

|NO.Z.00040|——————————|BigDataEnd|——|Hadoop&ElasticSearch.V40|——|ELK.v40|原理剖析|存储文件|
一、存储文件详解
### --- 存储文件详解说明
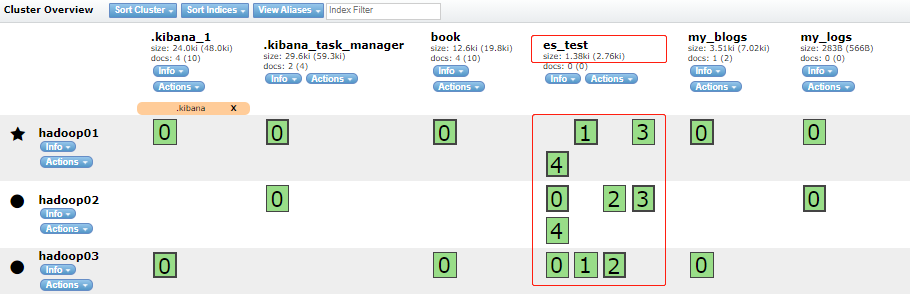
~~~ 通过ES-HEAD插件可以查看到一个索引的分片信息,图中一个绿色方块就代表一个分片Shard;
~~~ ES使用Lucene来处理shard级别的索引和查询,
~~~ 因此数据目录中的文件由Elasticsearch和Lucene共同编写。
~~~ Lucene负责编写和维护Lucene索引文件,而Elasticsearch在Lucene之上编写与功能相关的元数据,
~~~ 例如字段映射,索引设置和其他集群元数据,用户和支持功能由Elasticsearch提供。二、存储结构数据说明
### --- 进入ES集群数据存储目录
~~~ # 进入es存储数据目录查看目录结构
[root@hadoop02 ~]# ll /opt/yanqi/servers/es/data/es/nodes/0/
drwxrwxr-x 11 es es 4096 Nov 25 20:36 indices
-rw-rw-r-- 1 es es 0 Nov 24 13:50 node.lock # 确保每次只有一个es应用读写该目录
drwxrwxr-x 2 es es 4096 Nov 25 20:37 _state # 全局状态文件,包含集群全局元数据### --- 进入 indices目录
~~~ # 查看indices数据文件
[root@hadoop02 ~]# ll /opt/yanqi/servers/es/data/es/nodes/0/indices/
drwxrwxr-x 4 es es 4096 Nov 25 20:36 1u4A0I1oRRWqe_-xbp32EQ
drwxrwxr-x 4 es es 4096 Nov 24 20:40 3srxfjOwTUKyiP_qt55qnQ
drwxrwxr-x 4 es es 4096 Nov 24 21:59 5esO6z6TR8qZXgx5YfC-_g
drwxrwxr-x 3 es es 4096 Nov 25 20:35 LtB1yt1TQjmpxPYuYBo1sA
drwxrwxr-x 4 es es 4096 Nov 24 22:21 M0E-QACCRR-uYqOdL_ItPQ
drwxrwxr-x 4 es es 4096 Nov 25 00:20 meJCi6zfRnWSGsW-XbA9TQ
drwxrwxr-x 7 es es 4096 Nov 25 19:43 MUiqoQHrRnO4Nk2gwB9lnQ
drwxrwxr-x 3 es es 4096 Nov 24 20:40 SyKsKRrnR5i3bXIUz7E9og
drwxrwxr-x 3 es es 4096 Nov 25 14:13 YcQlQBPJQ5uJ8itZ0GkSHQ~~~ # 在es_test:索引中es_test:Index Metadata下查看
{
"state": "open",
"settings": {
"index": {
"creation_date": "1637840612533",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "MUiqoQHrRnO4Nk2gwB9lnQ", # MUiqoQHrRnO4Nk2gwB9lnQ和indices目录中文件对应
"version": {
"created": "7030099"
},
"provided_name": "es_test"
}### --- 补充:indices目录下存储当前节点持有的所有索引的数据(指定分片)。
~~~ # 进入 指定索引目录
[root@hadoop02 ~]# ll /opt/yanqi/servers/es/data/es/nodes/0/indices/MUiqoQHrRnO4Nk2gwB9lnQ/
drwxrwxr-x 5 es es 4096 Nov 25 19:43 0 # 标识shard编号
drwxrwxr-x 5 es es 4096 Nov 25 19:43 2
drwxrwxr-x 5 es es 4096 Nov 25 19:43 3
drwxrwxr-x 5 es es 4096 Nov 25 19:43 4
drwxrwxr-x 2 es es 4096 Nov 25 19:43 _state # 存储索引状态,包括setting,mapping等文件### --- 进入state目录
[root@hadoop02 ~]# ll /opt/yanqi/servers/es/data/es/nodes/0/indices/MUiqoQHrRnO4Nk2gwB9lnQ/_state/
total 4
-rw-rw-r-- 1 es es 783 Nov 25 19:43 state-6.st
[root@hadoop02 ~]# cat /opt/yanqi/servers/es/data/es/nodes/0/indices/MUiqoQHrRnO4Nk2gwB9lnQ/_state/state-6.st
~~~输出参数:是二进制文件:
settings
index.number_of_shards
mappingsay三、进入分片编号目录
### --- es目录存储结构
~~~ # 进入es存储数据目录查看目录结构
[root@hadoop02 ~]# ll /opt/yanqi/servers/es/data/es/nodes/0/indices/MUiqoQHrRnO4Nk2gwB9lnQ/0/
drwxrwxr-x 2 es es 4096 Nov 25 19:48 index # ES的数据目录
drwxrwxr-x 2 es es 4096 Nov 25 19:43 _state # 当前shard的信息,比如是主,副分片等信息
drwxrwxr-x 2 es es 4096 Nov 25 19:43 translog # 保证数据写入安全的事务日志数据### --- 进入数据目录
~~~ # 查看index目录
[root@hadoop02 ~]# ll /opt/yanqi/servers/es/data/es/nodes/0/indices/MUiqoQHrRnO4Nk2gwB9lnQ/0/index
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.dim
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.fdt
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.fdx
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.fnm
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.doc
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.pos
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.tim
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.tip
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.dvd
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2_Lucene50_0.dvm
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.nvd
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.nvm
-rw-rw-r-- 1 es es 283 Nov 25 19:48 _2.si
-rw-rw-r-- 1 es es 283 Nov 25 19:48 segments_3
-rw-rw-r-- 1 es es 0 Nov 25 19:43 write.lock四、文件说明:
| Name | Extension | BriefDescription |
| Segemnts File | segments_N | 存储lucene数据文件的元信息, 记录所有segment的元数据信息。 主要记录了当前有多少个segment, 每个segment有一些基本信息, 更新这些信息能定位到每个segment的元信息文件。 |
| Lock File | write.lock | 防止多个IndexWriters写入同一个文件 |
| Segement Info | .si | 存储有关段的元数据 |
| Compound File | .cfs,.cfe | 一个segment包含了如下表的各个文件, 为减少打开文件的数量,在segment小的时候, segment的所有文件内容都保存在cfs文件中, cfe文件保存了lucene各文件在cfs文件的位置信息 |
| Fields | .fnm | 存储fileds的相关信息 |
| Fields Index | .fdx | 正排存储文件的元数据信息 |
| Fields Data | .fdt | 存储了正排存储数据,写入的原文存储在这 |
| Term Dictionary | .tim | 倒排索引的元数据信息 |
| Term Index | .tip | 倒排索引文件,存储了所有的倒排索引数据 |
| Frequencies | .doc | 保存了每个term的doc id列表和term在doc中位置 |
| Positions | .pos | Stores position information about where a term occurs in the index 全文索引的字段, 会有该文件,保存了term在doc中的位置 |
| Playloads | .pay | Stores additional per-position metadata information such as character offsets and user payloads 全文索引的字段, 使用了一些像payloads的高级特性会有该文件, 保存了term在doc中的一些高级特性 |
| Norms | .nvd,.nvm | 存储索引字段加权数据 |
| Per-Document Values | .dvd,.dvm | Lucene的docvalues文件,即列式存储,用作聚合和排序 |
| Term Vector Data | .tvx,.tvd,.tvf | 保存索引字段的矢量信息, 用在对term进行高亮,计算文本相关性中使用 |
| Live Documents | .liv | 记录了segment中删除的doc |
Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor
分类:
bdv025-elk



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通