字符串
字符串
字符串(str) 字符串, 可以保存少量数据并进行相应的操作
在第一天的时候咱们简单的认识了下字符串,今天我们好好的来认识一下这个让你又喜又优的字符串
字符串是可以存储一些数据,方便我们使用
数字转字符,字符转数字
str --> int int(要转换的内容,只有带引号的数字可以)
int -- > str str(要转换的内容,没有限制)
字符串加
a = '你好' b = '世界' print(a + b) 结果: 你好世界
通过刚刚我们的测试发现字符串也是可以进行加法操作的,字符串相加其实有个专业的名词 --- 字符串拼接;相加的规则就是必须都是字符串才能相加
字符串乘
a = '你好' print(a * 3)
结果:
你好你好你好
索引(下标)
大家在上学的时候就会发现在一个班有的同学的名字是一样的,最后大家为了好区分就有了外号,我们每个人都有个学号,其实学校就是为了防止重名找错人,
学号就是一种能够保证唯一且准确的手段,这种手段在计算机中存在,这种手段叫做索引,也有人称之为下标.注意:索引如果操作会报错
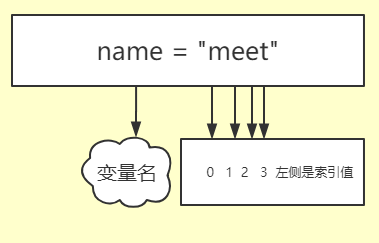
图上就是对"meet"字符串进行索引排号,其实图上有一点大家不难看出m对应的是数字0,如果让我们人来给排号.下意识的会从1开始.
因为我们从小的时候就是从1开始数数的,但是在计算机中数数确实要从0开始,其实这个点也是对程序的入门.
以后在碰到这种类似的问题我们就知道是从0开始计数,测试一下:
a = 'meet'
#索引 0123
print(a[3]) 结果: t
细心的老铁们会发现这[ ]是干啥的,这个是一个查找,我不知道字符串中第一个是什么,但是我知道第一个的索引,我就可以通过这个方式来查看
比方:我不知道这个学生叫什么,但是我知道他的学号.我也可以通过学号找到这个同学.
图上这个是从左到右的一种排序,其实还有一种从右像左的排序,看下图:
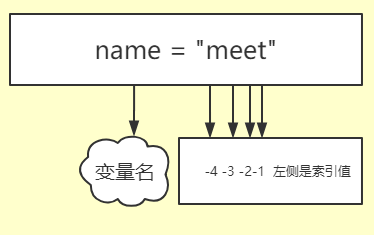
这个查看和上边的一样,只不过是索引排序的方式不一样,他这次的排列序号是从右向左并且还是以-1开始,这里的-1其实就是表示我们的倒数第一个
-2表示倒数第二个,这样排列,如果我们的字符串比较长的时候想要获取最后一个就完全可以使用-1,看以下示例:
a = 'meet' #索引 -4-3-2-1 print(a[-1])
结果:
t
切片
切片就是对字符串指定区域进行切除并将切除的部分打印出来
a = 'meet'
#索引 0123 print(a[0:3])
结果:
mee
[第一个位置是开始:第二个位置是终止]中间必须使用分号,这样的写法就是从索引0开始获取到索引3结束,(终止的索引是不包含的,获取的是这个区间的内容)就是顾头不顾尾.
步长
a = 'meet' print(a[0:3:1]) 结果: mee
中括号里第一个参数是起始位置,第二参数是终止位置,第三个参数现在告诉大家是步长(每次走几步)
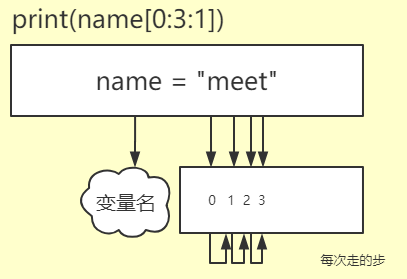
上面我在中括号最后写了步长的数字后没什么变化是因为当步长不写的时候默认就是1,可以尝试换个数字尝试
a = 'meat' print(a[0:3:2])
结果:
ma
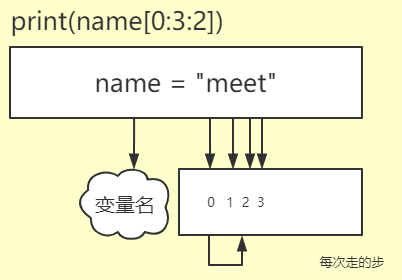
当步长设置为2的时候,咱们只需要用起始位置0加上步长2,结果也就2然后在把索引为2的找到,2在加上步长2就是4,当要查找索引4是发现终止索引就是3,
所有不会进行查找.最终的结果就是ma.
练习题一:
s ='Python最NB'
获取s字符串中前3个内容
获取s字符串中第3个内容
获取s字符串中后3个内容
获取s字符串中第3个到第8个
获取s字符串中第2个到最后一个
获取s字符串中第1, 3, 5个内容
获取s字符串中第2, 4, 6个内容
获取s字符串中所有内容
获取s字符串中第4个到最后一个, 每2个取一个
获取s字符串中倒数第5个到最开始, 每3个取一个


s = 'Python最NB' # 获取s字符串中前3个内容 print(s[0:3]) # 获取s字符串中第3个内容 print(s[2]) # 获取s字符串中后3个内容 print(s[-3:]) # 获取s字符串中第3个到第8个 print(s[2:9]) # 获取s字符串中第2个到最后一个 print(s[1:]) # 获取s字符串中第1, 3, 5个内容 print(s[0::2]) # 获取s字符串中第2, 4, 6个内容 print(s[1::2]) # 获取s字符串中所有内容 print(s) # 获取s字符串中第4个到最后一个, 每2个取一个 print(s[3::2]) # 获取s字符串中倒数第5个到最开始, 每3个取一个 print(s[-5:0:-3])
练习题二:
判断一句话是否是回文:正着念和反着念是一样的,例如上海自来水来自海上
name = input("输入回文") if name[0:] == name[-1::-1]: print("是回文") else: print("不是回文")
此处利用下标将输入的文件,进行正序和倒叙排列,然后再对排列好的字符串进行对比,若是一样则为回文
练习三:
有字符串s = "123a4b5c"
通过对s切片形成新的字符串s1, s1 = "123"
通过对s切片形成新的字符串s2, s2 = "a4b"
通过对s切片形成新的字符串s3, s3 = "1345"
通过对s切片形成字符串s4, s4 = "2ab"
通过对s切片形成字符串s5, s5 = "c"
通过对s切片形成字符串s6, s6 = "ba2"
s = "123a4b5c" # 通过对s切片形成新的字符串s1, s1 = "123" print(s[0:3]) # 通过对s切片形成新的字符串s2, s2 = "a4b" print(s[3:6]) # 通过对s切片形成新的字符串s3, s3 = "1345" print(s[0::2]) # 通过对s切片形成字符串s4, s4 = "2ab" print(s[1:6:2]) # 通过对s切片形成字符串s5, s5 = "c" print(s[-1]) # 通过对s切片形成字符串s6, s6 = "ba2" print(s[-3:0:-2])
字符串方法详解
字符串大写: 变量.upper()
name = "aleX leNb" print(name.upper()) 结果: ALEX LENB
字符串小写: 变量.lower()
name = "aleX leNb" print(name.lower()) 结果: alex lenb
字符串首字母大写: 变量.capitalize()
name = "aleX leNb" print(name.capitalize()) 结果 Alex lenb
每个单词首字母大写:(特殊分割符)
la='laix,asd' la = la.title() print(la) 结果: Laix,Asd
以什么开头: 变量.startswith('al')
name = "aleX leNb" print(name.startswith('al')) 结果 True
以什么结尾: 变量.endswith('Nb')
# 6.判断name变量是否以"Nb"结尾,并输出结果 name = "aleX leNb" print(name.endswith('Nb')) 结果: True
去除头尾两边的空格: 变量.strip(' ')
1.移除 name 变量对应的值两边的空格,并输出处理结果 name = " aleX leNb " print(name.strip(' ')) 2.移除name变量左边的"al"并输出处理结果 name = "aleX leNb" new_name = name.strip('al') print(new_name) print(name[2:]) 结果: eX leNb 3.移除name变量右面的"Nb",并输出处理结果 print(name.strip('Nb')) print(name[0:7]) 结果: aleX le 4.移除name变量开头的a"与最后的"b",并输出处理结果 print(name[1:8]) print(name.strip('ab')) 结果: leX leN
字符串替换: 变量.replace('l','p')
# 7.将 name 变量对应的值中的 所有的"l" 替换为 "p",并输出结果 name = "aleX leNb" print(name.replace('l','p',)) 结果: apeX peNb # 8.将name变量对应的值中的第一个"l"替换成"p",并输出结果 name = "aleX leNb" print(name.replace('l','p',1)) 结果 apeX leNb 可以指定替换的次数,可全部替换也可只替换一次,上面小括号的1是只替换一次l换成p的操作
分割: 变量.split('l')
name = "aleX leNb" # 9.将 name 变量对应的值根据 所有的"l" 分割,并输出结果。 print(name.split('l')) 结果: ['a', 'eX ', 'eNb'] # 10.将name变量对应的值根据第一个"l"分割,并输出结果。 print(name.split('l',1)) 结果: ['a', 'eX leNb']
统计出现的次数: 变量.count('l')
name = "aleX leNb" # 14.判断name变量对应的值字母"l"出现几次,并输出结果 print(name.count('l')) # 15.如果判断name变量对应的值前四位"l"出现几次,并输出结果 1. print(name.count('l',0,4)) 2. new_name = name[0:4] nam = new_name.count("l") print(nam) #可以指定范围从何开始到何结束在此区间进行搜索
查找下标:
变量.index('N')
变量.find('N')
name = "aleX leNb" # 16.从name变量对应的值中找到"N"对应的索引(如果找不到则报错),并输出结果 print(name.index('N')) 结果 7 # 17.从name变量对应的值中找到"N"对应的索引(如果找不到则返回-1)输出结果 print(name.find('N')) 结果 7 # 18.从name变量对应的值中找到"X le"对应的索引,并输出结果 print(name.find('X le')) 结果 3
字符串格式化: 变量.format('name')
name = 'alexdasx:{}' new_name = name.format('name') print(new_name) 结果: alexdasx:name s = '你好{},{}' s1 = s.format('少年','我还好') # 按照顺序填充 print(s1) 结果: 你好少年,我还好 ss = '你好{1},{0}' # ss = '你好{好难受},{少年}' ss1 = ss.format('少年','好难受') # 按照下标填充 print(ss1) 结果: 你好好难受,少年 sss = '你好{name},{age}' # ss = '你好{好难受},{少年}' sss1 = sss.format(age='18',name='meet') # 按照关键字 print(sss1) 结果: 你好meet,18
is系列
判断是不是阿拉伯数字,返回的是布尔值
name = "aleleNb" print(name.isdigit())
判断是不是数字和字母,返回的是布尔值
name = "aleleNb" print(name.isalnum())
判断是不是纯字母及汉字,返回的是布尔值
name = "aleleNb" print(name.isalpha())
字符串.isalnum() 所有字符都是数字或者字母,为真返回 Ture,否则返回 False。
字符串.islower() 所有字符都是小写,为真返回 Ture,否则返回 False。
字符串.isupper() 所有字符都是大写,为真返回 Ture,否则返回 False。
字符串.istitle() 所有单词都是首字母大写,为真返回 Ture,否则返回 False。
字符串.isspace() 所有字符都是空白字符,为真返回 Ture,否则返回 False。
获取长度
name = "aleleNb" print(len(name))
posted on 2018-12-30 14:23 🐳️南栀倾寒🐳️ 阅读(241) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号