

|NO.Z.00041|——————————|BigDataEnd|——|Hadoop&ElasticSearch.V41|——|ELK.v41|原理剖析|数据结构.V1|
一、Elasticsearch中的数据结构
### --- 倒排索引详解:概述
~~~ 倒排索引是全文检索的根基,理解了倒排索引之后才能算是入门了全文检索领域。
~~~ 倒排索引的的概念很简单,也很好理解。Elasticsearch/Lucene是如何实现这个结构的呢? Term Doc_1 Doc_2
-------------------------
Quick | | X
The | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
quick | X |
summer | | X
the | X |
------------------------二、数据结构说明
### --- 数据结构说明
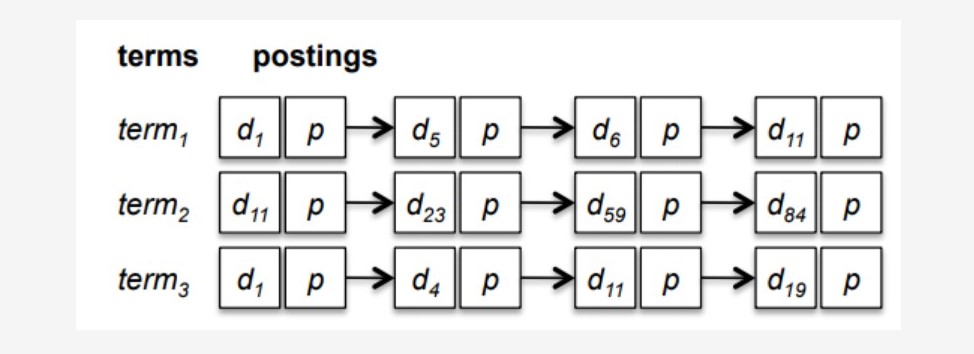
~~~ 倒排索引由两部分组成,所有独立的词列表称为索引,词对应的一系列表统称为倒排表。
~~~ —— 来自《信息检索》
~~~ 索引表,叫Terms Dictionary ,是由于一系列的Term组成的。
~~~ 倒排表,称Postings List ,即是由所有的Term对应的Postings组成的。
~~~ 如何存储一个倒排索引数据?选择哪种数据结构?### --- 场景
~~~ 全文搜索引擎通常是需要存储大量的文本,不仅是Postings可能会是非常巨大,
~~~ 同样Dictionary的大小极可能也是非常庞大。
~~~ 真正的搜索引擎的倒排索引实现都极其复杂,因为它直接影响了搜索性能和功能
~~~ # Lucene的实现非常高级,它的关键特性是能够将整个倒排索引序列化存储在磁盘上,
~~~ 同时它必须是能够满足快速读写的需求。
~~~ Lucene为了极致的搜索体验,引用多种数据结构和算法。
~~~ 倒排索引变得高效又复杂给我们带来一次研读和剖析的机会。| 数据结构 | 评估 |
| 排序列表Array/List | 使用二分法查找,不平衡 |
| HashMap/TreeMap | 性能高,内存消耗大,几乎是原始数据的三倍 |
| Skip List | 跳跃表,可快速查找词语, 在lucene、redis、Hbase等均有实现,模糊查询支持很差 |
| Trie | 适合英文词典,如果系统中存 在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存 |
| Double Array Trie | 适合做中文词典,内存占用小,很多分词工具均采用此种算法 |
| Finite State Transducers (FST) |
一种有限状态转移机,Lucene 4有开源实现,并大量使用(Trie + 有限状态机) |
四、Lucene索引文件分析
### --- Lucene 索引文件分析
[root@hadoop02 ~]# ll /opt/yanqi/servers/es/data/es/nodes/0/indices/MUiqoQHrRnO4Nk2gwB9lnQ/0/index
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.dim
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.fdt
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.fdx
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.fnm
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.doc # ---
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.pos # ---
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.tim # ---
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.tip # ---
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.dvd
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.dvm
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.nvd
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.nvm
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.si
-rw-rw-r-- 1 es es 283 Nov 25 19:48 segments_3
-rw-rw-r-- 1 es es 0 Nov 25 19:43 write.lock### --- Lucene将索引文件拆分为了多个文件,此处仅讨论倒排索引部分。
~~~ tip: Lucene把用于存储Term的索引文件叫Terms Index,它的后缀是.tip ;
~~~ doc: 把Postings信息分别存储在.doc ,分别记录Postings的DocId信息和Term的词频信息。
~~~ tim: Terms Dictionary的文件后缀称为.tim ,
~~~ 它是Term与Postings的关系纽带,存储了Term和其对应的Postings文件指针。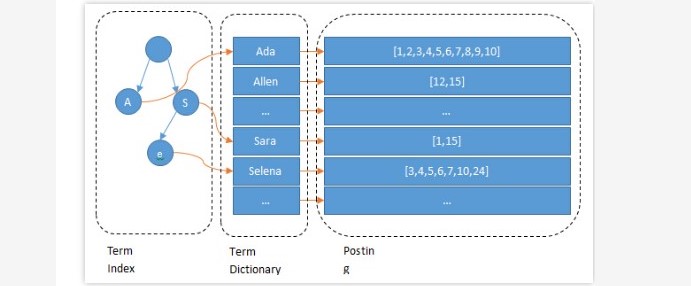
### --- Term Dictionary:把Term按字典序排列,然后用二分法查找Term (存在磁盘)
~~~ 在Lucene, Terms Dictionary 被存储在.tim文件上。
~~~ 当一个Segment的文档数量越来越多的同时Dictionary的词汇也会越来越多,
~~~ 那查询效率必然也会慢慢变低。如果有一个很好的结构也为Dictionary建构一个索引,
~~~ 将Dictionary的索引进一步压缩,这就是后来的Terms Index(.tip)。
~~~ Term Index:是Term Dictionary的索引,存Term的前缀,
~~~ 和与该前缀对应的Term Dictionary中的第一个Term的block的位置,
~~~ 找到这个第一个Term后会再往后顺序查找,直到找到目标Term。(存在内存)### --- 总结:
~~~ 通过Terms Index(.tip)可以快速地在Terms Dictionary(.tim)中找到你的想要的Term,
~~~ 以及它对应的Postings文件指针(指向doc)。
~~~ Terms Index实际上一个或者多个FST 组成的,
~~~ Segment上每个字段都有自己的一个FST(FSTIndex)记录在.tip 上。
~~~ (FST类似一种TRIE树)Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv025-elk



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix