tf.squeeze(tf.gather(cls_prob_reshape, cls_prob_pos_index), axis=1) ### shape [384]
图解如下
参考资料:
https://blog.csdn.net/zhouzongzong/article/details/94716746



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2019-03-14 卷积神经网络 CNN - Dropout
2019-03-14 rnn-手写数字识别-网络结构-shape
2019-03-14 tensorflow-LSTM-网络输出与多隐层节点