手写数字识别经典案例,目标是:
1. 掌握tf编写RNN的方法
2. 剖析RNN网络结构
tensorflow编程
#coding:utf-8 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data ### 注意 # init_state = tf.zeros(shape=[batch_size,rnn_cell.state_size]) # init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32) mnist=input_data.read_data_sets("./data",one_hot=True) # 常规参数 train_rate=0.001 train_step=10000 batch_size=1280 display_step=100 # rnn参数 frame_size=28 # 输入特征数 sequence_length=28 # 输入个数, 时序 hidden_num=100 # 隐层神经元个数 n_classes=10 # 定义输入,输出 # 此处输入格式是样本数*特征数,特征是把图片拉成一维的,当然一维还是二维自己定,改成相应的代码就行了 x=tf.placeholder(dtype=tf.float32,shape=[None,sequence_length*frame_size],name="inputx") y=tf.placeholder(dtype=tf.float32,shape=[None,n_classes],name="expected_y") # 定义权值 # 注意权值设定只设定v, u和w无需设定 weights=tf.Variable(tf.truncated_normal(shape=[hidden_num,n_classes])) # 全连接层权重 bias=tf.Variable(tf.zeros(shape=[n_classes])) def RNN(x,weights,bias): x=tf.reshape(x,shape=[-1,sequence_length,frame_size]) # 3维 rnn_cell=tf.nn.rnn_cell.BasicRNNCell(hidden_num) ### 注意 # init_state=tf.zeros(shape=[batch_size,rnn_cell.state_size]) # rnn_cell.state_size 100 init_state=rnn_cell.zero_state(batch_size, dtype=tf.float32) output,states=tf.nn.dynamic_rnn(rnn_cell,x,initial_state=init_state,dtype=tf.float32) return tf.nn.softmax(tf.matmul(output[:,-1,:],weights)+bias,1) # y=softmax(vh+c) predy=RNN(x,weights,bias) # 以下所有神经网络大同小异 cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=predy,labels=y)) train=tf.train.AdamOptimizer(train_rate).minimize(cost) correct_pred=tf.equal(tf.argmax(predy,1),tf.argmax(y,1)) accuracy=tf.reduce_mean(tf.to_float(correct_pred)) sess=tf.Session() sess.run(tf.global_variables_initializer()) step=1 testx,testy=mnist.test.next_batch(batch_size) while step<train_step: batch_x,batch_y=mnist.train.next_batch(batch_size) _loss,__=sess.run([cost,train],feed_dict={x:batch_x,y:batch_y}) if step % display_step ==0: print() acc,loss=sess.run([accuracy,cost],feed_dict={x:testx,y:testy}) print(step,acc,loss) step+=1
如果你非常熟悉rnn,代码整体上还是比较好理解的,但是里面涉及许多次的shape设置,比较让人头大,特别是后期写各种rnn时,很容易迷糊,所以每个模型都要理解透彻。
以上代码涉及到shape的变量有
x y w b x变形 init_state
其中比较难理解的是 x x变形 init_state
网络结构
首先回顾一下RNN网络,以便对上个问题进行深入分析。
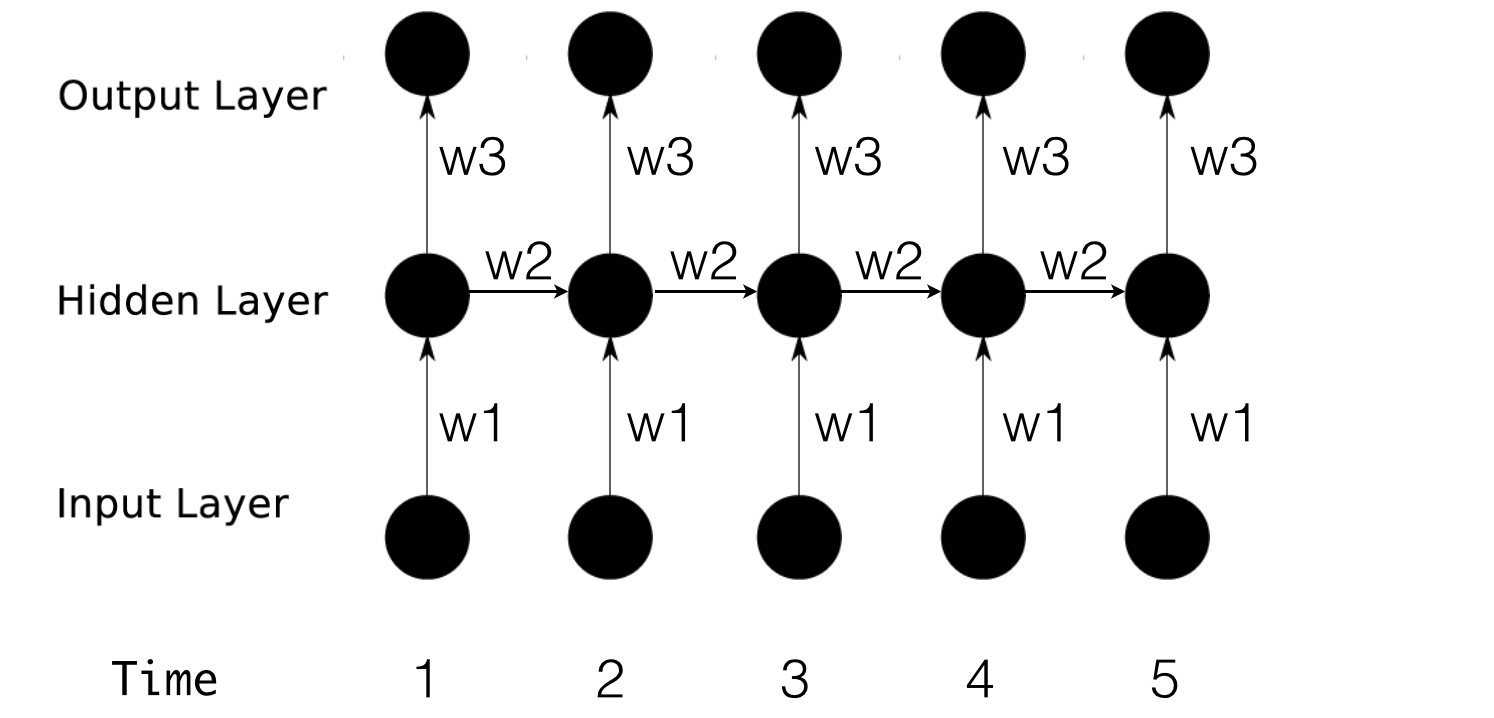
公式简写如下:
h1 = f(x1w1 + h0w2)
o1 = h1w3 输出层就是简单的全连接,这里不做讨论
shape分析
我们把每个时刻的输入看做向量或者矩阵,因为如果只是一个数,没有shape可言,而且也很简单,没有讨论的必要。
首先有如下思考:
1. h是隐层的输出,也就是x传进去得到的输出,因此传一个x就有一个h(但这并不足以说明什么)
其次从公式层面考虑
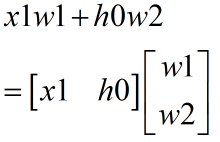
从公式可以看出,x和h的行必须相同,列不必相同
图形表示

这是单节点隐层,那么多节点呢?
首先一个神经元节点对应一组weight,多个神经元就是多组weight
其次从公式层面考虑
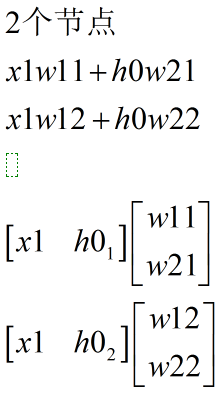
从公式看出,h和x行相同,h列和神经元个数相同。
图形表示
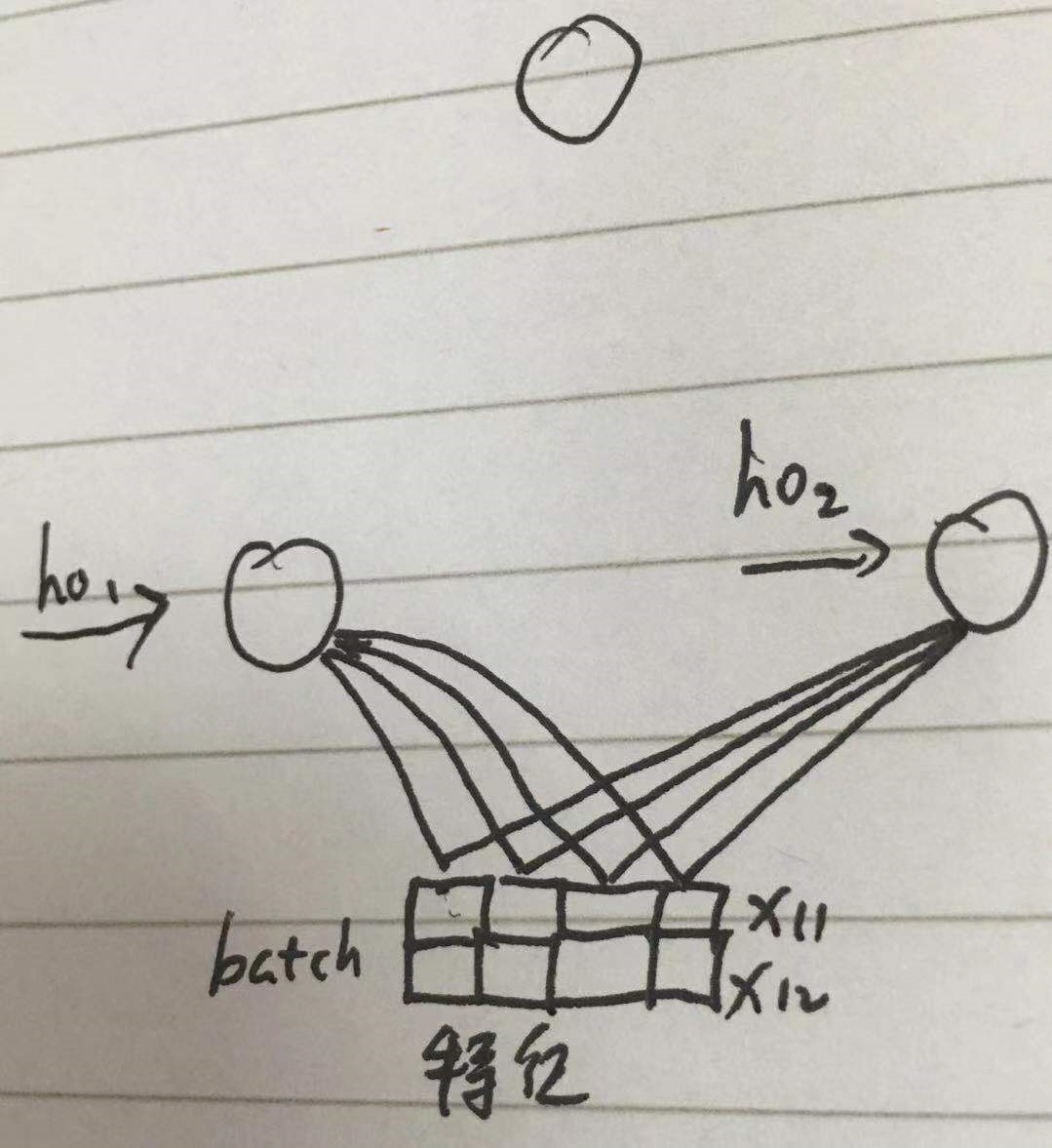
综上所述,h0的shape是行为 x的行,即batch,列为神经元个数
也就是说一个神经元对应一个h0
对应到上述代码
init_state=tf.zeros(shape=[batch_size,rnn_cell.state_size]) # rnn_cell.state_size 100,100为节点数
init_state=rnn_cell.zero_state(batch_size, dtype=tf.float32)
对于输入x的shape,把代码转化成图

根据图来理解:
每次输入n张图片,也就是一次性输入所有时序的x,所有x的shape 为 [None,sequence_length*frame_size]
在rnn模型中因为要与权重相乘,所以需要转化为 [-1,sequence_length,frame_size] [ 样本数,时序数,特征数 ],把特征划分出来,
然后特征乘以权重,然后按时序向上传递,得到输出
结合其他代码分析,对应图片而言,rnn包括LSTM的输入必须是 一次性输入所有时序的x,即 [ 样本数,时序数,特征数 ]
其实这个网络应该是这样
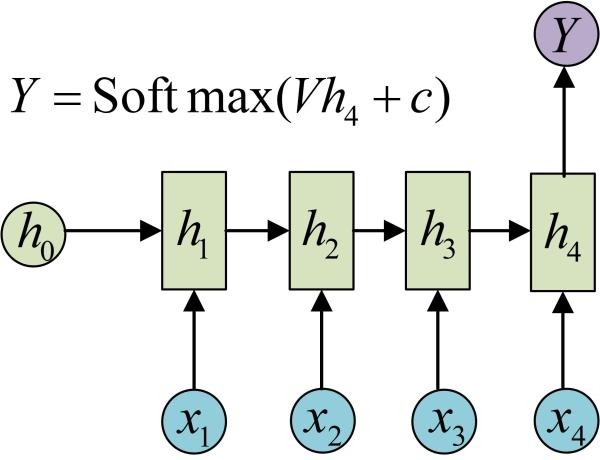
我的理解:像图像这种所有时序的特征结合起来才能确定y的模型用多对一RNN,且每次输入所有时序的特征,而词语预测不然。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号