MTCNN,multi task convolutional neural network,多任务卷积神经网络;
它同时实现了人脸检测和关键点识别,关键点识别也叫人脸对齐;
检测和对齐是很多其他人脸应用的基础,如人脸识别,表情识别;
网络特点:
1. 级联网络
2. 在线困难样本选择 online hard sample dining
3. 速度非常快,可做实时检测
MTCNN 主体架构为 3 个逐级递进的级联网络,分别称为 P-Net、R-Net、O-Net,P-Net 快速生成粗略候选框,R-Net 进行过滤得到高精度候选框,O-Net 生成边界框和关键点坐标;
如图
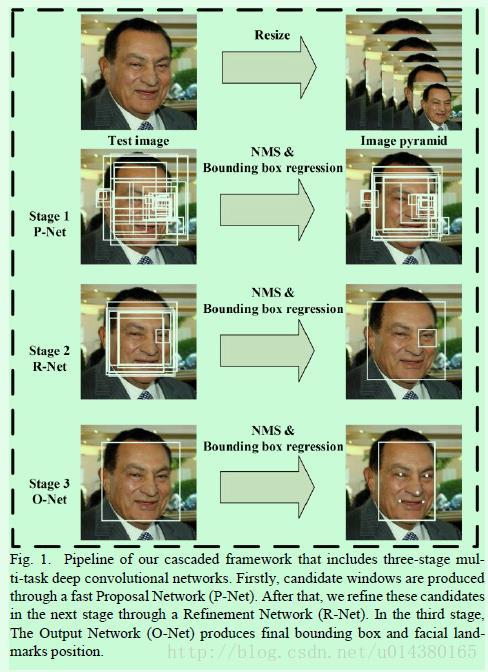
注意上图是 测试过程,训练过程略有不同
网络解析
MTCNN 网络的形象理解:
三个级联网络,我们可以理解为面试过程,
HR 面试为 P-Net,HR 面试不能太严格,因为这样会漏掉很多合适的人选,故 P-Net 是一个简单的网络;
HR 面试完毕后,把通过的简历传给 技术,技术面试为 R-Net,技术面基本就能确定人选是否被录用,只是薪资可能无法确定,故 R-Net 基本就确定了是否为人脸,只是关键点没有指定;
技术面试完毕后,把通过的简历传给 boss,boss 面为终面,输出是否录用及薪资;
图像金字塔
将样本进行等比例的多次缩放,目的是为了检测不同大小的人脸;
缩放比例一般为 0.7-0.8 之间,如果缩放比例太大,会导致小人脸检测不到,如果太小,图片过大,效率降低;
最小的图片要大于 12x12,因为 P-Net 的输入为 12;
P-Net
全称 Proposal Netwrok,通过一个简单的网络快速得到粗略的建议框;
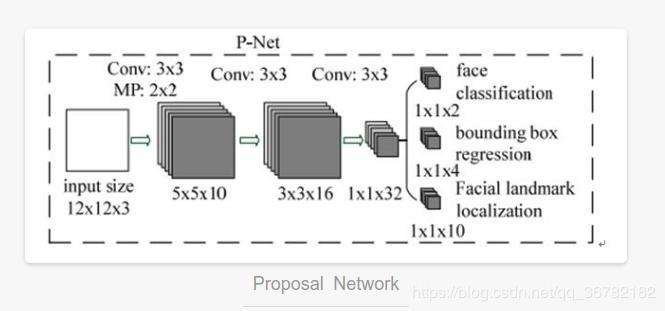
它是一个全卷积网络,输出分为 3 部分:是否为人脸(2)、建议框的 左上右下坐标(4)、人脸关键点(5个点*(x,y)=10);
上图最后的输出为 方框,因为他是卷积,而 R-Net、O-Net 的输出为长条,因为他是全连接;
训练阶段:虽然是全卷积网络,但是输入仍需 resize 到 12x12;
测试阶段:无需 resize 到 12x12,而是把图像金字塔输入网络;
R-Net
全称 Refine Network,主要作用是去除大量非人脸建议框

它的输入是 P-Net 的输出;
网络最后加上了一个全连接层;
O-Net
全称 Output Network,这一步对 建议框进行最终修正,并且对关键点进行回归;
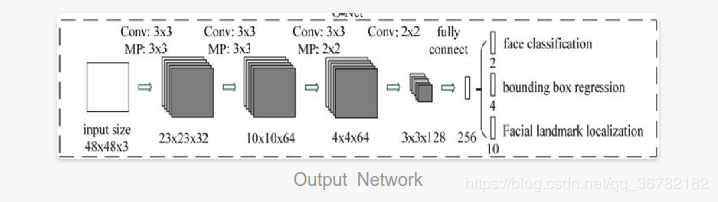
它的输入是 R-Net 的输出;
网络多了一个卷积层和全连接层;
损失函数
人脸类别为 交叉熵

边框和 关键点都是 均方差

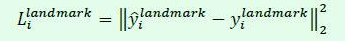
由于在训练时不是每一步都计算所有损失,因此用下式统一了模型的损失函数

N 表示样本数;
α 表示任务权重,在整个模型中,我们始终最关注是不是人脸,故它的权重最大,一直为 1,边框回归是在识别为人脸的建议框上做的,故权重小于人脸,一直为 0.5,在 P-Net 和 R-Net 中,关键点的回归几乎不需要,权重很小,在 O-Net 中,人脸和边框都差不多了,好好把关键点识别一下,权重变大;
β 取值 0,1,如果输入为非人脸,只计算 人脸部分的损失,边框和关键点不计算;
模型训练
MTCNN 的训练还是比较麻烦的,需要串行地训练 三个网络 【据说可以并行,没试过,只是每个网络的训练数据不同】
首先明确以下几点:
作者采用的数据集为 wider face 边框 和 Celeba 关键点
训练三个网络都需要四种数据
- positive:正样本,与 ground truth IOU > 0.65 的 bbox;
- negative:负样本,与 ground truth IOU < 0.3 的 bbox;
- part:部分脸, 0.4 < 与 ground truth IOU < 0.65 的 bbox;
- landmark:关键点;
三种 任务 所需数据不同
- 分类任务:只需要 positive 和 negative;
- 回归任务:只需要 positive 和 part;
- 对齐任务:只需要 landmark;
P-Net 训练
第一步,生成数据集
随机裁剪 不同 size 的正方形 bbox,计算与 GT 的 IOU,获取以下训练集:
- negative1:获取 50 个,真的随机裁剪;
- negative2:获取 5 个,在人脸附近裁剪,保证 偏移量 < 裁剪框 size,这样 bbox 与 人脸 的 IOU 是大于 0 的;
- positive and part:共约 20 个,在人脸附近裁剪;
- landmark:每个人脸区域附近生成10个框框,根据iou,保存有效的框框,随机进行翻转flip,或者旋转rotate,旋转 + 翻转,中的1步或几步进行数据增强;
把这些 裁剪 的图片缩放成 12x12 大小;
第二步,生成 label
positive 的 label 有两部分,是否为人脸,bbox 的坐标;
// 如果是人脸,label 为 1;
part 的 label 也是两部分,是否为人脸,bbox 的坐标;
// 如果是人脸,label 为 -1,;
negative 的 label 只有一部分,是否为人脸;
landmark 的坐标也是两部分,是否为人脸,关键点坐标;
// 如果是人脸,label 为 -2;

label 中所有 坐标都是 偏移量 offset
为什么要用 offset?
首先 offset 是个很小的值,方便我们做回归,容易学习,其次 offset 是个相对位置,bbox 左上角 相对于 ground truth 左上角的偏移量,根据偏移量我们很容易获取它在原图的位置;
如何计算 offset?
positive 和 part 的 offset 计算方式如下,
假设真实 label 的坐标为 [x1,y1,x2,y2],裁剪框的坐标为 [xa,ya,xb,yb],那么裁剪框的 size = xb-xa = yb-ya,那么 offset 为
offset_xa = (x1-xa) / size
offset_ya = (y1-ya) / size
offset_xb = (x2-xb) / size
offset_yb = (y2-yb) / size
为什么是 x1-xa,而不是 xa-x1?为什么是 bbox 的 size,不是 gt 的 size?
首先 offset 是我们的 label,那么网络的输出就是我们预测的 offset,我们需要拿预测的 offset 计算出它在原图的坐标,offset 需要乘以一个 size,然后 加上 一个 x ;
而 size 我们只有 预测出来的 bbox 的 size 啊,真实的 size 根本没有啊,特别是 test 阶段,所以 size 是 bbox 的 size;
然后 加上 一个 x 得到 另一个 x,需要得到的是 gt 的 x,所以加上的只能是 bbox 的 x 了;
offset 图解

landmark 的 offset 计算同理与 bbox;
第三步,输入样本,计算 loss
注意,每种 loss 需要不同的数据集,我们可以选择 分别输入 各种数据集,
如 先 输入 positive 和 negative 用作 分类任务,此时 回归 loss 都是 0 就行了,然后 再 输入 bbox 样本,此时 分类 loss 都是 0 就行了;
但这种做法感觉怪怪的;
更好的做法是,把所有样本 打乱,随机输入各种样本,然后根据 label [0 1 -1 -2] 来判断是哪种样本,从而计算对应的 loss 即可;
在计算 loss 时,作者提出了一种 在线困难样本选择的 方法,其实很简单,就是把 所有 loss 排序,取前面一部分大的 loss,后面小的 直接舍弃,具体参考我的博客 ohem
第四步,NMS,这一步可有可无,有的话可大大减少计算量
R-Net 训练
与 P-Net 的随机裁剪不同,R-Net 是把 P-Net 输出的 bbox 在原图上进行裁剪,从而根据与 ground truth 的 IOU 得到 各种样本;
其他与 P-Net 相同;
O-Net 训练
把 R-Net 的输出作为 裁剪框,其他与 P-Net 相同;
模型应用
MTCNN 不仅可以做人脸检测,也可以做其他检测,如交通流检测,人流检测;
它与 Yolo 的区别在于,Yolo 是多目标检测,MTCNN 是多个单目标检测,MTCNN 在单目标检测领域要优于 Yolo;
=================== 2025.12.20补充 图像金字塔
一、训练阶段
1. 通常情况:固定尺寸输入
大多数现代深度学习模型在训练时确实使用固定尺寸的输入,原因包括:
-
批次处理效率:GPU需要统一尺寸的数据进行并行计算
-
内存管理:固定尺寸便于内存分配和优化
-
简化实现:避免动态图结构带来的复杂性
2. 图像金字塔在训练时的应用
当使用图像金字塔策略时,训练阶段可能有几种方式:
a) 单尺度训练 + 多尺度推理
-
训练:单一固定尺寸
-
推理:多个不同尺度的金字塔层级
b) 多尺度训练
-
对每个训练样本,随机选择金字塔的一个尺度
-
但仍然在每个批次内保持统一的尺寸
-
通过数据增强实现尺度变化
二、推理阶段
1. 无需严格固定尺寸
在推理时,模型通常可以接受任意尺寸的输入,因为:
-
全卷积网络(FCN)特性:现代CNN大多使用全卷积结构,没有全连接层的尺寸限制
-
动态计算:推理时不需要批次对齐,可以逐张处理
三、技术细节说明
1. 全连接层的处理
如果模型包含全连接层:
-
训练:需要固定输入尺寸
-
推理:可以通过以下方式处理可变尺寸:
-
全局平均池化 + 全连接
-
空间金字塔池化(SPP)
-
自适应池化层
-
2. 实际应用案例
a) YOLOv3/v4/v5
-
训练:多尺度训练(如640×640随机缩放)
-
推理:支持任意尺寸,但推荐使用训练时的尺寸
b) Faster R-CNN with FPN
-
特征金字塔网络本身就是一种高效的多尺度处理方法
-
可以在推理时处理不同尺寸的输入
四、最佳实践建议
-
训练策略
# 多尺度训练示例 scales = [320, 416, 512, 608, 704] # 随机选择 input_size = random.choice(scales) -
推理优化
-
虽然支持任意尺寸,但使用训练时的常见尺寸通常效果最好
-
考虑硬件对齐(如32的倍数)以提高推理速度
-
-
部署考虑
-
TensorRT、ONNX Runtime等推理引擎可能对输入尺寸有特定要求
-
某些部署环境可能要求固定尺寸以获得最优性能
-
总结
-
训练阶段:通常固定尺寸(为了批次训练),但可以通过数据增强模拟多尺度
-
推理阶段:可以处理可变尺寸,图像金字塔正是在这个阶段发挥优势
-
关键原因:现代CNN的全卷积设计使其具备尺寸不变性
参考资料:
https://blog.csdn.net/qq_36782182/article/details/83624357 MTCNN工作原理
https://blog.csdn.net/u014380165/article/details/78906898 MTCNN算法及代码笔记
https://blog.csdn.net/weixin_44791964/article/details/103530206
https://zhuanlan.zhihu.com/p/58825924 知乎总是最详细
https://zhuanlan.zhihu.com/p/64989774
https://blog.csdn.net/sinat_28731575/article/details/80330631
https://www.cnblogs.com/helloworld0604/p/9808795.html 训练
https://zhuanlan.zhihu.com/p/72308496 训练讲得很清楚的教程
https://www.zhihu.com/collection/231012127


 浙公网安备 33010602011771号
浙公网安备 33010602011771号