Prometheus-PromQL
简介
官网文档地址: https://prometheus.io/docs/prometheus/latest/querying/basics/
Prometheus 提供了一种名为 PromQL(Prometheus Query Language)的函数式(查询语言),可以让用户实时选择和聚合时间序列数据。表达式的结果既可以显示为图形,也可以在 Prometheus 的表达式浏览器中查看为表格数据,也可以通过HTTP API由外部系统使用。
作业(Job) 和 实例 (Instance)
Instance: 能够接收 Prometheus Server 数据 Scrape 操作的每个网络端点(endpoint), 即为一个 Instance.
通常, 具有类似功能的 Instance 的集合称为一个 Job, 例如一个 Mysql 主从复制集群中的所有 Mysql 进程.
prometheus特殊tag说明
-
address 采集endpoint的地址
-
name metrics 的名称
-
-
job 任务
-
metrics_path 采集的http path 如 /metrics /cadvisor/metrics
表达式语言数据类型
在 Prometheus 的表达式语言中,表达式或子表达式可以计算为以下四种类型之一:
- 即时向量- 一组时间序列,每个时间序列包含一个样本,所有时间序列都共享相同的时间戳
- 范围向量- 一组时间序列,包含每个时间序列随时间变化的数据点范围
- 标量- 一个简单的数字浮点值
- String - 一个简单的字符串值;目前未使用
根据用例(例如,当绘制与显示表达式的输出时),作为用户指定表达式的结果,这些类型中只有一些是合法的。例如,返回即时向量的表达式是唯一可以直接绘制的类型。
时间序列选择器
即时向量选择器
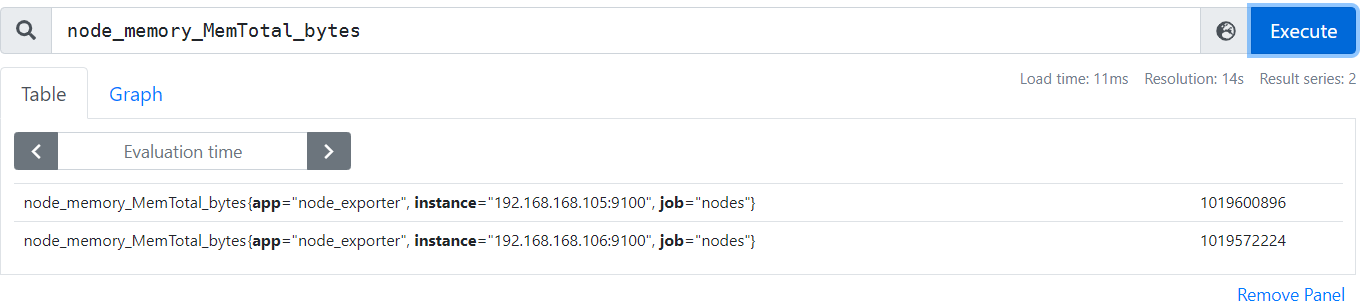
即时向量选择器允许在给定的时间戳(即时)选择一组时间序列和单个样本值:在最简单的形式中,只指定一个度量名称。这会产生一个包含所有具有此度量名称的时间序列元素的即时向量。
-
指标名称: 用于限定特定指标下的时间序列, 即负责过滤指标,可选.
-
匹配器(Matcher): 或者成为标签选择器, 用于过滤时间序列上的标签, 定义在{}之中.可选
-
-
例如:
http_requests_total 和 http_request_total{}的功能相同, 都是用于返回http_requests_total指标下各时间序列的即时样本. -
仅给定匹配器, 返回所有符合给定的匹配器的所有时间序列上的即时样本.
-
这些时间序列可能会有这不同的指标名称
-
例如: {job=".*", method='get'}
-
-
指标名称和匹配器的组合; 返回给定的指定的, 且符合给定的标签过滤器的所有时间序列上的即时样本.
-
例如:
-
-
标签匹配模式
=:选择与提供的字符串完全相同的标签。!=:选择不等于提供的字符串的标签。=~:选择与提供的字符串正则表达式匹配的标签。!~:选择与提供的字符串不匹配的标签。
范围向量选择器
范围向量字面量的工作方式与即时向量字面量类似,不同之处在于它们从当前时刻选择了一系列样本。从语法上讲,在向量选择器的末尾将持续时间附加在方括号 ( []) 中,以指定应该为每个结果范围向量元素提取多远的时间值。
在此示例中,我们选择了过去 5 分钟内为所有具有指标名称http_requests_total和job标签设置为 的时间序列记录的所有值prometheus:
http_requests_total{job="prometheus"}[5m]
时间范围
持续时间指定为一个数字,后跟以下单位之一:
ms- 毫秒s- 秒m- 分钟h- 小时d- days - 假设一天总是 24 小时w- 周 - 假设一周总是 7dy- 年 - 假设一年总是 365d
rate(node_network_receive_bytes_total{device!="lo"}[1m]) / 1024
偏移修改器
(node_network_receive_bytes_total{device!="lo"}offset 5h)
四种指标类型
Counter
计数器是代表一个累积指标单调递增计数器,其价值只能在重新启动增加或归零。例如,您可以使用计数器来表示已服务请求,已完成任务或错误的数量。
http_request_total
通常 Counter 的总数并没有直接作用, 而是需要借助 rate, topk, increase 和 irate 等函数来生成样本数据的变化情况增长率.
-
-
topk(http_requests_total[2]), 高灵敏度函数, 用于计算指标的瞬时速率.
-
基于样本范围内的最后两个样本进行计算, 相比较 rate 函数来说, irate更适用于短期啥时间范围的变化速率分析.
-
-
increase 同时极差速率.
Gauge
当前数, 表示单个数值,可以任意地上升和下降的度量。仪表通常用于测量值,如温度或当前内存使用情况,但也用于可以上下波动的“计数”,如并发请求的数量。
node_memory_MemFree_bytes
用于存储值为可增可减的指标的样本数据, 常用于进行求和, 取平均值, 最小值, 最大值等聚合计算, 也会经常结合 PromQL的predict_linear和delta函数使用.
-
predict_linear(v range-vector, t, scalar)函数可以预测时间序列v在t秒后的值, 它通过线性回归的方式来预测样本数据的Gauge变化趋势.
-
delta(v range-vector) 函数计算范围向量中每个时间序列元素的第一个值与最后一个值之差, 从而展示不同时间点上的样本值的差值.
-
delta(cpu_temp_celsius{host='www.superops.com'}[2h]), 返回该服务器上的CPU温度与2小时之前的差异.
Histogram
直方图样本观测(通常之类的东西请求持续时间或响应大小)和计数它们配置的桶中。它还提供所有观测值的总和。它还提供所有观察值的总和。
具有基本指标名称的直方图<basename>在抓取期间公开多个时间序列:
- 观察桶的累积计数器,公开为
<basename>_bucket{le="<upper inclusive bound>"} - 的总和的所有观察值的,公开为
<basename>_sum - 该计数已观察到的事件的,公开为
<basename>_count(等同于<basename>_bucket{le="+Inf"}上文)
使用该 histogram_quantile()函数 从直方图甚至直方图的聚合计算分位数。直方图也适用于计算 Apdex 分数。在对桶进行操作时,请记住直方图是 累积的。
Histogram 是一种对数据分布情况的图形展示, 由一系列高度不等的长条图(bar)或线段表示, 用于展示单个测度的值的分布.
一般用横轴表示某个指标纬度的数据取值区间, 用纵轴表示样本统计的频率或频数, 从而能够以二维图的形式展现数值的分布情况.
为了构建Histogram, 首先需要将值的范围进行分段, 即将所有值的整个可用范围分成一系列连续, 相邻(相邻处可以使等同值) 但不重叠的间隔, 而后统计每个间隔中有多少值.
从统计学的角度看, 分为数不能被聚合, 也不能进行算数运算.
Histogram 实现将特定测度可能的取值范围分隔为多个样本空间, 并通过对落入bucket内的观测值进行计数以及请求和操作.
与常规方式略有不同的是, Prometheus 取值间隔的划分采用的累积区间间隔机制, 即米格 bucket 中的样本均包含了其前面所有的 bucket 中的样本, 因而也称为累积直方图.
-
可降低Histogram 的维护成本.
-
支持粗略计算样本值的分位数,
-
单独提供了 _sum和 _count 指标, 从而支持计算平均值.
-
累积间间隔机制生成的样本数据需要额外使用内置的histogram_quantile()函数即可根据Histogram指标来计算相应地分位数, 即某个 bucket 的样本数在所有样本数中占据的比例.
histogram_quantile() 函数在计算分为数时会假定每个区间内的样本满足线性分布状态, 因而他的结果仅是一个预估值, 并不完全准确.
预估的准确度取决于bucket区间划分的粒度, 粒度越大, 准确度越低
# http所有接口 总的95分位值 # sum/count 可以算平均值 prometheus_http_request_duration_seconds_sum/ prometheus_http_request_duration_seconds_count # histogram_quantile(0.95, sum(rate(prometheus_http_request_duration_seconds_bucket[5m])) by (le,handler)) histogram_quantile(0.95, sum(rate(prometheus_http_request_duration_seconds_bucket[1m])) by (le)) # range_query接口的95分位值 histogram_quantile(0.95, sum(rate(prometheus_http_request_duration_seconds_bucket{handler="/api/v1/query_range"}[5m])) by (le)
Summary
与histogram类似,摘要样本观察(通常是请求持续时间和响应大小之类的东西)。虽然它还提供观察的总数和所有观察值的总和,但它计算滑动时间窗口内的可配置分位数。
具有基本指标名称的摘要<basename>在抓取期间公开多个时间序列:
指标类型是客户端的特征, 而 Histogram 在客户端仅是简单的桶划分和分桶计数, 分位数由 Prometheus Server 基于样本数据进行估算, 因而其结果未必准确, 甚至不合理的 bucket 划分会导致较大的误差.
Summary 是一种类似于 Histogram 的指针类型, 单他在客户端于前一段时间内(默认为10分钟)的米格采样点进行统计, 计算并储存了分位数数值, Server 段直接抓取相应即可.
但Summary不支持sum或avg一类的聚合运算, 而且其分位数由客户端计算并生成, Server 段无法获取客户端未定义的分位数, 而 Histogram 可通过PromQL任意定义, 有较好的灵活性.
- 观察事件的流式φ-分位数(0 ≤ φ ≤ 1),暴露为
<basename>{quantile="<φ>"} - 的总和的所有观察值的,公开为
<basename>_sum - 该计数的事件已经被观察到,暴露
<basename>_count
# gc耗时 # HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles. # TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"} 0.000135743 go_gc_duration_seconds{quantile="0.25"} 0.000872805 go_gc_duration_seconds{quantile="0.5"} 0.000965516 go_gc_duration_seconds{quantile="0.75"} 0.001055636 go_gc_duration_seconds{quantile="1"} 0.006464756 # summary 平均值 go_gc_duration_seconds_sum /go_gc_duration_seconds_count
聚合函数
一般来说, 单个指标的价值不大, 在监控场景中往往需要联合并可视化一组指标, 这种联合机制即聚合操作, 例如将计数请求和平均值, 分位数, 标准差集等统计函数应用于时间序列的样本之上生成具有统计学意义的结果等.
对于查询结果实现按照某种分类机制进行分组(group by)并将查询结果按照组进行聚合计算, 也是比较常见的需求, 例如 分组统计, 分组求平均值分组求和等.
组合操作由聚合函数针对一组值进行计算并返回单个值或少量值作为结果.
- Prometheus 内置提供了 11 哥聚合函数称为 聚合运算符.
- 这些函数仅支持应用于单个即时向量的元素, 返回值也是具有少量元素的新向量或者标量.
- 这些聚合运算符即可以基于向量表达式返回结果中的时间序列的所有标签纬度进行分组聚合, 也可以仅基于指标的标签纬度分组后进行分组聚合.
聚合表达式
PromQL 中的聚合操作语法可采用如下两种
-
-
<aggr-op>[without|by(label list)] ([args,], <过滤器>)
分组聚合: 先分组, 后聚合
-
without: 从结果向量中删除由without子句指定的标签, 未指定的那部分标签则用作分组标准.
-
by: 功能与 without 刚好相反, 它仅使用 by 子句中指定的标签进行聚合, 结果向量中出现但为被 by 子句指定的标签则会被忽略.
sum
求和函数
sum(node_filesystem_files) by (instance, mountpoint)
avg
求平均值
avg(node_filesystem_files) by (instance)
count
对分组内的时间序列进行数量统计
count(node_memory_MemAvailable_bytes) by (instance)
stddev
对样本值求标准差, 以帮助用户了解数据的变动大小
stddev(node_memory_MemAvailable_bytes) by (instance)
stdvar
对样本值求平方差,他是求标准差过程中的中间状态
stdvar(node_memory_MemAvailable_bytes) by (instance)
min
求样本值最小的值
min(node_filesystem_size_bytes) by (instance)
max
求样本值中的最大者
topk
逆序返回分组内的样本值最小的k个时间序列及其值
bottomk
顺序返回分组内的样本值最小的前k个时间序列及其值
quantile
分位数用于评估数据的分布状态, 该函数会返回分组内指定的分位数的值, 及数值落在小于等于指定的分为区间的比例.
count_values
对分组内的时间序列的样本值进行数量统计.
rate
irate(v range-vector)计算范围向量中时间序列的每秒即时增长率。这是基于最后两个数据点。单调性中断(例如由于目标重新启动导致计数器重置)会自动调整。
以下示例表达式返回范围向量中每个时间序列的两个最近数据点的 HTTP 请求的每秒速率,该请求最多可回溯 5 分钟:
rate(prometheus_http_requests_total{}[5m])
irate
irate(v range-vector)计算范围向量中时间序列的每秒即时增长率。这是基于最后两个数据点。单调性中断(例如由于目标重新启动导致计数器重置)会自动调整。
以下示例表达式返回范围向量中每个时间序列的两个最近数据点的 HTTP 请求的每秒速率,该请求最多可回溯 5 分钟:
rate(prometheus_http_requests_total{}[5m])
二元运算符
PromQL 支持基本的算数运算和逻辑运算, 这类运算支持使用操作符连接两个操作数, 因而也称为二元运算符或二元操作符.
支持运算
-
-
即时向量和标量间的运算, 将运算符应用于向量上的每个样本.
-
两个即时向量间的运算, 遵循向量匹配机制.
将运算符用于两个即时向量间的运算时, 可基于向量匹配模式, 定义其运算机制.
算数运算
-
支持的运算符: +, - , *, /, %, ^
比较运算符
-
== , != , >, <, >=, <=
逻辑集合运算
-
and , or , unless
-
目前该运算仅在两个即时向量间进行, 长不支持标量运算.
运算符优先级
^, *, /, %, +, -, ==, !=, <=, <, >=, >, and , unless, or
向量匹配
即时向量间的运算时 PromeQL的特色之一, 运算时, PromeQL为会左侧向量中的每个元素找到匹配的元素, 其匹配行为有两种基本类型.
-
一对一 (One-toOne)
-
一对多或多对多(Many-to-One, One-to-Many)
一对一匹配
即时向量一对一匹配.
-
从运算符的两边表达式所获取的即时向量一次比较, 并找到唯一匹配, 标签完全一致的样本值.
-
找不到匹配项则不会出现在结果中.
匹配表达式语法:
-
ignore:定义匹配检测时要忽略的标签. -
on:定义匹配检测时指使用的标签.
<即时向量> <运算> ignoring<label list> <即时向量>
<即时向量> <运算> on<label list> <即时向量>
实例:
rate(http_requests_total{status_code=~"5.*"}[5m]) > .1* rate(http_requests_total[5m])
- 左侧会生成一个即时向量, 计算出 5xx 响应码的各类请求的增长速率.
- 右侧会生成一个即时向量, 计算出所有标签组合所代表的增长速率
- 计算时, PromeQL 会在操作符左右两侧的结果元素中找到标签完全一致的元素, 进行比较.
- 计算出没类请求中的 500 响应码在该类请求中所占的比例.
rate(prometheus_http_requests_total{code=~'2.*'}[5m]) > .1 * rate(prometheus_http_requests_total[5m])
sum (rate(prometheus_http_requests_total{code=~'2.*'}[5m])) by (handler) > 0.1 * sum by (handler) (rate(prometheus_http_requests_total[5m]))
rate(prometheus_http_requests_total{code=~'2.*'}[5m])> on (handler) 0.1 * sum by (handler) (rate(prometheus_http_requests_total[5m]))
多对多
一对多/多对以匹配
-
一 侧的每个元素, 可与 多侧的多个元素进行匹配.
-
必须使用 group_left 或 group_right 明确指定那侧为 多 侧.
-
语法
<vector expr> <bin-op>
PromeQL 的解析过程
PromeQL表达式时一段文本, Prometheus 会解析这段文本, 将它转化为一个结构化的语法树对象, 进而实现响应的数据计算逻辑.
调用 Prometheus Restful API 查询表达式计算工作流入有图所示.
请求数据的时候给出 step 参数就是这里 interval, 它设定结果中相邻两个点的间隔, 对 Prom QL的每次 Evaluation 都是针对某个确定的时间点和 Statement 来计算, 得到一个 Vector(时间戳相同的向量.)
Prometheus 可以将异构(时间戳不一致) 的多维时间序列经过计算转化为同结构 时间戳一直的多时间序列纬度.
作者:闫世成
出处:http://cnblogs.com/yanshicheng

