
LSTM(Long Short-Term Memory)是长短期记忆网络,是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。
LSTM能够很大程度上缓解长期依赖的问题。
LSTM的形象描述
RNN是傻子式的记忆,把所有的事情都记下来,这很容易记忆混乱。
LSTM不同的地方是学会了思考、总结,而且思考方式很符合人类的思维。
首先它会有一定的记忆(初始记忆)和经验。
// 记忆:人在学习时会通过各种渠道获取大量资料,但是有些资料这样说,有些那样说,无法确定真假,只能都记住,这就是记忆
// 经验:通过一些权威的资料获取的知识,或者自己实际验证过的,作为经验
然后它会综合今天发生的事情和之前的经验,来判断之前的记忆是否正确,然后遗忘错误的记忆,记忆被刷新。
此时的记忆还不包含今天的事情。
然后它并行的做了两件事,第一,把今天发生的事情和之前的经验总结一下(当中肯定有确定是错误的的),第二,对今天发生的事情和之前的经验进行评价,之后它把确定错误的删除,不确定正确与否的放入记忆库,和之前的记忆产生新的记忆,记忆又被刷新。
此时的记忆已经包含今天的事情。
然后它又并行的做了两件事,第一,对当前的记忆进行思考总结,第二,综合今天发生的事情和之前的经验,来对当前的记忆进行评价,然后提炼出新的经验,并且保存所有的记忆。
// 经验也是需要被记忆的,也是放在记忆库中
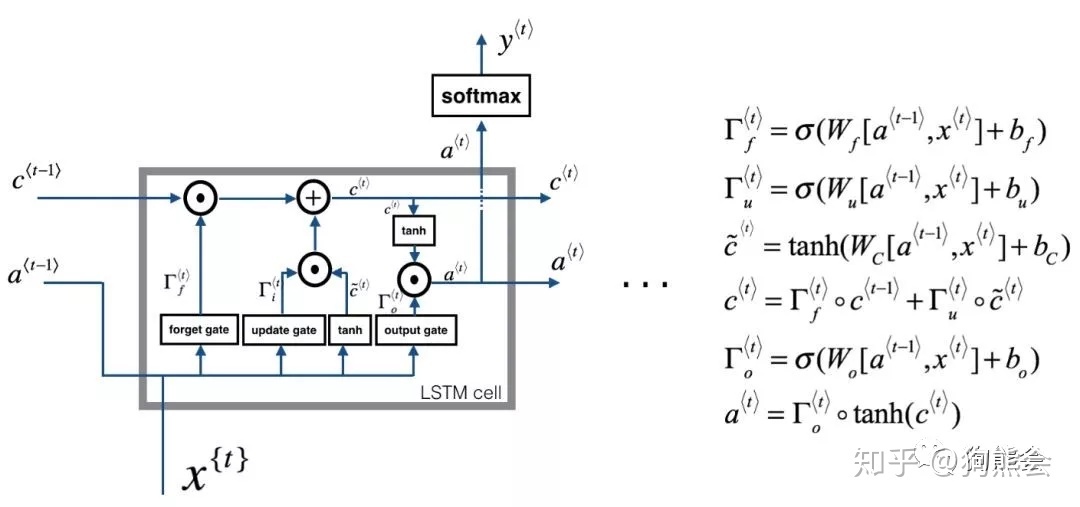
LSTM的结构
先从宏观上感受下RNN和LSTM的区别
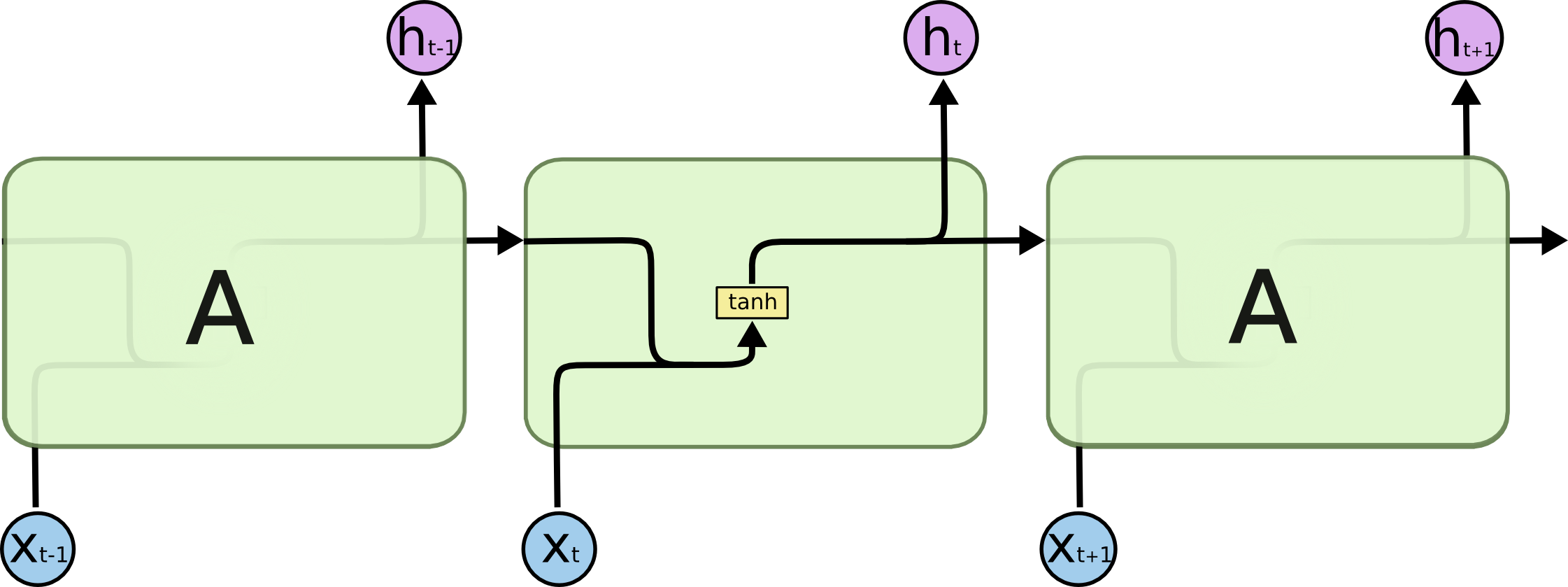
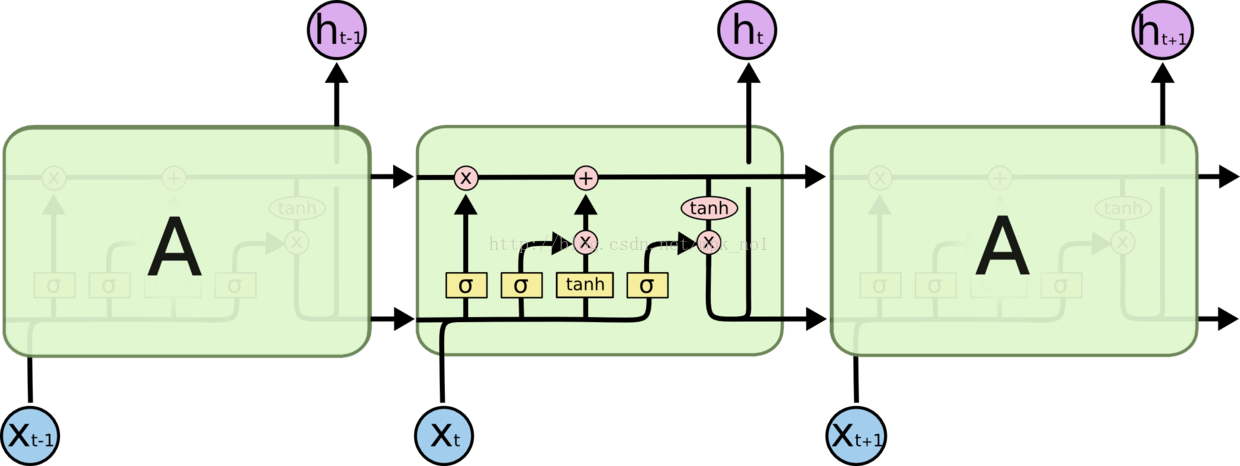
传统RNN每个隐层单元内只是一个简单的tanh层 ,LSTM每个隐层单元内有4层结构:3个sigmoid层,1个tanh层
LSTM结构详解
LSTM的关键是细胞状态C,一条水平线贯穿图形上方,这条线上只有少量线性操作,信息在上面流传很容易保持。
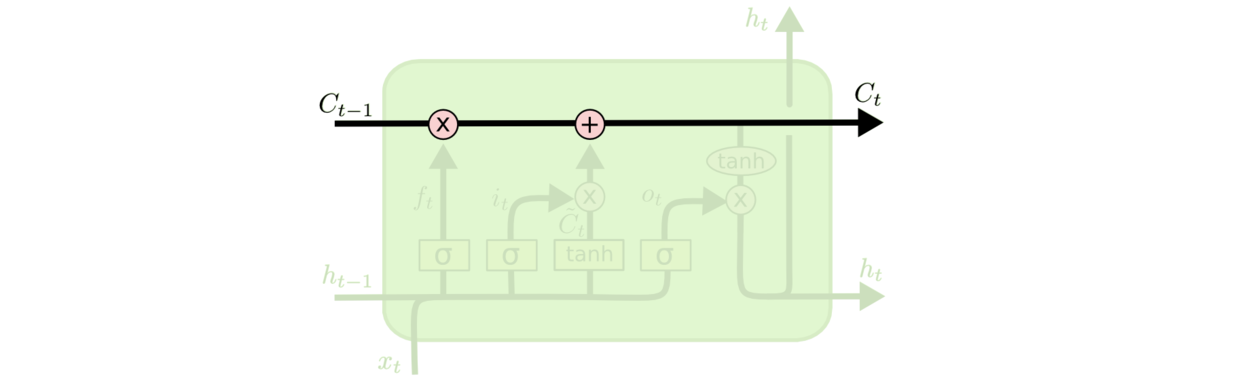
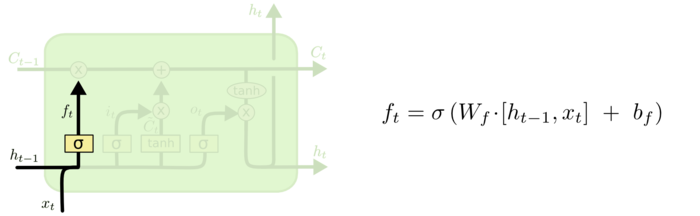
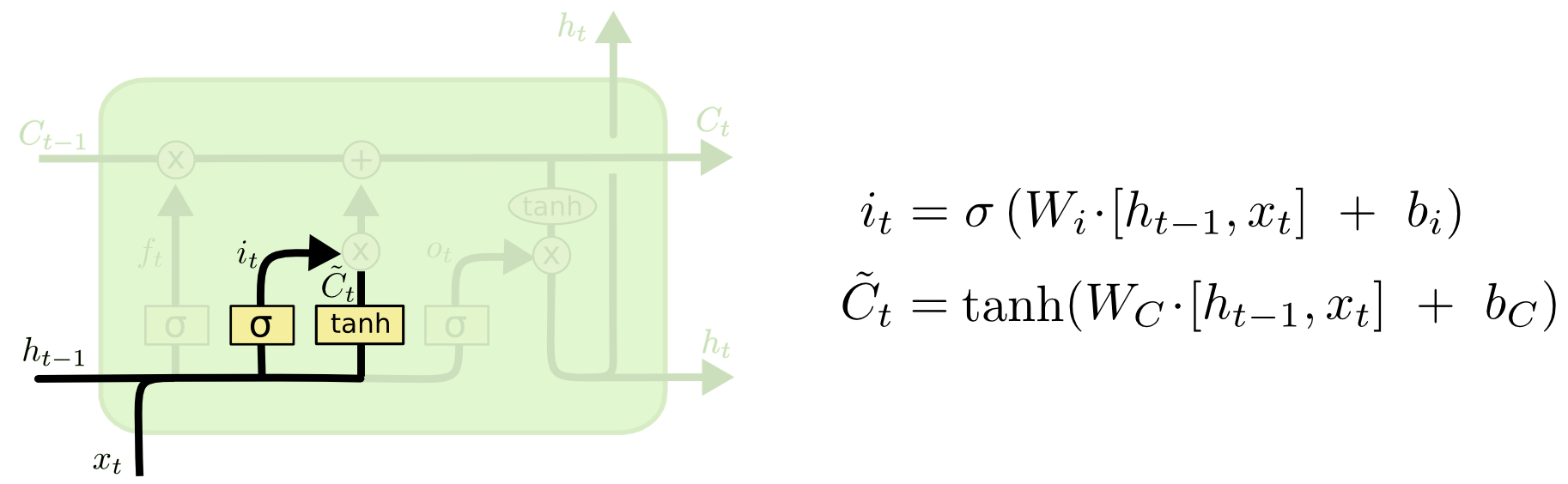
第一层是个忘记层,有个遗忘门,决定细胞状态中丢弃什么信息。
把ht−1和xt拼接起来,传给一个sigmoid函数,该函数输出0到1之间的值,这个值乘到细胞状态Ct−1上去。sigmoid函数的输出值直接决定了状态信息保留多少。
比如当我们要预测下一个词是什么时,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
上一步的细胞状态Ct−1已经被忘记了一部分,接下来本步应该把哪些信息新加到细胞状态中呢?
这里又包含2层:
一个tanh层用来产生更新值的候选项![]() ,tanh的输出在[-1,1]上,说明细胞状态在某些维度上需要加强,在某些维度上需要减弱;
,tanh的输出在[-1,1]上,说明细胞状态在某些维度上需要加强,在某些维度上需要减弱;
还有一个sigmoid层(输入门层),它的输出值要乘到tanh层的输出上,起到一个缩放的作用,极端情况下sigmoid输出0说明相应维度上的细胞状态不需要更新。
在那个预测下一个词的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
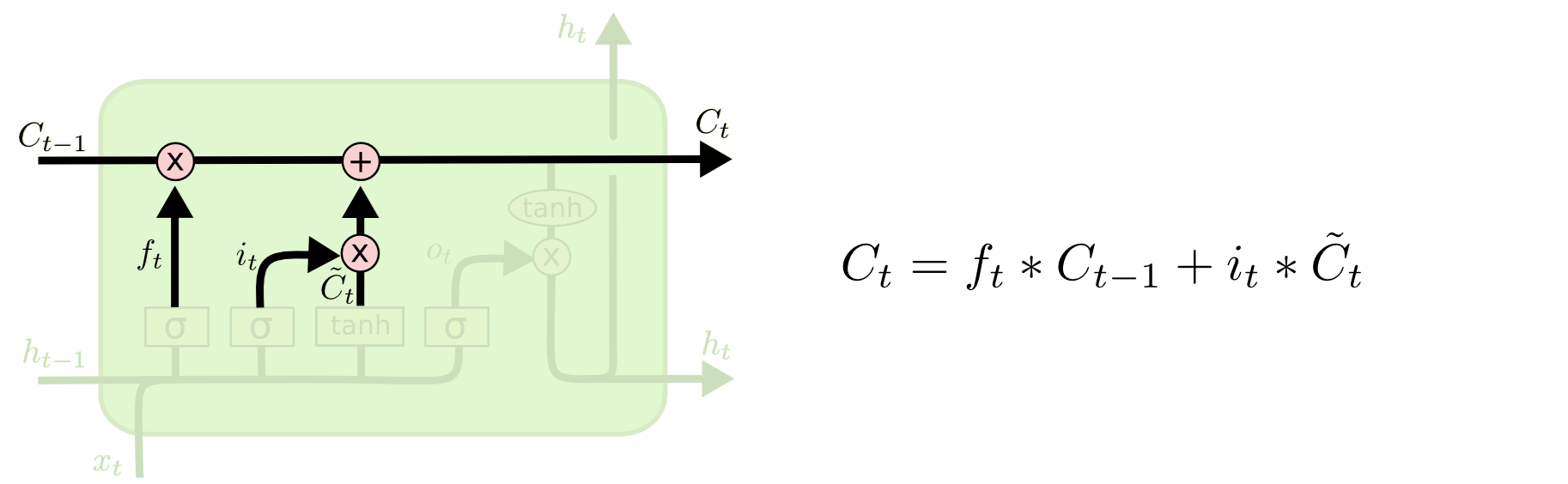
现在可以让旧的细胞状态Ct−1与ft(f是forget忘记门的意思)相乘来丢弃一部分信息,然后再加个需要更新的部分it∗![]() (i是input输入门的意思),这就生成了新的细胞状态Ct。
(i是input输入门的意思),这就生成了新的细胞状态Ct。
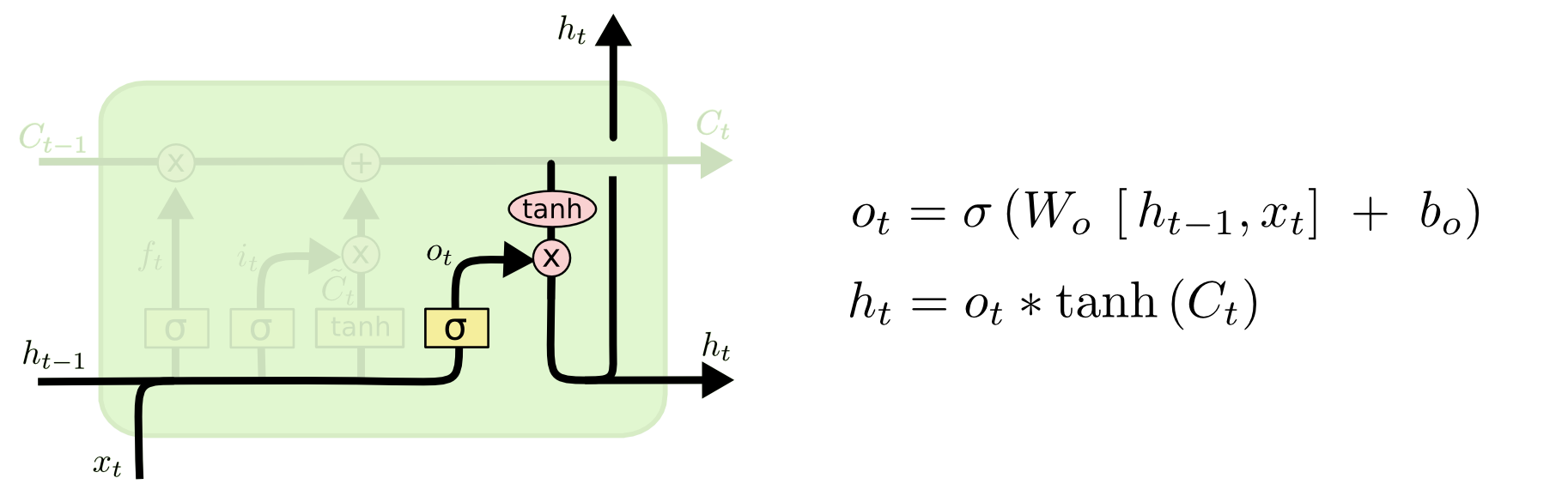
最后是输出门,决定输出什么。
输出值跟细胞状态有关,把Ct输给一个tanh函数得到输出值的候选项。候选项中的哪些部分最终会被输出由一个sigmoid层来决定。
在那个预测下一个词的例子中,如果细胞状态告诉我们当前代词是第三人称,那我们就可以预测下一词可能是一个第三人称的动词。
总结一下
比较流行的叫法是“门”
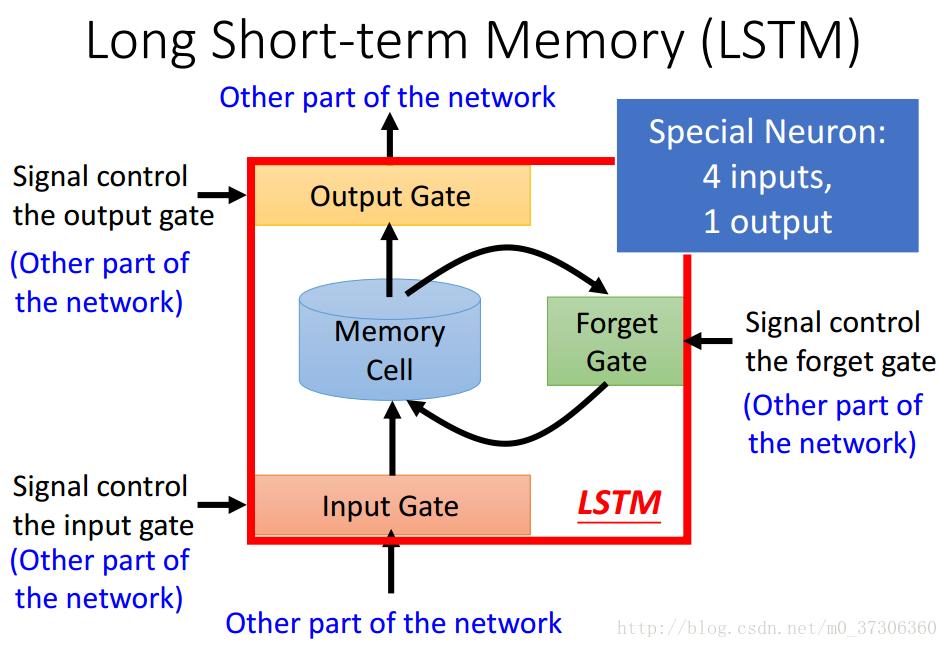
LSTM包括四个输入,一个输出。
Input Gate的功能是外界能否存入值到Memory里去。当打开时,能存入,当关闭时,则不能存入值。
Output Gate的功能是决定Memory的值能否传递到外面单元去。
Forget Gate 的功能是什么时候要把过去记忆的东西忘掉。
Input Gate和Output Gate以及Forget Gate的打开和关闭都是通过学习自己学习得到的。
而LSTM有四个inputs和一个output:
1.想要被存入到Memory里面的值,但是不一定存的进去(看Input Gate的开关)
2.操控Input Gate的输入
3.操控Output Gate的输入
4.操控Forget Gate的输入
一个输出:
Memory输出的值(不一定能输出,要受Output Gate的控制)
以上是最简单的LSTM,后面我会通过实例来阐述复杂一点的LSTM。
LSTM缺点的形象描述
接着上面的形象描述讲,LSTM虽然在学习方法上跟人类很像,但是并不如人类那么智能,为什么呢?
因为LSTM的每个门都有个激活函数sigmoid,sigmoid的特点是大多数时候都要么无限接近1,要么无限接近0,这使得LSTM在总结经验时不能像人类那样很好地吸收精华,去掉糟粕,而是要么全盘忘掉以前,要么全盘接受以前,要么全盘否定现在,要么全盘接受现在,所以LSTM只能算是个比较极端的人。
2020-2-25 更新
我重新形象的解释一下 LSTM
记忆:在我们的记忆里,一定有一些我们可以认为正确的东西,我们叫做经验,也有一些我们无法确定对错的东西,我们只能先记住,日后再判断对否;
记忆是长久的,有用的没用的,我们都放在记忆里;
经验:我们暂时认为正确的东西,他存在于记忆里;
经验是短期的,我们每天都有新的认知,从而得到新的经验,忘掉老的经验,当然新老经验之间会有交集;
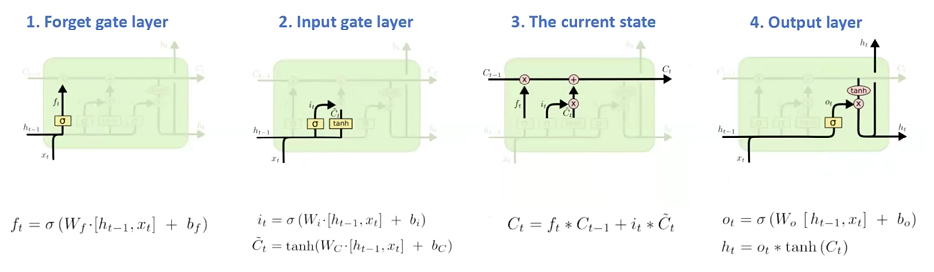
遗忘门:忘记记忆里确定错误的东西
当我们接触到新的事物[x]时,我们会结合现有经验[h]来判断记忆里的东西[c]是否正确,或者有多少正确,忘掉错误的,记住正确的,c*σ(x,h)
输入门:在记忆里加入新的东西
当我们接触到新的事物[x]时,我们会结合现有经验[h]来判断新事物多少是可能正确的,现有经验[h]哪些是正确的,然后把它们存入记忆[c],c+σ1(x,h)* σ2(x,h)
输出门:从记忆里总结新的经验
结合新的事物[x] 和现有经验[h] 对新的记忆进行梳理总结,形成新的经验[h_new],σ1(x,h)*σ2(c)
然后输出新的经验[h_new] 和 记忆[c_new]
2022-7-25 更新
通过代码 更进一步理解 LSTM

class LSTM(nn.Module): def __init__(self, input_size, hidden_size, output_size, num_layers=1): """初始化函数的参数与传统RNN相同""" super(LSTM, self).__init__() # 将hidden_size与num_layers传入其中 self.hidden_size = hidden_size self.num_layers = num_layers # 实例化预定义的nn.LSTM self.lstm = nn.LSTM(input_size, hidden_size, num_layers) # 实例化nn.Linear, 这个线性层用于将nn.RNN的输出维度转化为指定的输出维度 self.linear = nn.Linear(hidden_size, output_size) # 实例化nn中预定的Softmax层, 用于从输出层获得类别结果 self.softmax = nn.LogSoftmax(dim=-1) def forward(self, input, hidden, c): """在主要逻辑函数中多出一个参数c, 也就是LSTM中的细胞状态张量""" # 使用unsqueeze(0)扩展一个维度 input = input.unsqueeze(0) # 将input, hidden以及初始化的c传入lstm中 rr, (hn, c) = self.lstm(input, (hidden, c)) # 最后返回处理后的rr, hn, c return self.softmax(self.linear(rr)), hn, c def initHiddenAndC(self): """初始化函数不仅初始化hidden还要初始化细胞状态c, 它们形状相同""" c = hidden = torch.zeros(self.num_layers, 1, self.hidden_size) return hidden, c
1.ht 既是传递给下层的经验,也是该时刻点的输出
2.ht 只是 lstm 的输出,真正的输出 可能要在 ht 后面再 加一层网络 转换成 我们需要的 output
参考资料:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人