
首先学习RNN需要一定的基础,即熟悉普通的前馈神经网络,特别是BP神经网络,最好能够手推。
所谓前馈,并不是说信号不能反向传递,而是网络在拓扑结构上不存在回路和环路。
而RNN最大的不同就是存在环路。
为什么需要RNN
1. 特征之间序列性
普通的神经网络的输入,具备样本独立同分布(iid), 特征也是独立的,多数也是同分布的,特征之间谁先谁后无所谓,
而现实中描述一件事情,往往是逻辑性的,有先后顺序的,
比如理解一个句子,只看句子中的词是无法理解整个句子的,再如猜猜下一个字,看到 “天空很”,下面肯定是 “蓝”,
此时普通的神经网络就无能为力了。
2.特征的不确定性
普通的神经网络,每个样本的特征个数必须相同,
而现实中有很多是不同的,比如将一个句子进行分类,看看是消极的还是积极的,每个句子长度肯定不同,此时普通的神经网络也无能为力。
于是,专门处理序列数据的RNN就诞生了。
RNN的结构
首先看一个简单的RNN
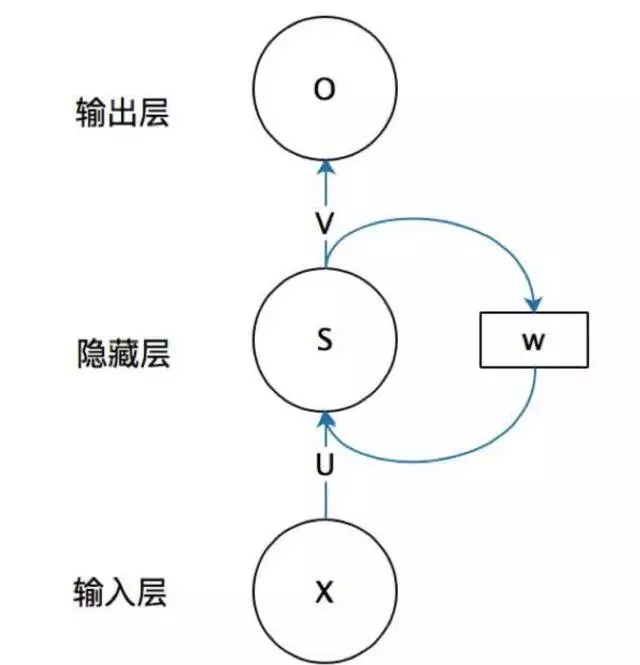
x是输入,s o是对应层的输出,u v 是对应层的权重,还有w
可以看到,唯一不同的就是隐藏层多了一个环路。
环路代表s的值不仅取决于x,而且取决于上次隐藏层的输出,即上个s,而w就是这条传播线路上的权重矩阵。
把上图按时间顺序展开
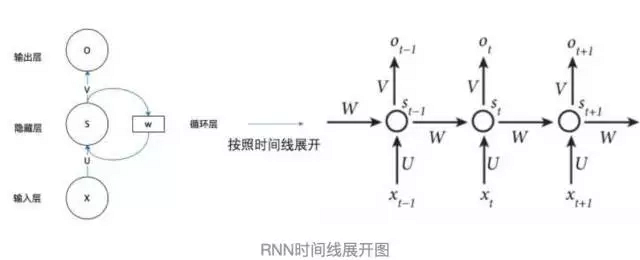
xt是特征,t代表序列(可以理解为时间),t=1,2...n,代表了一个样本
此图可以清晰的看到RNN处理数据的流程,特点就是每个时刻隐藏层的输出s不仅取决于输入x,而且取决于上一时刻的输出,这使得RNN具有记忆功能
由图可以得到如下公式
Ot=g(V*St)
St=f(U*Xt+W*St-1)
将上图扩展为多个神经元
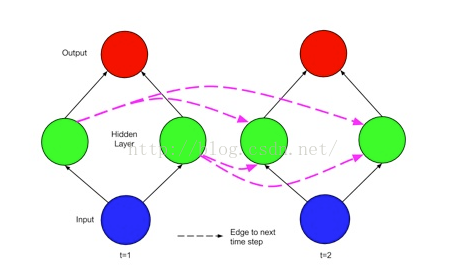
这张图就是比较完整的RNN网络结构
RNN实例图,更容易理解
1. 预测下个单词
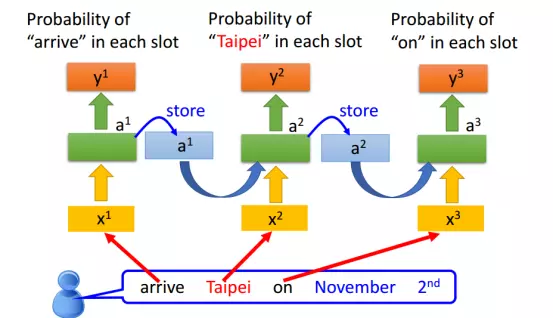
2. 预测下个字母

把图扩展为多层- Deep RNN

Pytorch 简单实现 RNN,看代码更容易理解网络结构

import torch from torch import nn import numpy as np ### 用 网络的方式 实现 RNN class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__() self.hidden_size = hidden_size self.u = nn.Linear(input_size, hidden_size) self.w = nn.Linear(hidden_size, hidden_size) self.v = nn.Linear(hidden_size, output_size) self.tanh = nn.Tanh() self.softmax = nn.LogSoftmax(dim=1) def forward(self, inputs, hidden): u_x = self.u(inputs) # ux hidden = self.w(hidden) # ws hidden = self.tanh(hidden + u_x) # s' = f(ux + ws) output = self.softmax(self.v(hidden)) # o = g(vs') return output, hidden def initHidden(self): return torch.zeros(1, self.hidden_size) # 矩阵的方式实现 RNN # 这里要啰嗦一句,RNN的前向中还计算了一个输出向量output vector, # 但根据RNN的原始公式,它的输出只有一个hidden_state,至于整个网络最后的output vector, # 是在hidden_state之后再接一个全连接层得到的,所以并不属于RNN的内容。 # 包括pytorch和tf框架中,RNN的输出也只有hidden_state。理解这一点很重要。 class RNN(): def step(self, x, hidden): # update the hidden state hidden = np.tanh(np.dot(self.W_hh, hidden) + np.dot(self.W_xh, x)) return hidden
总结
学习过CNN的朋友可能觉得RNN很容易,其实不然,这里只是入门,RNN 具有很多衍生网络及网络特性
CNN我就不写了,CNN有什么问题可以在此处探讨。
在实际场景中,CNN多用于图像识别,RNN多用于自然语言、语音和视频识别,当然图像其实也是序列性的,空间连续。
参考资料:
https://blog.51cto.com/u_15088375/3248583 Pytorch 实现 RNN



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人