

数据库用法之limit,order by
数据库limit用法及其优化
1.语法:
*** limit [offset,] rows
一般是用于select语句中用以从结果集中拿出特定的一部分数据。
offset是偏移量,表示我们现在需要的数据是跳过多少行数据之后的,可以忽略;rows表示我们现在要拿多少行数据。
2.栗子:
①select * from mytbl limit 10000,100
上边SQL语句表示从表mytbl中拿数据,跳过10000行之后,拿100行
②select * from mytbl limit 0,100
表示从表mytbl拿数据,跳过0行之后,拿取100行
③select * from mytbl limit 100
这条SQL跟②的效果是完全一样的,表示拿前100条数据
④为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1: mysql> SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last
mysql> SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last
3.用处:
我目前用到的地方是数据库查询分页,比如前台要展示数据库中数据,需要后台实现分页,传入数据要有“页码page”跟“每页数据条数nums”。
对应SQL大概是这样子:select * from mytbl order by id limit (page-1)*nums,nums
4.问题发现:
在数据量不大或者是大数据量的前几页的时候,性能还算不坏,但是大数据量页码稍微大一点性能便下降比较严重。
5.问题分析:
原因出在Limit的偏移量offset上,比如limit 100000,10虽然最后只返回10条数据,但是偏移量却高达100000,数据库的操作其实是拿到100010数据,然后返回最后10条。
那么解决思路就是,我能不能跳过100000条数据然后读取10条,而不是读取100010条数据然后返回10条数据。
6.问题解决实现:
原SQL语句如下:select *from mytbl order by id limit 100000,10
改进后的SQL语句如下:
select *from
mytbl
where id>=
(
select id from mytbl order by id limit 100000,1
)
limit 10
注:假设id是主键索引,那么里层走的是索引,外层也是走的索引,所以性能大大提高
order by 用法
首先,order by是用来写在where之后,给多个字段来排序的一个DQL查询语句。
其次,order by写法:
1. select 字段列表/* from 表名 where 条件 order by 字段名1 asc/desc, 字段名2 asc/desc,.......
2. select 字段列表/* from 表名 where 条件 order by 字段序号 asc/desc, 字段序号 asc/desc,....... (此时字段序号要从1开始)
3. select 字段列表/* from 表名 where 条件 order by 字段别名1 asc/desc, 字段别名2 asc/desc,.......(这里类似于第一种,无非就是把字段名加了个别名来代替而已。)
然后,order by的方式:
1.asc 升序,可以省略,是数据库默认的排序方式
2.desc 降序,跟升序相反。
最后要注意order by的原则,写在最前面的字段,他的优先级最高,也就是写法中第一个的字段名1的优先级最高,优先执行他的内容。
下面举个栗子吧!
这里我有几个表

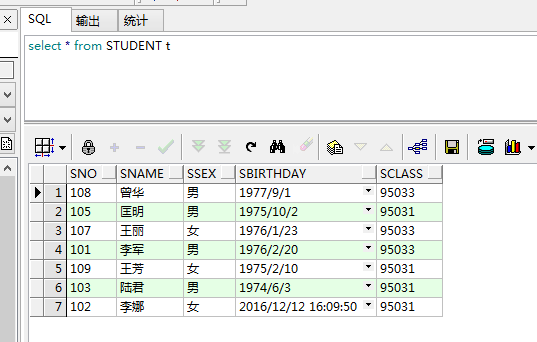
首先以sclass的降序查找student表中的记录
写法为:
select * from student t order by t.sclass desc;
输出为:
可以看到是以sclass的降序排列的。
再来:以Cno升序、Degree降序查询Score表的所有记录。
写法为:
select * from score s order by s.cno, s.degree desc;
输出为:
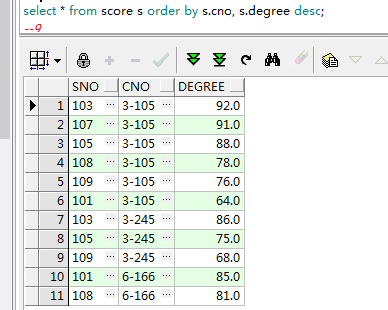
可以看到是优先以cno的升序来排列的,在cno相同的里面再以degree的降序来排列的。
所以总结一下,order by的用法就是用来做排序,写在where之后,简单明了。

