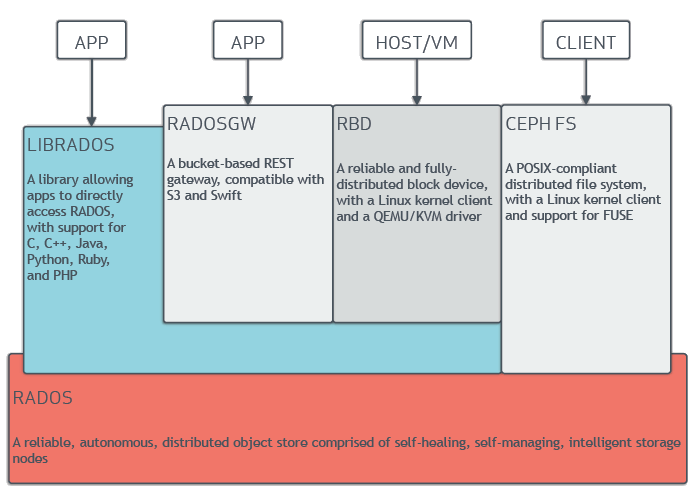
|
CEPH 对象存储
|
CEPH 块设备
|
CEPH 文件系统
|
-
RESTful 接口
-
S3 和 Swift 兼容的 API
-
S3 风格的子域
-
统一的 S3/Swift 命名空间
-
用户管理
-
使用跟踪
-
条纹对象
-
云解决方案集成
-
多站点部署
-
多站点复制
|
-
精简配置
-
图像高达 16 艾字节
-
可配置的条带化
-
内存缓存
-
快照
-
写时复制克隆
-
内核驱动支持
-
KVM/libvirt 支持
-
云解决方案的后端
-
增量备份
-
灾难恢复(多站点异步复制)
|
-
符合 POSIX 的语义
-
将元数据与数据分离
-
动态再平衡
-
子目录快照
-
可配置的条带化
-
内核驱动支持
-
保险丝支持
-
NFS/CIFS 可部署
-
与 Hadoop 一起使用(替换 HDFS)
|
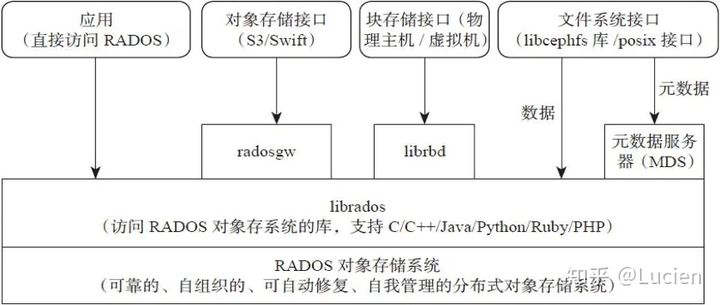
2.ceph的组件和功能
Ceph 提供了一个基于 RADOS 的可无限扩展的Ceph 存储集群,Ceph 存储集群由多种类型的守护进程组成:
- Monitors:Ceph Monitor ( ceph-mon) 维护集群状态的映射,包括监视器映射、管理器映射、OSD 映射、MDS 映射和 CRUSH 映射。这些映射是 Ceph 守护进程相互协调所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。通常至少需要三个监视器才能实现冗余和高可用性。
- 管理器:Ceph 管理器守护进程 ( ceph-mgr) 负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率、当前性能指标和系统负载。Ceph 管理器守护进程还托管基于 Python 的模块来管理和公开 Ceph 集群信息,包括基于 Web 的Ceph 仪表板和 REST API。高可用性通常至少需要两个管理器。
- Ceph OSD:Ceph OSD(对象存储守护进程 ceph-osd)存储数据,处理数据复制、恢复、重新平衡,并通过检查其他 Ceph OSD 守护进程的心跳来向 Ceph 监视器和管理器提供一些监控信息。通常至少需要 3 个 Ceph OSD 来实现冗余和高可用性。
- MDS:Ceph 元数据服务器(MDS,ceph-mds)代表Ceph 文件系统存储元数据(即 Ceph 块设备和 Ceph 对象存储不使用 MDS)。Ceph的元数据服务器允许POSIX文件系统的用户来执行基本的命令(如 ls,find没有放置在一个Ceph存储集群的巨大负担,等等)。
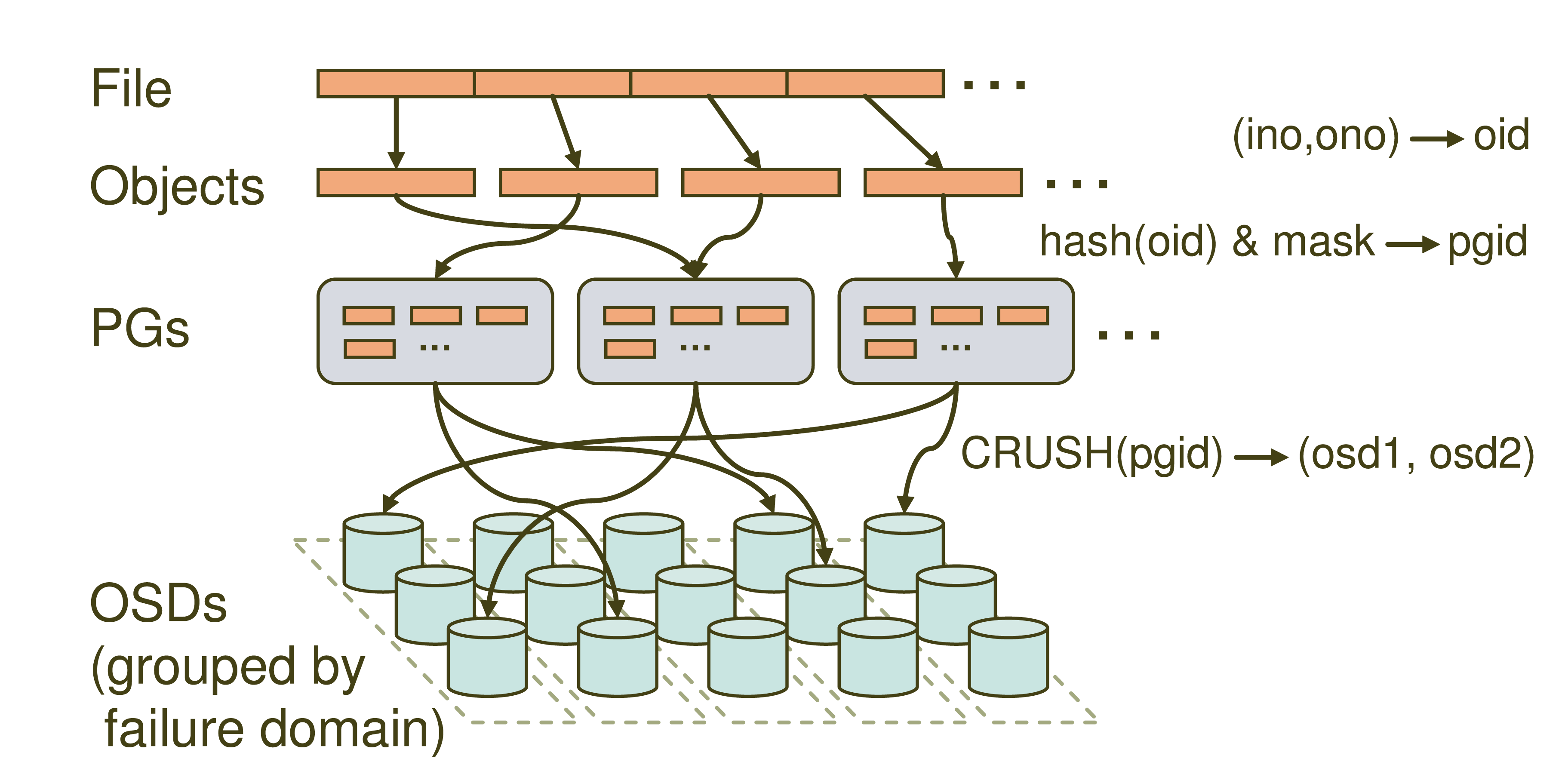
3.ceph的数据读写流程
![]()
主要分四层,File->Objects->PGs->OSDs。
- File: 就是我们想要存储和访问的文件,这个是面向我们用户的,是我们直观操作的对象。
- Object:object就是Ceph底层RADOS所看到的对象,也就是在Ceph中存储的基本单位。object的大小由RADOS限定(通常为2m或者4m)。就跟HDFS抽象一个数据块一样,这里也是为了方便底层存储的组织管理。当File过大时,需要将File切分成大小统一的objects进行存储。
- PG (Placement Group): PG是一个逻辑的概念,它的用途是对object的存储进行组织和位置的映射,通过它可以更好的分配数据和定位数据。
- OSD (Object Storage Device): 它就是真正负责数据存取的服务。
PG和object是一对多的关系,一个PG里面组织若干个object,但是一个object只能被映射到一个PG中。
PG和OSD是多对多的关系,一个PG会映射到多个OSD上(大于等于2,此处即为副本机制),每个OSD也会承载大量的PG。
通过寻址流程图我们可以看到,Ceph中的寻址需要经历三次映射,分别是File->Object,Object->PG,PG->OSD。我们重点提到的CRUSH就是在第三步映射PG->OSD出现的。我们依次看一下。
File->Object
这一步就是将file切分成多个object。每个object都有唯一的id即oid。这个oid是怎样产生的呢,就是根据文件名称得到的。
图中的ino为文件唯一id(比如filename+timestamp),ono则为切分后某个object的序号(比如0,1,2,3,4,5等),根据该文件的大小我们就会得到一系列的oid。
注:将文件切分为大小一致的object可以被RADOS高效管理,而且可以将对单一file的处理变成并行化处理提高处理效率。
Object -> PG
这里需要做的工作就是将每个object映射到一个PG中去,实现方式也很简单就是对oid进行hash然后进行按位与计算得到某一个PG的id。图中的mask为PG的数量减1。这里我们认为得到的pgid是随机的,这与PG的数量和文件的数量有关系。在足够量级的程度上数据是均匀分布的。
PG -> OSD
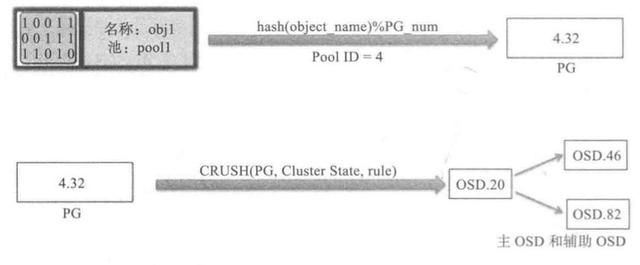
最后一次映射就是将object所在的PG映射到实际的存储位置OSD上。这里应用的就是CRUSH算法了,通过CRUSH算法可以通过pgid得到多个osd(跟配置有关)。
crush算法流程
4.Ceph集群部署
4.1 服务器硬件配置及IP规划
OS:Ubuntu 18.04.5 LTS (GNU/Linux 4.15.0-153-generic x86_64)
硬件配置:
4核CPU/8GB内存/200G磁盘/2千兆网卡
4个osd节点各额外增加5块100G的磁盘
服务器列表
|
hostname
|
public-net
|
cluster-net
|
|
ceph-deploy
|
192.168.2.2
|
172.1.0.2
|
|
mon1
|
192.168.2.21
|
172.1.0.21
|
|
mon2
|
192.168.2.22
|
172.1.0.22
|
|
mon3
|
192.168.2.23
|
172.1.0.23
|
|
mgr1
|
192.168.2.31
|
172.1.0.31
|
|
mgr2
|
192.168.2.32
|
172.1.0.32
|
|
osd1
|
192.168.2.41
|
172.1.0.41
|
|
osd2
|
192.168.2.42
|
172.1.0.42
|
|
osd3
|
192.168.2.43
|
172.1.0.43
|
|
osd4
|
192.168.2.44
|
172.1.0.44
|
|
client1
|
192.168.2.50
|
172.1.0.50
|
4.2 服务器初始化配置及优化
4.2.1 关闭ssh登录dns域名查询,加速远程登录
pssh -i -h /data/host_list/ceph 'sed -i "s/^#UseDNS no/UseDNS no/g" /etc/ssh/sshd_config'
pssh -i -h /data/host_list/ceph 'service sshd restart'
4.2.2 关闭防火墙
pssh -i -h /data/host_list/ceph 'ufw disable'
4.2.3 配置定时时间同步
#pssh -i -h /data/host_list/ceph 'echo "*/30 * * * * root /usr/sbin/ntpdate 192.168.1.20 && hwclock -w > /dev/null 2>& 1" >> /var/spool/cron/crontabs/root '
pssh -i -h /data/host_list/ceph ' crontab -l|tail -n 1'
4.2.4 ceph安装的版本
4.25 .将Ubuntu的apt-get 源改为清华源
Ubuntu 的软件源配置文件是 /etc/apt/sources.list。将系统自带的该文件做个备份,将该文件替换为下面内容,即可使用 TUNA 的软件源镜像
# mv /etc/apt/sources.list /etc/apt/sources.list.bak
vim /etc/apt/sources.list
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
4.2. 6 各节点配置ceph yum 仓库
导入key 文件:
wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add -
添加清华源ceph源:
echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >> /etc/apt/sources.list
执行系统更新
apt-get update
4.2.7 配置hosts,添加各节点hostname
vim /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.1.0.2 ceph-deploy
172.1.0.21 mon1
172.1.0.22 mon2
172.1.0.23 mon3
172.1.0.31 mgr1
172.1.0.32 mgr2
172.1.0.41 osd1
172.1.0.42 osd2
172.1.0.43 osd3
172.1.0.44 osd4
172.1.0.50 client1
4.2.8 Ubuntu 各服务器需要单独安装Python2
# apt install python2.7 -y
# ln -sv /usr/bin/python2.7 /usr/bin/python2
4.3 安装系统常用工具
apt install iproute2 ntpdate tcpdump telnet traceroute nfs-kernel-server nfs-common lrzsz tree openssl libssl-dev libpcre3 libpcre3-dev zlib1g-dev gcc openssh-server iotop unzip zip -y
4.4 创建普通用户cephuser
4.4.1 创建cephuser普通用户
groupadd -r -g 2023 cephuser && useradd -r -m -s /bin/bash -u 2023 -g 2023 cephuser && echo cephuser:sa@123.. | chpasswd
4.4.2 各服务器允许ceph 用户以sudo 执行特权命
echo "cephuser ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
4.4.3 配置免秘钥登录
在ceph-deploy 节点配置允许以非交互的方式登录到各ceph osd/mon/mgr 节点,即在ceph-deploy 节点生成秘钥对,然后分发公钥到各被管理节点:
ssh-keygen
ssh-keygen
ssh-copy-id cephuser@172.1.0.2
ssh-copy-id cephuser@172.1.0.21
ssh-copy-id cephuser@172.1.0.22
ssh-copy-id cephuser@172.1.0.23
ssh-copy-id cephuser@172.1.0.31
ssh-copy-id cephuser@172.1.0.32
ssh-copy-id cephuser@172.1.0.41
ssh-copy-id cephuser@172.1.0.42
ssh-copy-id cephuser@172.1.0.43
ssh-copy-id cephuser@172.1.0.44
ssh-copy-id cephuser@172.1.0.50
4.5.deploy节点部署
4.5.1 在ceph 部署服务器(192.168.2.2)安装部署工具ceph-deploy
root@ceph-deploy:~# apt install ceph-deploy
4.5.2 ceph-deploy 管理ceph 集群
在ceph-deploy 节点配置一下系统环境,以方便后期可以执行ceph 管理命令。
# apt install ceph-common
4.5.3 推送正证书给自己
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy admin ceph-deploy
4.5.4 证书文件授权
root@ceph-deploy:/data/ceph-cluster# setfacl -m u:cephuser:rw /etc/ceph/ceph.client.admin.keyring
4.6 配置mon节点
4.6.1 在管理节点ceph-depoly上初始化mon节点
root@ceph-deploy:~# mkdir ceph-cluster -p #保存当前集群的初始化配置信息
root@ceph-deploy:~# cd ceph-cluster/
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy new --cluster-network 172.1.0.0/24 --public-network 192.168.2.0/24 mon1 mon2 mon3
生成如下文件:
-rw-rw-r-- 1 cephuser cephuser 295 Aug 19 11:23 ceph.conf
-rw-rw-r-- 1 cephuser cephuser 11492 Aug 19 11:23 ceph-deploy-ceph.log
-rw------- 1 cephuser cephuser 73 Aug 19 11:23 ceph.mon.keyring
ceph.conf #自动生成的配置文件
ceph-deploy-ceph.log #初始化日志
#用于ceph mon 节点内部通讯认证的秘钥环文件
4.6.2 配置mon 节点并生成及同步秘钥
4.6.2.1 在各mon节点安装组件ceph-mon,并通过初始化mon 节点,mon 节点ha 还可以后期横向扩容
apt install ceph-mon
4.6.2.2 在ceph-deploy 初始化mon节点
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy mon create-initial
4.6.2.3 验证mon 节点
ps -ef |grep mon
ceph 20082 1 1 12:00 ? 00:00:00 /usr/bin/ceph-mon -f --cluster ceph --id mon1 --setuser ceph --setgroup ceph
4.7 配置manager 节点
4.7.1 mgr节点安装ceph-mgr安装包
apt install ceph-mgr
4.7.2 ceph-deploy节点cephuser账号执行初始化mgr节点
ceph-deploy mgr create mgr1 mgr2
4.7.3 验证ceph-mgr 节点
root@mgr1:~# ps -ef |grep mgr
ceph 20913 1 40 12:54 ? 00:00:12 /usr/bin/ceph-mgr -f --cluster ceph --id mgr1 --setuser ceph --setgroup ceph
4.8 mon、mgr初始化安装后集群状态查询
测试ceph 命令:
root@ceph-deploy:/data/ceph-cluste# su - cephuser
cephuser@ceph-deploy:~$ ceph -s
cluster:
id: d623cb9e-74c4-44ec-ba47-a49272ddd76e
health: HEALTH_WARN
mons are allowing insecure global_id reclaim
OSD count 0 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum mon1,mon2,mon3 (age 59m)
mgr: mgr1(active, since 5m), standbys: mgr2
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
mon is allowing insecure global_id reclaim #需要禁用非安全模式通信
OSD count 0 < osd_pool_default_size 3 #集群的OSD 数量小于3
配置优化
cephuser@ceph-deploy:~$ ceph config set mon auth_allow_insecure_global_id_reclaim false
mon is allowing insecure global_id reclaim 警告消失了
4.9 准备OSD 节点
4.9.1 初始化ceph 存储节点
初始化存储节点等于在存储节点安装了ceph 及ceph-rodsgw 安装包,但是使用默认的官方仓库会因为网络原因导致初始化超时,因此各存储节点推荐修改ceph 仓库为阿里或者清华等国内的镜像源。
修改ceph 镜像源,之前步骤已经配置过,此步忽略。
初始化node 节点过程,此过程会在指定的ceph node 节点按照串行的方式逐个服务器安装epel 源和ceph 源,并按安装ceph ceph-radosgw
ceph-deploy install --no-adjust-repos --nogpgcheck osd1 osd2 osd3 osd4
4.9.1 分发admin 秘钥
root@ceph-deploy:/data/ceph-cluste# apt install ceph-common -y
root@ceph-deploy:/data/ceph-cluste# su - cephuser
cephuser@ceph-deploy:~$ cd ceph-cluster/
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy admin osd1 osd2 osd3 osd4
4.9.3 ceph 节点(osd)验证秘钥
root@osd1:~# ll /etc/ceph/
total 24
drwxr-xr-x 2 root root 87 Aug 19 12:06 ./
drwxr-xr-x 95 root root 8192 Aug 19 11:41 ../
-rw------- 1 root root 151 Aug 19 12:06 ceph.client.admin.keyring
-rw-r--r-- 1 root root 295 Aug 19 12:06 ceph.conf
-rw-r--r-- 1 root root 92 Jul 8 22:17 rbdmap
-rw------- 1 root root 0 Aug 19 12:06 tmpSJF5Yk
4.9.4 认证文件的属主和属组的修改
为了安全考虑,默认设置为了root 用户和root 组,如果需要ceph用户也能执行ceph 命令,那么就需要对ceph 用户进行授权
root@osd1:~# setfacl -m u:cephuser:rw /etc/ceph/ceph.client.admin.keyring
root@osd2:~# setfacl -m u:cephuser:rw /etc/ceph/ceph.client.admin.keyring
root@osd3:~# setfacl -m u:cephuser:rw /etc/ceph/ceph.client.admin.keyring
root@osd4:~# setfacl -m u:cephuser:rw /etc/ceph/ceph.client.admin.keyring
4.9.5 擦除磁盘之前通过deploy 节点对node(osd) 节点执行安装ceph 基本运行环境
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific osd1
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific osd2
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific osd3
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific osd4
4.9.6 列出ceph node 节点磁盘
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy disk list osd1
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy disk list osd2
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy disk list osd3
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy disk list osd4
4.9.7 使用ceph-deploy disk zap 擦除各ceph node 的ceph 数据磁盘
cephuser@ceph-deploy:~/ceph-cluster$ for i in b c d e f; do ceph-deploy disk zap osd1 /dev/vd$i;done
cephuser@ceph-deploy:~/ceph-cluster$ for i in b c d e f; do ceph-deploy disk zap osd2 /dev/vd$i;done
cephuser@ceph-deploy:~/ceph-cluster$ for i in b c d e f; do ceph-deploy disk zap osd3 /dev/vd$i;done
cephuser@ceph-deploy:~/ceph-cluster$ for i in b c d e f; do ceph-deploy disk zap osd4 /dev/vd$i;done
4.9.8 添加OSD
数据分类保存方式:
Data:即ceph 保存的对象数据
Block: rocks DB 数据即元数据
block-wal:数据库的wal 日志
cephuser@ceph-deploy:~/ceph-cluster$ for i in b c d e f; do ceph-deploy osd create osd1 --data /dev/vd$i;done
cephuser@ceph-deploy:~/ceph-cluster$ for i in b c d e f; do ceph-deploy osd create osd2 --data /dev/vd$i;done
cephuser@ceph-deploy:~/ceph-cluster$ for i in b c d e f; do ceph-deploy osd create osd3 --data /dev/vd$i;done
cephuser@ceph-deploy:~/ceph-cluster$ for i in b c d e f; do ceph-deploy osd create osd4 --data /dev/vd$i;done
4.9.10 验证osd添加后集群状态
cephuser@ceph-deploy:~/ceph-cluster$ ceph -s
cluster:
id: d623cb9e-74c4-44ec-ba47-a49272ddd76e
health: HEALTH_OK
services:
mon: 3 daemons, quorum mon1,mon2,mon3 (age 86m)
mgr: mgr1(active, since 32m), standbys: mgr2
osd: 20 osds: 20 up (since 42s), 20 in (since 53s)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 152 MiB used, 2.0 TiB / 2.0 TiB avail
pgs: 1 active+clean
5. Ceph块设备RBD
5.1 RBD简介
RBD(RADOS Block Devices)即为块存储的一种,RBD 通过librbd 库与OSD 进行交互,RBD为KVM 等虚拟化技术和云服务(如OpenStack 和CloudStack)提供高性能和无限可扩展性的存储后端,这些系统依赖于libvirt 和QEMU 实用程序与RBD 进行集成,客户端基于librbd 库即可将RADOS 存储集群用作块设备,不过,用于rbd 的存储池需要事先启用rbd功能并进行初始化。例如,下面的命令创建一个名为myrbd1 的存储池,并在启用rbd 功能后对其进行初始化
5.2 RBD创建
5.2.1 创建RBD
创建存储池命令格式:
$ceph osd pool create <poolname> pg_num pgp_num {replicated|erasure}
#创建存储池,指定pg 和pgp 的数量,pgp 是对存在于pg 的数据进行组合存储,pgp 通常等于pg 的值
cephuser@ceph-deploy:~/ceph-cluster$ ceph osd pool create rbd-test1 64 64
$ ceph osd pool --help
cephuser@ceph-deploy:~/ceph-cluster$ ceph osd pool application enable rbd-test1 rbd
5.2.2 通过RBD 命令对存储池初始化
$ rbd -h
rbd pool init -p rbd-test1
5.2.3 创建并验证img
不过,rbd 存储池并不能直接用于块设备,而是需要事先在其中按需创建映像(image),并把映像文件作为块设备使用,rbd 命令可用于创建、查看及删除块设备相在的映像(image),以及克隆映像、创建快照、将映像回滚到快照和查看快照等管理操作,例如,下面的命令能够创建一个名为img-test1 的映像:
cephuser@ceph-deploy:~/ceph-cluster$ rbd create img-test1 --size 5G --pool rbd-test1
cephuser@ceph-deploy:~/ceph-cluster$ rbd create img-test2 --size 3G --pool rbd-test1 --image-format 2 --image-feature layering
#后续步骤会使用 img-test2,由于系统内核较低无法挂载使用,因此只开启部分特性。
除了layering 其他特性需要高版本内核支持
列出img:
cephuser@ceph-deploy:~/ceph-cluster$ rbd ls --pool rbd-test1
img-test1
img-test2
5.2.4 查看指定rdb 的信息
cephuser@ceph-deploy:~/ceph-cluster$ rbd --image img-test1 --pool rbd-test1 info
rbd image 'img-test1':
size 5 GiB in 1280 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 1295c66bf942
block_name_prefix: rbd_data.1295c66bf942
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Thu Aug 19 13:42:45 2021
access_timestamp: Thu Aug 19 13:42:45 2021
modify_timestamp: Thu Aug 19 13:42:45 2021
cephuser@ceph-deploy:~/ceph-cluster$ rbd --image img-test2 --pool rbd-test1 info
rbd image 'img-test2':
size 3 GiB in 768 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 129e31139198
block_name_prefix: rbd_data.129e31139198
format: 2
features: layering
op_features:
flags:
create_timestamp: Thu Aug 19 13:44:39 2021
access_timestamp: Thu Aug 19 13:44:39 2021
modify_timestamp: Thu Aug 19 13:44:39 2021
5.3 客户端使用块存储
5.3.1 查看当前ceph 状态
cephuser@ceph-deploy:~/ceph-cluster$ ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 2.0 TiB 2.0 TiB 162 MiB 162 MiB 0
TOTAL 2.0 TiB 2.0 TiB 162 MiB 162 MiB 0
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 633 GiB
rbd-test1 2 64 405 B 7 48 KiB 0 633 GiB
5.3.2 在客户端安装ceph-common
root@client1:~# apt install ceph-common
5.3.3 从ceph-deploy服务器同步认证文件
cephuser@ceph-deploy:~/ceph-cluster$ scp ceph.conf ceph.client.admin.keyring root@172.1.0.50:/etc/ceph/
5.3.4 客户端映射img
root@client1:/etc/ceph# rbd -p rbd-test1 map img-test1
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable rbd-test1/img-test1 object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
root@client1:/etc/ceph# rbd -p rbd-test1 map img-test2
/dev/rbd0
5.3.5 客户端验证RBD
root@client1:/etc/ceph# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
rbd0 251:0 0 3G 0 disk
vda 252:0 0 200G 0 disk
├─vda1 252:1 0 4.7G 0 part /boot
└─vda2 252:2 0 195.4G 0 part /
5.3.6 客户端格式化磁盘并挂载使用
root@client1:/etc/ceph# fdisk /dev/rbd0
root@client1:/etc/ceph# mkfs.xfs /dev/rbd0p1
root@client1:/etc/ceph# mkdir /mnt/rbd0
root@client1:/etc/ceph# mount /dev/rbd0p1 /mnt/rbd0/
root@client1:/etc/ceph# df -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/rbd0p1 3.0G 36M 3.0G 2% /mnt/rbd0
5.3.7 客户端验证
root@client1:/etc/ceph# dd if=/dev/zero of=/mnt/rbd0/ceph-test-file bs=1MB count=300
300+0 records in
300+0 records out
300000000 bytes (300 MB, 286 MiB) copied, 0.537179 s, 558 MB/s
ceph 验证数据
root@client1:/etc/ceph# df -h
Filesystem Size Used Avail Use% Mounted on
udev 3.9G 0 3.9G 0% /dev
tmpfs 798M 5.9M 792M 1% /run
/dev/vda2 196G 4.7G 191G 3% /
tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/vda1 4.7G 183M 4.5G 4% /boot
tmpfs 798M 0 798M 0% /run/user/0
/dev/rbd0p1 3.0G 323M 2.7G 11% /mnt/rbd0
6.ceph radosgw(RGW)对象存储
6.1 RGW简介
RGW 提供的是REST 接口,客户端通过http 与其进行交互,完成数据的增删改查等管理操。
radosgw 用在需要使用RESTful API 接口访问ceph 数据的场合,因此在使用RBD 即块存储得场合或者使用cephFS 的场合可以不用启用radosgw 功能。
6.2 部署radosgw 服务
如果是在使用radosgw 的场合,则以下命令以mgr1 节点为例部署为RGW 主机:
首先在需要安装radosgwf服务的服务器上,比如mgr1上安装radosgw安装包
root@mgr1:~# apt install radosgw=16.2.5-1bionic
6.3 radosgw节点的初始化
在ceph-deploy节点用cephuser账号执行radosgw节点的初始化命令
cephuser@ceph-deploy:~/ceph-cluster$ ceph-deploy --overwrite-conf rgw create mgr1
6.4 验证mgr1 上radosgw 服务
root@mgr1:~# ps -ef |grep radosgw
root 22253 1 2 15:41 ? 00:00:00 /usr/bin/radosgw -f --cluster ceph --name client.rgw.mgr1 --setuser ceph --setgroup ceph
6.5 查看radosgw服务的监听端口
root@mgr1:~# netstat -ntlp |grep radosgw
tcp 0 0 0.0.0.0:7480 0.0.0.0:* LISTEN 22253/radosgw
tcp6 0 0 :::7480 :::* LISTEN 22253/radosgw
6.6 访问测试
cephuser@ceph-deploy:~/ceph-cluster$ curl "http://mgr1:7480"
<?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>
验证ceph 状态
cephuser@ceph-deploy:~/ceph-cluster$ ceph -s
cluster:
id: d623cb9e-74c4-44ec-ba47-a49272ddd76e
health: HEALTH_OK
services:
mon: 3 daemons, quorum mon1,mon2,mon3 (age 3h)
mgr: mgr1(active, since 2h), standbys: mgr2
osd: 20 osds: 20 up (since 2h), 20 in (since 2h)
rgw: 1 daemon active (1 hosts, 1 zones)
data:
pools: 6 pools, 169 pgs
objects: 282 objects, 300 MiB
usage: 2.0 GiB used, 2.0 TiB / 2.0 TiB avail
pgs: 169 active+clean
6.7 验证radosgw 存储池
初始化完成radosgw 之后,会初始化默认的存储池如下:
cephuser@ceph-deploy:~/ceph-cluster$ ceph osd pool ls
device_health_metrics
rbd-test1
.rgw.root
default.rgw.log
default.rgw.control
default.rgw.meta

 浙公网安备 33010602011771号
浙公网安备 33010602011771号