Prometheus概述
Prometheus是什么
首先, Prometheus 是一款时序(time series) 数据库, 但他的功能却并非支部与 TSDB , 而是一款设计用于进行目标 (Target) 监控的关键组件.
结合生态系统内的其他组件, 例如: Pushgateway, Altermanager, Grafana等,可构成一个完整的IT监控系统.
时序数据简介
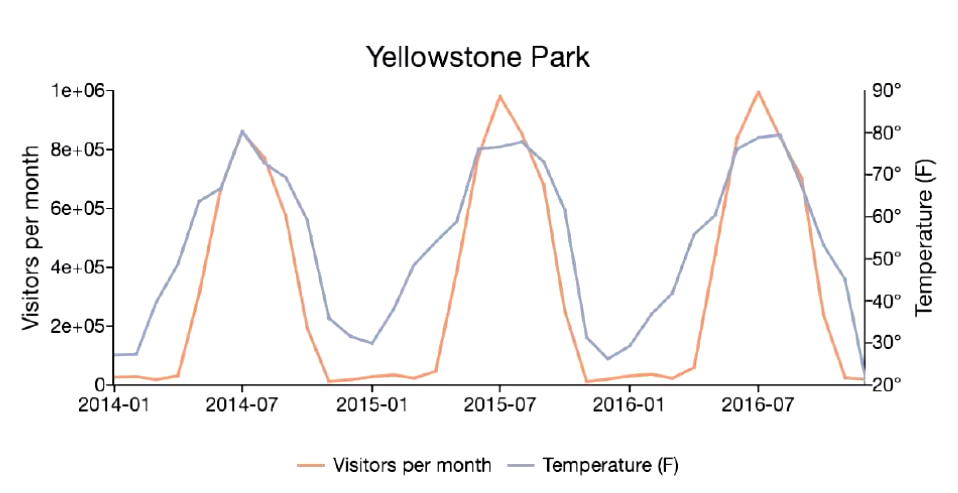
时序数据, 是在一段时间内通过重复测量(measurement)而获得的观测值的结合, 将这些观测值绘制于图形之上, 他会有一个数据轴和时间轴.
服务器指标数据, 应用程序性能监控数据, 网络数据等也是时序数据.
Prometheus 的优点
Prometheus怎么工作的
基于 HTTP call, 从配置文件指定的网络端点(endpoint) 上周期性获取指标数据
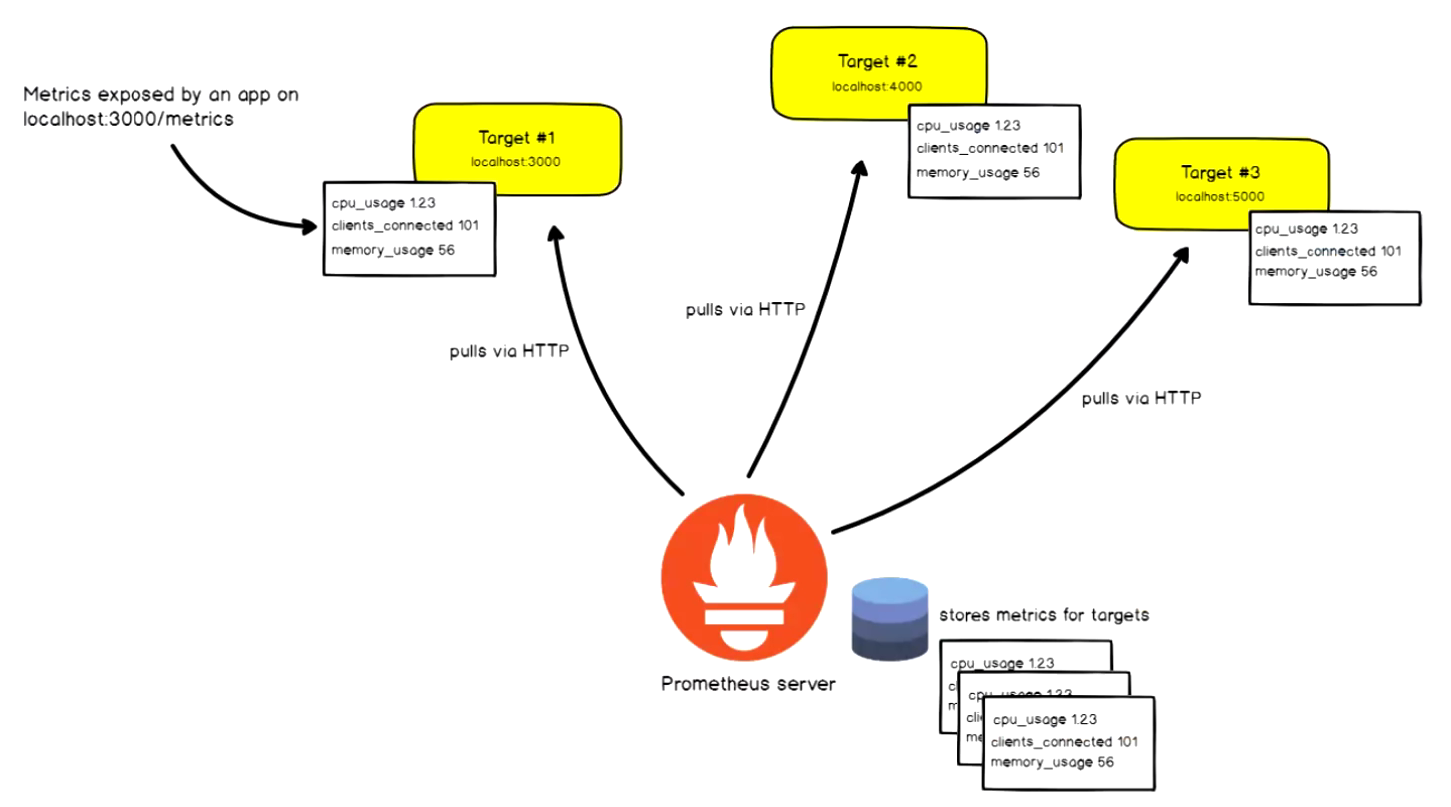
Prometheus 支持的监控方式
Prometheus 支持通过三种类型的途径从目标上 "抓取(Scrape)" 指标数据.
-
Exporters
-
Instrumentation (测量系统, 应用程序内建的支持Prometheus采集格式)
-
Pushgateway
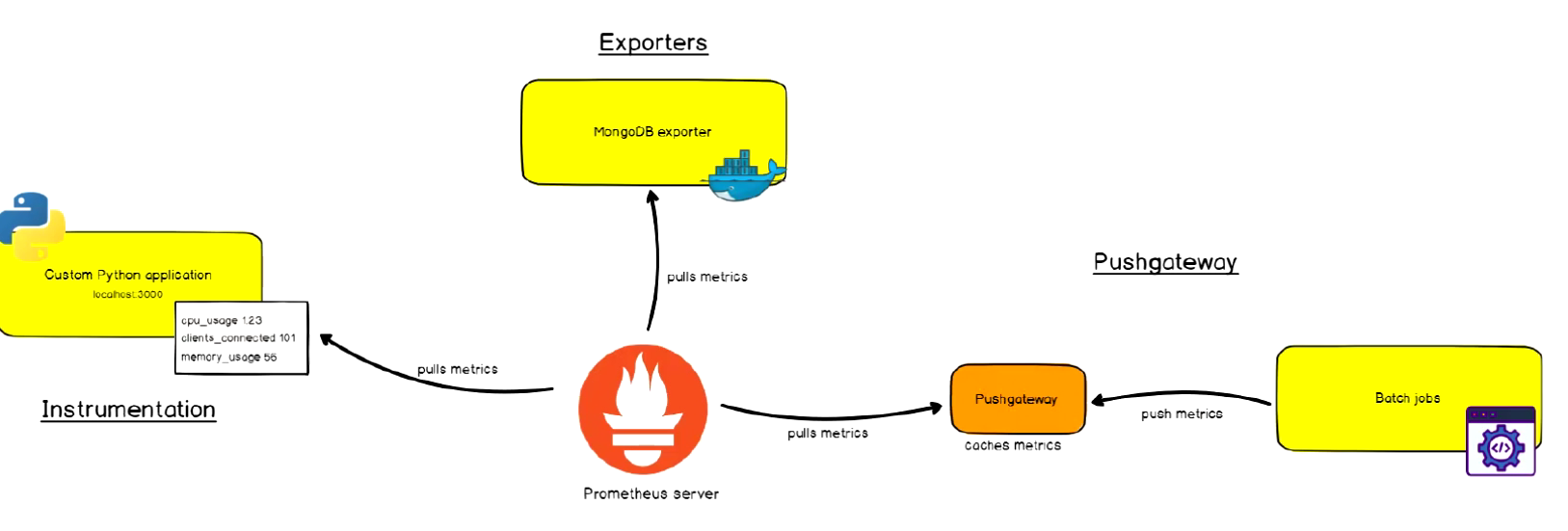
Prometheus Push and Push
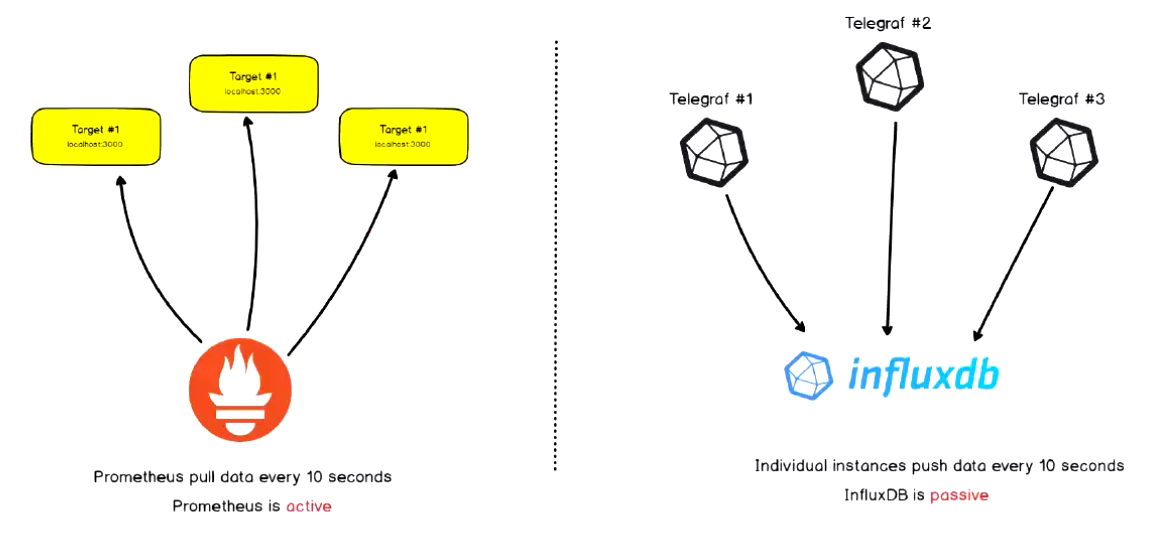
Prometheus 同其他的 TSDB 相比有一个非常典型的特性: 它主动从各 Target 上 "拉取(pull)"数据, 而非等待被监控端的推送"push" .
两个方式各有优劣, 其中, Pull 模型的优势在于.
集中控制: 有利于将配置集中在 Prometheus Server 上完成, 包括指标及采取速率等.
Prometheus的根本目标在于手机在 Target 上预先完成集合的聚合型数据, 而非一款由时间驱动的存储系统.
Prometheus 生态组件
Prometheus 负责时序性指标数据的采集以及存储, 但是数据的分析, 聚合及直观展示以及告警等功能并非由 Prometheus Server 所负责.
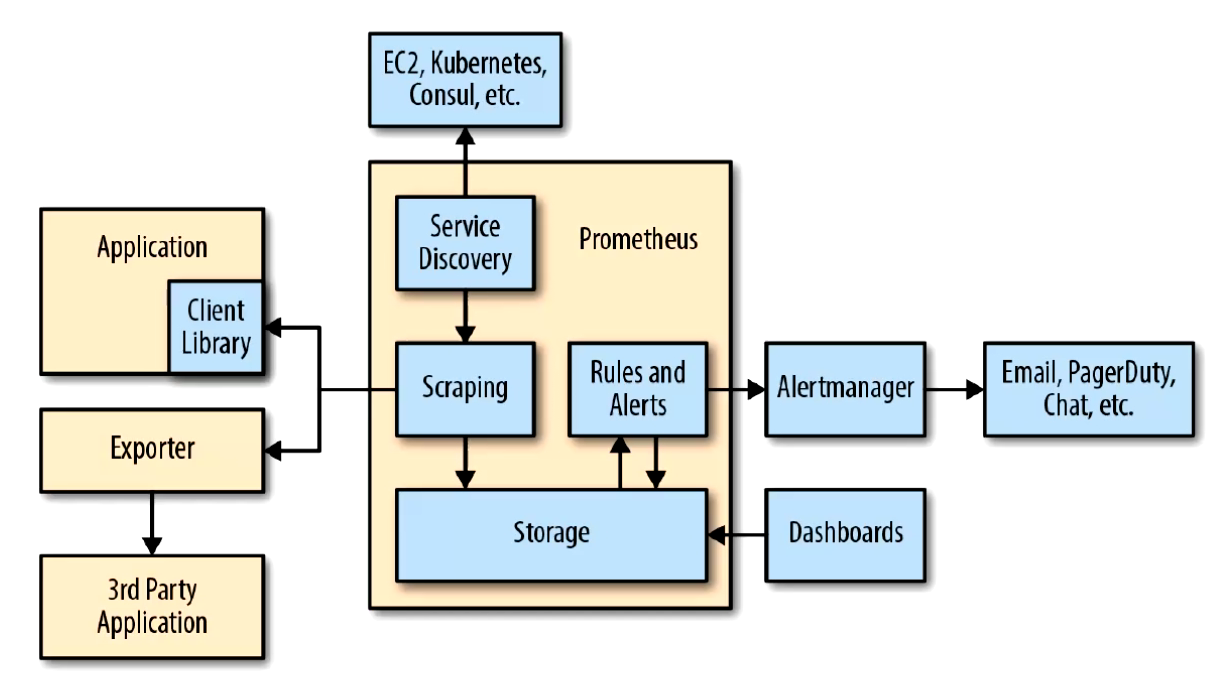
Prometheus数据模型
Prometheus 仅用于以 "键值" 形式存储时序式的聚合数据, 它并不支持存储文本信息,
其中的 "键" 称为指标 (Metric), 它通常意味着CPU速率, 内存使用率或区分空闲比例等
同一个指标会适配多个目标设备, 因而他使用 "标签作为元数据", 从而为 Metric添加更多的信息描述纬度.
这些标签可以作为过滤器进行指标过滤及聚合运算.
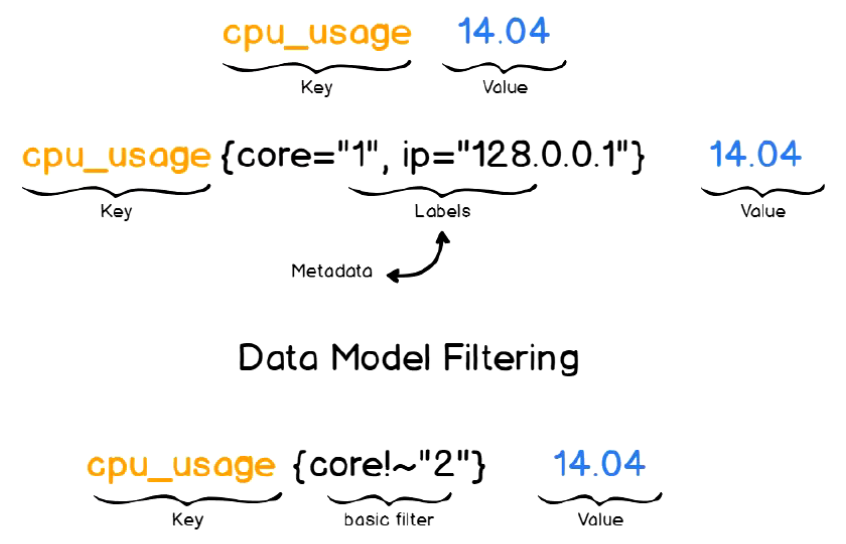
Prometheus 的指标定义
Prometheus 的所有指标 (Metric) 被统一定义为: <metric name> {label_name=<label_value>,....}
指标定义设计指标名称和标签两个部分.
指标名称(metric name)
指标名称用于说明指标的含义, 例如 http_request_total 代表 HTTP 请求总数.
指标名称必须由字母, 数字, 瞎花钱或者冒号组成. 其中的冒号指标不能用于 exporter.
标签(label)
标签可以体现指标的纬度特征, 用于过滤和聚合, 它通过指标名 (label name) 和标签值 (label value ) 这种键值对的形式, 形成多种纬度.
指标的某些标签以 "__"开头的, 这些标签时在 Prometheus 系统内部使用的, 在形式上 http_request_total{status="200"} 和 {__name__="http_request_total ", status="200"} 代表相同的指标.
Prometheus 指标采用标签的方式能够很好的与容器结合, 无论是原生 Docker 还是 Kubernetes, 都通过标签关联资源.
指标类型(Metric Types)
Prometheus 使用四种方法来描述监控的指标
Counter
计数器, 用于保存单调递增型的数据, 例如站点访问次数, 机器的启动时间, HTTP访问量等, 不能为负值, 也不支持减少, 但可以重置回0;
Counter 具有很好的不关联性, 不会因为重启而置0, 我们使用 Counter 指标是, 通常会结合 rate() 方法获取该指标在某个时间段的变化, 例如, "HTTP请求总数", 指标就属于典型的 Counter 指标, 通过对他进行 rate()操作, 可以得出请求的变化率.
Gauge
仪表盘, 用于存储有着起伏特征的数据实施变化的数据, 例如内存空闲大小等可增可减.
Gauge 是 Counter 的超集, 但存在指标数据丢失的可能性, Counter 能让用户确切的了解指标随时间的变化状态, 而 Gauge 则可能随时间流逝而精准度越来越低.
Histogram
直方图, 它会在一段时间范围内对数据进行采样, 并将其计入可配置的 bucket 之中, Histogram 能够存储更多的信息, 包括样本值分布在每个 bucket (bucket 自身可配置) 中的数量, 所有样本值之和以及总的样本数量, 从而 Prometheus 能够使用内置函数进行如下操作.
-
计算样本平均值, 以值的总和除以值的数量.
-
计算样本分位值: 分位数有助于来哦接符合特定标准数据个数, 例如评估响应时长超过1秒中的请求比例, 若超过20%即发送告警信息.
Summary
摘要, Histogram 的扩展类型, 单他是直接被检测端自行聚合计算出分位数, 并将计算结果响应给Prometheus Server 的样本采集请求, 因而其分位数计算是由监控端完成.
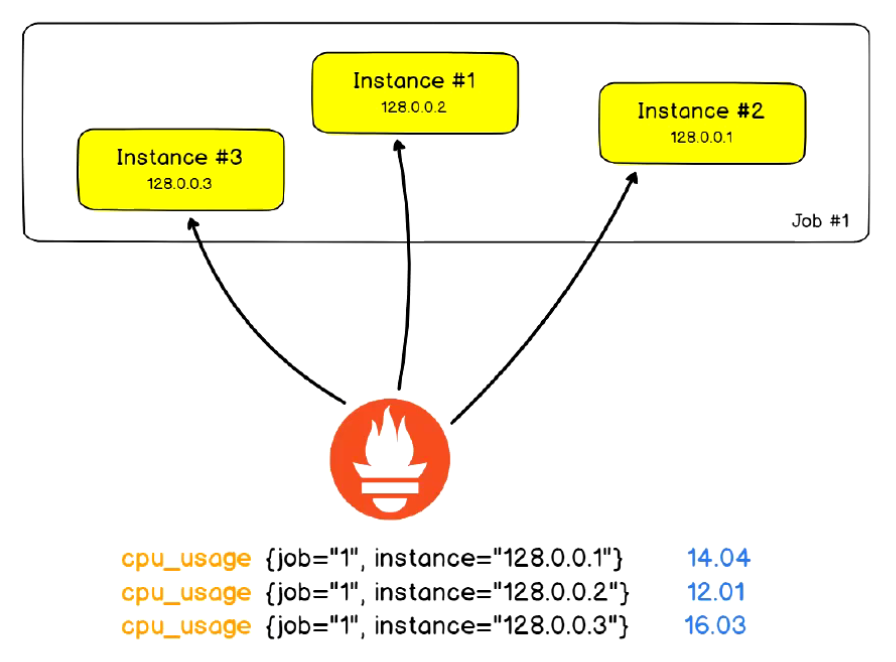
作业(Job)和实例(Instance)
Instance: 即能够接收 Prometheus Server 数据 Scrape 操作的每个网络端点(endpoint), 即为一个 Instance(实例)
通常, 具有类似功能的 Instance 的集合成为一个 Job, 例如一个 Mysql 主从复制几圈中的所有 Mysql 进程.
作者:闫世成
出处:http://cnblogs.com/yanshicheng

