Canal和Otter介绍和使用
Canal
Canal原理

原理相对比较简单:
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
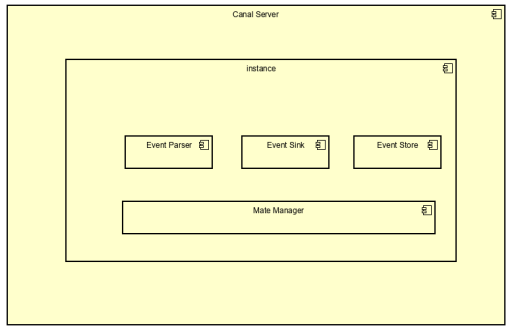
Canal架构
Canal集群
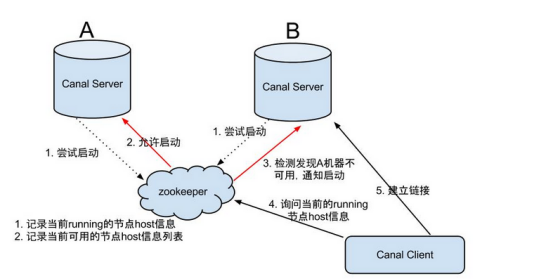
大致步骤:
- canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态
- 一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance.
- canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect.
Canal数据流程
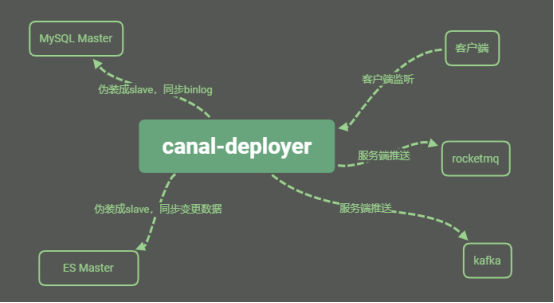
相关问题:
canal过滤数据的单位是数据库,可以过滤到表:
|
参数名字 |
参数说明 |
默认值 |
|
canal.instance.filter.regex (白名单) |
mysql 数据解析关注的表,Perl正则表达式. 多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
1. 所有表:.* or .*\\..* 5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔) |
.*\\..* |
|
canal.instance.filter.black.regex (黑名单) |
mysql 数据解析表的黑名单,表达式规则见白名单的规则 |
无 |
Canal单实例和多实例:instance对应于一个数据队列(1个server对应1..n个instance)(canal官方文档--简介)
Canal集群仅仅是为了可靠性:为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态。(针对同一主备)
(canal官方文档--简介)
Otter
Otter原理

原理描述:
1. 基于Canal开源产品,获取数据库增量日志数据。
2. 典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
3. 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
Otter架构

名词解释
- Pipeline:从源端到目标端的整个过程描述,主要由一些同步映射过程组成
- Channel:同步通道,单向同步中一个Pipeline组成,在双向同步中有两个Pipeline组成
- DataMediaPair:根据业务表定义映射关系,比如源表和目标表,字段映射,字段组等
- DataMedia : 抽象的数据介质概念,可以理解为数据表/mq队列定义
- DataMediaSource : 抽象的数据介质源信息,补充描述DateMedia
- ColumnPair : 定义字段映射关系
- ColumnGroup : 定义字段映射组
- Node : 处理同步过程的工作节点,对应一个jvm
Otter分布式架构
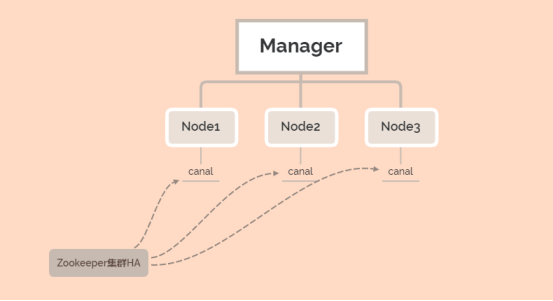
由于单节点容易导致宕机时数据丢失,所以可以将多个Node绑定到同一Zookeeper集群,在宕机时重新选举工作节点,实现高可用。
Otter完整搭建图
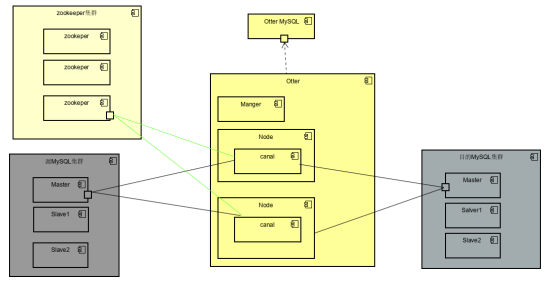
Otter完整搭建需要otter数据库,zookeeper集群,Manager管理组件和Node工作组件。otter运行时数据保存在单独的otter数据库,zookeeper实现高可用,Node完成同步数据的工作。
Otter操作
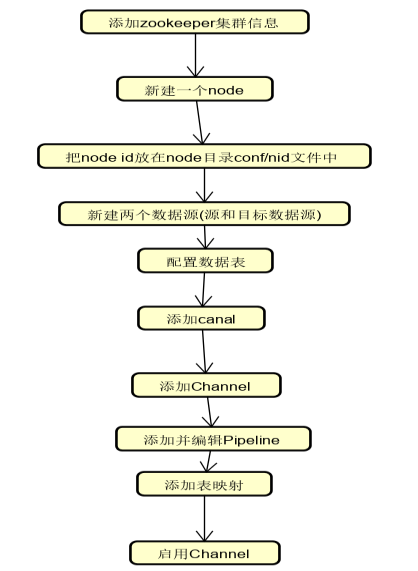
安装完成后打开manager地址例如:http://172.16.0.3:8080,默认用户名密码是admin/admin

单向同步配置:
前提条件: 数据库表结构相同